Image recognition and camera positioning with OpenCV.
A tourist guide application
Francesco Nazzaro

f.nazzaro@bopen.eu

Image recognition issues:
We have to implement a human ability!
The images to compare can be distorted and oriented in different ways!
We have to detect individual features.
The detection must be scale invariant.
Google Images: why not?

Google Goggles doesn't have a public API!
Features detection
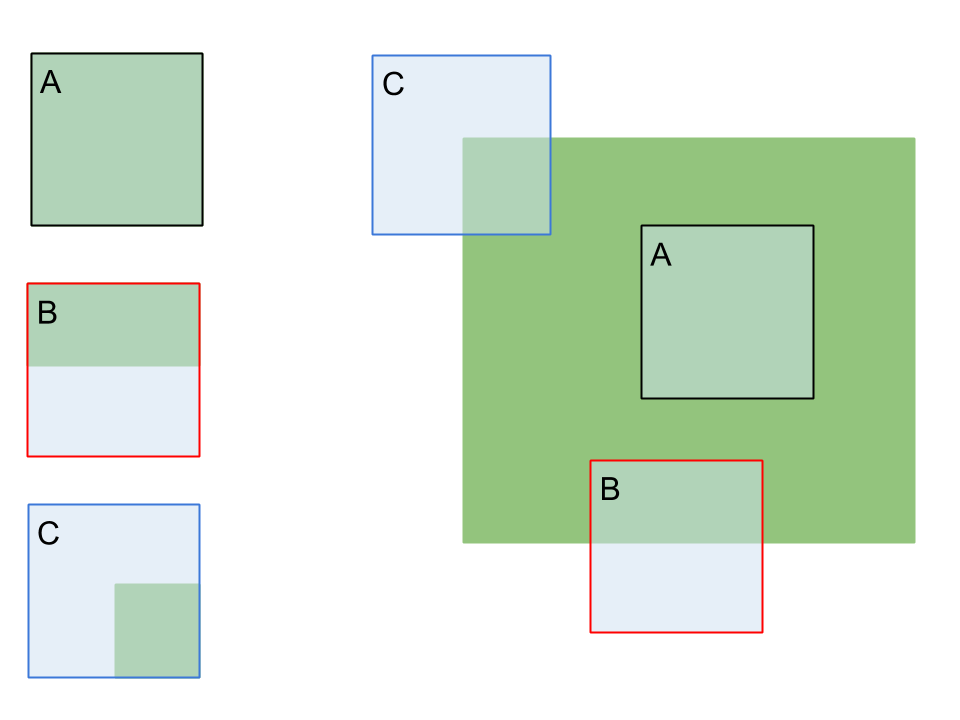
C - corner
-
Corners have an orientation!
-
We need a corner detection algorithm!
-
The algorithm must be scale invariant!
Scale Invariant Feature Transform algorithm by Lowe
- Difference of Gaussians (DoG) passed on the image to detect scale invariant blobs. Blobs are the extrema of the DoG distribution.
- An algorithm like Harris' corner detector is used to leave out edges, and to keep corners.
- An orientation is assigned to each feature to achieve rotation invariance.
- For each keypoint a descriptor vector is created
- Keypoints matching through nearest neighbor algorithm
David G. Lowe, Distinctive Image Features from Scale-Invariant Keypoints, International Journal of Computer Vision, Volume 60 Issue 2, November 2004, Pages 91-110
Image recognition with OpenCV
and IPython Notebook
%pylab inline
import cv2Import b/w image
imshow(image, cmap='gray')
Extract keypoints and descriptors
sift = cv2.SIFT()
key_points, descriptors = sift.detectAndCompute(image, None)
imshow(cv2.drawKeypoints(image, key_points))
Same process for library image
key_points_lib, descriptors_lib = sift.detectAndCompute(lib_image, None)
imshow(cv2.drawKeypoints(lib_image, key_points_lib))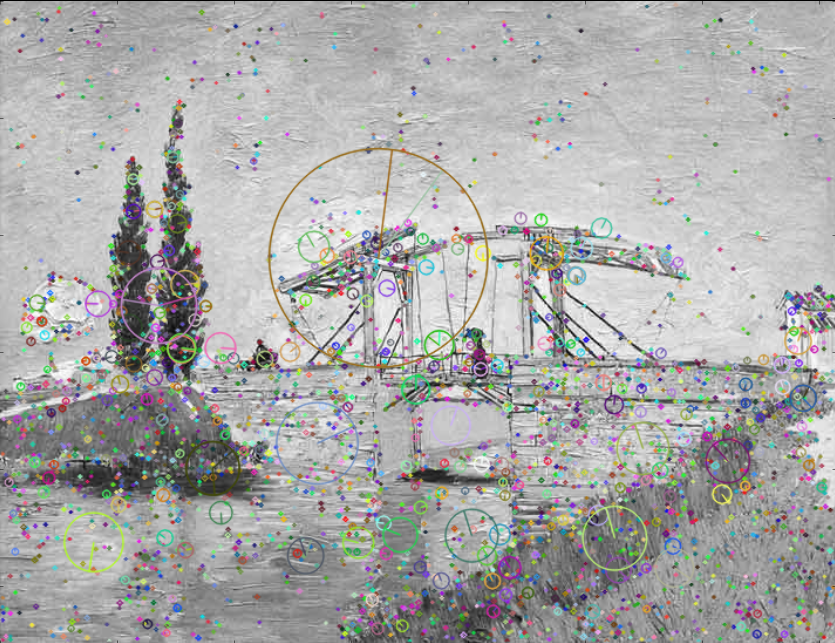
Match descriptors
flann = cv2.FlannBasedMatcher(index_params, search_params)
matches = flann.knnMatch(desc, desc_lib, k=2)
good = [m for m, n in matches if m.distance < 0.7 * n.distance]
cv2.drawMatches(image, kp, lib, kp_lib, good)
Recognized
156 matches
Not recognized
35 matches
SIFT algorithm


