Evaluation of Elastic Experiments
Demo of Initial Results
Dmitry Duplyakin, 01/13/2017
Experiment 1:
HTC, 50 jobs run to completion in over ran less than 2h
(Experiment directory: 20161205-213258)
Experiment 1:

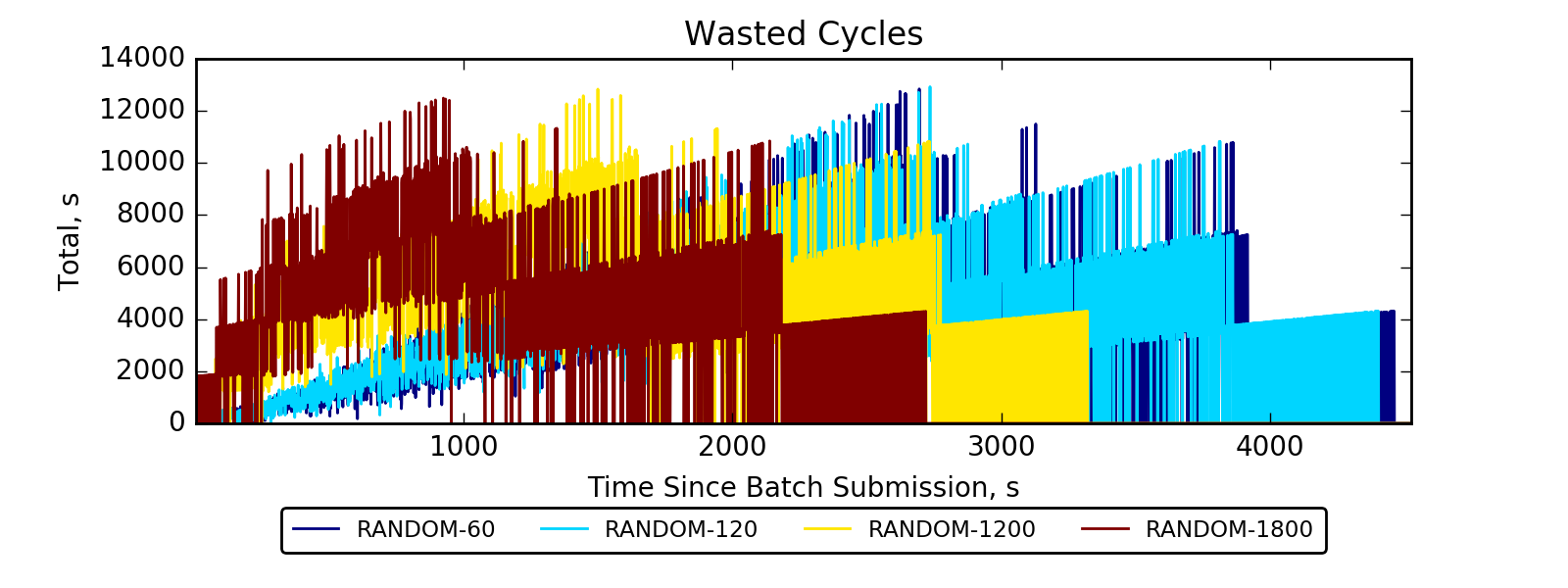
Halfway through the experiment, some nodes finish their jobs
and remain idle until the end of experiment; LIFO chooses such idle nodes for preemption (therefore WC goes to 0)
(Experiment directory: 20161205-213258)
Experiment 1:
Observations:
- Should use more data: run longer experiments
- The tail end of execution, where some of the nodes are idle, should not be compared to the rest of the experiment when all nodes are utilized
- All future experiments should be terminated when both:
- one or more nodes become idle
- and the number of pending jobs is zero
(Experiment directory: 20161205-213258)
Moving forward: building a scheduler simulator
- discrete event simulator with First-Come-First-Served scheduling + backfilling
- similar to SLURM's scheduling with sched/backfill
- simulated job schedule is not exactly the same as the one in SLURM
- SLURM has a lot of complex optimizations
- exact job ordering is not critical for this analysis
