K-Means: Revisão

k-means
- Classificação
- Não-Supervisionada
- por Particionamento
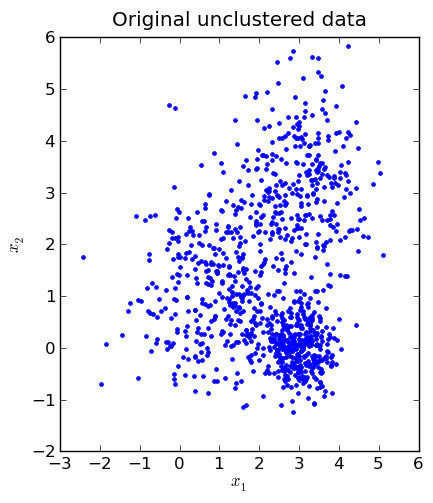
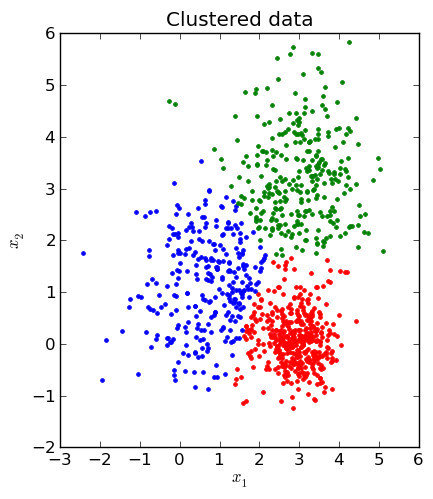
É bom
- Simples
- Flexível
- Relativamente rápido
- Mesmo com dados obscuros
- Fácil de entender e implementar
...Mas
- Precisa informar quantos "K" clusters
- Precisão (accuracy) depende da posição inicial dos "K" centróides
- Velocidade diminui quando números K ou N (amostras) aumentam muito

Desafios
- Determinando o "K"
- Inicializando os "K" centróides
- Aumentando a escala
Determinando o "K"

- Rodar várias vezes
- Medir o "erro"
- Tomar decisão
Método "cotovelo"
Qual o "K" Correto?
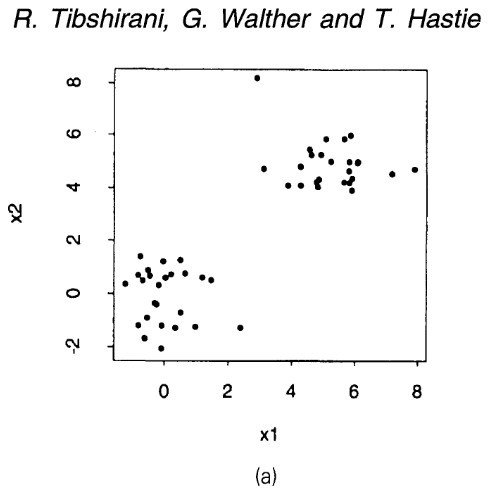
Qual o "K" Correto?
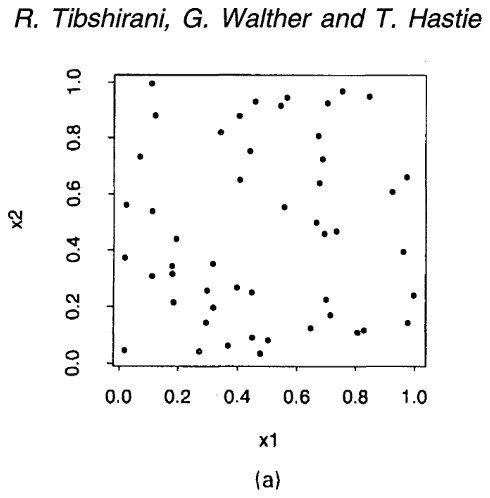
Determinando o "K"
Mais de 40 métodos e índices, com 9 principais
Entre eles: Silhouette, Dendogram, gap

Método "Silhouette"
Determinando o "K"
Mais de 40 métodos e índices, com 9 principais

Método "Silhouette"
Entre eles: Silhouette, Dendogram, gap
Determinando o "K"
Mais de 40 métodos e índices, com 9 principais
Entre eles: Silhouette, Dendogram, gap

Método "Dendogram"

