Reinforcement Learning

Examples
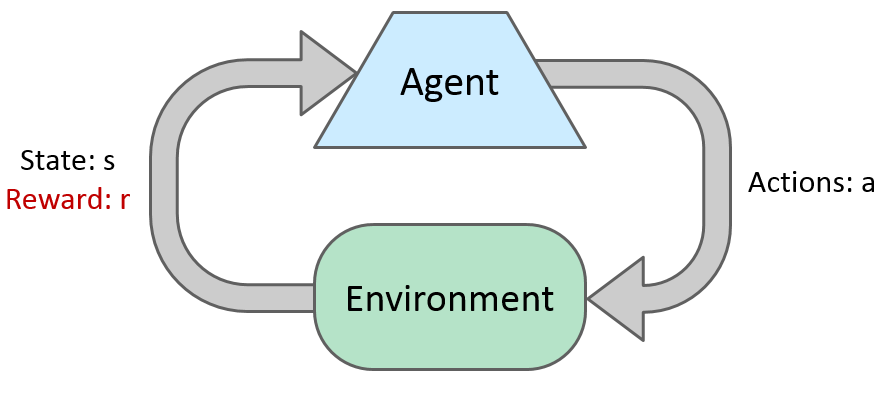
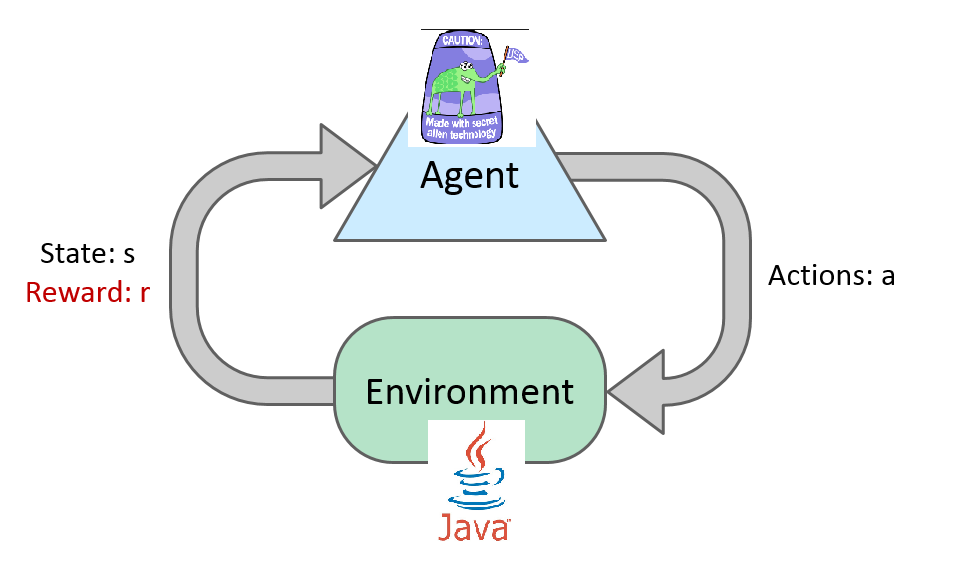
Basic Idea
Markov Decision Process
- A set of states s in S
- A set of actions (per state) A
- A model T(s,a,s’) ; P(s'|s,a)
- A reward function R(s,a,s’)
- A policy Pi(s)
Reinforcement Learning
- Still assume a Markov decision process
- Still looking for a policy Pi(s)
- We don’t know T or R

Offline Solution (MPD)
Online Learning (QLearning)
Model-Based Learning

Model-Free Learning


Passive Reinforcement Learning

Active Reinforcement Learning



Q-Learning
Q-Learning

Model Free

Active RL
Q-Learning
-
Easy way to qualify a action in a specific state
-
QValue - Q(s,a) = 0
-
Temporal Difference Learning
-
Q-Learning
-
Learn Q(s,a) values as you go
-
Take a action based in the max QValue(s,a)
-
Receive a sample (s,a,s’,r)
-
Consider your old estimate:
-
-
Consider your new sample estimate:
-
-
Incorporate the new estimate into a running average
-
-
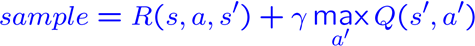
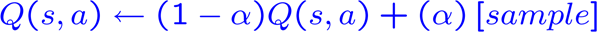
Q-Learning
Q-Learning
Exploration vs. Exploitation
And the Pacman?

What could compose a state in the Pacman problem?
Pacman States



Pacman
Cognitive Science Conection
The Frame Problem
Generalizing Across States
- In realistic situations, we cannot possibly learn about every single state!
- Too many states to visit them all in training
- Too many states to hold the q-tables in memory
- Instead, we want to generalize:
- Learn about some small number of training states from experience
- Generalize that experience to new, similar situations
Approximate
Q-Learning
Feature-Based Representations
Solution: describe a state using a vector of features (properties)
- Features are functions from states to real numbers (often 0/1) that capture important properties of the state
- Example features:
- Distance to closest dot
- Number of ghosts
- 1 / (dist to dot)^2
Approximate Q-Learning
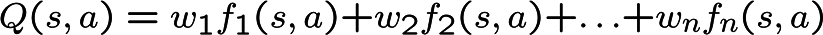

Update the weights
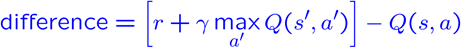
Approximate Q-Learning
Java vs Lisp
References
Questions?