- Main advantage: can simulate ~55 days of execution in ~3 hours
- Recording the state of the cluster:
- every time one of the jobs finishes
- every dt=30 seconds between jobs completion moments
- Cluster size N=20 and number of preempted nodes P=10 can change
- Policies:
- FIFO, LIFO, RANDOM, and PAP
- Grace periods:
- 60s, 120s (preemption notification for spot instances on AWS), 1200s, 1800s
HPC Workload: PEREGRINE
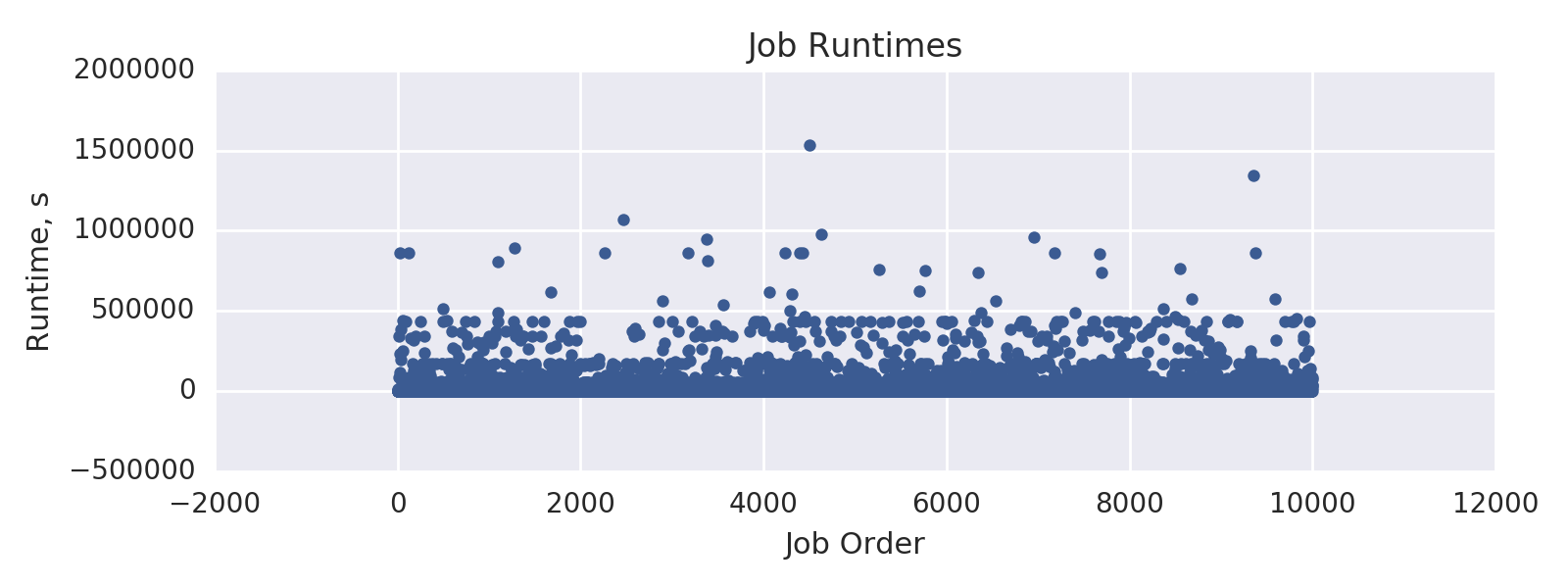
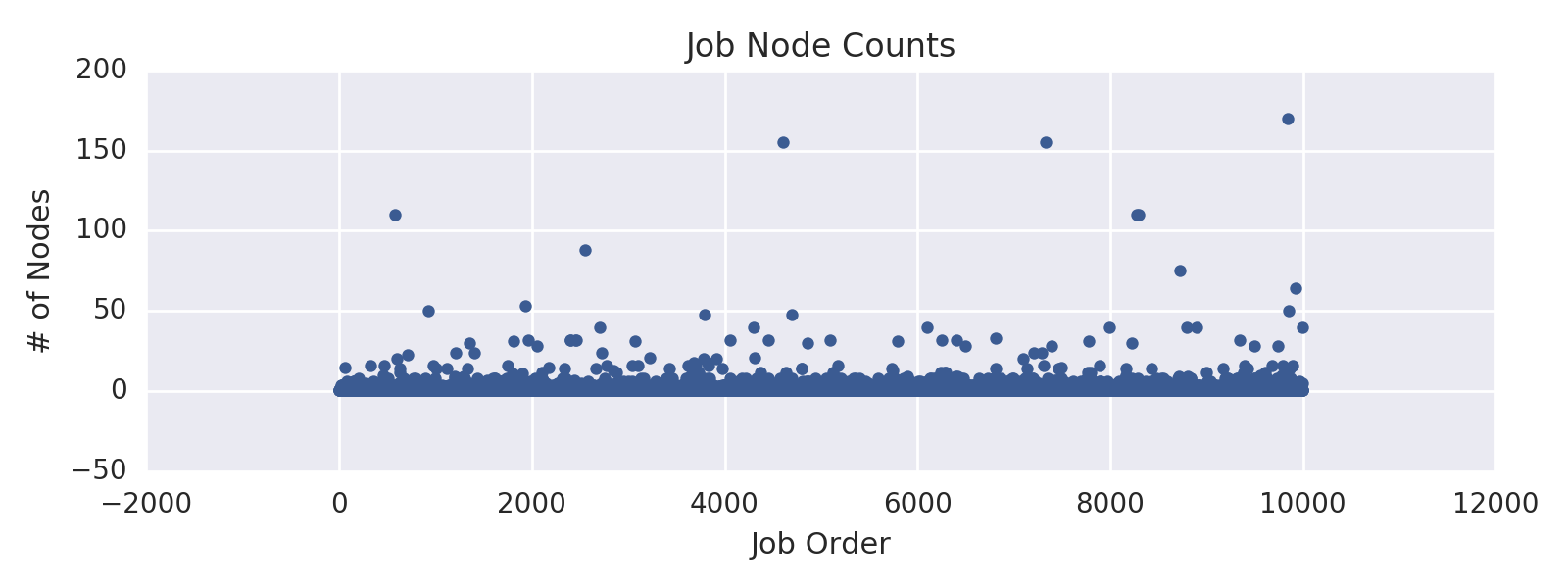
HPC Workload: PEREGRINE
HPC Workload: PEREGRINE
- Selection criteria:
- node count <= 20
- runtime <= 24 hours
- exit code is 0
- no missing fields
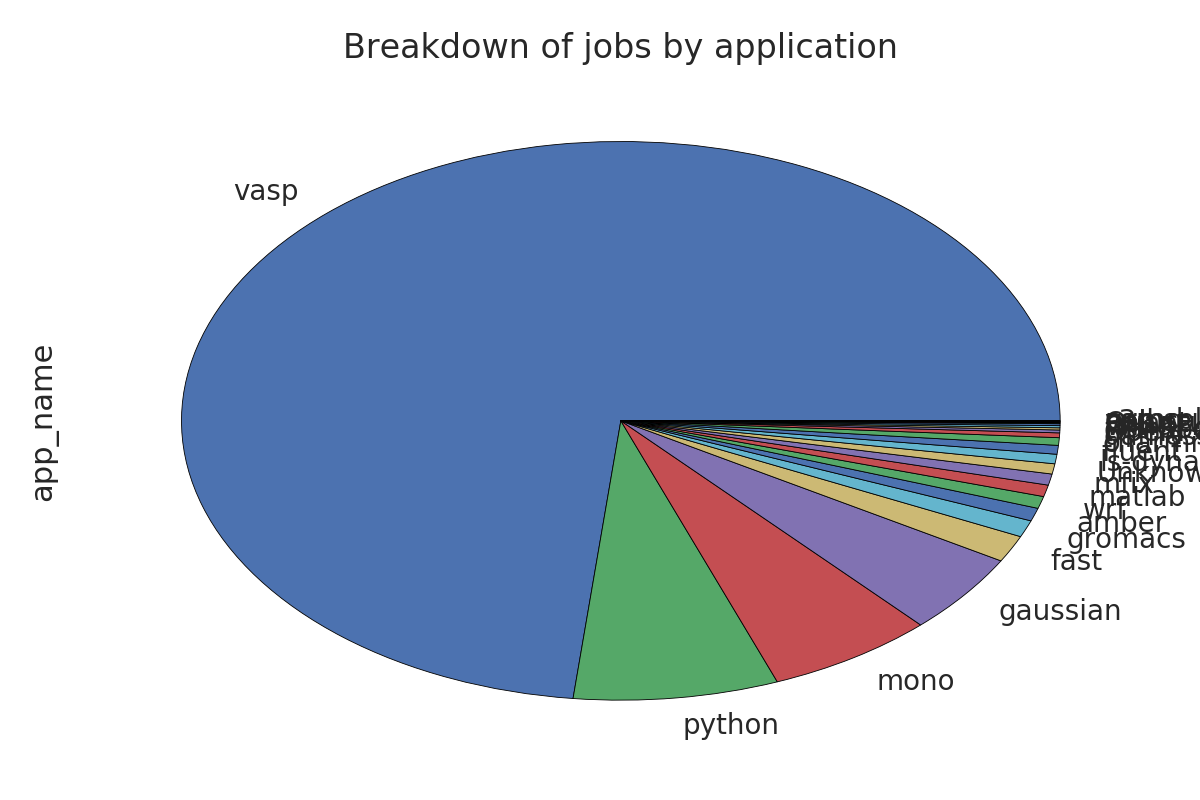
- Yields 7275 out of 9996 jobs from 24 applications
with total node-hours: 26838.58 (~55 days on 20 nodes)
Runtime:
- mean: 7119.07 s
- min: 33.00 s
- 25%: 439.50 s
- 50%: 1921.00 s
- 75%: 6840.5 s
- max: 85945.00 s
Node count:
- mean: 1.42
- min: 1.00
- 25%: 1.00
- 50%: 1.00
- 75%: 1.00
- max: 16.00
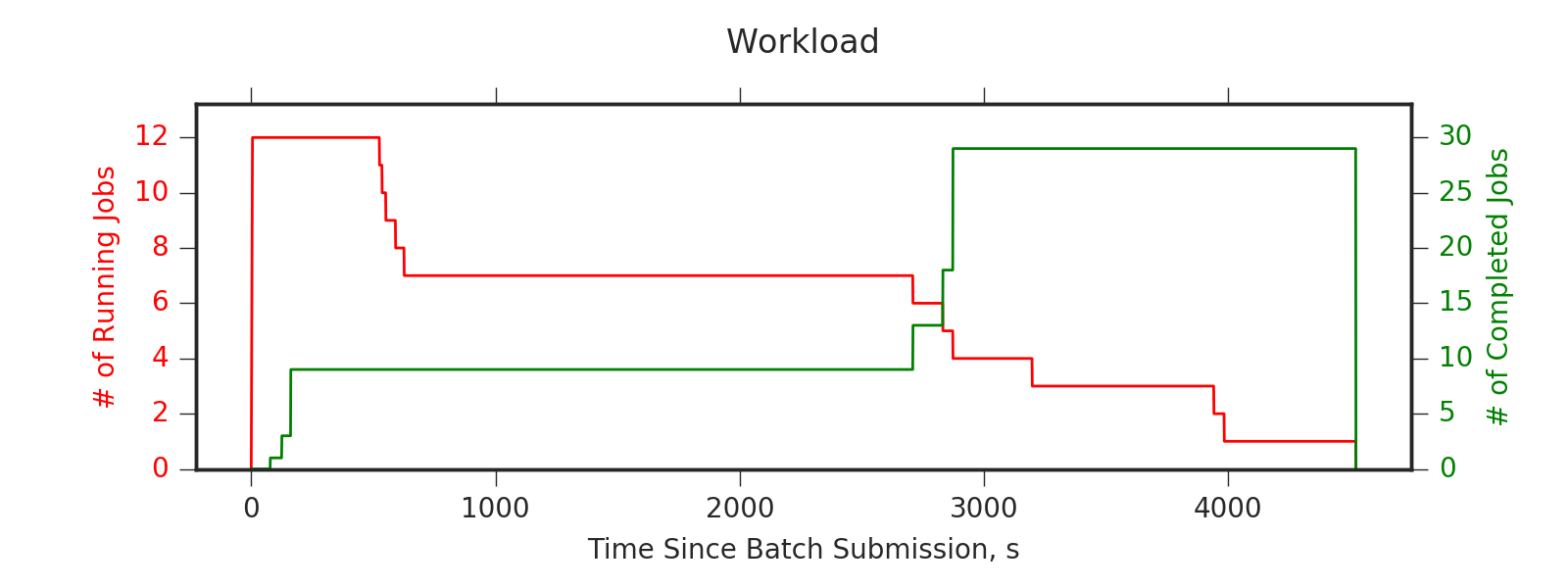
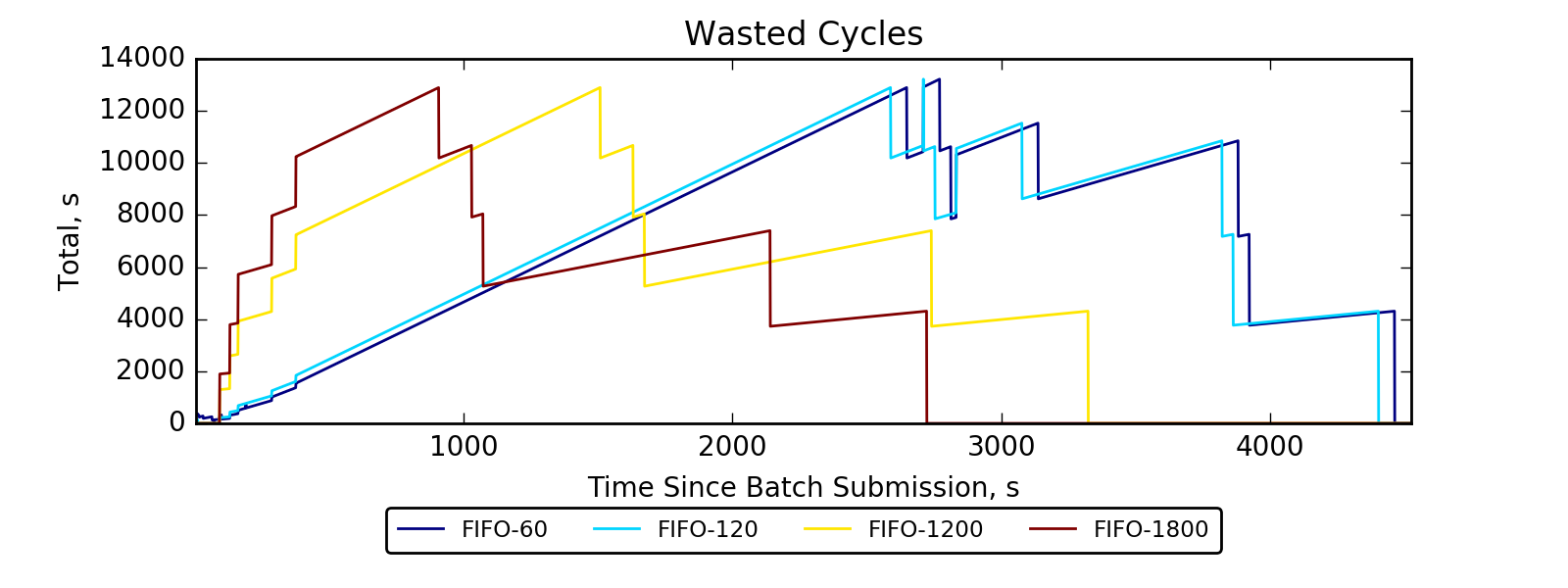
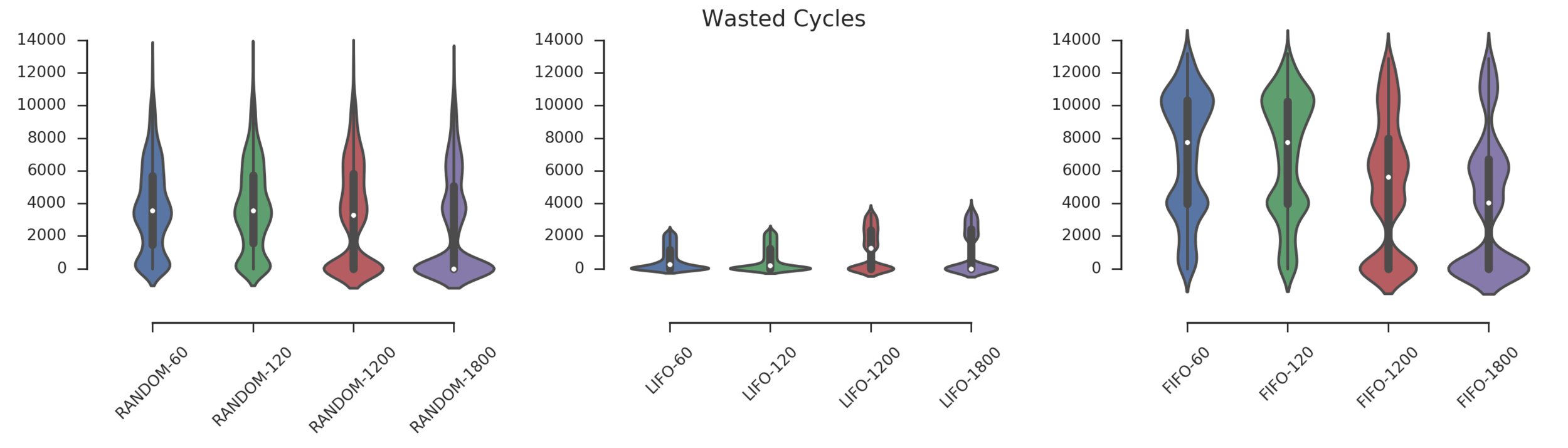
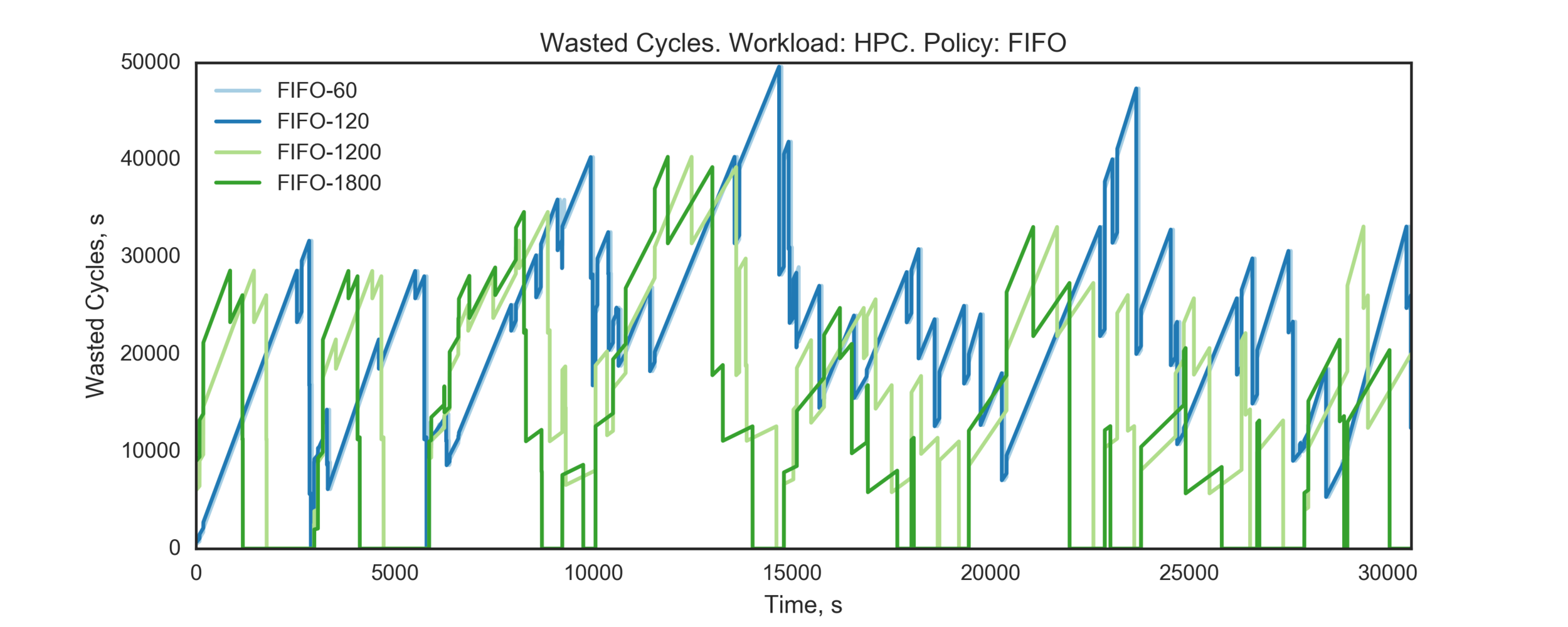
Experiment 2:
Simulating 8h of execution of a subset of PEREGRINE jobs
