Automated Ingest
November 12-15, 2018
Supercomputing 2018
Dallas, TX
Automated Ingest

Alan King
Developer, iRODS Consortium
iRODS Capabilities

- Packaged and supported solutions
- Require configuration not code
- Derived from the majority of use cases observed in the user community








Automated Ingest
Provide a flexible and highly scalable mechanism for data ingest
- Directly ingest files to vault
- Capture streaming data
- Register data in place
- Synchronize a file system with the catalog
- Extract and apply metadata
Architecture Overview
- Implemented with Python iRODS Client
- Based on Redis and Celery
- Any number of Celery workers distributed across servers
- File system metadata cached in Redis to detect changes
- iRODS API is invoked only to update the catalog
- Policy defined through event callbacks to user-provided python functions
File System Scanning
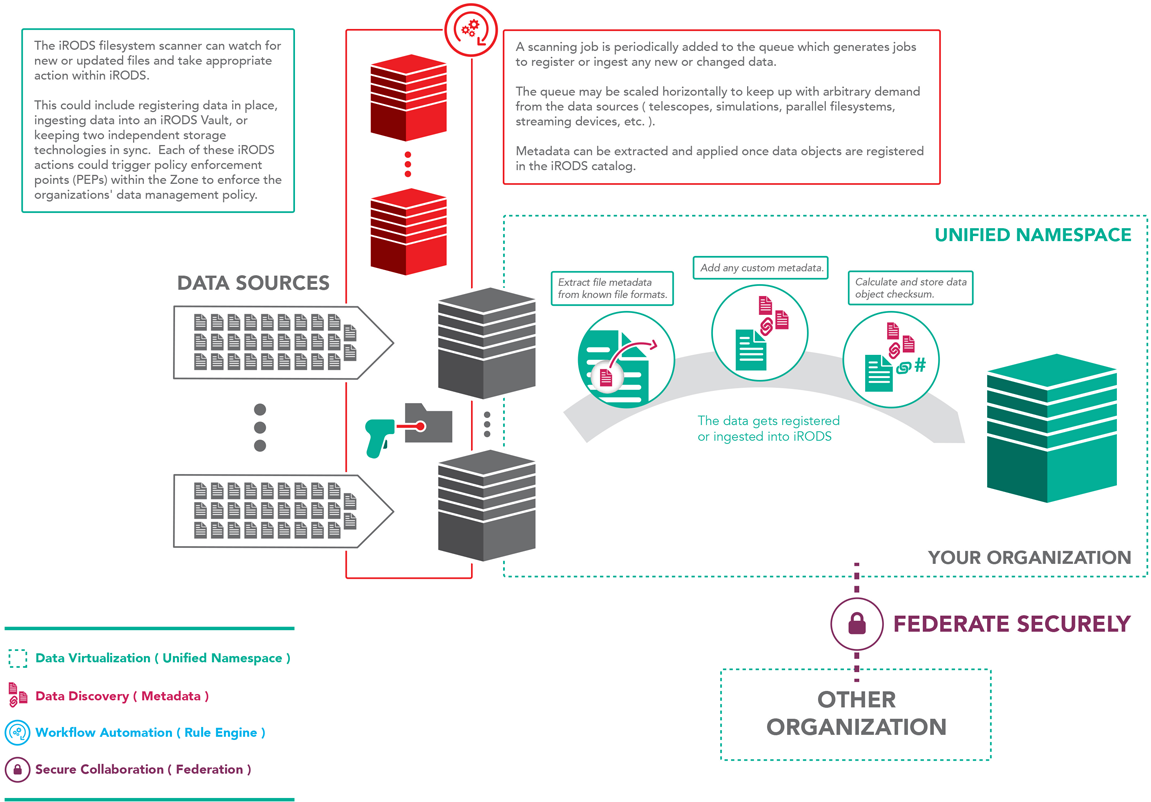
File System Scanning
This implementation periodically scans a source directory, registers the data in place, or updates system metadata for changed files.
In this use case, the file system is considered the single point of truth for ingest. Changes are detected during the scan, and the system metadata is updated within the catalog.
