Building data set pipelines for
deep learning strategies
See important disclosures at the end of this presentation.
Ankit Awasthi
Quantitative Portfolio Manager
The Trading Show NY, September 26th, 2018
Outline of the talk
Breaking down a generic learning problem
Criteria for selecting datasets
Improving deep learning strategies using hypothetical data
Future Testing Strategies
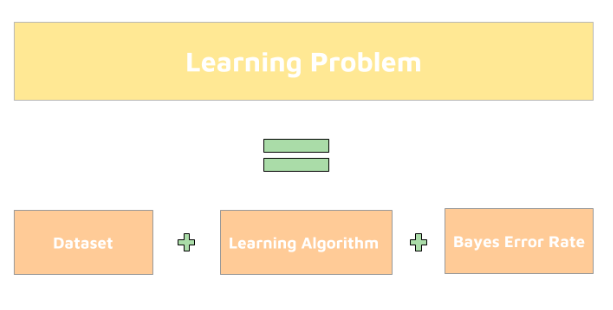
Breaking down a general machine learning problem
Illustrative and Representative Only
Hard problems are easy (to overfit)!
Here, for a dataset of 1,000 data points, given an expected correlation of 1%, around 75% of datasets could appear to be statistically significant, whereas for expected correlation values of 13%, it is close to 0.
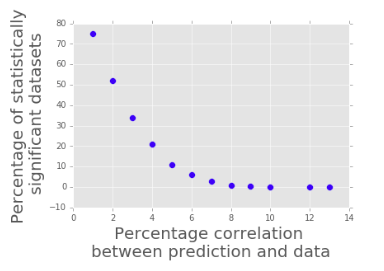
Hard problems are easy (to overfit)!
Given expected correlation of 1%, as the size of the dataset increases from 100 data points to 100,000 data points, the chances of a random dataset appearing statistically significant goes from around 92% to close 0%
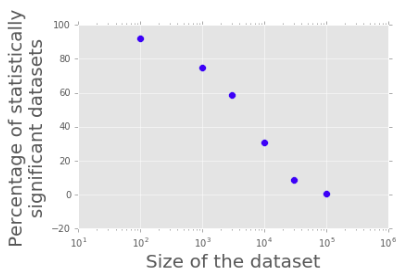
Select a dataset that...
Is clean and reliable
Has high coverage
Has long history
Is predictive over long horizons
Data Cleaning and Validation
Addressing look-ahead bias
Filling in missing data
Outlier Detection
Datasets : Coverage vs History
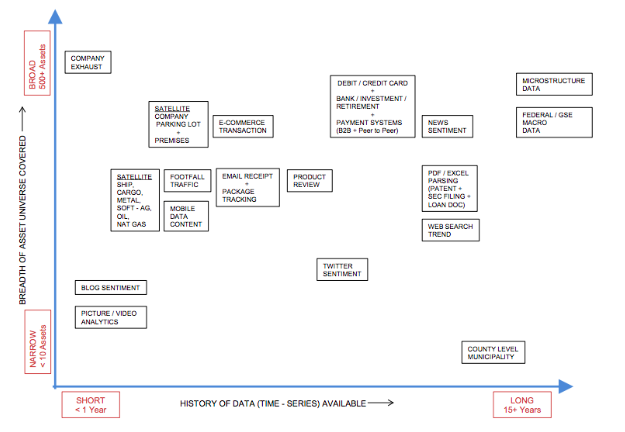
Source : JP Morgan
Macro data and price volume data have the highest coverage with longest history!
Tremendous Success of Deep Learning
Image
Text
Speech
Abundance of Data!


Deep learning scales with data
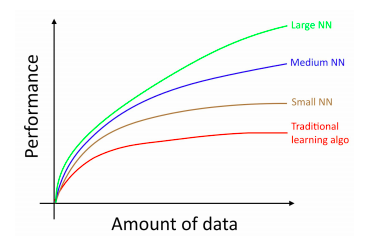
Source : Andrew Ng, Coursera Deep learning specialization
Data Augmentation for Deep Learning
Even more data!

Source : Bharat Raj, Data Augmentation | How to use Deep Learning when you have Limited Data
Much harder in Finance!
