Text
Profile
- Github: kyamaguchi
- Freelance Software Developer
- Ruby, Rails
- Like / Interest
- English
- Sublime Text
- Data analysis (R, Python)
- TDD, Pair programming, Browser testing
Tsundoku 積ん読
Do you have Tsundoku?

Tsundoku 積ん読
What is Tsundoku(積ん読)?
buying books and not reading them
Jisho.org
Compound of 積む (tsumu, “to pile up”) + 読 (doku, “reading”), punning on 積んどく (tsundoku), contraction of 積んでおく
(tsunde oku, “to leave piled up”).
Wikitionary
My problem
Do you read books on tablet?
I have so many kindle books.
(3000+ books including samples, free books)
I have so many unread kindle books.
It’s hard to find books on Kindle UI.
No API for Kindle books.
No OAuth
Goal
Build an app to manage kindle books
Main libraries/tools
- Ruby
- capybara + selenium-webdriver
- nokogiri
- Chrome
- chromedriver
Scrape it
Steps to scrape kindle books data
- Sign in
- Download pages
- Parse pages
- Output data
Sign in
I split this part in a library(gem).
Check out amazon_auth gem.
- Simple and reversible conversion of credentials
- Store it in dotenv(.env)
- Initialize Capybara session
- Basic commands to sign in and common utility
Sign in Amazon

Convert credentials

Scrape it
Steps to scrape kindle books data
- Sign in
- Download pages
- Parse pages
- Output data
Download pages
I build a library for this part.
Check out kindle_manager gem.
I suppose users update data periodically(daily). This library will
- Have limit on downloading
- It isn’t practical to Download all data every time
- Store(append) new pages to existing download directory
- ‘session.save_page(html_path)’
- ‘session.save_screenshot(image_path)’ (Not necessary)
- Don’t care duplicates of data among pages
- Output will be the same if there is no update(idempotence)
Fetch kindle books list

Tips for downloading
- Ensure page loading includeing ajax
- => use Capybara methods
- Read text, number, date, links in the page instantly
- => use Nokogiri methods
- Expose methods
- Retry/debug interactively on console
- Use more sleep (than testing)
- Good for the site
Ensure page loading
Helper for page loading
def wait_for_selector(selector, options = {})
options.fetch(:wait_time, 3).times do
if session.first(selector)
break
else
sleep(1)
end
end
end
- ‘default_max_wait_time’ of capybara may be enough
- It gives more controls
- Logging
- Change duration of sleep by action
Session and Document
attr_accessor :session
def initialize(options)
@session = options.fetch(:session, nil)
@options = options
...
end
def doc
Nokogiri.HTML(session.html)
end
- Delegate Capybara::Session object
- No memoization with Nokogiri Document
Capybara or Nokogiri
def number_of_fetched_books
# Capybara method
wait_for_selector('.contentCount_myx')
# Nokogiri method
text = doc.css('.contentCount_myx').text
...
end
- 1st, ensure dom with capybara methods
- capybara waits page loading in some way
- 2nd, read dom with nokogiri methods
- Because it’s faster
Example of downloading
class BooksAdapter < BaseAdapter
def load_next_kindle_list
wait_for_selector('.contentCount_myx')
current_loop = 0
while current_loop <= max_scroll_attempts
if limit && limit < number_of_fetched_books
break
elsif has_more_button?
snapshot_page
current_loop = 0
log "Clicking 'Show More'"
show_more_button.click
else
log "Loading books with scrolling #{current_loop+1}"
session.execute_script "window.scrollBy(0,10000)"
end
sleep fetching_interval
current_loop += 1
end
snapshot_page
end
Implementation of downloading
Code is’t clear because
- Hard to test downloading part
- It could fail depending on machine
- height of browser, network
- Response time from the site could be random
- Many code for logging
- Should use less instance variables
Capybara vs. Direct http requests
Capybara
- Much easier to get data
- Don’t need to know the spec of requests
Direct http requests
- If the spec of requests is known,
- Possible to control params
- page size, offset of pagination etc.
- Possible to control params
- Testable with vcr
- Easier when json response is available
- (I guess) more possibilities to be banned
Scrape it
Steps to scrape kindle books data
- Sign in
- Download pages
- Parse pages
- Output data
Tips for parsing
- Create parser model for page
- Initialize with filepath or html
- Create parser model for records
- Initialize with a node for a record
- Use memoization
- TDD helps a lot
Parser model for page
class BooksParser
def initialize(filepath, options = {})
@filepath = filepath
end
def doc
@doc ||= Nokogiri::HTML(body)
end
def body
@body ||= File.read(@filepath)
end
Parser model for records
class BooksParser
def parse
@_parsed ||= doc.css("div[id^='contentTabList_']").map{|e| BookRow.new(e) }
end
class BookRow
def initialize(node)
@node = node
end
def asin
@_asin ||= @node['name'].gsub(/\AcontentTabList_/, '')
end
def title
@_title ||= @node.css("div[id^='title']").text
end
Scrape it
Steps to scrape kindle books data
- Sign in
- Download pages
- Parse pages
- Output data
Output data
@parser.parse.first.asin
#=> "B004YW6M6G"
@parser.parse.first.title
#=> "Design Patterns in Ruby"
puts @parser.parse.to_json
#=> [{"asin":"B004YW6M6G","title":"Design Patterns in Ruby", ...
Print data on console