Getting Started
sudo apt-get install -y redis-server python-pip
sudo service redis-server start
As the ubuntu user - start Redis server
pip install virtualenv --user python -m virtualenv -p python3 rodssync source rodssync/bin/activate pip install irods_capability_automated_ingest
As the irods user - install automated ingest via pip
Getting Started
export CELERY_BROKER_URL=redis://127.0.0.1:6379/0 export PYTHONPATH=`pwd`
celery -A irods_capability_automated_ingest.sync_task worker -l error -Q restart,path,file
Open a new terminal, activate rodssync, and set environment variables for the scanner
As the irods user - start Celery workers
source rodssync/bin/activate export CELERY_BROKER_URL=redis://127.0.0.1:6379/0 export PYTHONPATH=`pwd`
Getting Started
mkdir /tmp/test_dir
for i in $(seq 1 200); do touch /tmp/test_dir/file$i; done
mkdir ./src_dir
cp -r /tmp/test_dir ./src_dir/dir0
Generate some source data and "stage" it
Having never scanned this before, we refer to this as the "initial ingest"
Default Ingest Behavior
By default the framework will register the data in place against the default resource into the given collection
imkdir reg_coll
python -m irods_capability_automated_ingest.irods_sync start ./src_dir /tempZone/home/rods/reg_coll --synchronous --progress
--synchronous and --progress are not required but give visual indication of progress - scans are asynchronous by default.
Check that our results are registered in place
$ ils -L reg_coll/dir0/file199
rods 0 demoResc 0 2018-11-08.15:00 & file199
generic /var/lib/irods/src_dir/dir0/file199
Default Ingest Behavior
Stage a different set of data and re-run the ingest
cp -r /tmp/test_dir ./src_dir/dir1 python -m irods_capability_automated_ingest.irods_sync start ./src_dir /tempZone/home/rods/reg_coll --synchronous --progress
$ ils -L reg_coll/dir1/file199
rods 0 demoResc 0 2018-11-08.15:03 & file199
generic /var/lib/irods/src_dir/dir1/file199
Check our results
Now we will demonstrate that the filesystem cache allows the scanner to only ingest changes - a "delta sync"
Customizing the Ingest Behavior
The ingest tool is a callback based system in which the system invokes methods within the custom event handler module provided by the administrator.
These events may then take action such as setting ACLs, providing additional context such as selection of storage resources, or extracting and applying metadata.
Customizing the Ingest Behavior
| Method | Effect | Default |
|---|---|---|
| pre/post_data_obj_create | user-defined python | none |
| pre/post_coll_create | user-defined python | none |
| pre/post_data_obj_modify | user-defined python | none |
| pre/post_coll_modify | user-defined python | none |
| as_user | takes action as this iRODS user | authenticated user |
| target_path | set mount path on the irods server which can be different from client mount path | client mount path |
| to_resource | defines target resource request of operation | as provided by client environment |
| operation | defines the mode of operation | Operation.REGISTER_SYNC |
| max_retries | defines max number of retries on failure | 0 |
| timeout | defines seconds until job times out | 3600 |
| delay | defines seconds between retries | 0 |
Available --event_handler methods
Customizing the Ingest Behavior
The operation mode is returned during the 'operation' method which informs the ingest tool as to which behavior is desired for a given ingest job.
To override the default behavior, one of these operations must be selected and returned. These operations are hard coded into the tool, and cover the typical use cases of data ingest.