Visualizing preemption vectors with heatmaps: the darker, the more valuable)
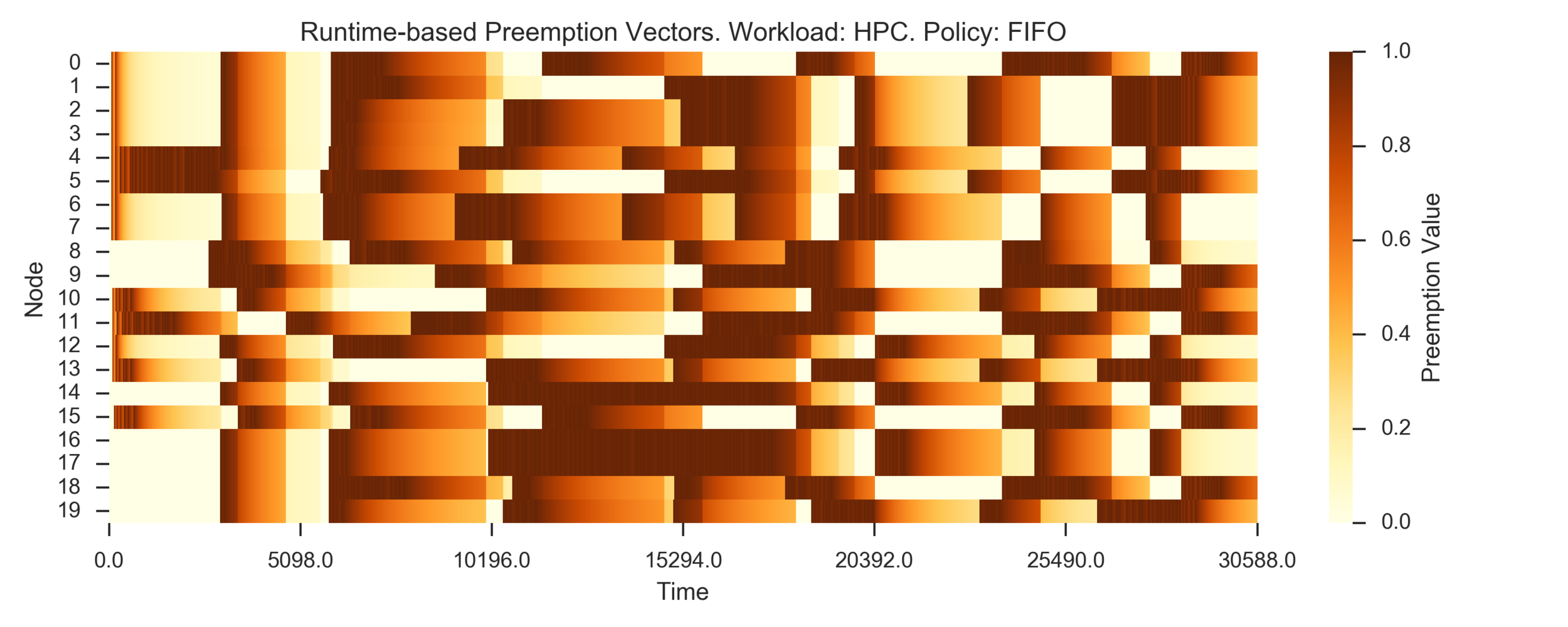
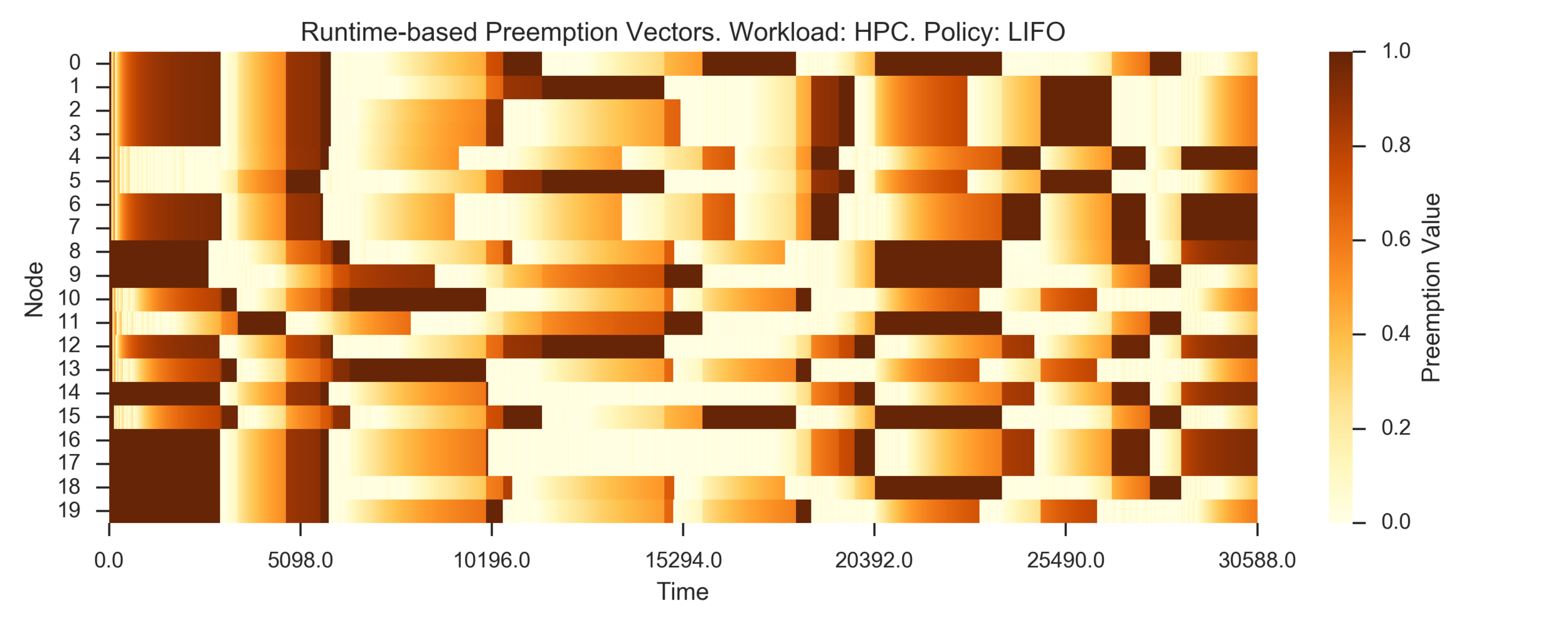
(Experiment directory: yass/preserved/hpc-20161219-131501)
FIFO:
Experiment 2:
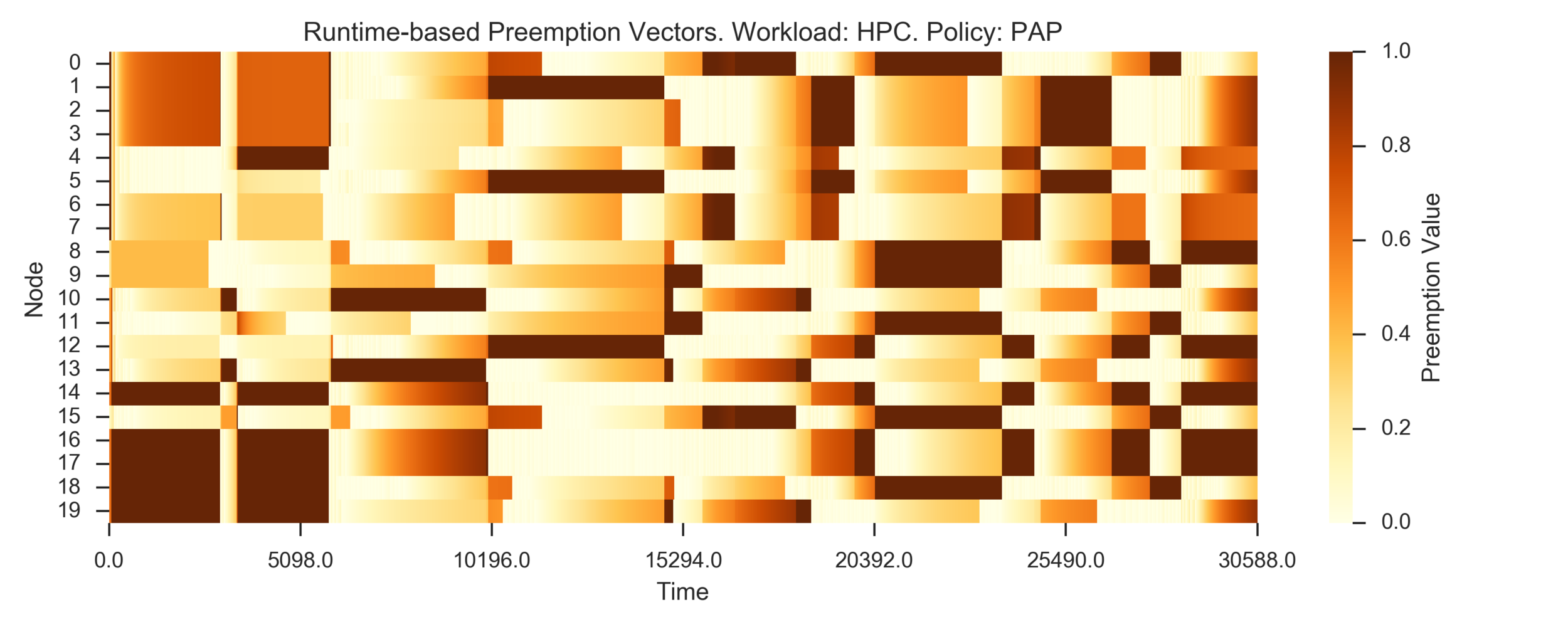
(Experiment directory: yass/preserved/hpc-20161219-131501)
Experiment 2:
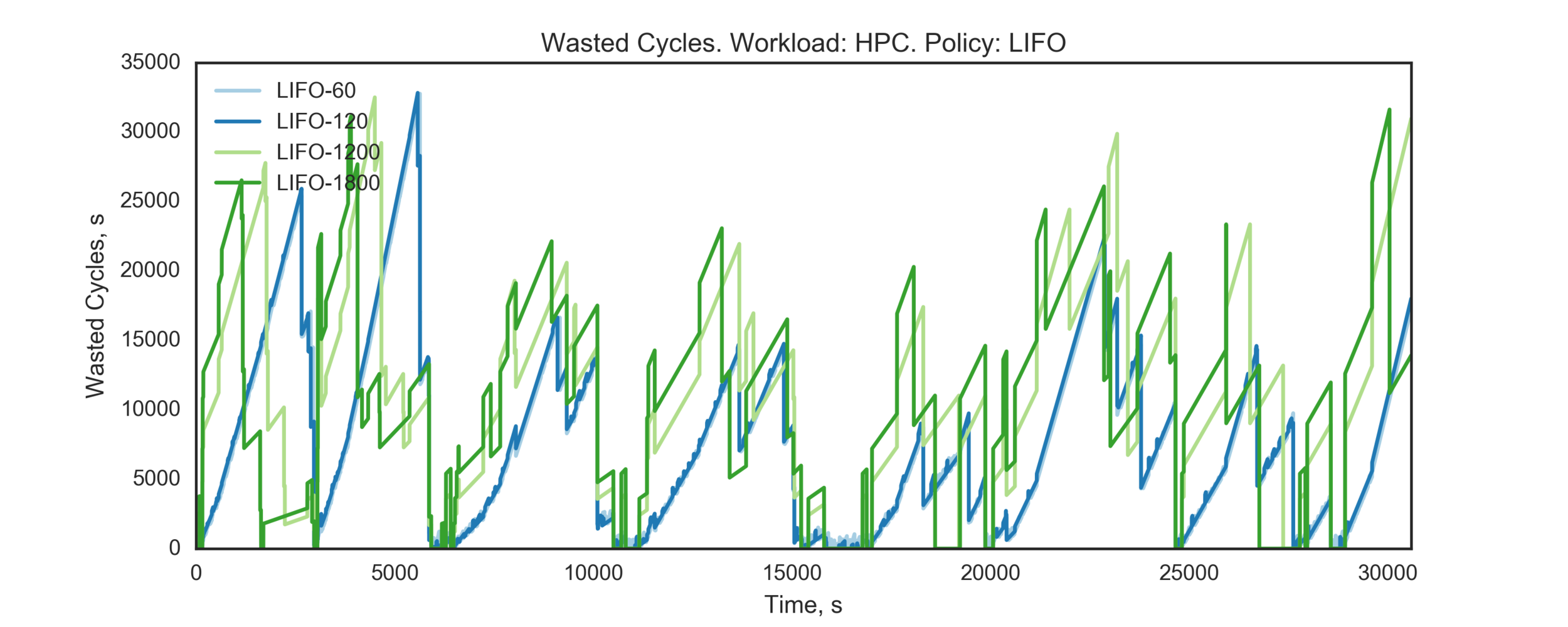
(Experiment directory: yass/preserved/hpc-20161219-131501)
Experiment 2:
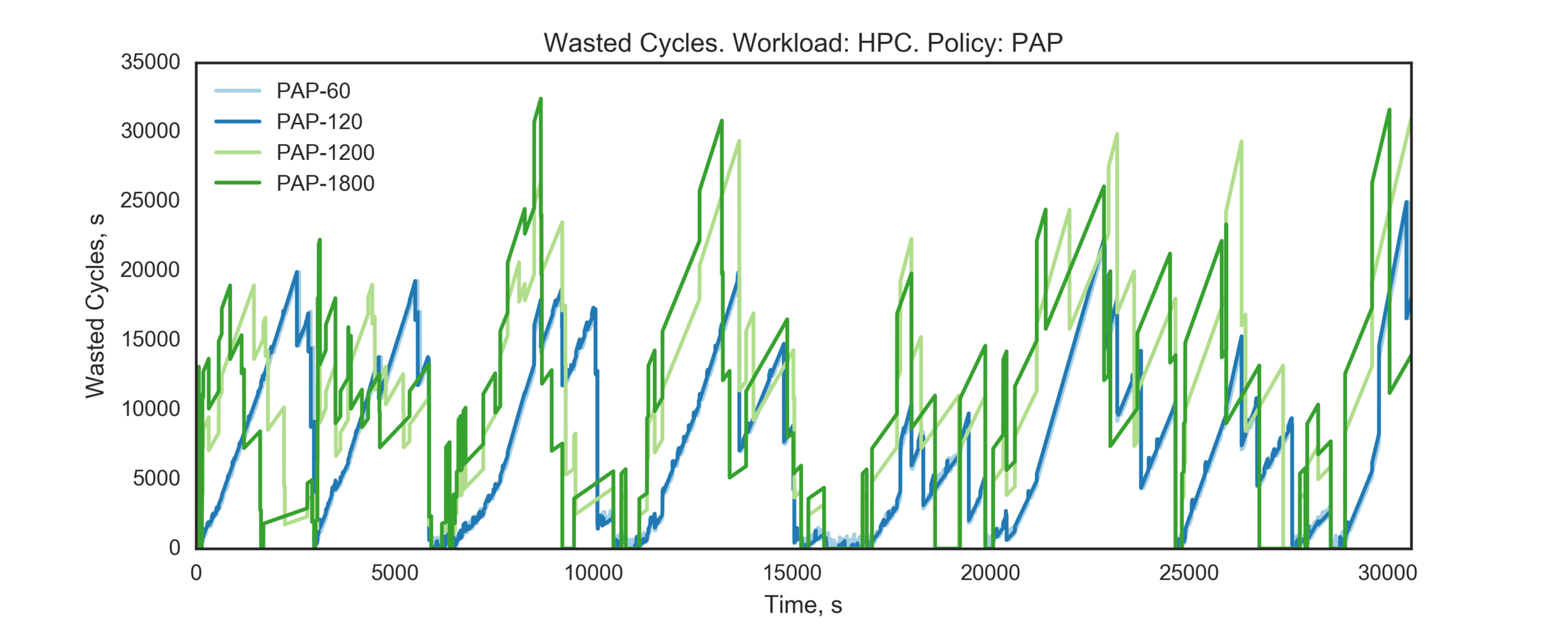
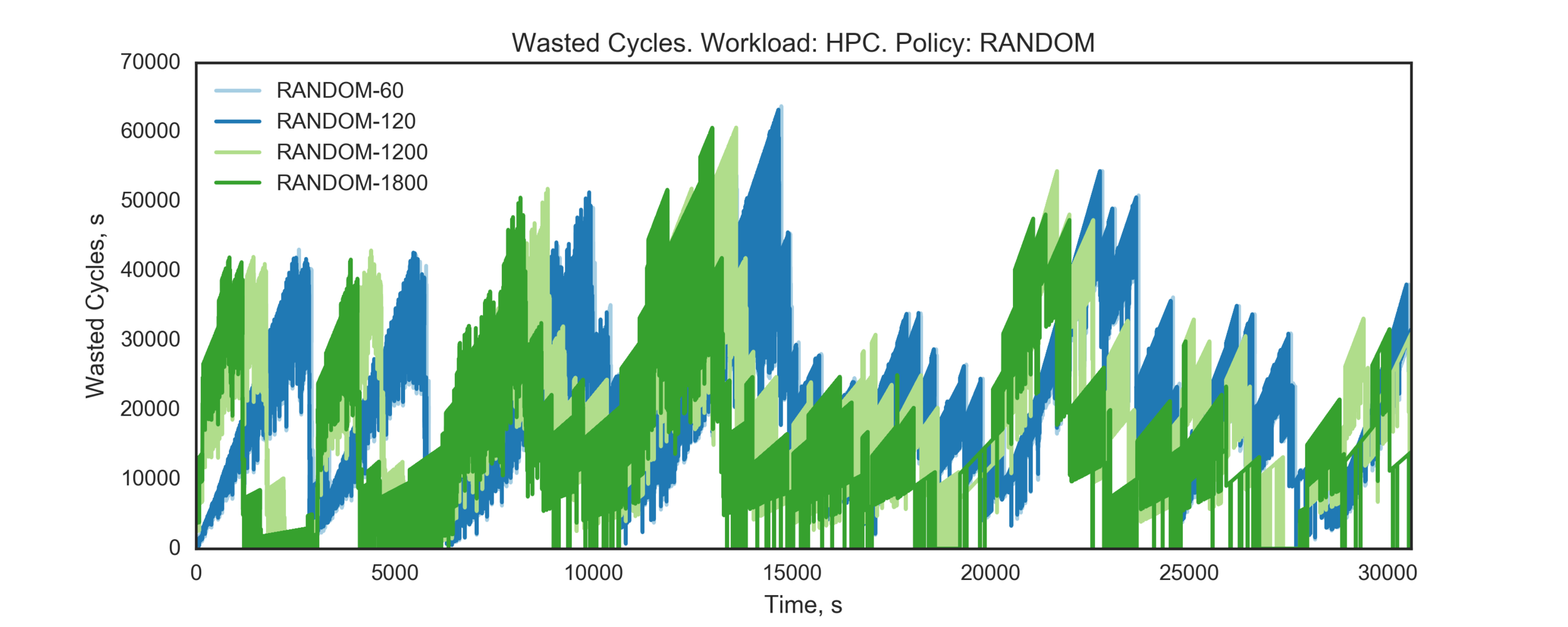
(Experiment directory: yass/preserved/hpc-20161219-131501)
Experiment 2:
Conclusion: need more data (longer simulation)
(Experiment directory: yass/preserved/hpc-20161219-131501)
Experiment 3:
Back to HTC
To run a longer experiment: combine 10 shuffled copies
Simulated time: ~68h on 20 nodes
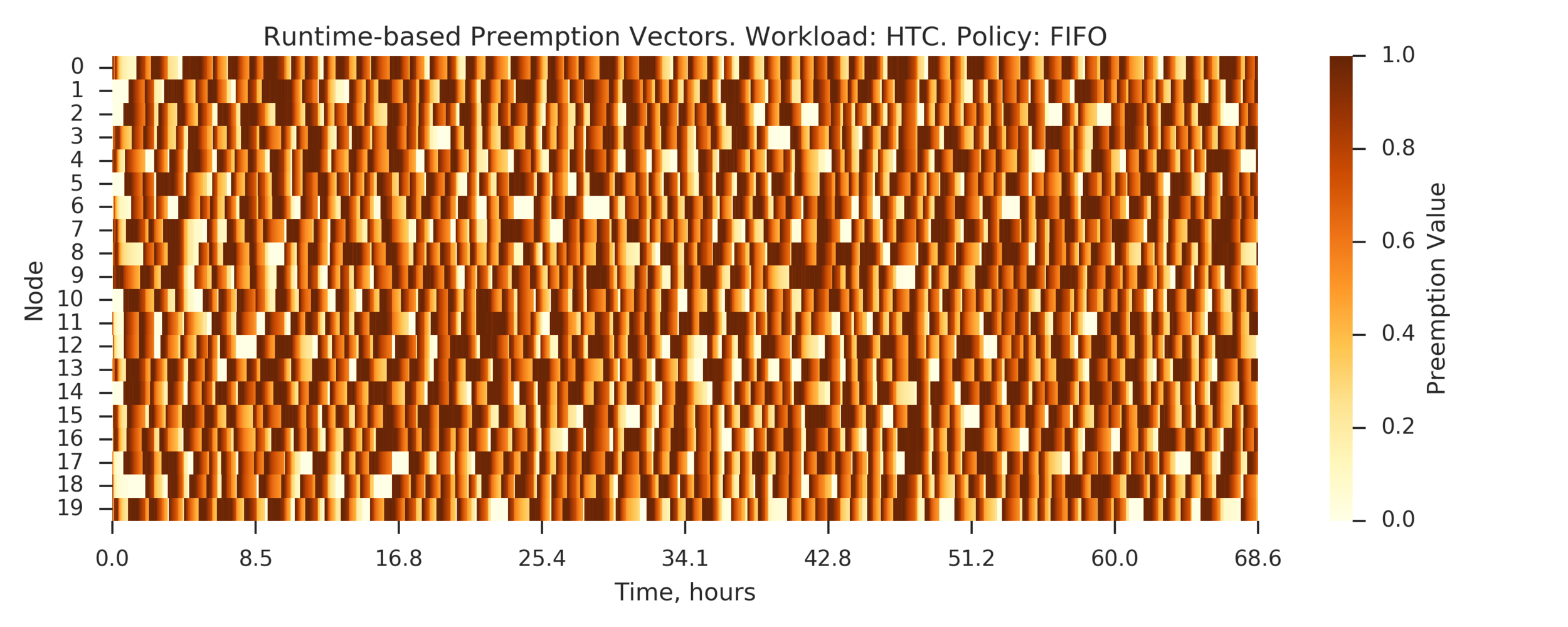
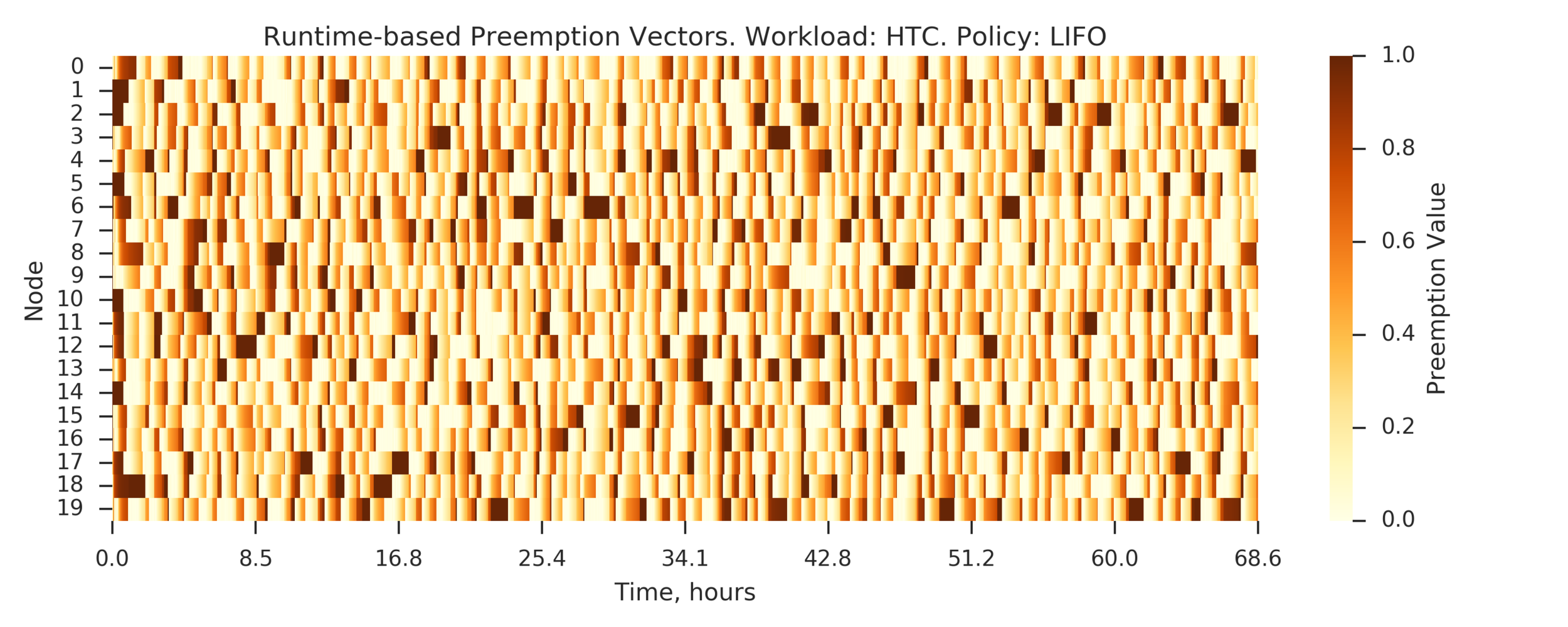
(Experiment directory: yass/preserved/htc-20170106-0958061)
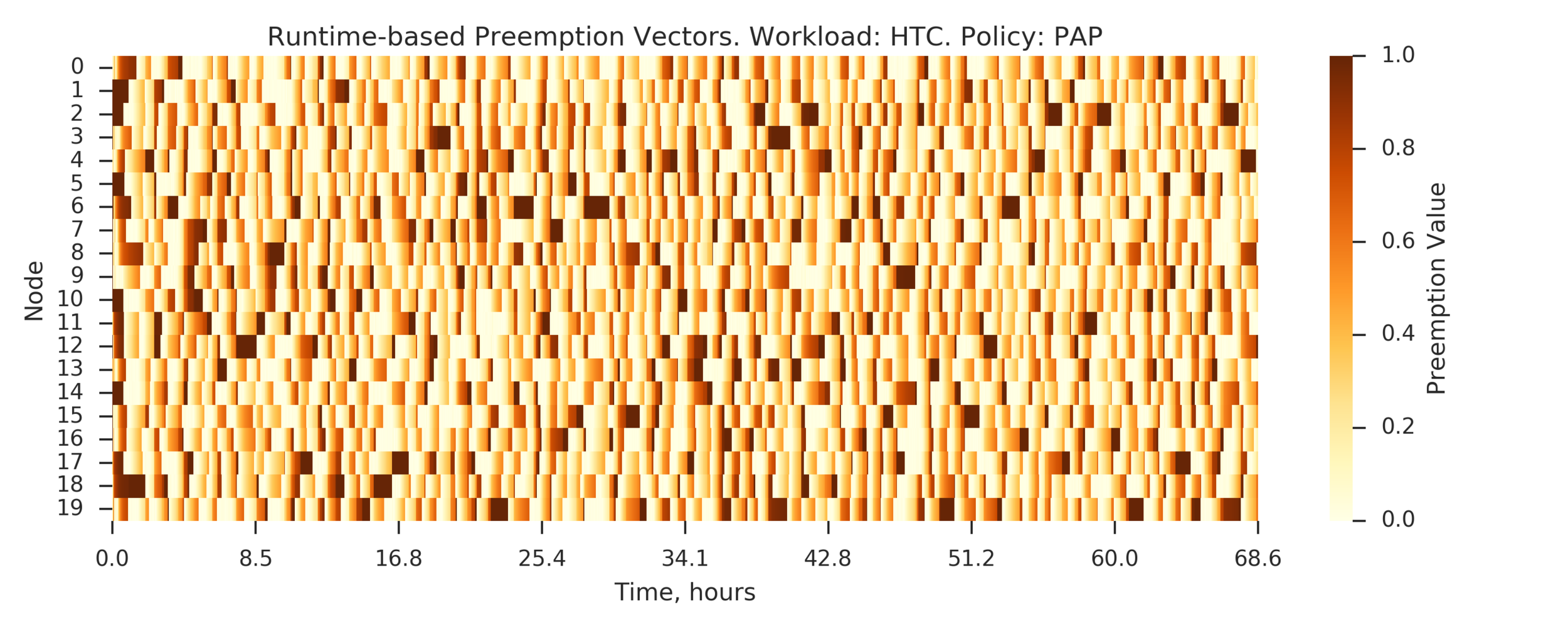
Experiment 3:
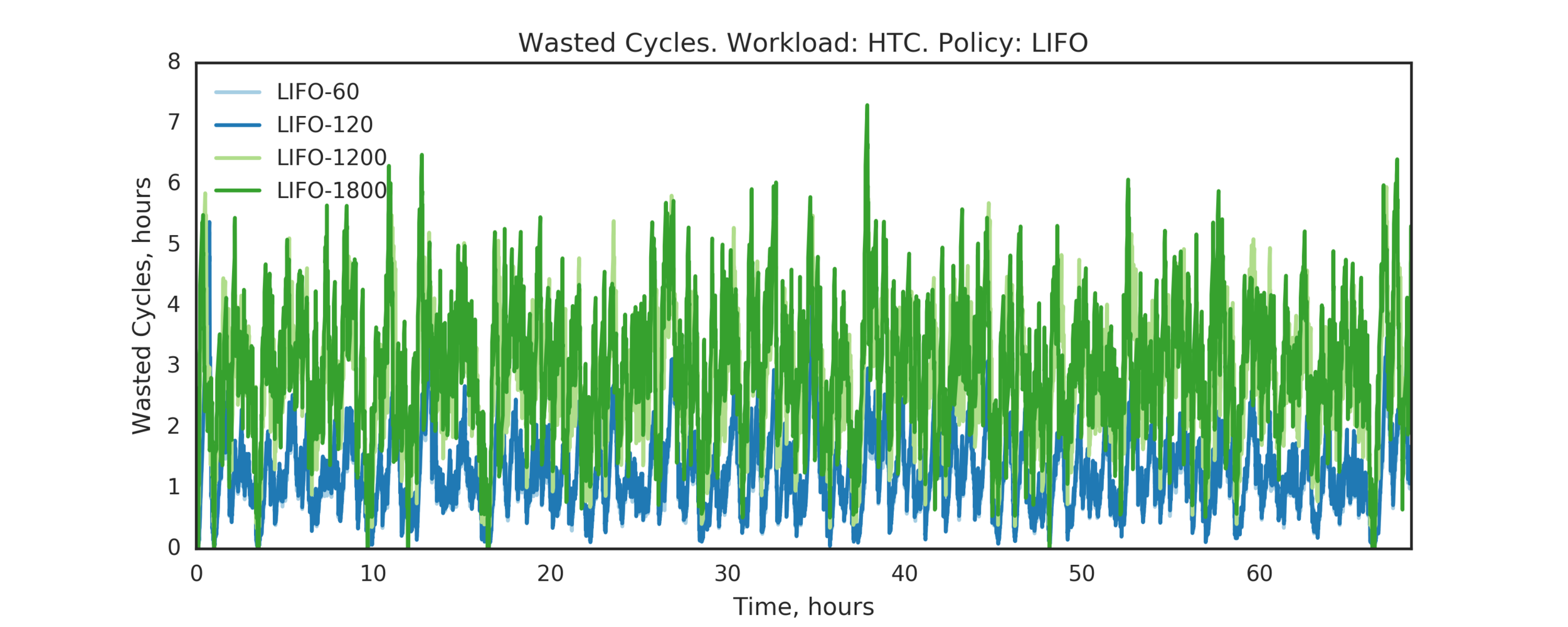
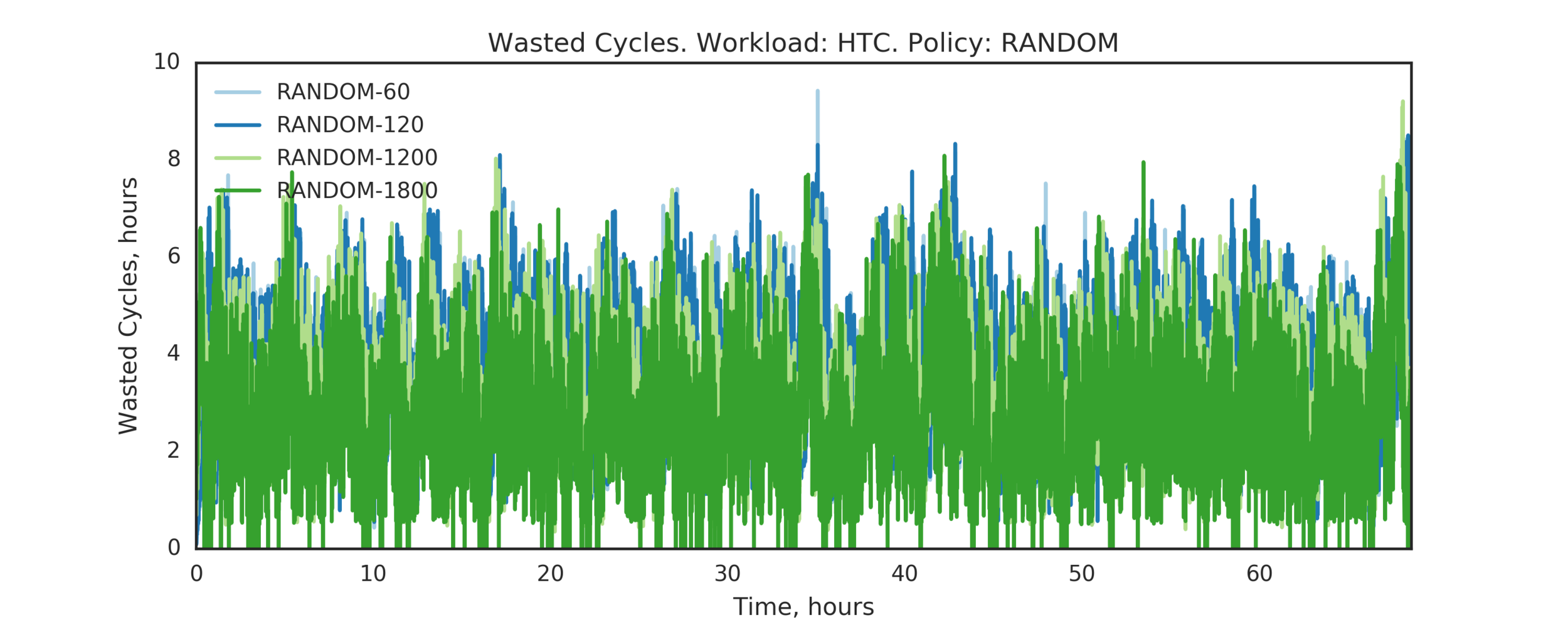
PAP is the same as LIFO
(Experiment directory: yass/preserved/htc-20170106-0958061)
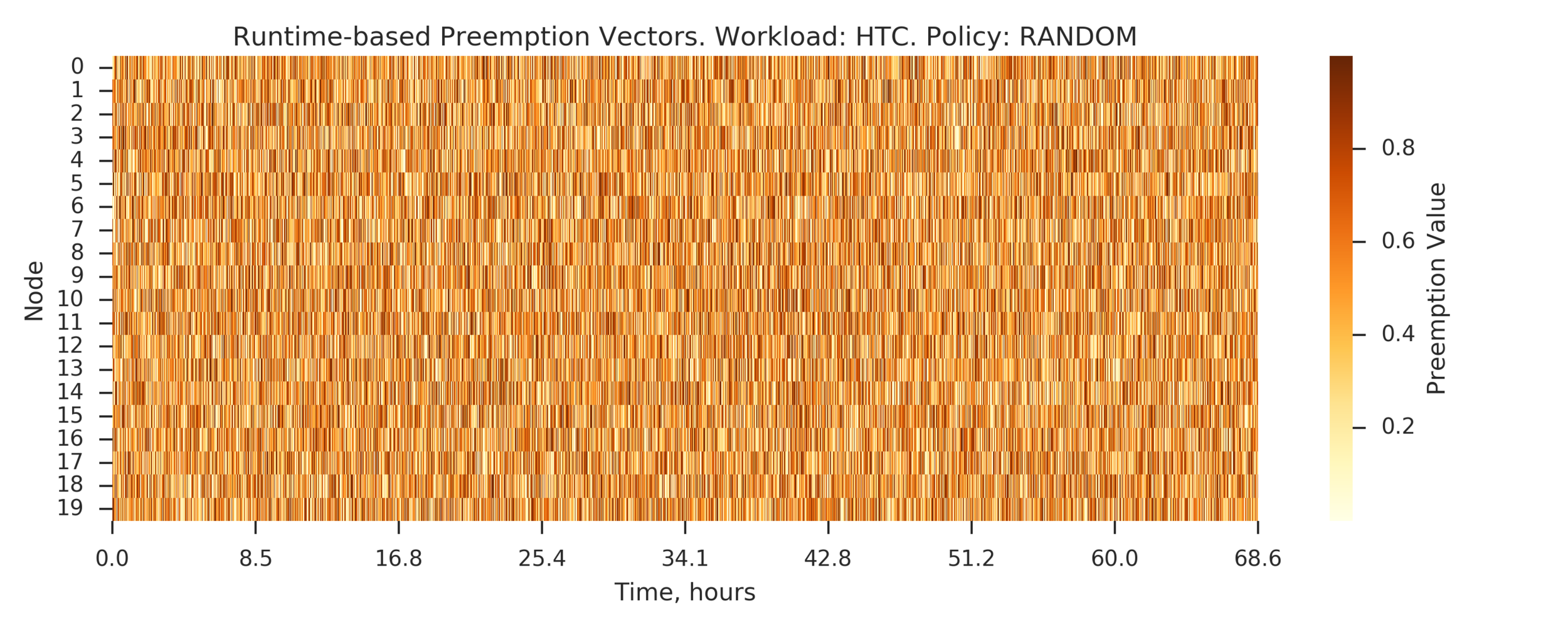
