Waterdrop
一个简单易用,高性能,能够应对海量数据的数据处理产品
- 为什么需要 Waterdrop(WD)
- WD 能做什么/应用场景
- WD 特性
- WD 工作流程
- WD 插件
- WD 配置
- WD 部署、运行
- WD 监控
- WD插件开发
主题
- WD 架构
- WD 相似产品比较
- WD 核心实现
- WD 插件体系
- WD 易用性
- WD 性能
- WD 核心工作
- WD 发展潜能
- 关注 InterestingLab
- 分布式数据处理入门易,精通难
- 太多Spark重复代码,重复逻辑可以抽象和简化
- 实现高效不出错的spark程序有难度
- 海量数据处理挑战多,经验少
- 开发、测试、上线周期长
为什么需要Waterdrop(WD)
通过我们的努力让Spark的使用更简单,更高效,并将业界和我们使用Spark的优质经验固化到Waterdrop这个产品中,明显减少学习成本,加快分布式数据处理能力在生产环境落地。
- 海量数据ETL
- 海量数据聚合
- 多源数据处理
Waterdrop 是什么
Waterdrop 应用场景
Waterdrop 是一个简单易用,高性能,能够应对海量数据的实时/离线数据处理产品,构建于Apache Spark之上。
- 简单易用,灵活配置,无需开发
- 支持实时流式处理和离线分批处理2种运行模式
- 高性能
- 海量数据处理能力
- 模块化和插件化,易于扩展
- 支持利用SQL做数据处理和聚合
- 支持spark 1.6 ~ spark 2.x
Waterdrop 特性
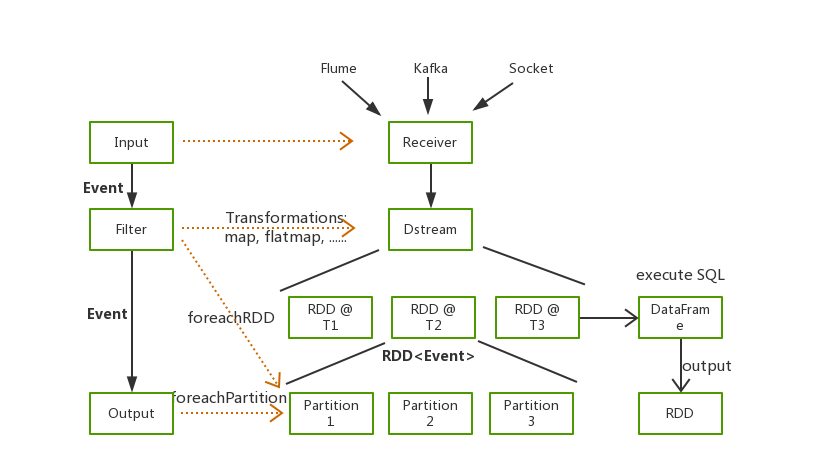
Waterdrop 工作流程
数据源输入
数据反序列化
数据处理
数据序列化
结果输出
Input Plugin
Serializer Plugin
Filter Plugin
Output Plugin
Serializer Plugin
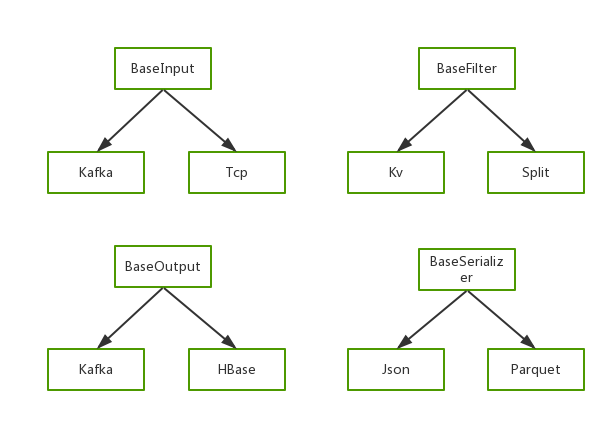
Waterdrop 插件
Input Plugin:
Hdfs, Http, Kafka, Redis, Stdin, Tcp,
自行开发的Input plugin
Filter Plugin:
Aggregate, Clone, Date, Dict, Drop, Geoip, Grok, Kv, Prune, Range, Split, SQL, 自行开发的Filter plugin
Output Plugin:
Elasticsearch, File, HBase, Hdfs, Http, Kafka, Mongodb, MySQL, Stdout,
自行开发的Output plugin
Serializer Plugin:
Carbondata, Csv, Json, Gzip, ORC, Parquet, Protobuf, Raw,
自行开发的Serializer plugin
Waterdrop 配置
input {
kafka {
topics = "gpc.oi_gaoyingju.test1"
consumer.bootstrap.servers = "10.110.94.130:9092,10.110.94.131:9092,10.110.95.50:9092,10.110.95.68:9092,10.110.95.82:9092"
consumer.zookeeper.connect = "10.110.94.130:2181,10.110.94.131:2181,10.110.95.50:2181,10.110.95.68:2181,10.110.95.82:2181"
consumer.group.id = "scala_test_group1"
consumer.num.consumer.fetchers = "4"
consumer.auto.offset.reset = "largest"
}
}
filter {
split {
delimiter = " "
keys = ["a", "b", "c"]
source_field = "raw_message"
target_field = "msg"
}
}
sql {
query {
table_name = "mytable"
sql = "select * from mytable where a = \"value\""
}
}
output {
kafka {
topic = "gpc.oi_wangjie7.test1"
producer.bootstrap.servers = "10.110.94.130:9092,10.110.94.131:9092,10.110.95.50:9092,10.110.95.68:9092,10.110.95.82:9092"
producer.acks = "1"
producer.retries = "2"
producer.retry.backoff.ms = "100"
producer.batch.size = "46384"
producer.linger.ms = "6000"
producer.buffer.memory = "268435456" # 256 MB
producer.key.serializer = "org.apache.kafka.common.serialization.StringSerializer"
producer.value.serializer = "org.apache.kafka.common.serialization.StringSerializer"
producer.compression.type = "snappy"
producer.send.buffer.bytes = "131072"
producer.max.request.size = "1048576"
producer.max.in.flight.requests.per.connection = "2"
}
}Waterdrop 部署、运行
## (1) Spark Submit
$SPARK_HOME/bin/spark-submit \
--master yarn-clienta \
--num-executors 30 \
--executor-cores 2 \
--executor-memory 2G \
--conf spark.app.name=Waterdrop \
