Computation and Data Management

Jason Coposky, Interim Executive Director
Goals

- Review some potentially useful components floating around at RENCI
- Discuss possible proof of concepts
- Catch up on iRODS at IBM
Trends in Data with respect to Computation
Drive towards "reproducible science" - just seen at MSST 2016
- Superfacility: How new workflows in the DOE Office of Science are influencing storage system requirements http://storageconference.us/2016/Slides/KatieAntypas.pdf
- Data-Intensive Workflows A journey to a Holistic Framework for Data-Intensive Workflows http://storageconference.us/2016/Slides/IanCorner.pdf
This is already a feature provided by iRODS implemented one of two ways:
- Take the data to the computation
- Take the computation to the data
Driven by the layer in the stack at which iRODS is integrated
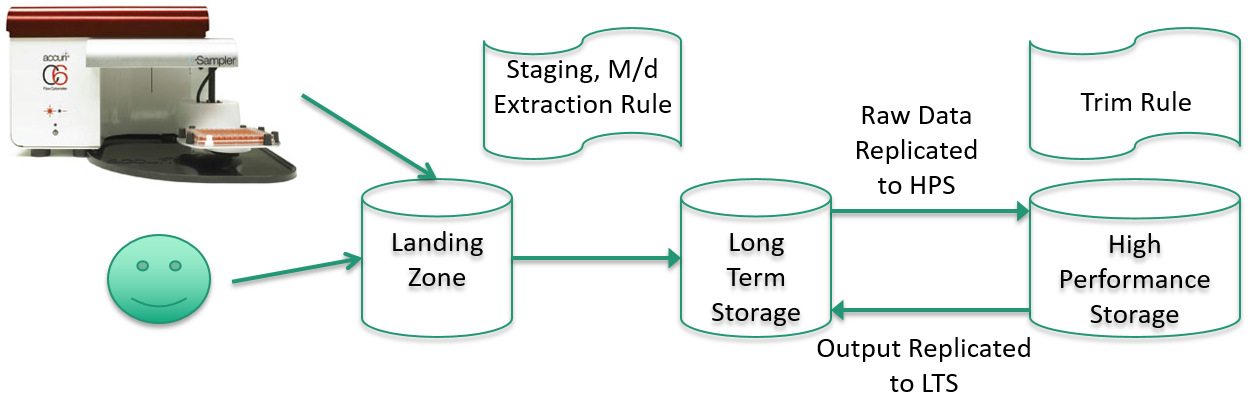
A Health Science Institute
1. Instrument or user palces raw data into landing zone subdirectory
2. Staging rule moves data from landing zone to LTS
3. Metadata extraction rule pulls m/d from data AND organizes raw data into
project collections
4. Data is replicated to high performance storage for processing
5. Processing results replicated to long term storage
6. Trim rule periodically deletes replicas from high performance storage
Computational Resources
iRODS 'resource server' as a compute node - take the compute to the data
Derived from the iPlant project at the University of Arizona
https://docs.google.com/presentation/d/1gyYCU0YZGDO-MHNZxd41t5FcTlqhy7uMKQJsaz2qitc/edit?usp=sharing
Reference Implementations
Derive a collection of use cases from existing IBM customers?
Build a packaged reference implementation of 'science in a box' for:
- Pharma
- Genomics Institutes
- Life / Environmental Science
Work with RENCI on a Proof of Concept and combine both approaches into a flexible reference architecture
- RENCI Genomics Data Grid
- POWER8 compute nodes
- GPFS storage
- Tiering to Cleversafe Object Storage
iRODS and IBM
- IBM Sales team training
- VM configuration for CI
- we need IBM technologist time to
- create templates
- assist in creating Ansible deployment
- we need IBM technologist time to
- Connect GPFS to P8
- move hardware, power cables, configuration
- Redhat - POWER8 Relationship
- Move to Centos for agility and open source
- Will need assistance creating images