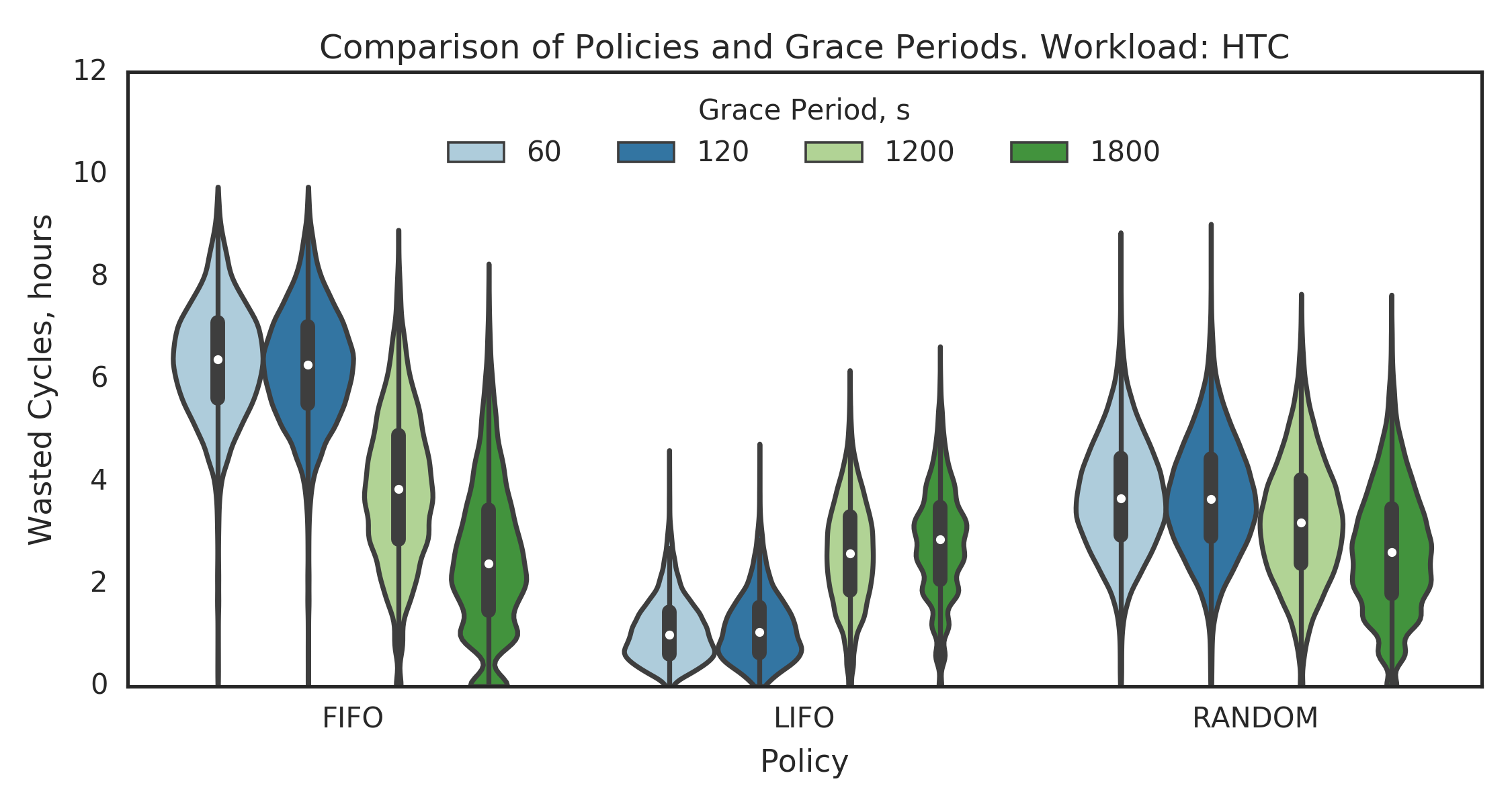
Experiment 3:
(Experiment directory: yass/preserved/htc-20170106-0958061)
Experiment 4:
Simulating full PEREGRINE workload
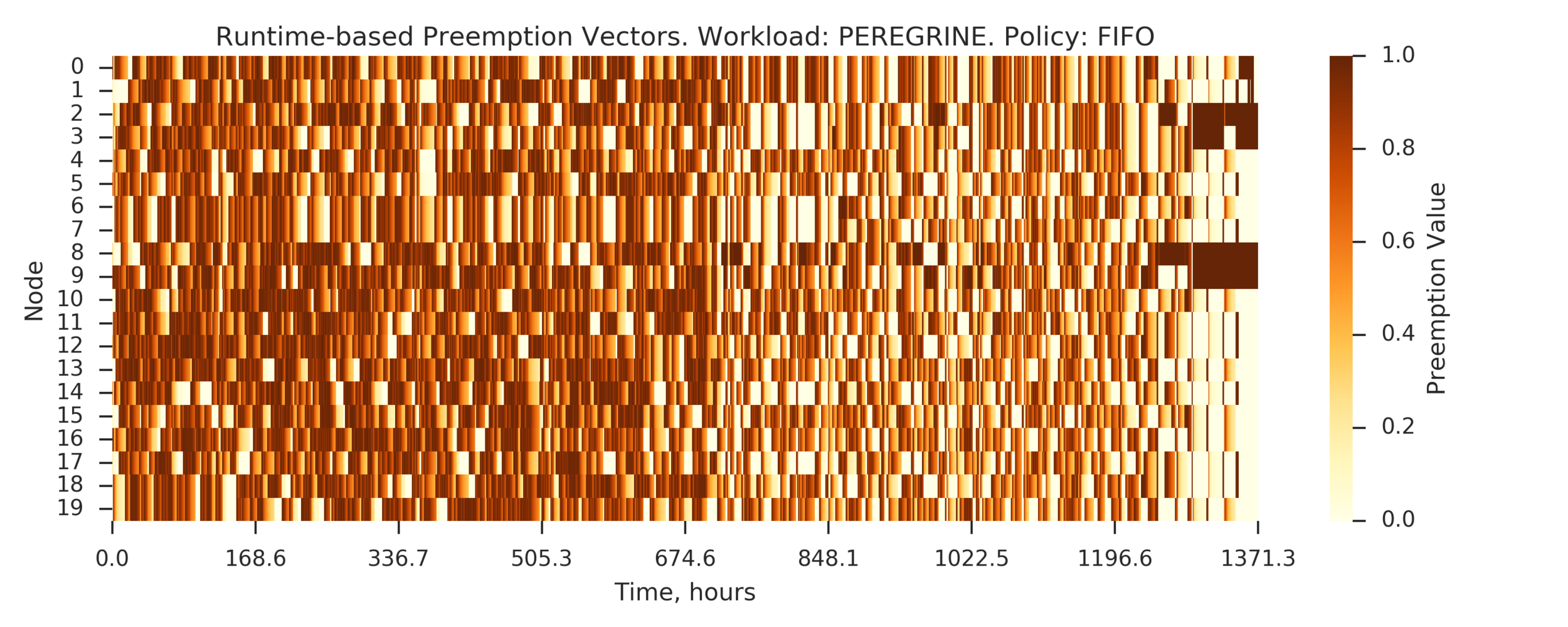
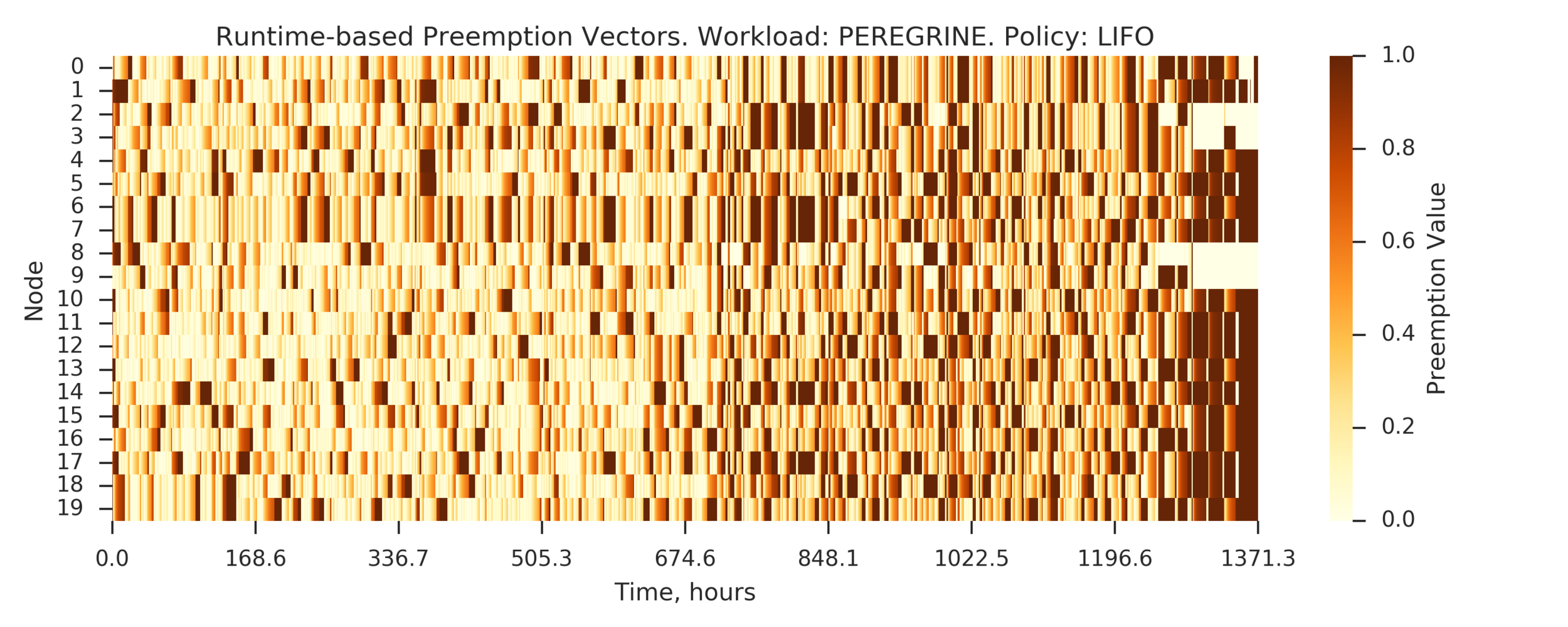
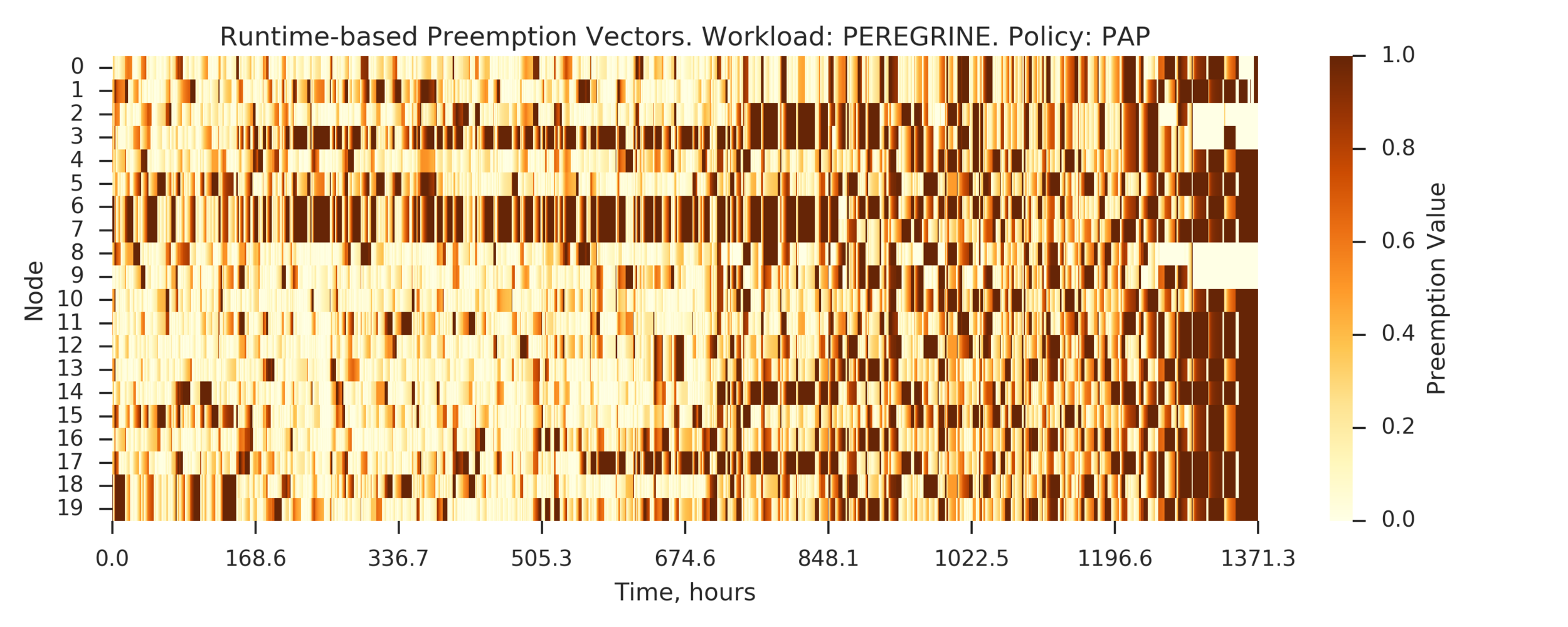
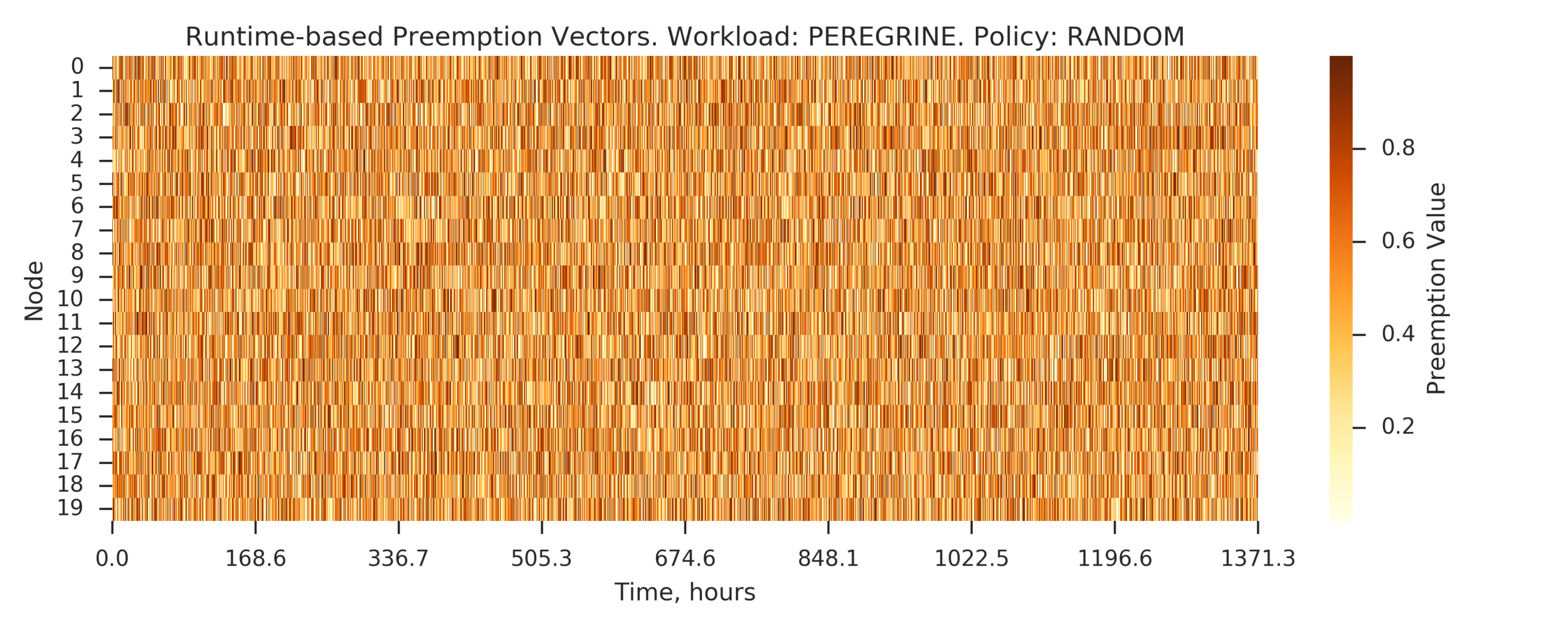
(Experiment directory: yass/preserved/peregrine-20170109-094539)
Experiment 4:
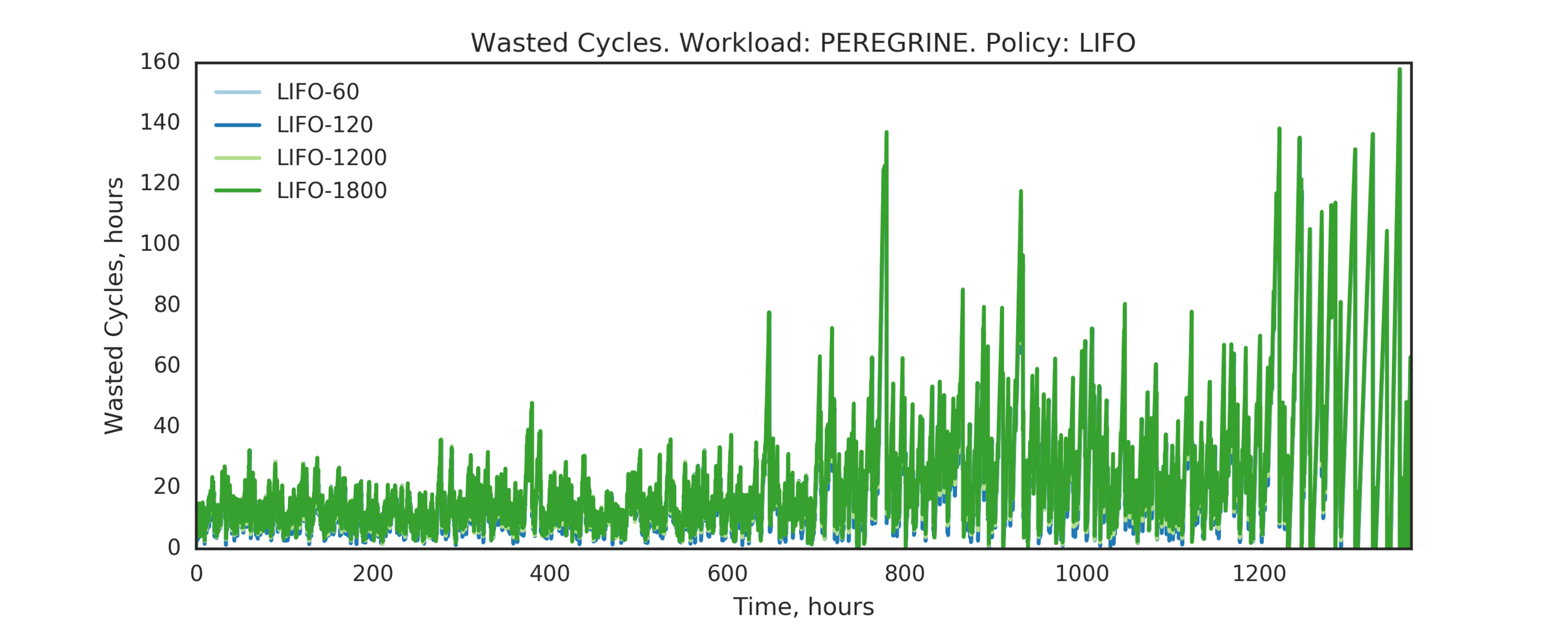
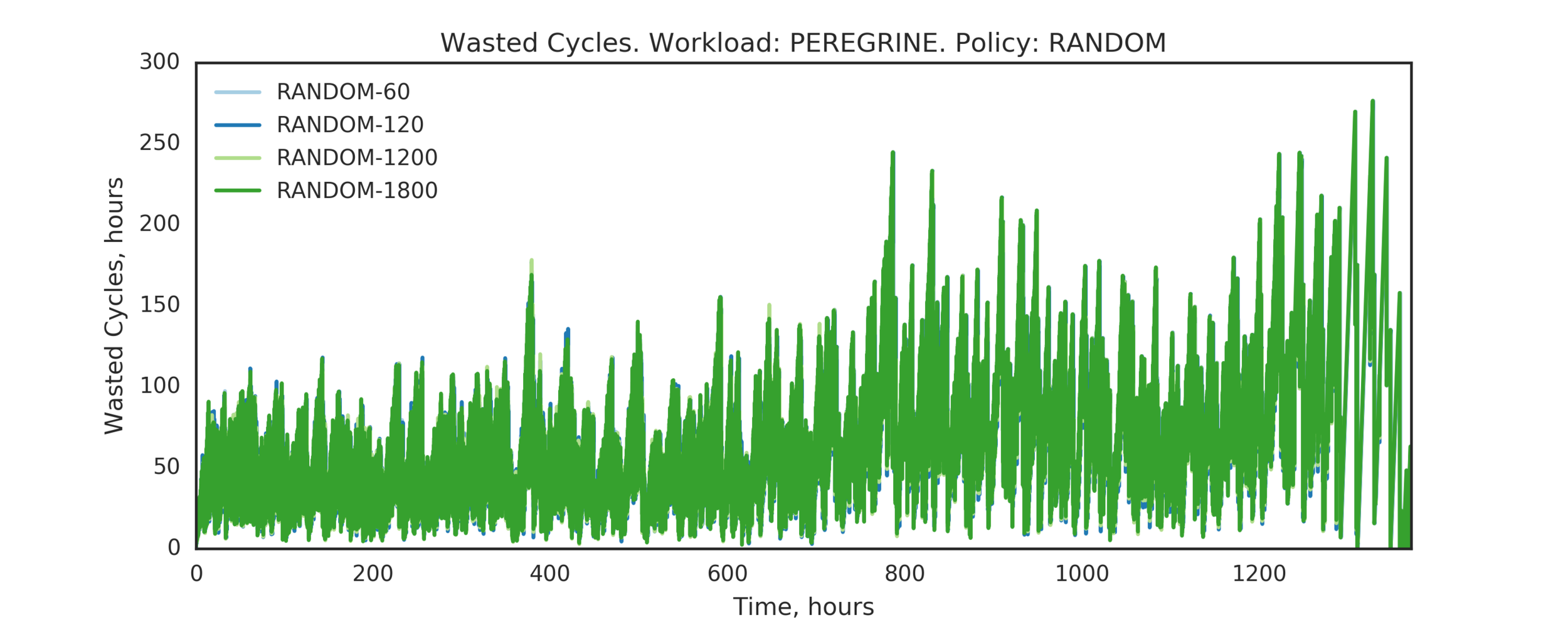
(Experiment directory: yass/preserved/peregrine-20170109-094539)
Observation: GP does not play a significant role
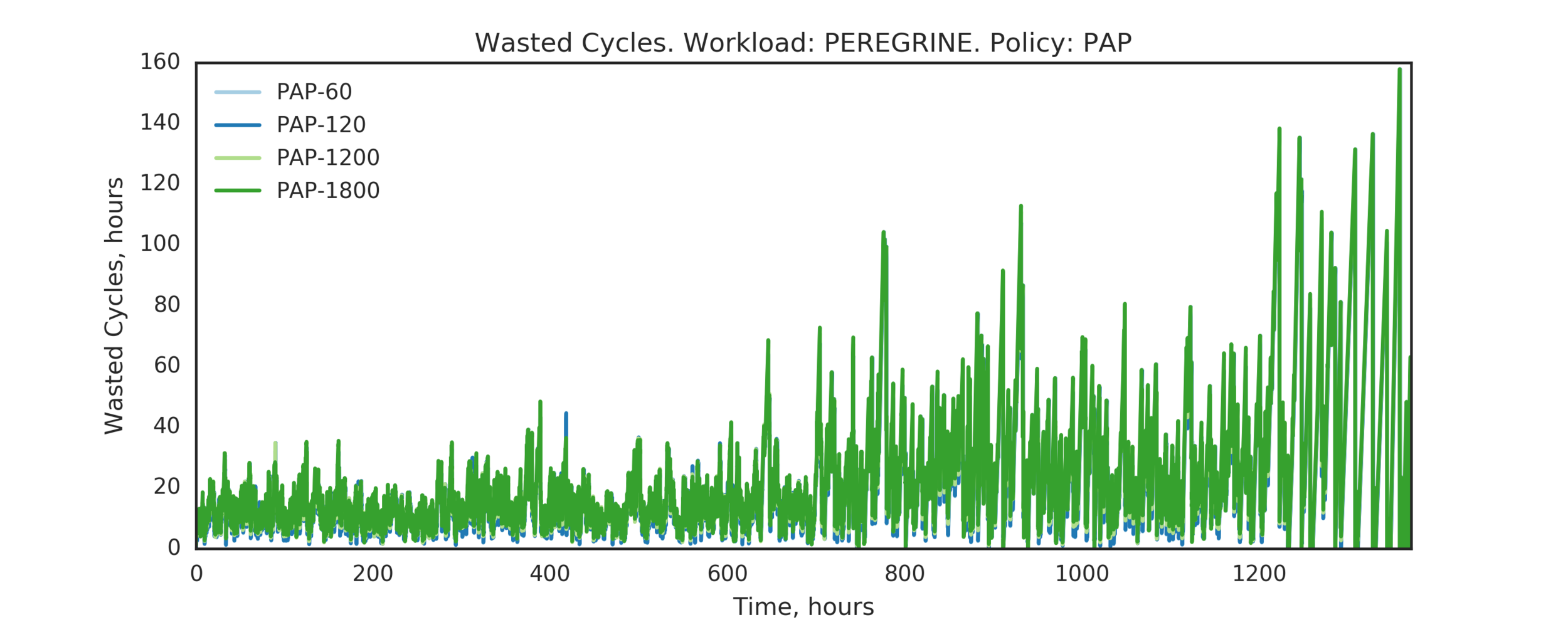
Experiment 4:
(Experiment directory: yass/preserved/peregrine-20170109-094539)
Observation: PAP's performance is the same as LIFO's
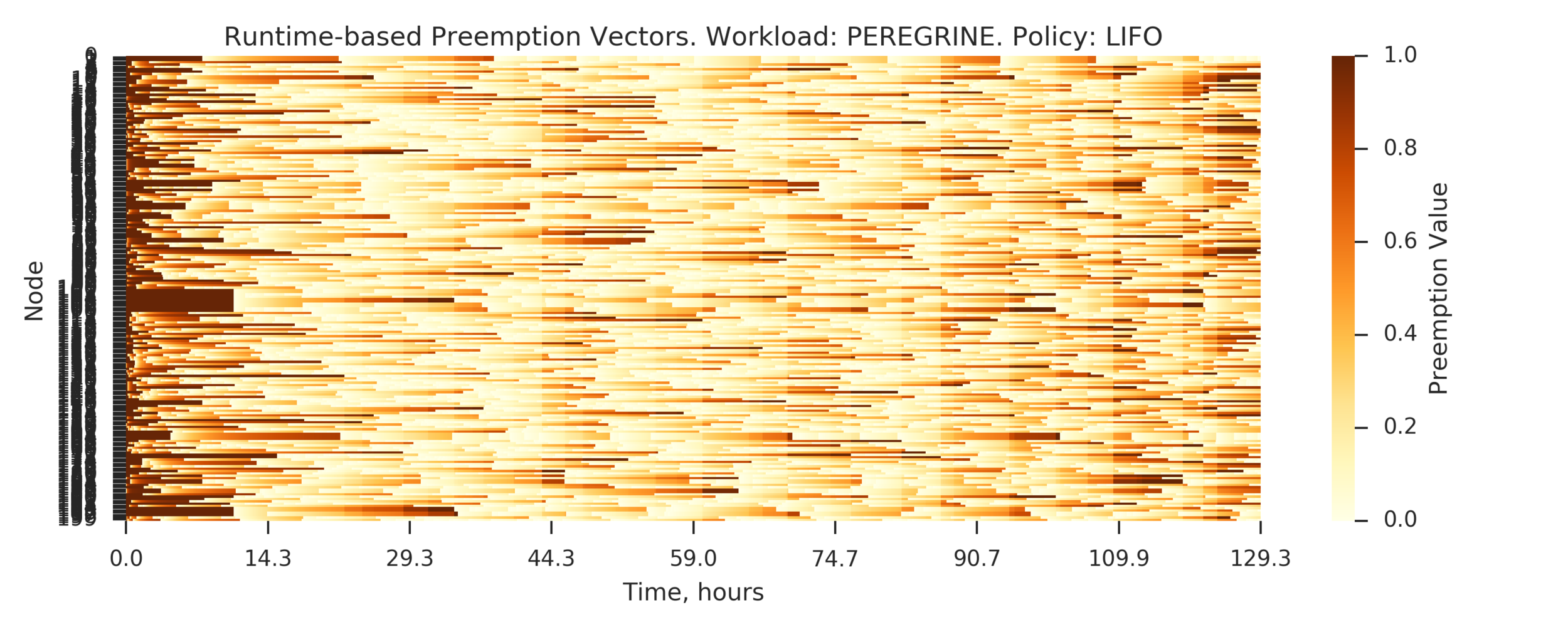
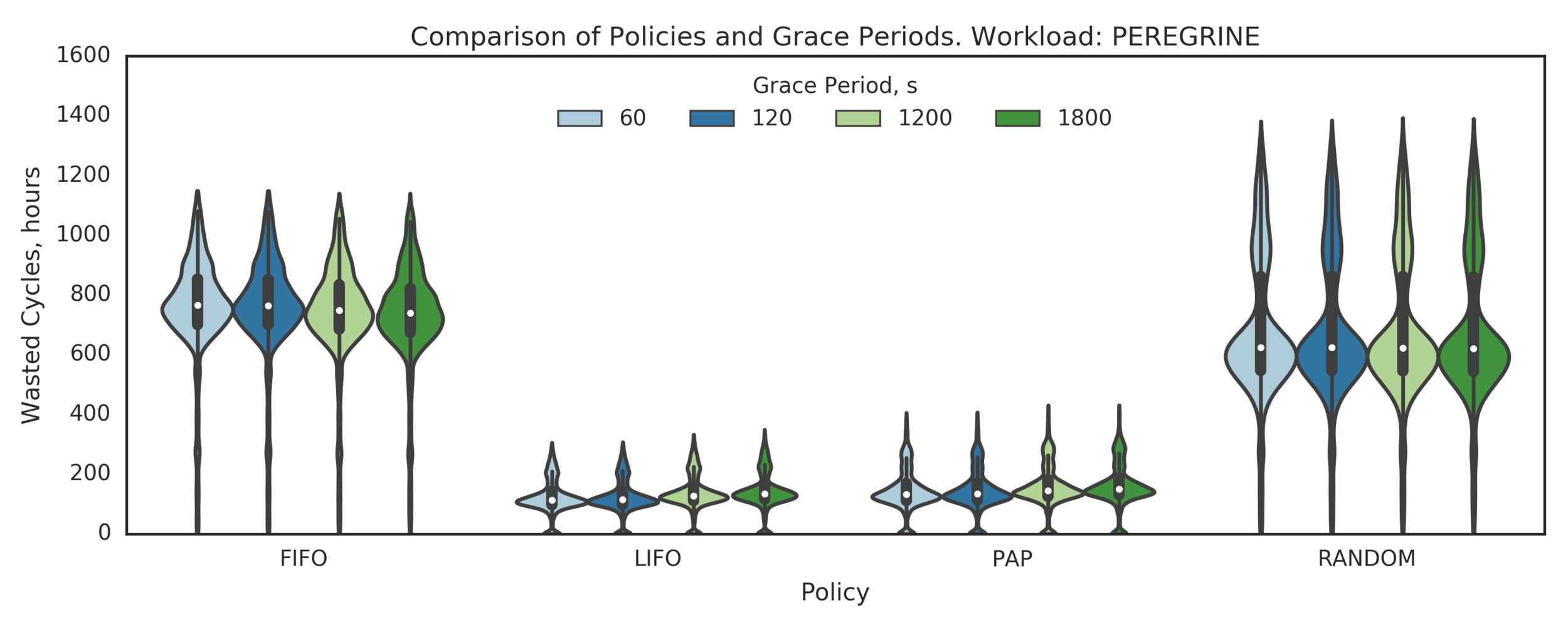
Experiment 5:
Simulating PEREGRINE workload on a larger cluster:
- P=100 nodes preempted from N=200 nodes cluster
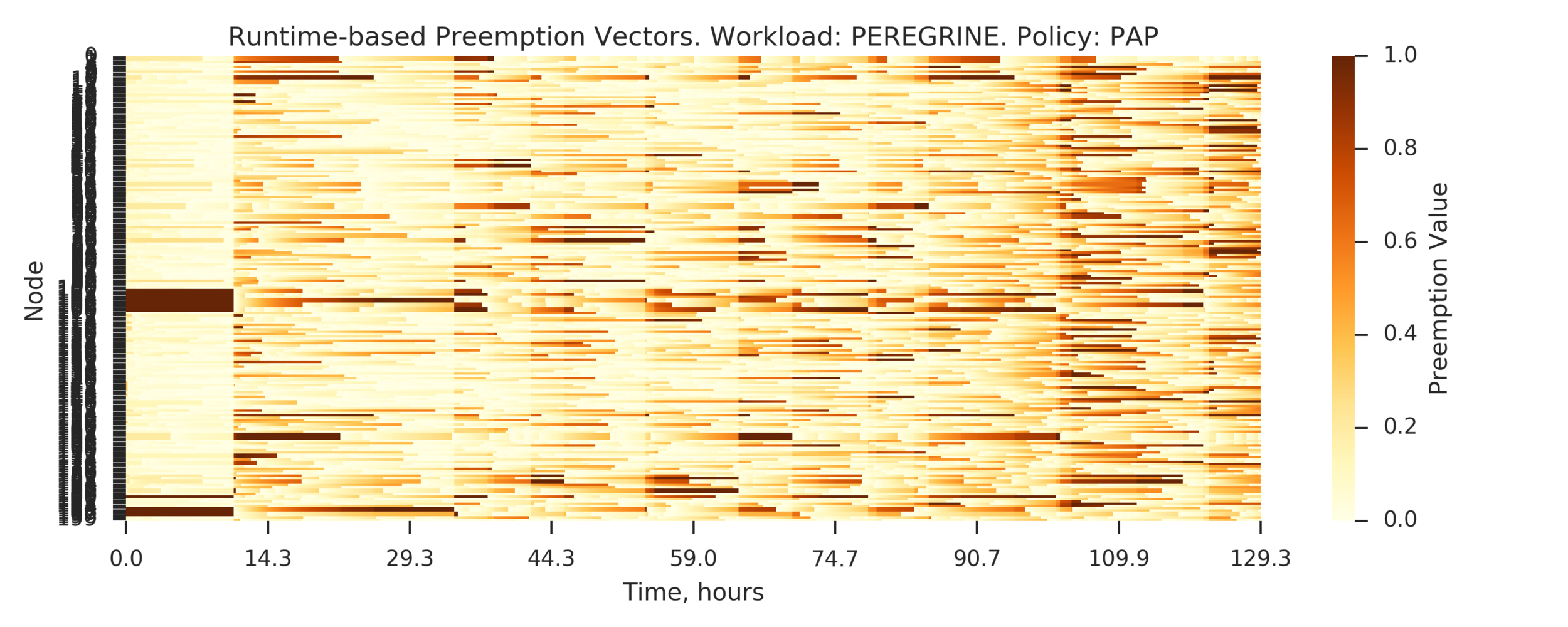
(Experiment directory: yass/preserved/peregrine-20170112-114539)
Experiment 5:
(Experiment directory: yass/preserved/peregrine-20170112-114539)
Experiment 5:
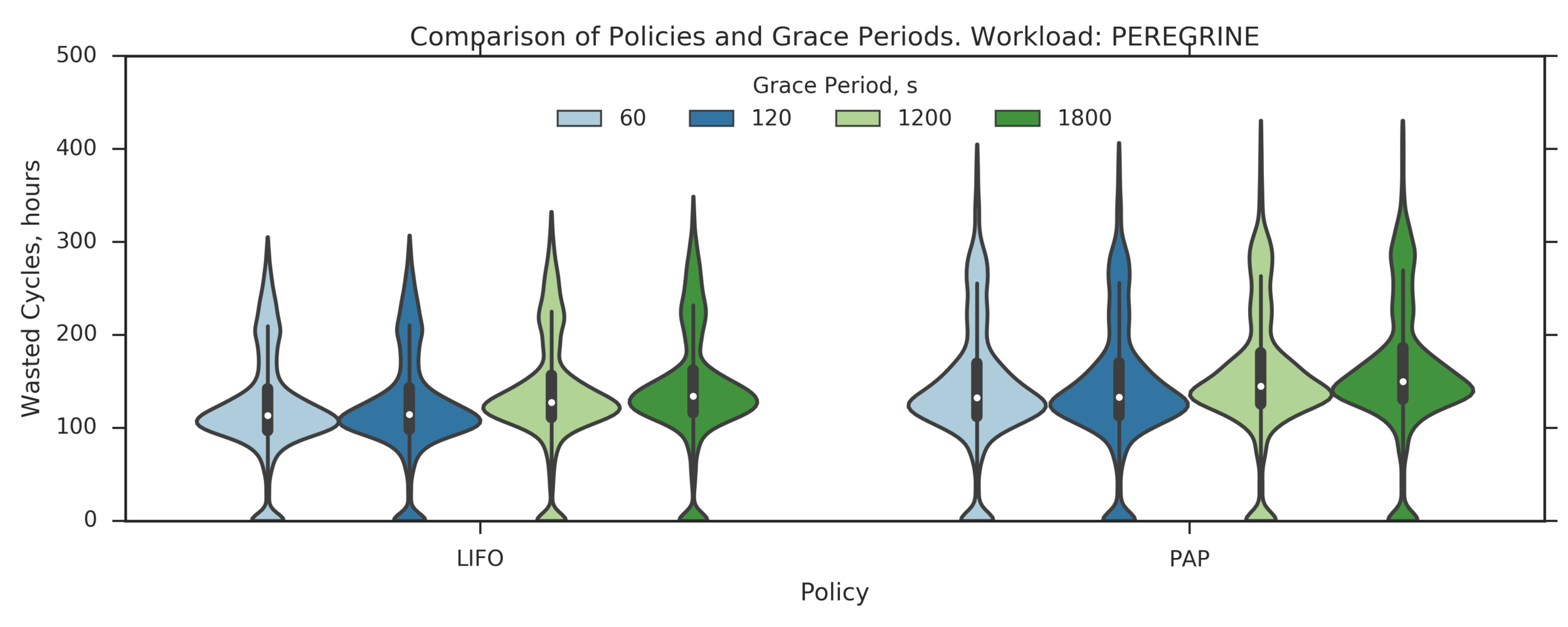