Customizing the Ingest Behavior
| Operation | New Files | Updated Files |
|---|---|---|
Operation.REGISTER_SYNC (default) |
registers in catalog | updates size in catalog |
| Operation.REGISTER_AS_REPLICA_SYNC | registers first or additional replica |
updates size in catalog |
| Operation.PUT | copies file to target vault, and registers in catalog |
no action |
| Operation.PUT_SYNC | copies file to target vault, and registers in catalog |
copies entire file again, and updates catalog |
| Operation.PUT_APPEND | copies file to target vault, and registers in catalog |
copies only appended part of file, and updates catalog |
| Operation.NO_OP | no action | no action |
Available Operations
Custom Metadata Annotation
We will implement the operation, to_resource, and post_data_obj_create methods in our event handler
Using the python iRODS client we will apply filesystem metadata from 'stat'
Create a new target resource and ingest collection, and stage data again
iadmin mkresc targetResc unixfilesystem `hostname`:/tmp/irods/target_vault
imkdir put_coll
cp -r /tmp/test_dir ./src_dir/dir2
Custom Metadata Annotation
# /var/lib/irods/stat_eventhandler.py
from irods_capability_automated_ingest.core import Core
from irods_capability_automated_ingest.utils import Operation
from irods.meta import iRODSMeta
import subprocess
class event_handler(Core):
@staticmethod
def to_resource(session, meta, **options):
return "targetResc"
@staticmethod
def operation(session, meta, **options):
return Operation.PUT
@staticmethod
def post_data_obj_create(hdlr_mod, logger, session, meta, **options):
args = ['stat', '--printf', '%04a,%U,%G,%x,%y', meta['path']]
out, err = subprocess.Popen(args, stdout=subprocess.PIPE, stderr=subprocess.PIPE).communicate()
s = str(out.decode('UTF-8')).split(',')
print(s)
obj = session.data_objects.get(meta['target'])
obj.metadata.add("filesystem::perms", s[0], '')
obj.metadata.add("filesystem::owner", s[1], '')
obj.metadata.add("filesystem::group", s[2], '')
obj.metadata.add("filesystem::atime", s[3], '')
obj.metadata.add("filesystem::mtime", s[4], '')
session.cleanup()
Create custom event handler locally
Custom Metadata Annotation
Should we want this module to register in place, we can simply change the operation returned to REGISTER_SYNC or REGISTER_AS_REPLICA_SYNC
python -m irods_capability_automated_ingest.irods_sync start ./src_dir /tempZone/home/rods/put_coll --event_handler stat_eventhandler --synchronous --progress
Launch the ingest job
$ ils -L put_coll/dir2/file199
rods 0 targetResc 0 2018-11-08.16:51 & file199
generic /tmp/irods/target_vault/home/rods/put_coll/dir2/file199
Check our results
Custom Metadata Annotation
$ imeta ls -d put_coll/dir2/file199
AVUs defined for dataObj put_coll/dir2/file199:
attribute: filesystem::group
value: irods
units:
----
attribute: filesystem::perms
value: 0644
units:
----
attribute: filesystem::atime
value: 2018-11-08 16:51:29.378976820 +0000
units:
----
attribute: filesystem::mtime
value: 2018-11-08 16:46:18.937475894 +0000
units:
----
attribute: filesystem::owner
value: irods
units:
Inspect our newly annotated metadata
The Landing Zone
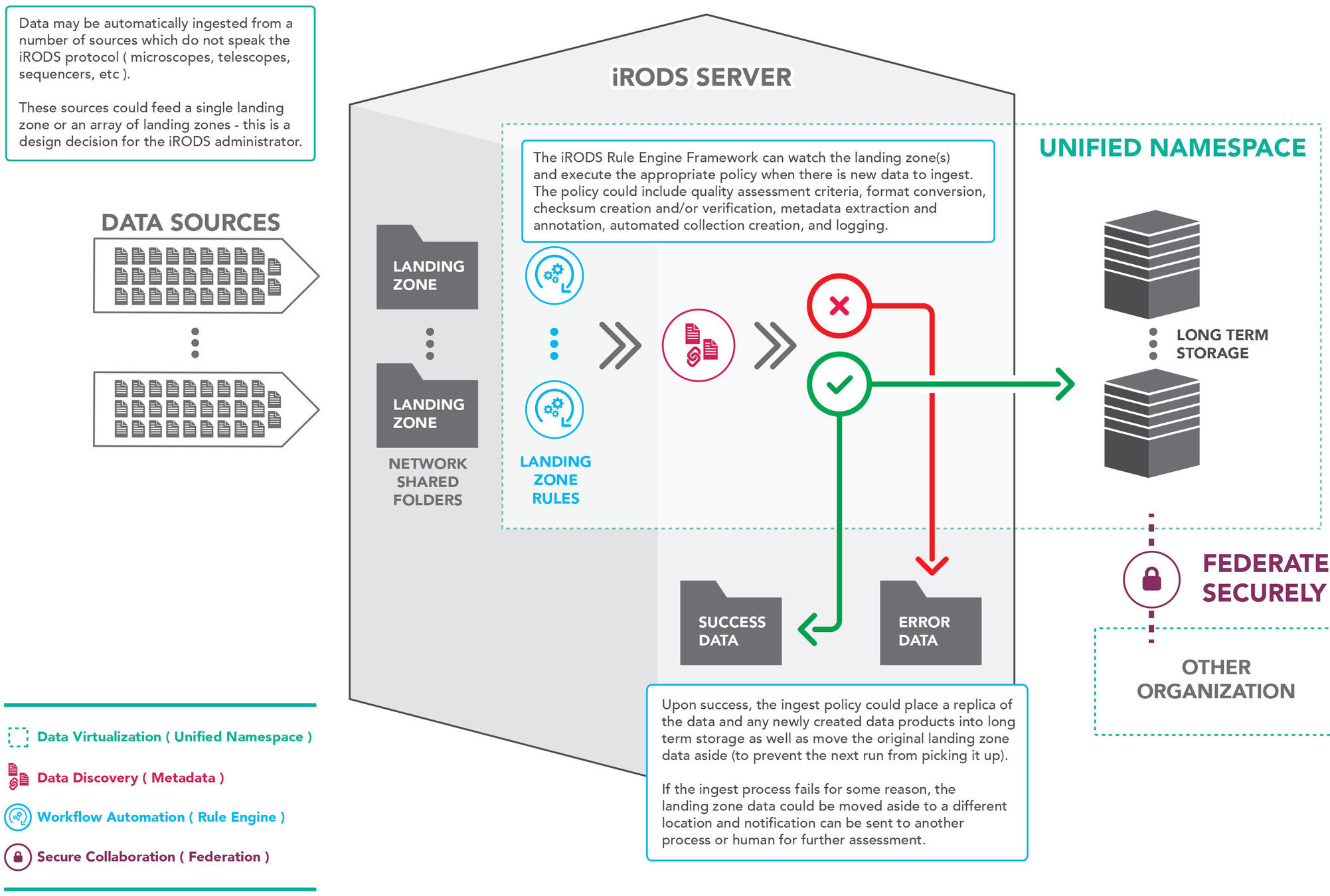
The Landing Zone
In this use case, data is written to disk by an instrument or another source we can run an ingest job on that directory. Once data is ingested it is moved out of the way in order to improve ingest performance. These ingested files can be removed later as a matter of local administrative policy.
The critical difference between a pure file system scan and a landing zone is that the LZ is not considered the single point of truth, it is a staging area for ingest (moving files out of the way).
In a file system scan, the file system is the canonical replica and the catalog and other replicas are kept in sync.
The Landing Zone
Create a new ingest collection
imkdir lz_coll
Create the landing zone and ingested directories
mkdir /tmp/landing_zone
mkdir /tmp/ingested
Stage data for ingest
cp -r /tmp/test_dir /tmp/landing_zone/dir0
Preparing a Landing Zone
The Landing Zone
# /var/lib/irods/lz_eventhandler.py
import os
from irods_capability_automated_ingest.core import Core
from irods_capability_automated_ingest.utils import Operation
class event_handler(Core):
@staticmethod
def operation(session, meta, **options):
return Operation.PUT
@staticmethod
def post_data_obj_create(hdlr_mod, logger, session, meta, **options):
path = meta['path']
new_path = path.replace('/tmp/landing_zone', '/tmp/ingested')
try:
dir_name = os.path.dirname(new_path)
os.makedirs(dir_name, exist_ok=True)
os.rename(path, new_path)
except:
logger.info('FAILED to move ['+path+'] to ['+new_path+']')
Using default resource (demoResc)
The Landing Zone
python -m irods_capability_automated_ingest.irods_sync start /tmp/landing_zone /tempZone/home/rods/lz_coll --event_handler lz_eventhandler --synchronous --progress
Launch the ingest job
ls -l /tmp/ingested/dir0
Check the ingested directory for the files
ls -l /tmp/landing_zone/dir0
Ensure landing zone directory is clean
ils -L lz_coll/dir0/file199
Check the landing zone collection
Scanning S3 buckets
$ python -m irods_capability_automated_ingest.irods_sync start \
/bucket_name/path/to/s3/folder \
/tempZone/home/rods/dest_coll \
--s3_keypair /path/to/keypair_file \
--s3_endpoint_domain s3.amazonaws.com \
--s3_region_name us-east-1 \
--s3_proxy_url myproxy.example.org
Just point the scanner at the bucket
S3 object semantics notwithstanding, this is exactly the same as a filesystem scan
Questions?