Recognized
93 matches
Not recognized
21 matches
SURF algorithm


Pose estimation
Pose estimation with homography
We have two cameras and , looking at point in a plane.
The projections of in and are respectively and
Where the homography matrix is
- is the rotation matrix between and .
- is the translation vector.
- and are the normal vector of the plane and the distance to the plane respectively.
- and are the cameras' intrinsic parameter matrices
We have to compute camera intrinsic parameter matrices
Calibration is performed through chessboard method.
Photographing a chessboard from different angles, searching the corners and forcing them to lies on a straight line through a distortion.

We can compute the intrinsic parameter of the camera with the OpenCV functions cv2.findChessboardCorners and cv2.calibrateCamera.
Starting from these parameters we can apply a warp to the image.

cv2.findChessboardCorners()cv2.calibrateCamera()Title Text
image_matches = np.array([ key_points[m.queryIdx].pt for m in good ]).reshape(-1,1,2)
lib_matches = np.array([ key_points_lib[m.trainIdx].pt for m in good ]).reshape(-1,1,2)
M, _ = cv2.findHomography(image_matches, lib_matches, cv2.RANSAC, 5.0)
h, w = image_lib.shape
pic_pts = np.array([[0, 0],[0, h - 1], [w - 1, h - 1], [w - 1, 0]]).reshape(-1, 1, 2)
distorted = cv2.perspectiveTransform(pic_pts, M)
plot(distorted[:, 0, 0], distorted[:, 0, 1], marker='.', c='red')
cv2.drawMatches(image, key_points, image_lib, key_points_lib, good, **draw_params)Now we can compute the position of the picture in the image

Picture positioning wrong!

False positive!
wsize = hsize / h * w
objp = np.array(
((0., 0., 0.), (0., hsize, 0.), (wsize, hsize, 0.), (wsize, 0., 0.)), dtype=np.float32
).reshape(4, 1, 3)
_, rvecs, tvecs = cv2.solvePnP(objp, distorted, mtx, dist)
R, _ = cv2.Rodrigues(rvecs)
translation = R.T.dot(-tvecs)To compute the position of the observer we have to extract rotation and translation from the homography
mtxare the camera intrinsic parameters
distand
3D
Let's start with a picture of the Costantine arc, taken from the right

Image recognition doesn't work. There are too many differences between the images.

We need 3 images in the library: from left, right and center. The algorithm recognizes the right one

We used image recognition in a Google Glass application
It is a tourist guide application for Google Glass.
It plays media contents based on your localization



cofinanced with contribution POR/FESR Regione Lazio
2007 – 2013 Asse I – Avviso Pubblico Insieme x Vincere

Image recognition is used for:

- advanced localization
- emission of advanced information on what you're watching

Thank you!
Francesco Nazzaro
f.nazzaro@bopen.eu