(Experiment directory: yass/preserved/peregrine-20170112-114539)
Observation: PAP performs slightly worse than LIFO
Example of a scenario where PAP makes worse decision than LIFO
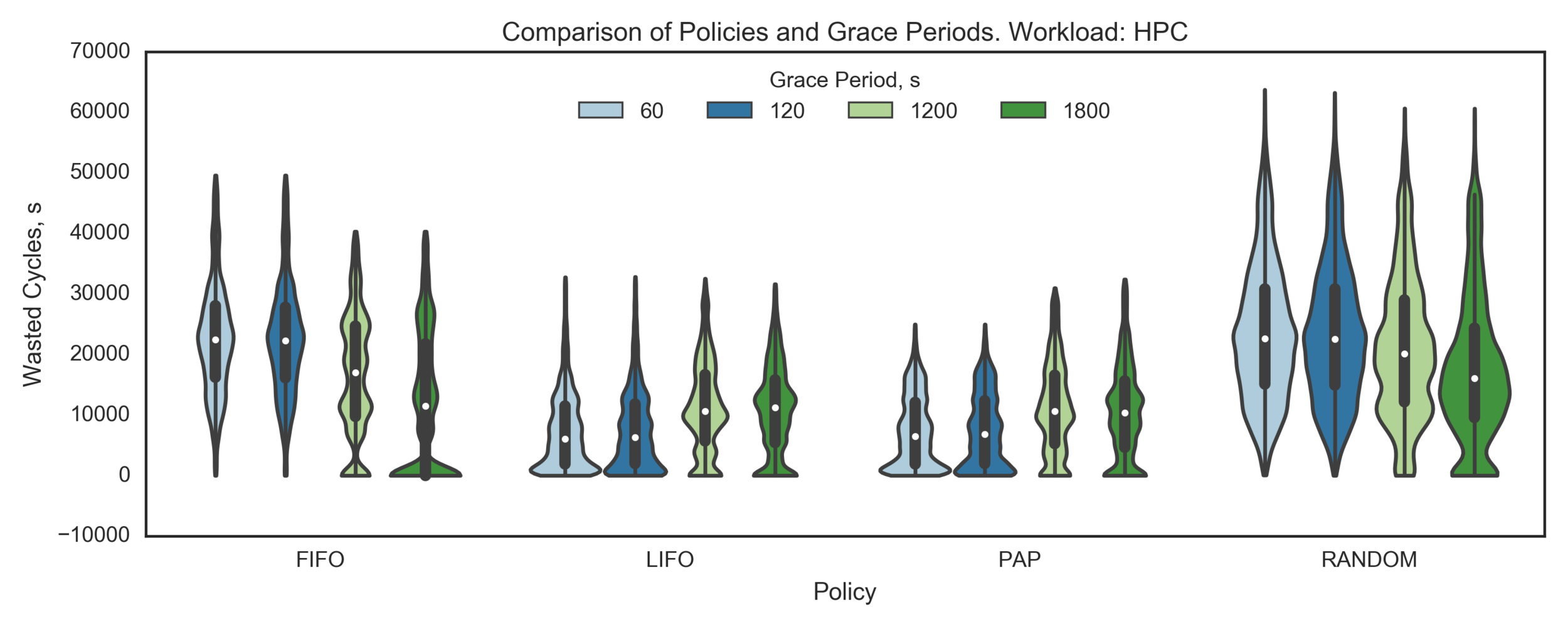
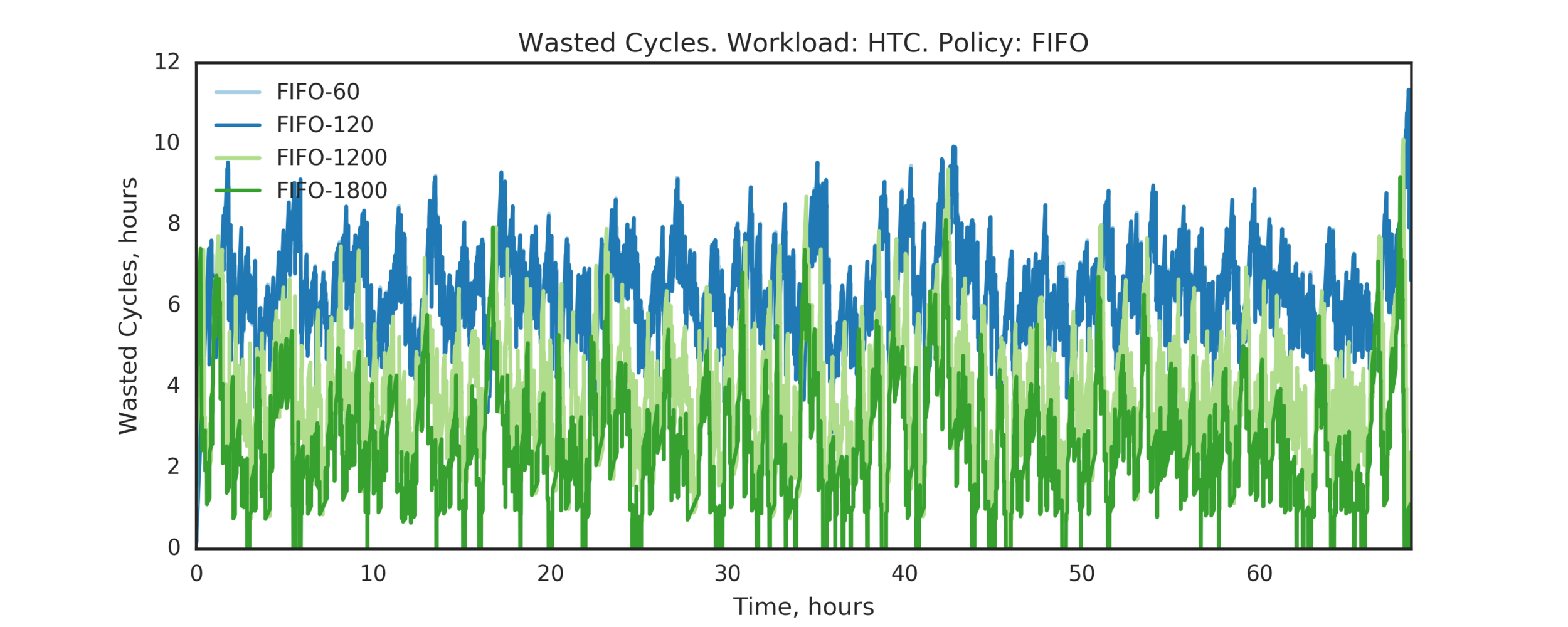
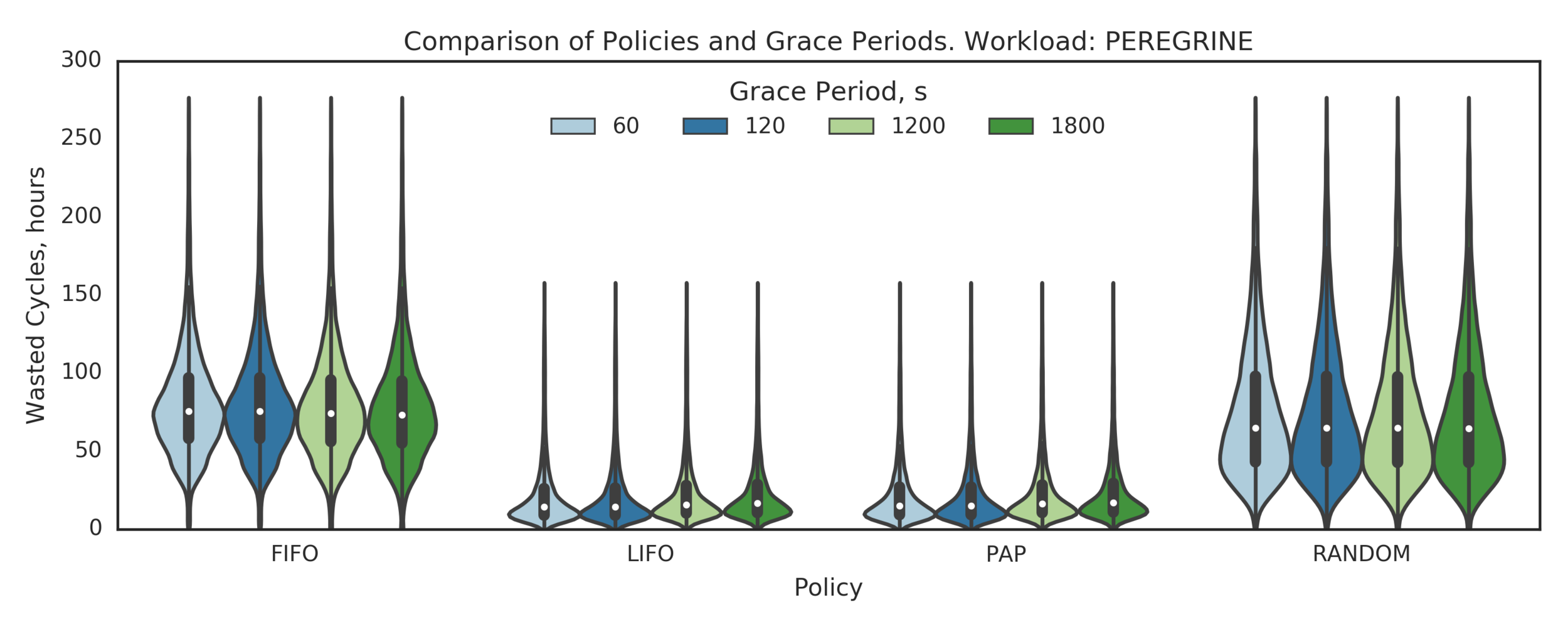
Summary:
HTC:
- LIFO provides significant reductions in WC comparing to FIFO and RANDOM
- LIFO’s GP=60s and GP=120s statistically perform better than the larger GPs
PEREGRINE (HPC):
- LIFO and PAP are much better than FIFO and RANDOM
- LIFO and PAP are almost equivalent, LIFO might be slightly better
- LIFO’s small GPs are the same or slightly better than larger GPs
One more thought:
Maybe preemption policies should consider wall clock times requested by users?
The accuracy of such estimates is extremely low:
for PEREGRINE, for over 50% of the jobs the requested wall clock exceeds the actual wall clock by the factor of 19.2.
In the "HPC System Lifetime Story..." paper on the analysis of NERSC HPC systems,
the authors mention similar level of accuracy:
The wall clock accuracy is calculated as real/estimated wall clock time....
For Carver... In 2014, the median is under 0.1 and the last quartile it is under 0.2.