Generating Hypothetical Data for Trading
Adding noise or transformations
Theoretical models
Appropriating High Frequency Data
Stylized Effects of Financial Time Series
Absence of Autocorrelations
Heavy Tails
Volatility Clustering
Leverage Effect
Cross Correlation vs Volatility
Reference : Empirical properties of asset returns: stylized facts and statistical issues, Rama Cont
Cross-Correlation Vs Asset Volatility
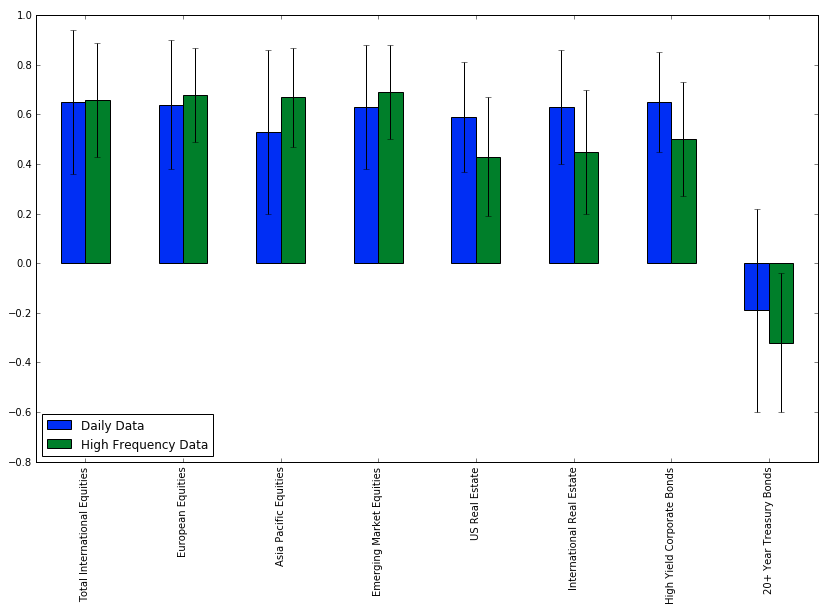
Mean of 30-day rolling correlation of different assets with US Total Stock Market (VTI)
Standard Deviation is shown as error bars.
Correlation (Mean and Variance)
Correlation increases with volatility
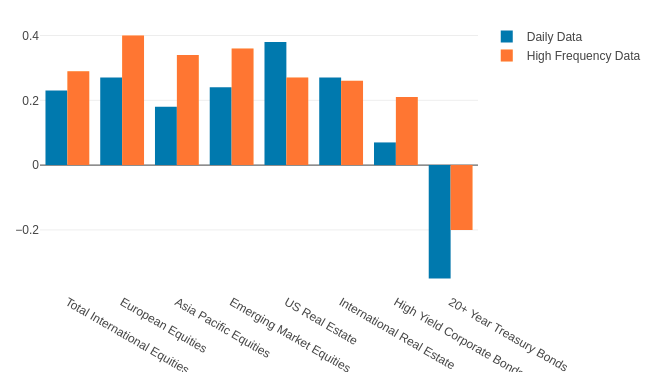
Correlation of 30-day rolling correlation of log returns of different assets vs US Total Stock Market against the volatility of US Total Stock Market.
Correlation
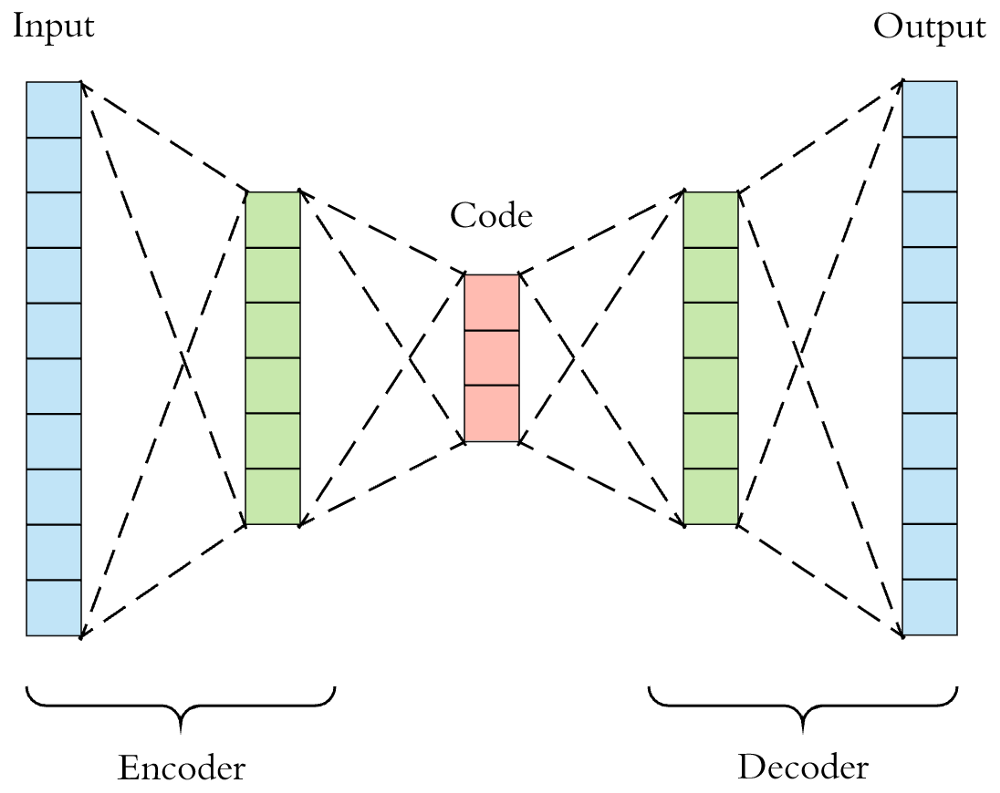
A simple example - Autoencoders
Source : Arden Dertat, Applied Deep Learning
Experimental Setup
Daily EOD Data
Training
3000 pts
Validation
1000 pts
Testing
1000 pts
Large High Frequency Data Corpus
( 32000 pts )
Training
(High Frequency + Daily)
Validation
Out of Sample
Evaluation
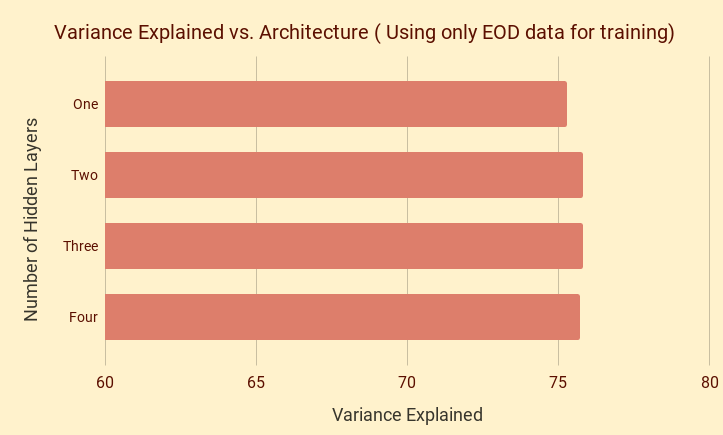
Model complexity alone doesn't help much!
One Hidden Layer : 62 -> 3 -> 62
Two Hidden Layers : 62 -> 10 -> 3 -> 10 -> 62
Three Hidden Layers : 62 -> 20 -> 10 -> 3 -> 10 -> 20 -> 62
Four Hidden Layers : 62 -> 100 -> 20 -> 10 -> 3 -> 10 -> 20 -> 100 -> 62
However....more data does!
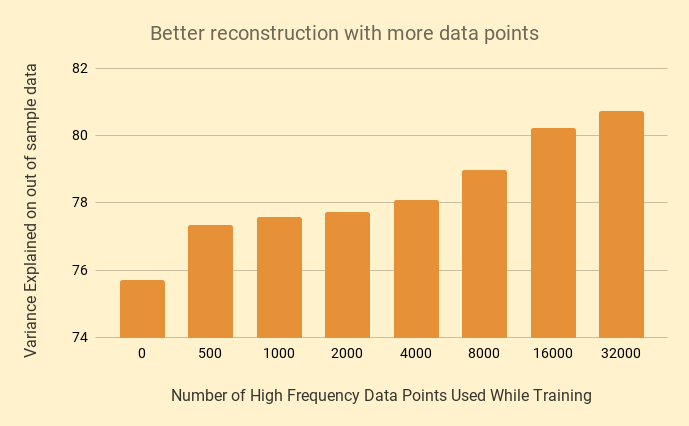
Architecture Used : 62 -> 100 -> 20 -> 10 -> 3 -> 10 -> 20 -> 100 -> 62
Stress / Future Testing Investment Strategies
Helps to be data-driven with more data!
Scenario Analysis
Cross-Validating Hyperparameters
Future performance under different capital market assumptions
Key Takeaways
Overfitting is one of the biggest concerns when working with financial datasets
Deep learning works best when you have lots of data and it's the same for finance
Hypothetical data can be used to develop better and more robust data driven strategies
Questions?
contact@qplum.co
ankit@qplum.co
Important Disclaimers: This presentation is the proprietary information of qplum Inc (“qplum”) and may not be disclosed or distributed to any other person without the prior consent of qplum. This information is presented for educational purposes only and does not constitute and offer to sell or a solicitation of an offer to buy any securities. The information does not constitute investment advice and does not constitute an investment management agreement or offering circular.
Certain information has been provided by third-party sources, and, although believed to be reliable, has not been independently verified and its accuracy or completeness cannot be guaranteed. The information is furnished as of the date shown. No representation is made with respect to its completeness or timeliness. The information is not intended to be, nor shall it be construed as, investment advice or a recommendation of any kind. Past performance is not a guarantee of future results. Important information relating to qplum and its registration with the Securities and Exchange Commission (SEC), and the National Futures Association (NFA) is available here and here.