Spam Classifier
Héctor F. Jiménez Saldarriaga
hfjimenez@utp.edu.co
@c1b3rh4ck @h3ct0rjs




CyberThreat LandScape

*CyberThreat Taxonomy tree, Taken from [3]
CyberThreat LandScape

*CyberThreat Taxonomy tree, Taken from [3]
Real World Uses of ML in Security
* Pattern Recognition
* Anomaly Detection
Pattern Recognition
We try to discover explicit or latent characteristics hidden in the data. It can be used to teach an algorithm to recognize other forms of the data that exhibit the same set of characteristics.
Anomaly Detection
Instead of learning specific patterns that exist within certain subsets of the data, the goal is to establish a notion of normality that describes most (say, more than 95%) of a given dataset
Pattern Recognition
- Spam detection
- Malware detection
- botnet detection
- exploitation
Anomaly Detection
- User Authentication
- Behaviour analysis
- Network attacks
- Malicious URL permutation
¿Spam?

Spam
use of electronic messaging systems to send an unsolicited message (spam), especially advertising, as well as sending messages repeatedly on the same site
Spam
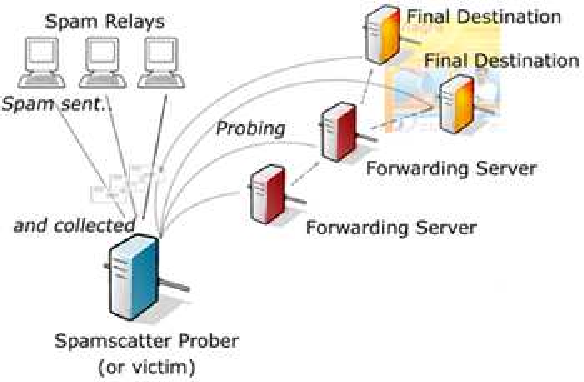
Applied to
instant messaging spam, Usenet newsgroup spam, Web search engine spam, spam in blogs, wiki spam, online classified ads spam, mobile phone messaging spam, Internet forum spam, junk fax transmissions, social spam, spam mobile apps
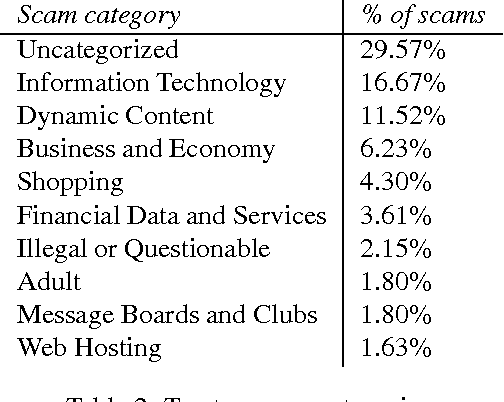
Let's go! and create a basic Spam Classifier

Mathematics Needs

Problem Statement

Baye’s Theorem
Problem Statement
sabiendo la probabilidad de tener un dolor de cabeza dado que se tiene gripe, se podría saber , la probabilidad de tener gripe si se tiene un dolor de cabeza
Problem Statement




Console....
Knowing the dataset

Knowing the dataset

Knowing the dataset
We shall use 75% of the dataset as train dataset and the rest as test dataset. Selection of this 75% of the data is uniformly random.

Visualize the message field

Training Model
Two techniques are being used for this talk:
Bag of words and TF-IDF
Bag of Words
John likes to watch movies. Mary likes movies too
"John","likes","to","watch","movies","Mary","likes","movies","too"
BoW1 = {"John":1,"likes":2,"to":1,"watch":1,"movies":2,"Mary":1,"too":1};

TF-IDF
short for term frequency–inverse document frequency, is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus

TF
The weight of a term that occurs in a document is simply proportional to the term frequency.
IDF
The specificity of a term can be quantified as an inverse function of the number of documents in which it occurs
Preprocessing
Free , FREE, FrEE they're all the same meaning....let's normalize that data
Preprocessing
Remove the stop words. Stop words are those words which occur extremely frequently in any text. For example words like ‘the’, ‘a’, ‘an’, ‘is’, ‘to’ etc
Preprocessing
Stemming to words


Bag of Words
John likes to watch movies. Mary likes movies too
"John","likes","to","watch","movies","Mary","likes","movies","too"
BoW1 = {"John":1,"likes":2,"to":1,"watch":1,"movies":2,"Mary":1,"too":1};
Book References
- Introduction to Machine Learning with applications in Infosec, Mark Stamp
- Machine Learning and Security, Protecting Systems with Data and Algorithms, Clarence Ohio and David Freeman
- Information Security and Machine Learning
- Spam Filter, Python for Scratch hackernoon.com
- Spam Detecting Machine Learning