Determinando o "K"
Mais de 40 métodos e índices, com 9 principais
Método "gap"
Entre eles: Silhouette, Dendogram, gap
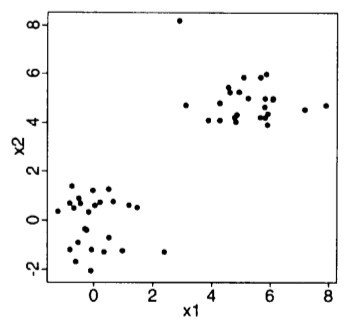
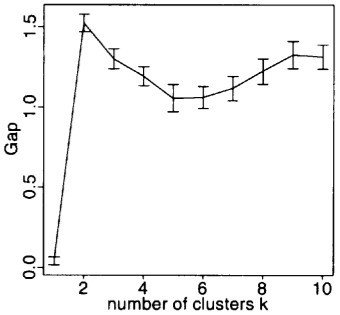
Determinando o "K"
Mais de 40 métodos e índices, com 9 principais
Método "gap"
Entre eles: Silhouette, Dendogram, gap
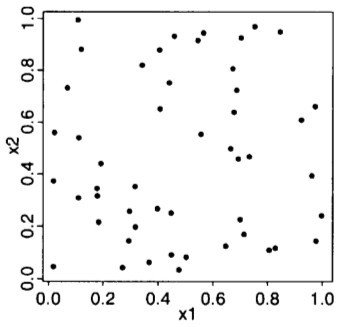
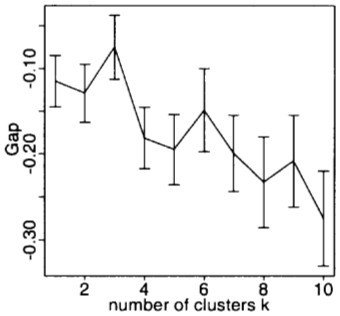
Desafios
- Determinando o "K"
- Inicializando os "K" centróides
- Aumentando a escala
Inicializando "K" Centróides
Método tradicional: Elemento aleatório