--conf spark.ui.port=13000 \
--conf spark.streaming.blockInterval=1000ms \
--conf spark.streaming.kafka.maxRatePerPartition=30000 \
--conf spark.streaming.kafka.maxRetries=2 \
--conf spark.yarn.jar=hdfs://alluxio-cluster/sparkLib/spark-assembly-1.6.0-hadoop2.6.0.jar \
--conf spark.local.dir=/data/slot6/streamingetl/tmp \
--conf spark.driver.extraJavaOptions=-Dconfig.file=/data/slot6/waterdrop/application.conf \
--class org.interestinglab.waterdrop.WaterdropMain \
/data/slot6/waterdrop/WaterdropMain-assembly-0.1.0.jar
## (2) Spark Job Server with Rest API
Use Rest API to submit Waterdrop Application.Waterdrop 监控
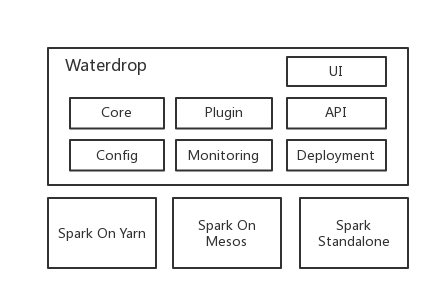
Waterdrop 架构
Waterdrop 相似产品比较
Waterdrop vs Spark :
基于Spark;灵活配置,开发少;更接近用户需求;
Waterdrop vs Flume/Logstash:
分布式集群;能够应对海量数据;支持SQL
Waterdrop 核心实现
(1) Dstream ---> foreachRDD ---> foreachPartition

Spark 实时流式计算
(2) Dstream ---> foreachRDD ---> toDataFrame ---> executeSQL
---> toRDD ---> foreachPartition
Waterdrop 核心实现
核心:
(1)数据流转:将input, filter, output, serializer plugin处理逻辑集成到Spark运行的各阶段中。
(2)Event:程序中用于存储数据的数据结构,实现了setField(), getField(), toJson(), toMap(), getSchema()等基础功能,支持多级嵌套Field。
(3)用 Spark SQL的 DataFrame, UDF 实现(1),用 Row 实现 (2)。
Waterdrop 核心实现
Waterdrop 核心实现
通过DataFrame/SQL做数据处理:
(1)转换:select substr(name, 0, 10), get_userid(url) from table1
(2)过滤:select * from table1 where http_status != 200
(3)聚合:select datatime, count(*) as req_count, sum(totalsize) / 60 as bandwidth from table1
(4)将Waterdrop的Filter插件,注册为Spark SQL的UDF(User Defined Function), UDAF(User Defined Aggregation Function),实现通过SQL完成各种Filter功能。
(5)Spark SQL提供了丰富的UDF。
Waterdrop 插件体系
(1)实现一个插件就是继承和实现特定的方法。
(2)利用Scala的Reflection机制实现根据插件类名加载插件。
(3)用abstract class定义BaseXXX能够更好的同时支持Java/Scala。
(4)用插件实现80%的常见数据处理逻辑。
(4)用户开发的插件与Waterdrop项目互相独立。
Waterdrop 易用性
举例:
(1) Kafka Input 允许记录每个Batch 的历史offset,便于对比和回退
(2) 支持Spark 1.6 ~ Spark 2.x
(3) 数据分散统计。场景:统计数据各个时间点的分散程度,对于分散的数据做特殊处理。
(4) ...
Waterdrop 可靠性
举例:
(1) 数据处理的at-most-once, at-least-once, exactly-once
(2) Gracefully Shutdown
(3) 应用存活检测,健康状况检测,自动拉起。
(4) ...
Waterdrop 性能
举例:
(1)充分利用Spark分布式计算的性能。
(2)经过优化的代码实现和固化的高性能调优经验。
(2)利用广播变量减少重复建立连接次数。
(4)...
Waterdrop 核心工作
第一期:
项目的开发、测试规范和流程
项目框架(Event, 数据流)的开发与测试
配置中支持复杂配置逻辑(如:if else 的逻辑,模版变量,预定义变量)
主要插件的开发与测试
部署、运行流程的包装
简洁易懂的中英文文档
第二期:
统计监控功能
Spark UI
Listener Plugin(实现常用的Spark Listener)
支持离线计算
第三期:
性能优化检查器
插件Repo的完整管理体系
支持机器学习算法
Waterdrop 发展潜能
(1)好产品吸引关注度和使用量
(2)Github开源让更多开发者加入
(3)运营和推广提高知名度
(4)深入Spark成为Committer
Questions & Answers
关注 Interesting Lab :
References
1. http://spark.apache.org/docs/latest/streaming-programming-guide.html
2. http://spark.apache.org/third-party-projects.html
3. https://github.com/spark-jobserver/spark-jobserver
4. http://arturmkrtchyan.com/apache-spark-hidden-rest-api
5. https://livy.incubator.apache.org/