Map Reduce
Talk by Kieran Andrews
http://kieranandrews.com.au
Map Reduce
...programming model for processing large data sets with a parallel, distributed algorithm on a cluster.
Basics
Map
filtering and sorting
This distributes the set into smaller problems
Reduce
collects all the answers to the sub problems
and combines them
In Ruby
rainbow = ['red', 'orange', 'yellow', 'green', 'blue', 'purple']
rainbow.select {|color| color.size >= 5}# ['orange', 'yellow', 'green', 'purple']
rainbow.map {|color| color.upcase}# ['RED', 'ORANGE', 'YELLOW', 'GREEN', 'BLUE', 'PURPLE'
# number of colorsrainbow.reduce(0) {|acc, n| acc += 1}# 6
How about Highly dIstributed?
The chunks (during map) can be processed in parallel
Distribute this across several servers (100s)
word_chunks.map do |chunk|
assign_to_server(count_words(chunk)) #[{"the" => 1}, {"cat" => 1}, {"the" => 1], {"dog" => 1}]
end Improves performance for large data sets
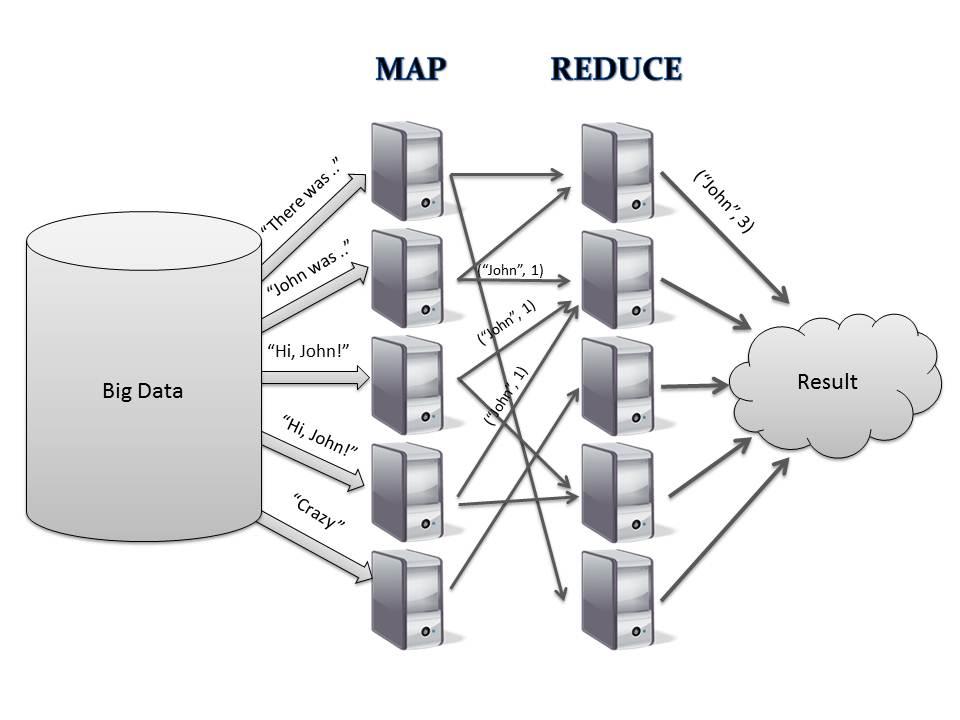
Example Time
Normally do on something like Hadoop
Local example showing the concept
Hadoop
open source project
for storing and large scale processing of data-sets on clusters of commodity hardware
apache foundation
MongoDB
Also supports mapreduce!
Try it out yourself, mapreduce with mongo in the browser
RubyGem for MapReduce with Mongo:
Fin
Thanks
Hope you enjoyed.