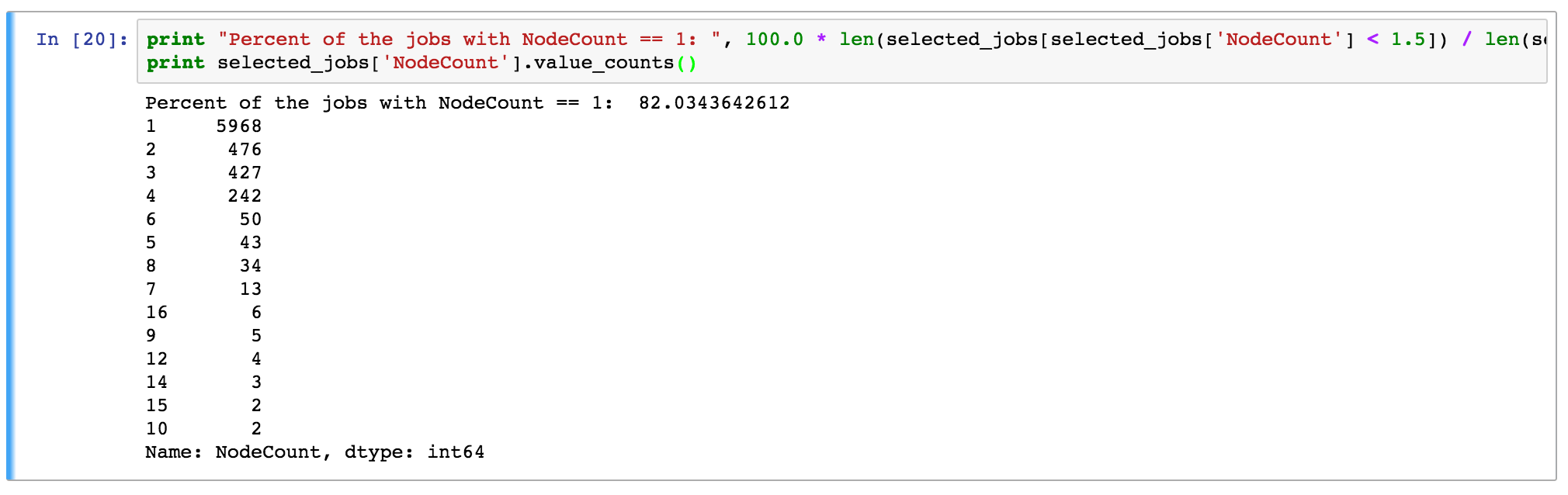
Additional Analysis:
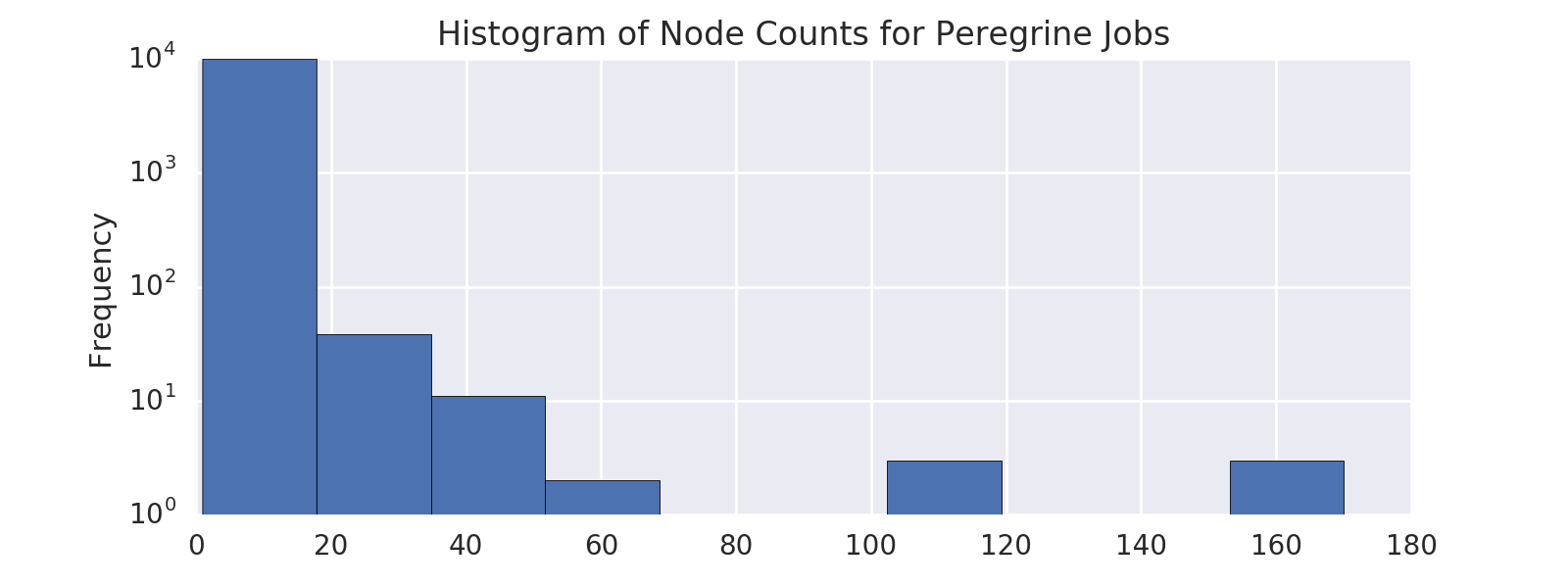
PEREGRINE workload:
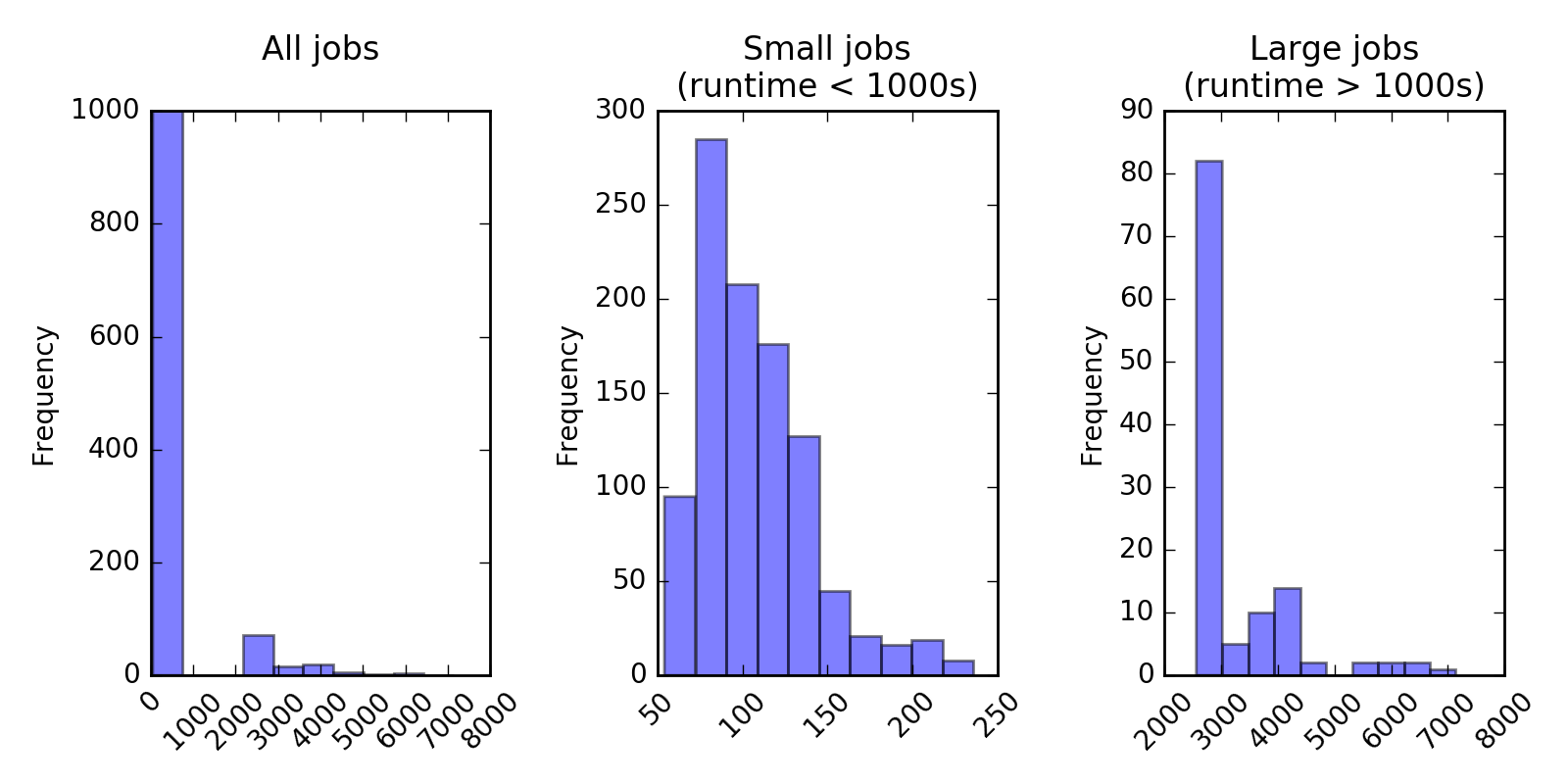
- 82% of jobs use only 1 node
- The remaining 18% represent 1307 jobs
- Breakdown of all 7275 jobs by the number of used nodes is below
(note that jobs with node count > 20 were excluded for our simulation experiments,
as explained on previous slides)
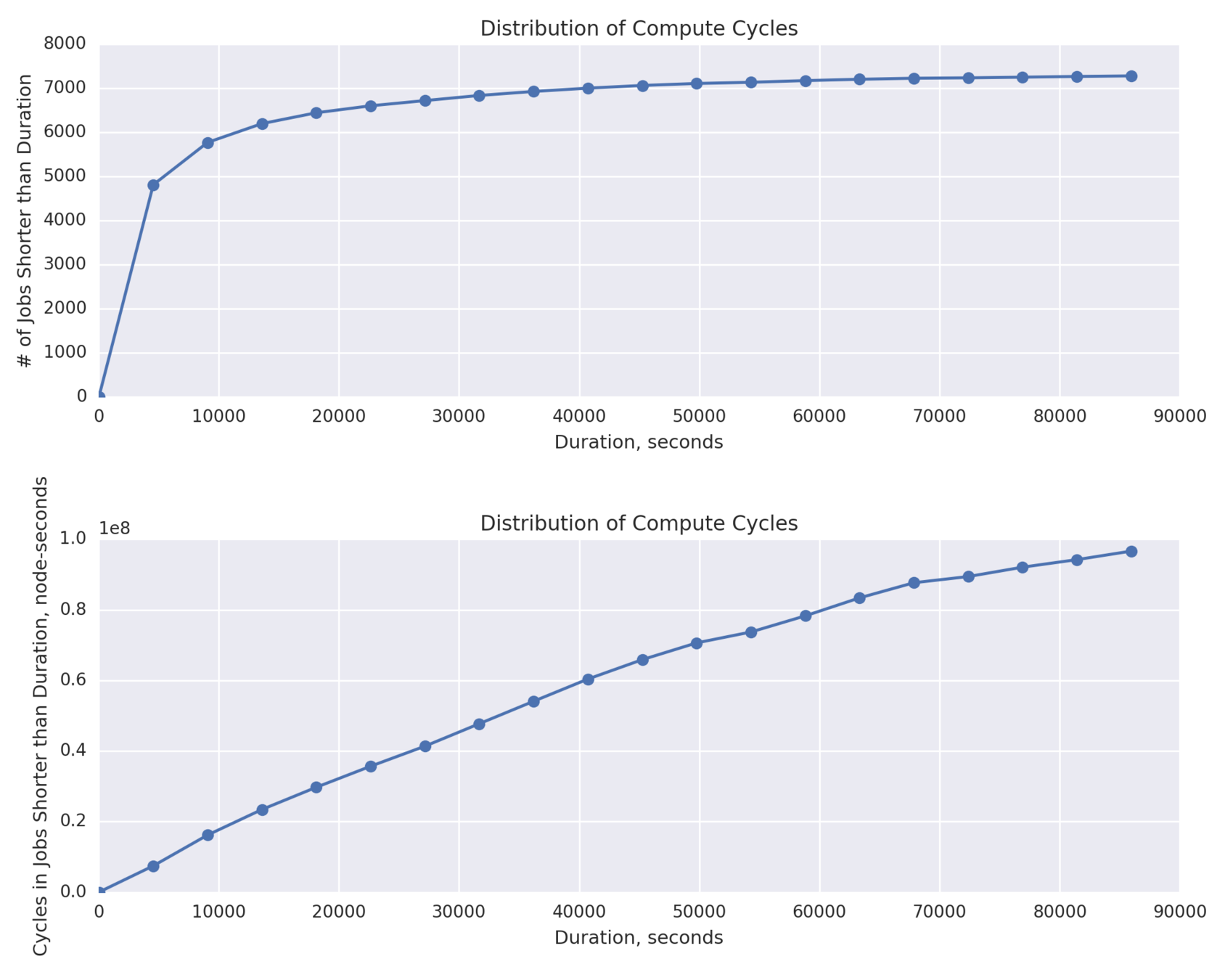
Additional Analysis:
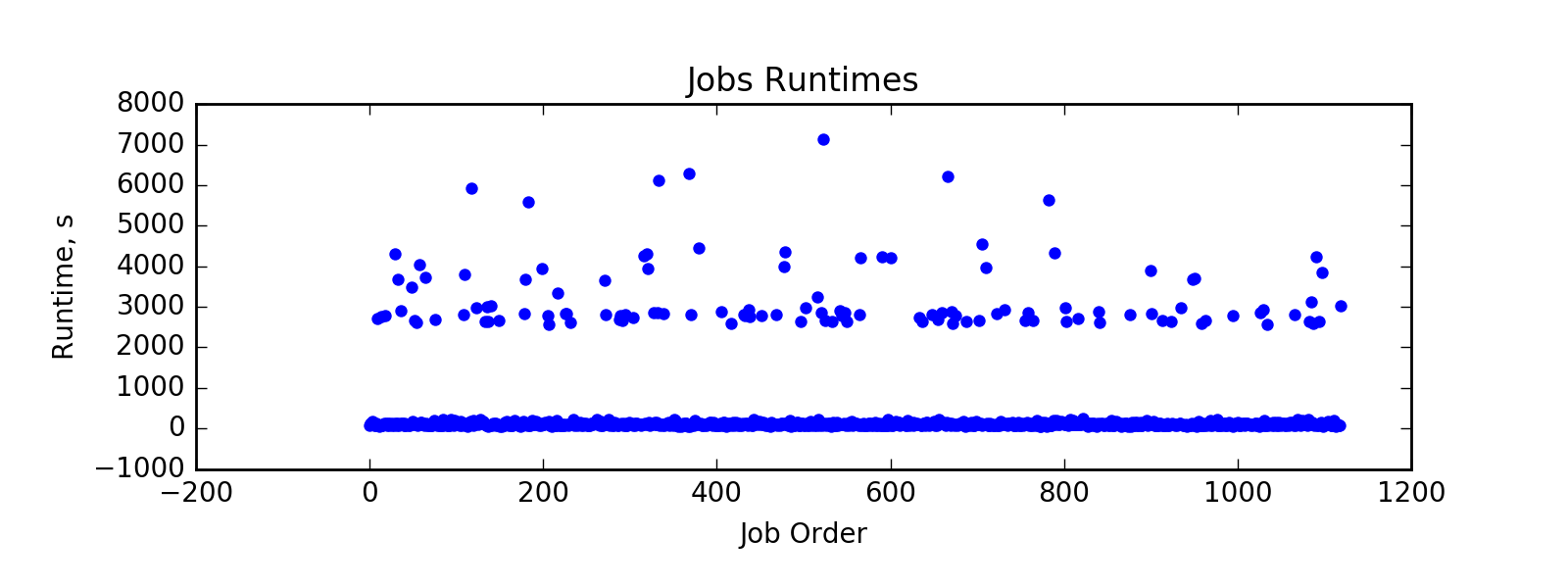
PEREGRINE workload: distribution of 7275 jobs (number and total node-seconds) by job duration
Additional Analysis:
PEREGRINE workload:
Breakdown of jobs by queue:
batch 6047
short 922
debug 143
bigmem 76
long 44
phi 42
large 1
Name: queue, dtype: int64
Proposal: treat 76 bigmem jobs (~1% of total number) as high priority jobs
Goal: improve PAP policy so it minimizes WC across all jobs and also tries to
preserve high-priority jobs (i.e. reduce WC for high-priority jobs when possible)
Additional Analysis:
Implementation:
PAP policy:
preemption_vector = scale(job_runtime * job_nodecount),
where scale() converts vector values to the [0,1] range
New PAP+ policy:
preemption_vector = scale(job_runtime * job_nodecount * job_priority)
Proposed Experiment:
- Assign job_priority = 10.0 (high) to high priority jobs (76 from the bigmem queue)
- Assign job_priority = 1.0 (default) to the rest of the jobs
- PAP+ can easily support many (more than 2) job priority classes with arbitrary, user/administrator defined priority coefficients
Additional Analysis:
Comparing PAP and PAP+ based on WC for default- and high-priority jobs
Selected metric: cumulative WC, summed across all samples recorded during the simulation of entire PEREGRINE workload
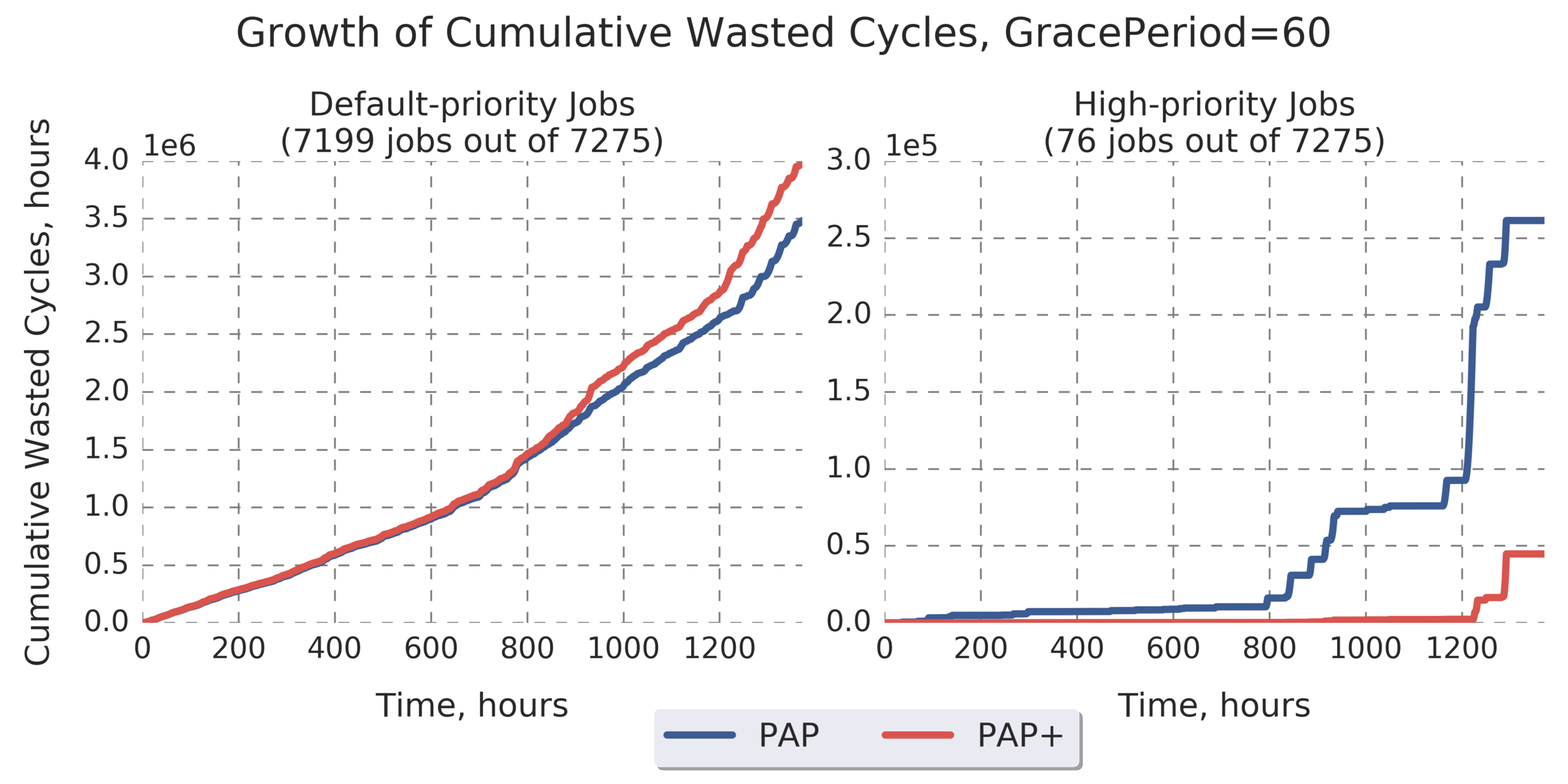
(Experiment directory: yass/preserved/peregrine-20170126-105500)
Additional Analysis:
Judging by the cumulative WC at the end of experiment:
- PAP+ reduces WC for high-priority jobs by 82.9% comparing to PAP (right graph).
- This happens at the expense of default-priority jobs; WC for those jobs increases by 14.3% with PAP+ comparing to PAP (left graph).