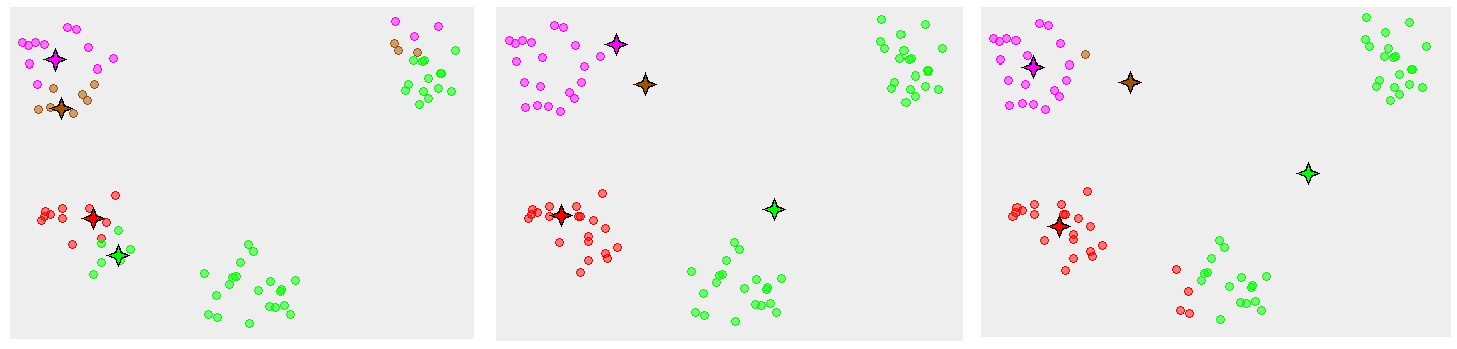
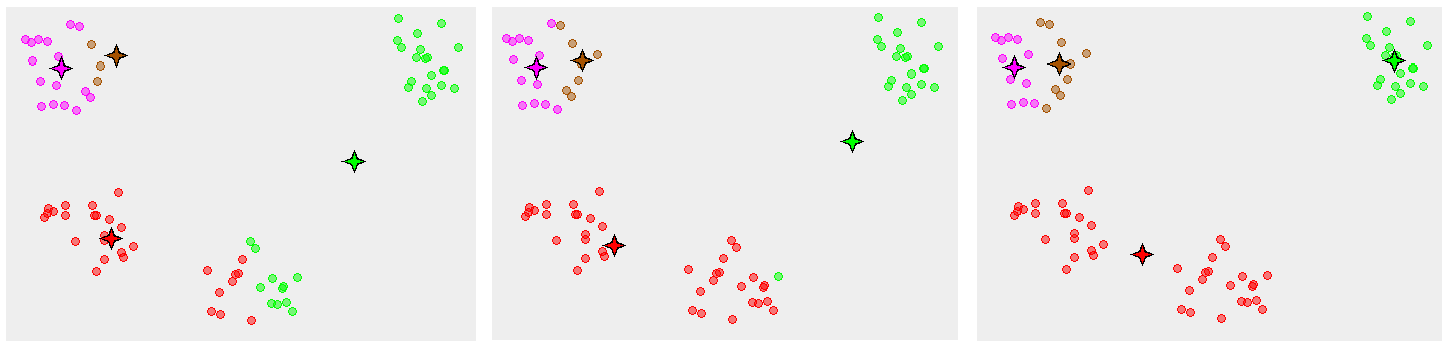
2)
1)
3)
5)
4)
6)
Inicializando "K" Centróides
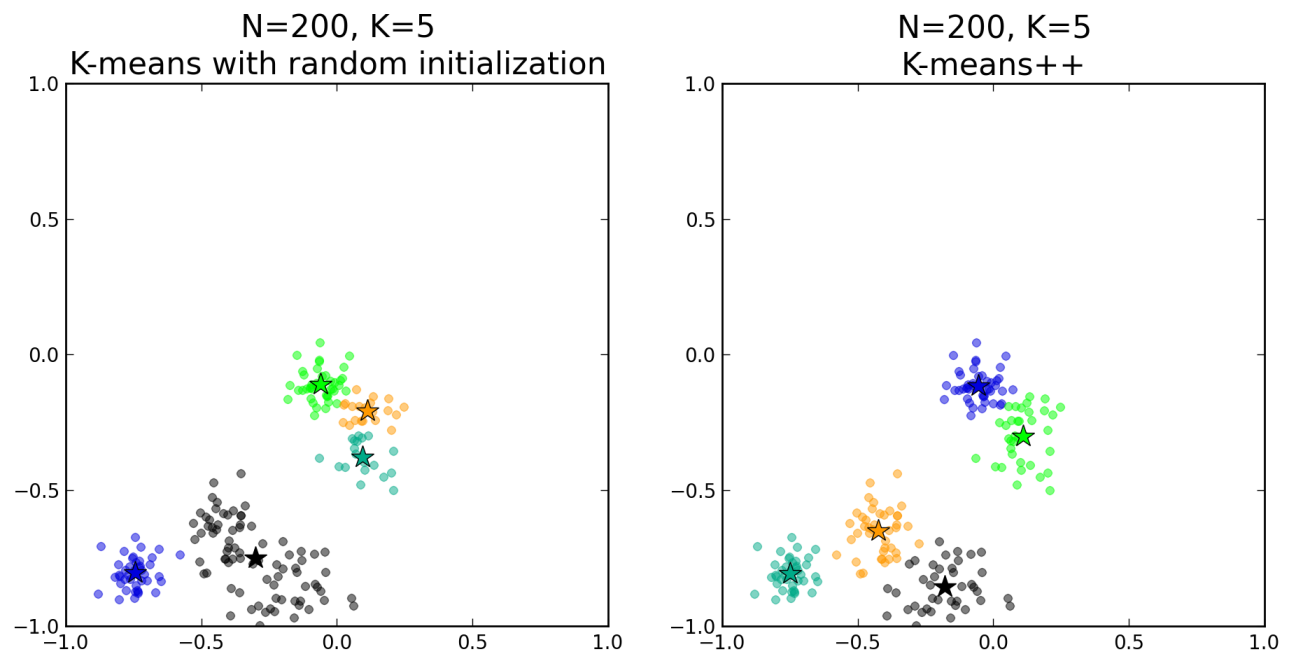
(slides do autor original - iniciar no slide 19)
Desafios
- Determinando o "K"
- Inicializando os "K" centróides
- Aumentando a escala
Aumentando a escala
- Otimizações na inicialização
- k-means||
- Otimizações nas iterações
- mini-batch (exemplo, sklearn-comparison)
- Paralelismo
- k-means||
- MapReduce
- BSP (Bulk Synchronous Parallel)
Perguntas
alan.justino@boolabs.com.br
@alanjds