- We can't always reduce WC for high-priority jobs to 0 (there will be moments when multiple high-priority jobs run at the same time and some of them may need to be terminated)
(Experiment directory: yass/preserved/peregrine-20170126-105500)
Additional Analysis:
Results for the rest of the Grace Period values look similar:
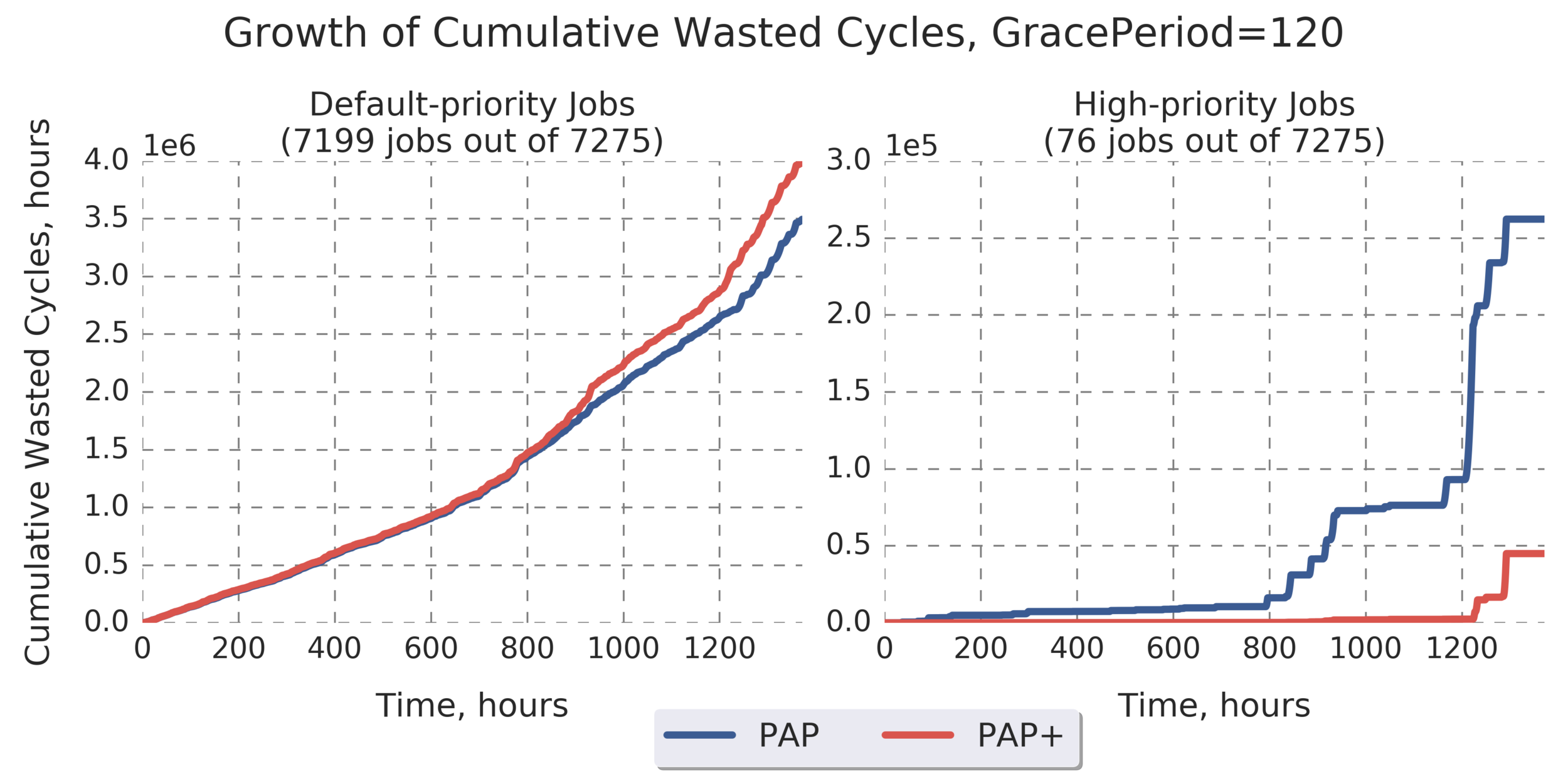
(more graphs below)
(Experiment directory: yass/preserved/peregrine-20170126-105500)
Additional Analysis:
(more graphs below)
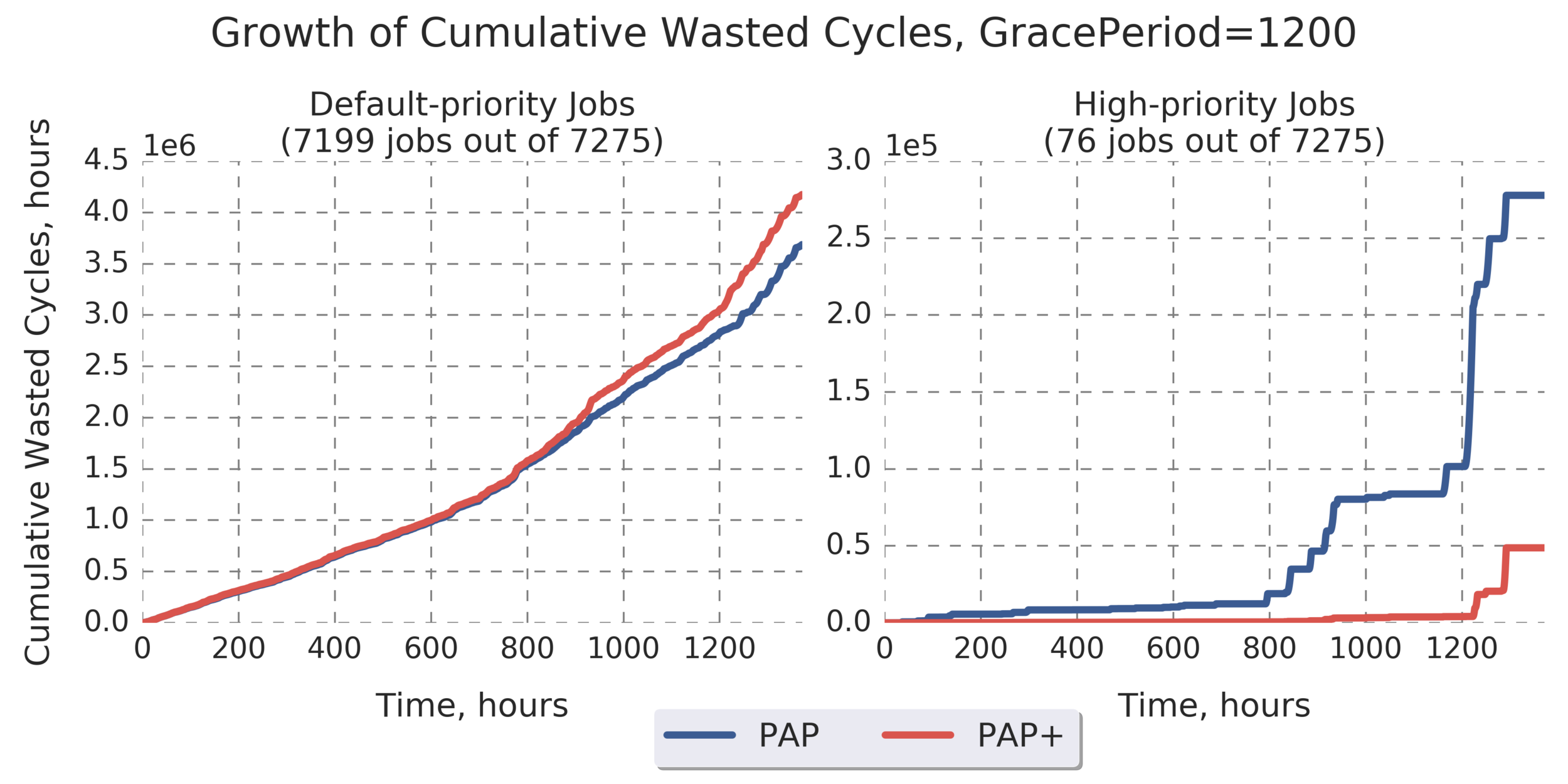
(Experiment directory: yass/preserved/peregrine-20170126-105500)
Additional Analysis:
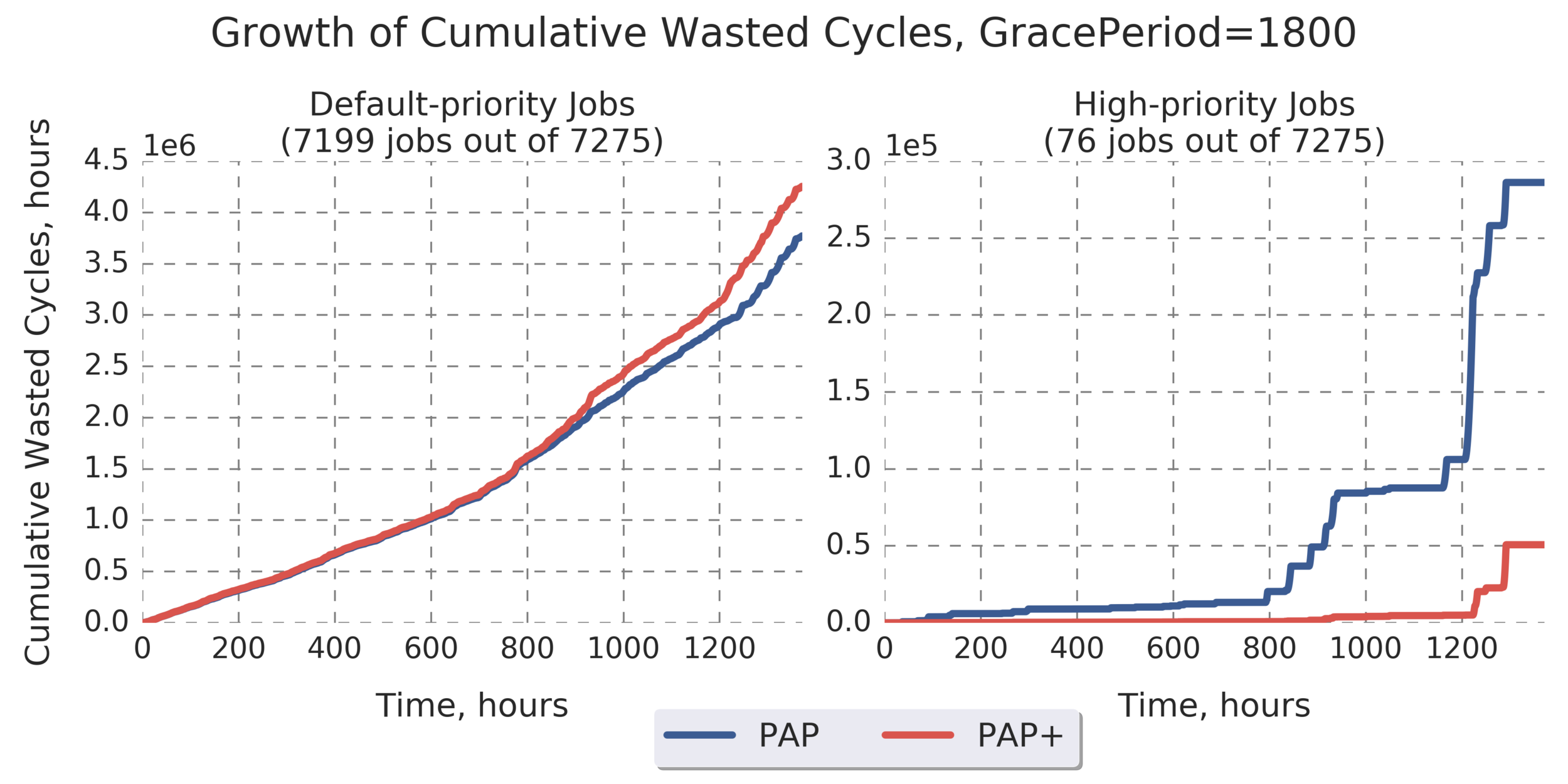
(Experiment directory: yass/preserved/peregrine-20170126-105500)
Additional Analysis:
Preemption Vectors visualized
for PAP and PAP+:
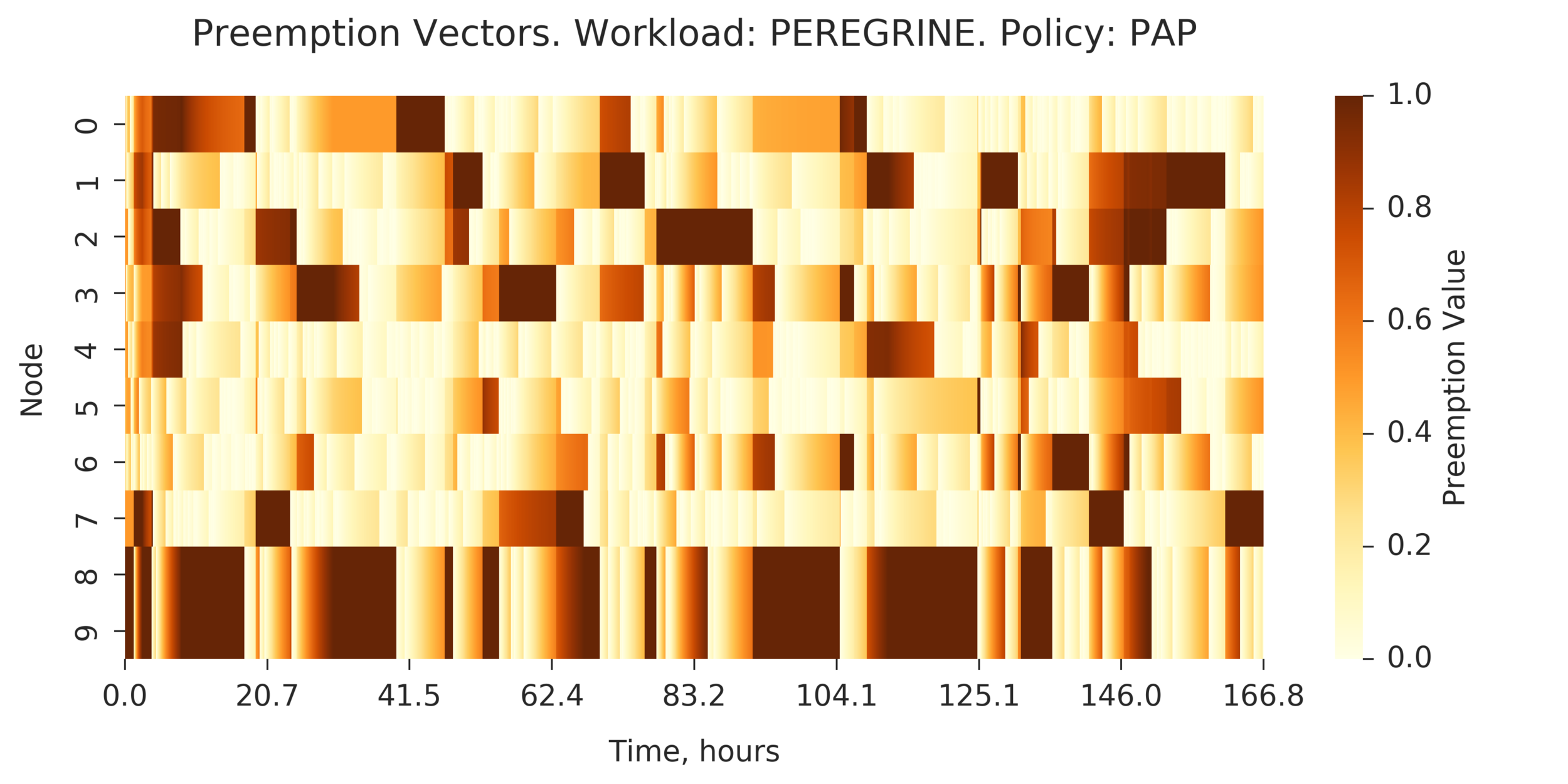
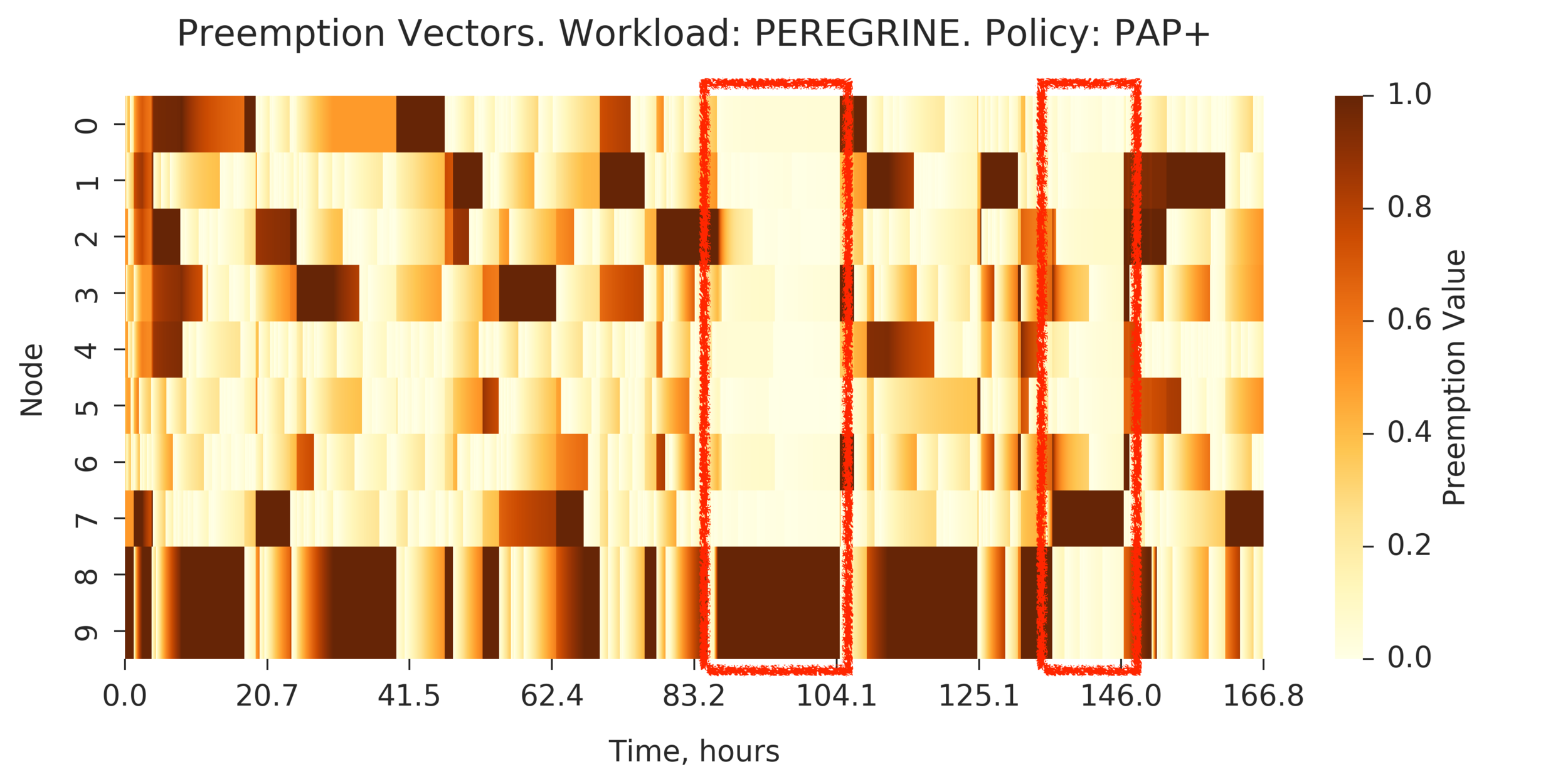
(Experiment directory: yass/preserved/peregrine-20170127-104259)
Additional Analysis:
Prioritizing jobs that represent a particular application:
app_name = gaussian (job count = 341, ~4.7% of total)
high_job_priority = 10.0
(Experiment directory: yass/preserved/peregrine-20170127-091920)
Grace Period = 60 Max for PAP for default-priority jobs: 3.625e+06 Max for PAP+ for default-priority jobs: 3.8831e+06 (relative difference: 7.120) Max for PAP for high-priority jobs: 1.1951e+05 Max for PAP+ for high-priority jobs: 3267.4 (relative difference: -97.266)
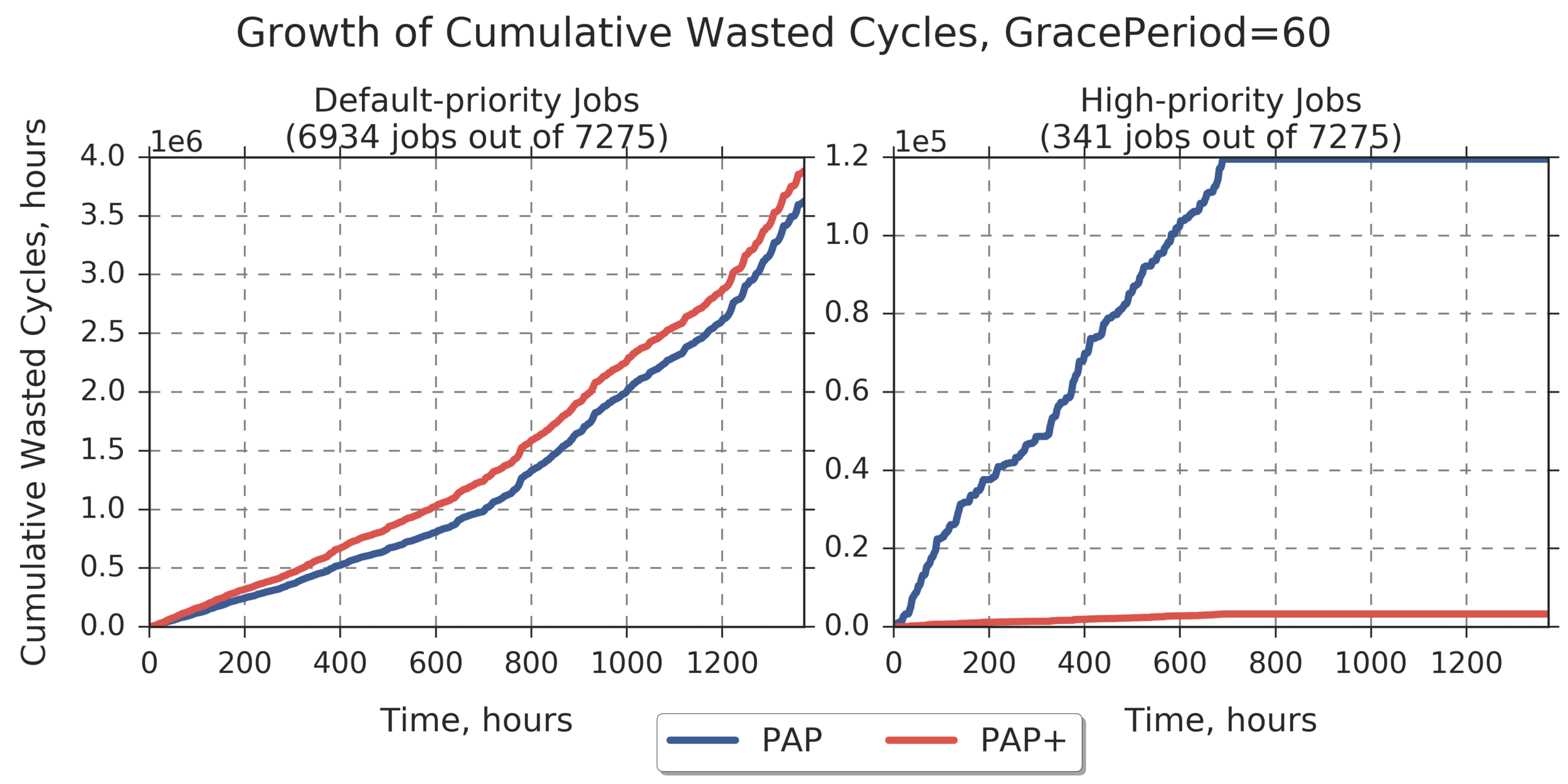
(Experiment directory: yass/preserved/peregrine-20170127-091920)
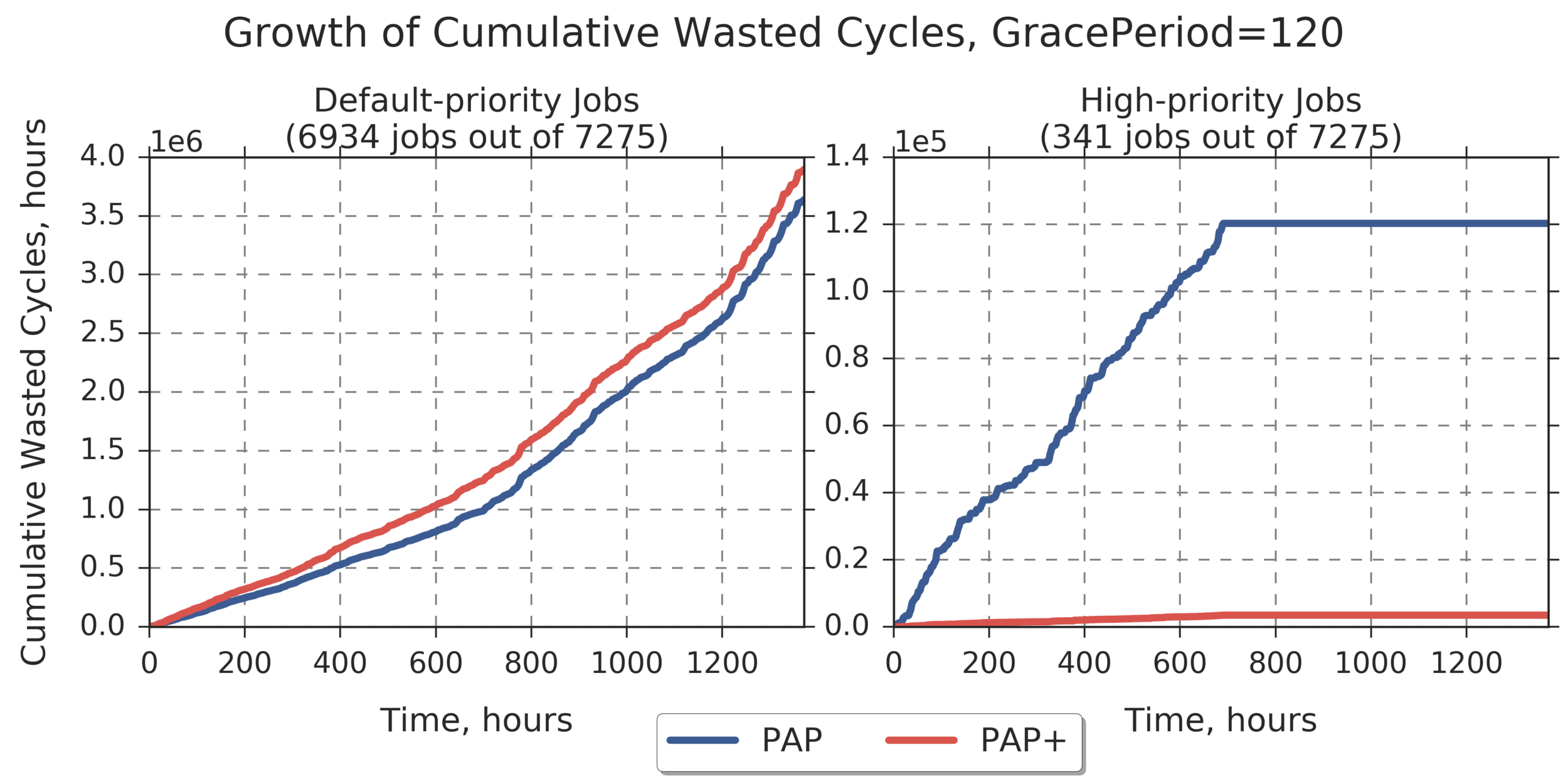
Grace Period = 120 Max for PAP for default-priority jobs: 3.6377e+06 Max for PAP+ for default-priority jobs: 3.8961e+06 (relative difference: 7.103) Max for PAP for high-priority jobs: 1.2028e+05 Max for PAP+ for high-priority jobs: 3468.4 (relative difference: -97.116)
Additional Analysis:
Prioritizing jobs that represent a particular application:
app_name = gaussian (job count = 341, ~4.7% of total)
high_job_priority = 10.0
(Experiment directory: yass/preserved/peregrine-20170127-091920)
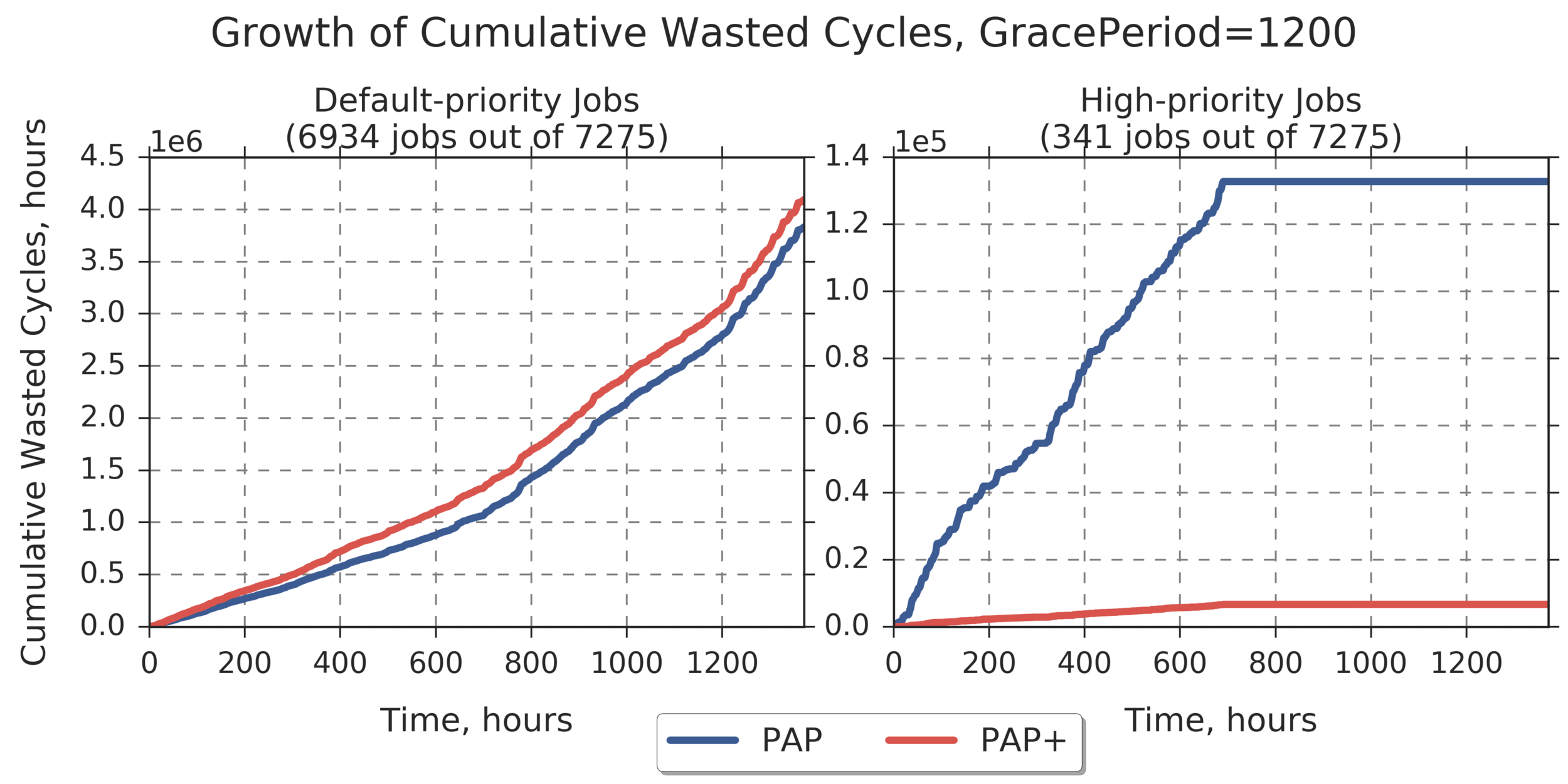
Grace Period = 1200 Max for PAP for default-priority jobs: 3.8308e+06 Max for PAP+ for default-priority jobs: 4.0929e+06 (relative difference: 6.842) Max for PAP for high-priority jobs: 1.3275e+05 Max for PAP+ for high-priority jobs: 6679.6 (relative difference: -94.968)
Additional Analysis:
Prioritizing jobs that represent a particular application:
app_name = gaussian (job count = 341, ~4.7% of total)
high_job_priority = 10.0
(Experiment directory: yass/preserved/peregrine-20170127-091920)
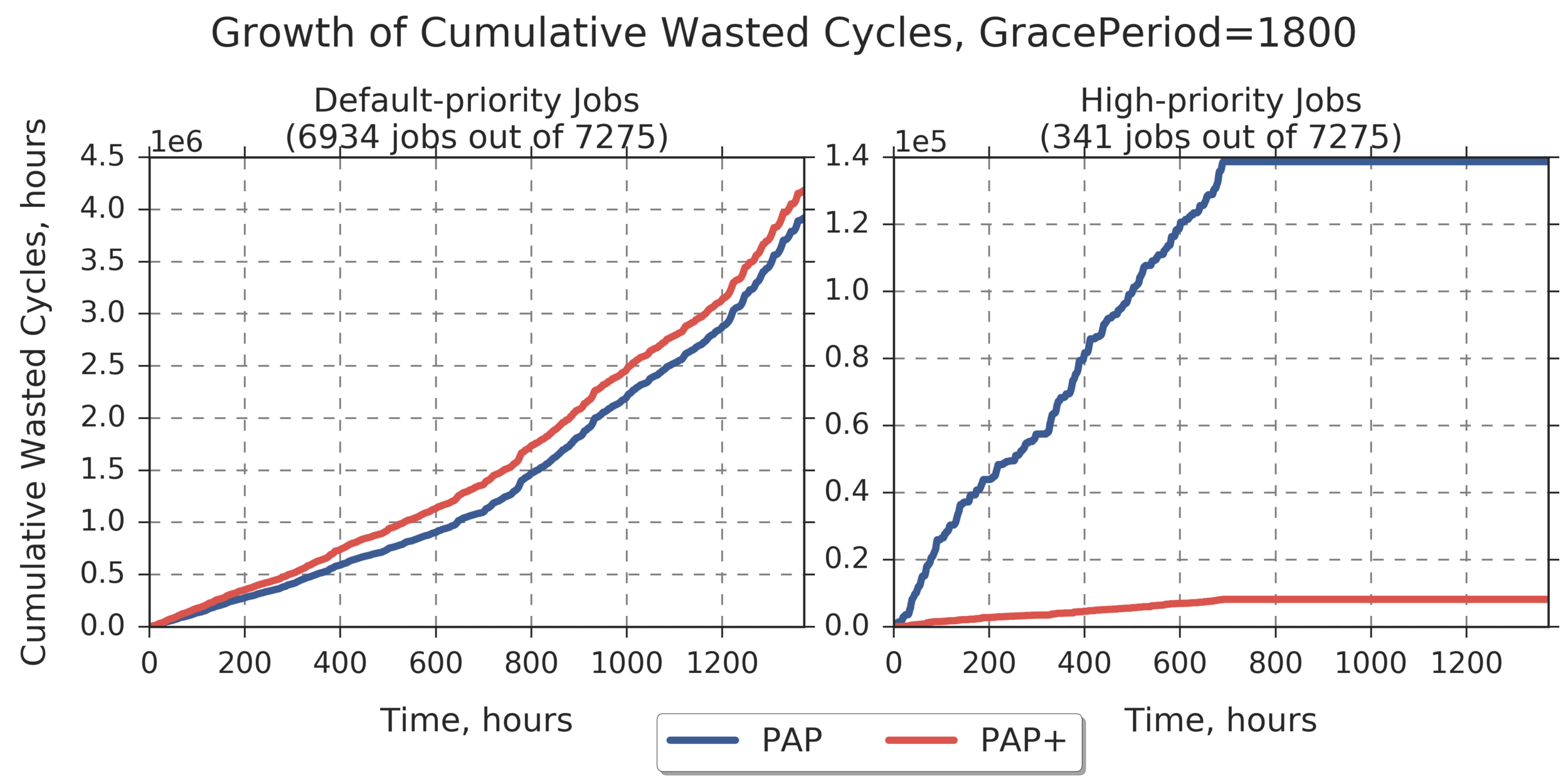
Grace Period = 1800 Max for PAP for default-priority jobs: 3.9184e+06 Max for PAP+ for default-priority jobs: 4.1819e+06 (relative difference: 6.724) Max for PAP for high-priority jobs: 1.3867e+05 Max for PAP+ for high-priority jobs: 8182.7 (relative difference: -94.099)
Additional Analysis:
Prioritizing jobs that represent a particular application:
app_name = gaussian (job count = 341, ~4.7% of total)
high_job_priority = 10.0
Additional Analysis:
What about larger Grace Periods? Trying: 1h to 6h
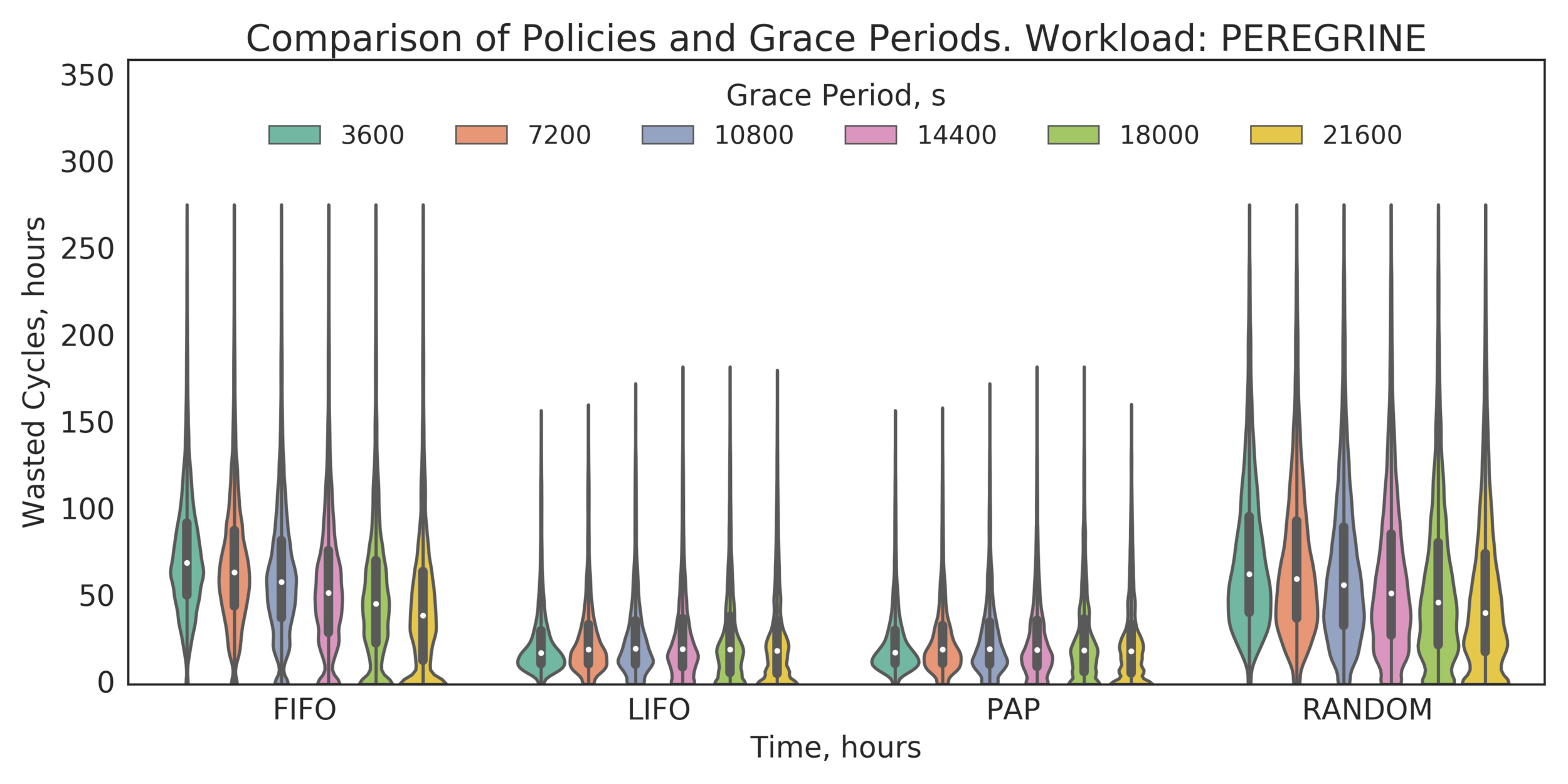
Additional Analysis:
What about larger Grace Periods? Trying: 1h to 6h
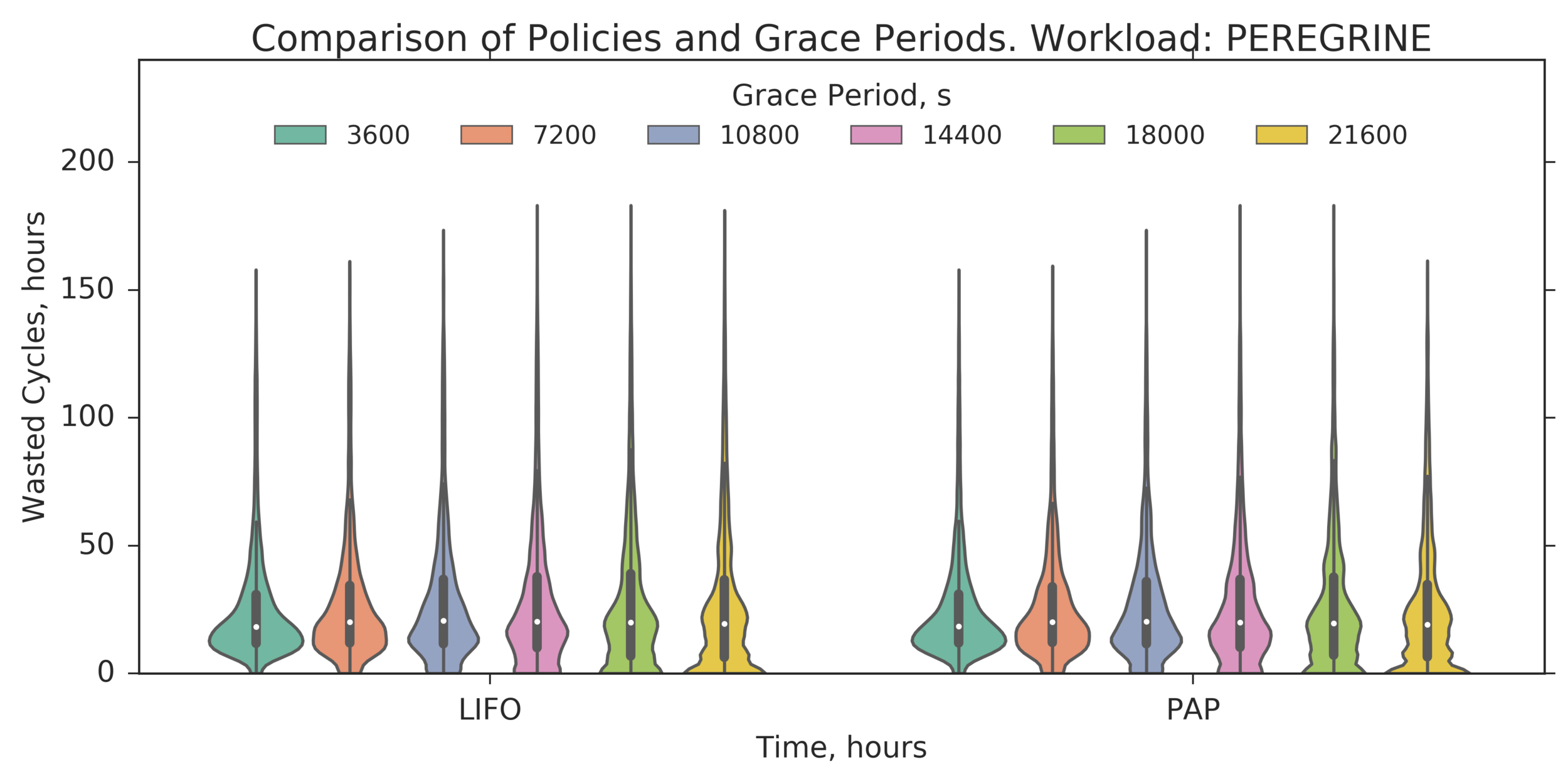
Additional Analysis:
What about larger Grace Periods? Trying: 30m to 6h with 30m increments
(Experiment directory: yass/preserved/peregrine-20170206-134326)
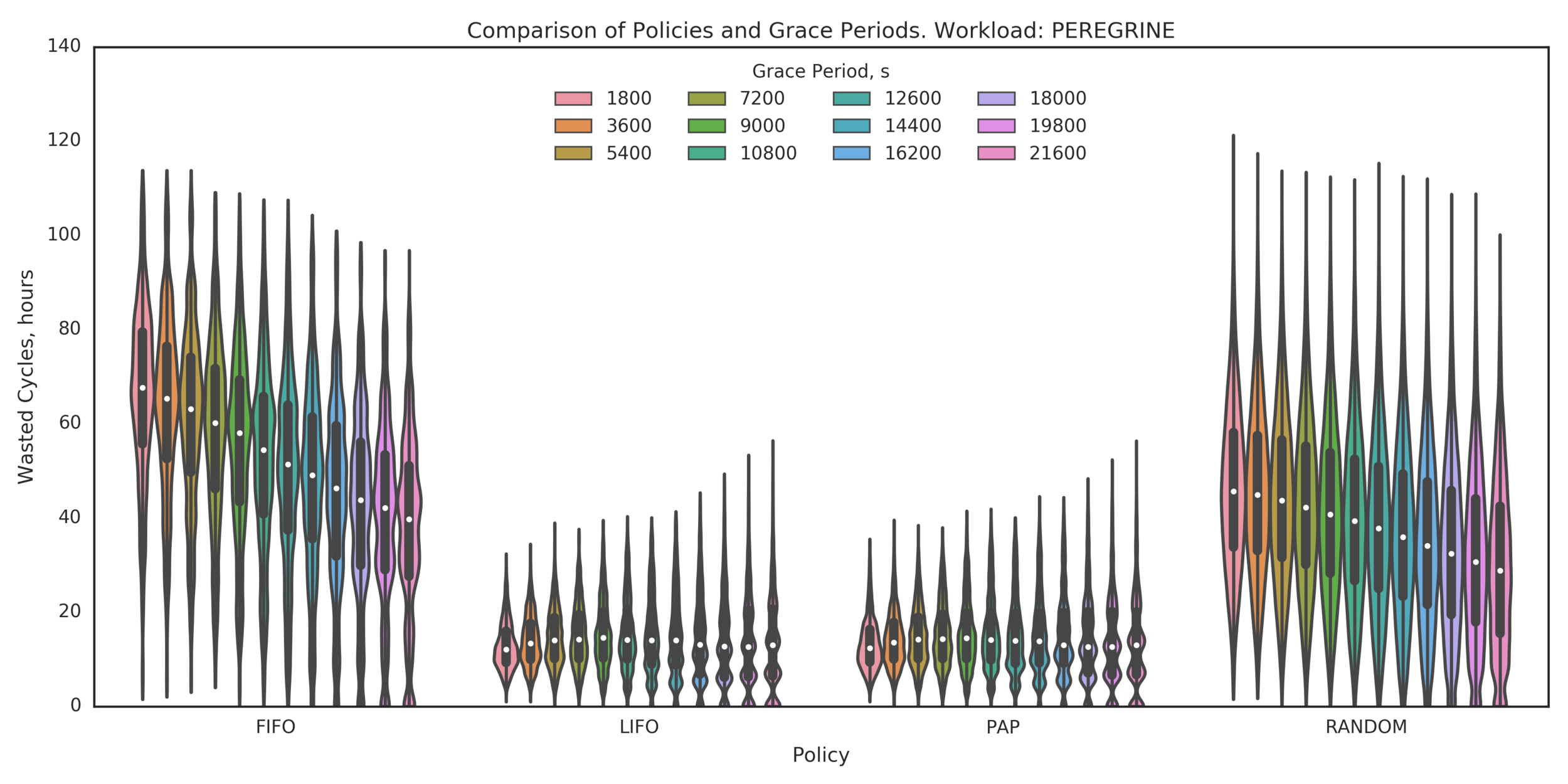
Additional Analysis:
What about larger Grace Periods?
(Experiment directory: yass/preserved/peregrine-20170206-134326)
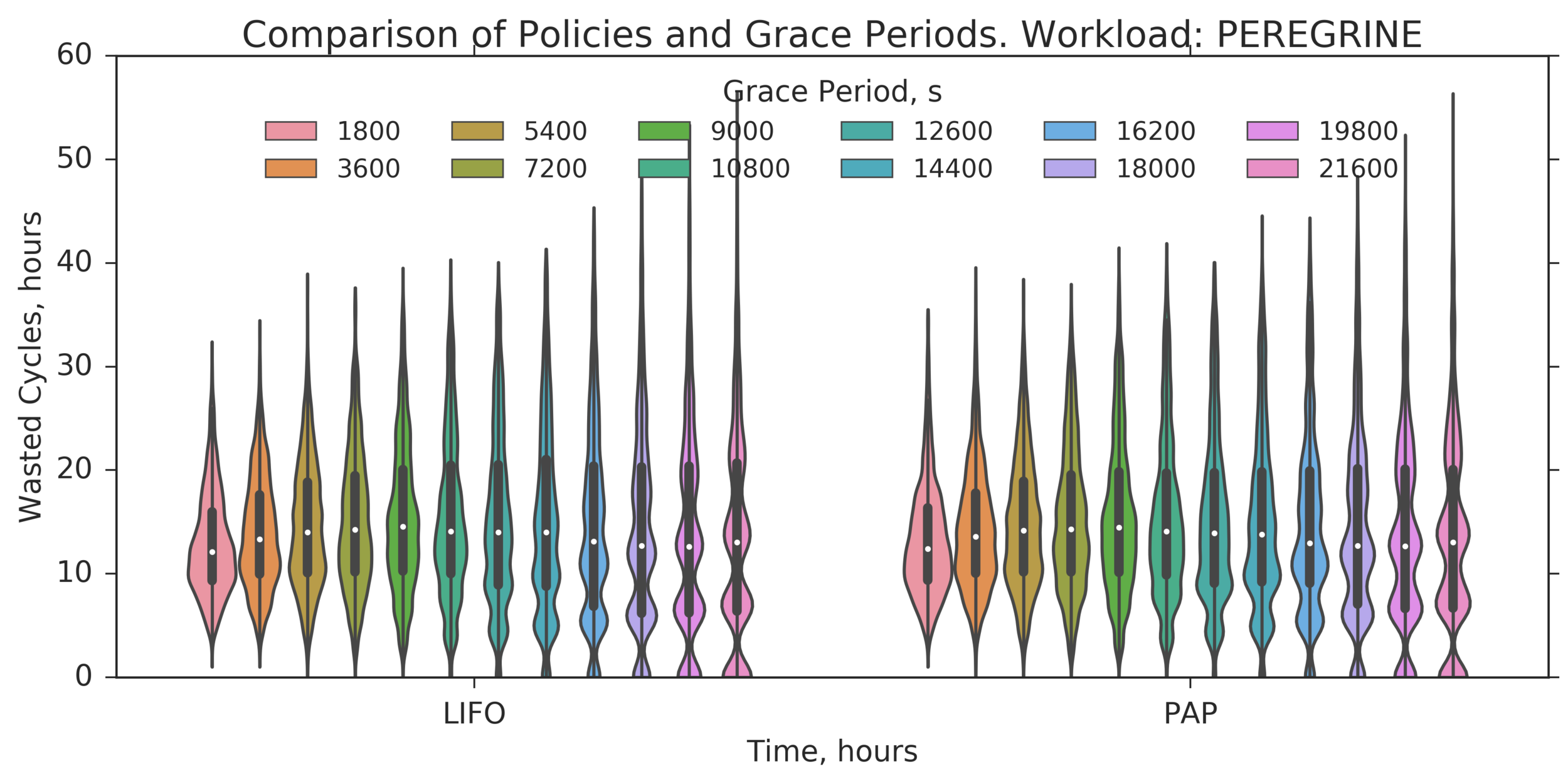
Additional Analysis:
What about larger Grace Periods?
(Experiment directory: yass/preserved/peregrine-20170206-134326)
Additional Analysis:
Summary:
- PAP+ is a straightforward extension of PAP
that uses the same interface based on the [0,1] preemption values. - PAP+ is shown to be efficient in reducing WC for all parallel jobs
and especially for a subset of high-priority jobs. - Priority coefficients can be assigned based on which queue the jobs are running in and also based on which application they represent.