Troubles
- Security of amazon
![:cop:]()
- You could be asked security question
- Compatibility of libraries
- It’s getting harder to find compatible libraries for recent Firefox
- FireFox + gechodriver + selenium-webdriver
- Just use Chrome & chromedriver
- It’s getting harder to find compatible libraries for recent Firefox
- Normalization of data (名寄せ)
- 全角スペース、全角英数 (full-width)
- Special whitespace characters
Some fact(mystery) of amazon security
- Sleep on key strokes doesn’t help
- Security question could be displayed after some tries
- 3 ~ 5 times of successful signin in a short time
- CAPTCHA could be displayed 3 ~ 5 times in a row
- when you click submit button with code
- CAPTCHA passes when you press submit button manually
- Do amazon check mouse movement or scroll or something?
Patterns of Security questions
- Ask characters in image (captcha)
- Ask registered phone number
- Ask registered zip code
- Ask security code through email
Security of credentials
I assume this library is used in private projects/machines.
It doesn’t have strong protection of credentials.
There is a tool called envchain which works with macOS Keychain.
This can be used as an alternative of dotenv.
The app I created

Tsundoku app can
- Fetch/import kindle books list
- Quick search/filter
- Tagging (free words)
- Read, Hope to read
- Sample (automatically tagged)
- Checked etc.
Official kindle books site
Reading status, rating, public notes
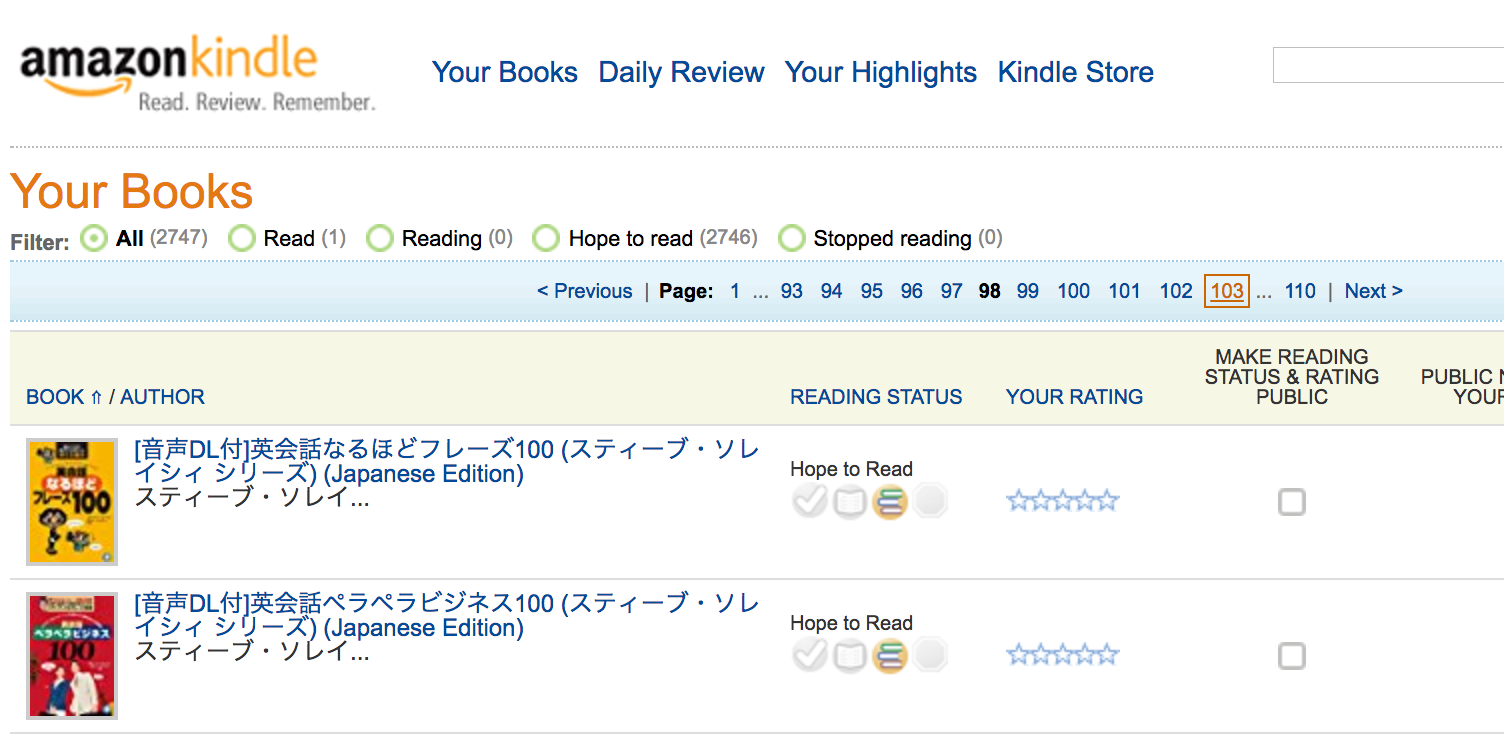
Result
- I have so many half price books or free books
- 1000+ comics
- 300+ sample books
- I’m getting more sample books than before
- Time for reading books didn’t increase
- But I learnt Ruby programming more than reading
- Now I have long list of Netflix
Other usage of capybara
- Smoke test
- Daily diagnostic
- Check sites requiring signin
- Possible to check GMail
- Captures, Recording
- Data collection for data analysis
- more
General News
- System test in Rails5
- Chrome headless
- phantomjs will be deprecated
- capybara-webkit continues
Wrap up
- Try it out / Star it
![:star:]()
- Check out GitHub
![:octocat:]() /kyamaguchi
/kyamaguchi
- kindle_manager
- tsundoku
- Check out GitHub
- TODO/Idea
- Limit fetching of records by date
- Integration with amazon orders(calculate expenses)
- Get metadata of amazon products
- Get data from other sites
- Pragmatic Bookshelf, Oreilly etc.
- Remind random books
Bonus (kindle highlights)
The site for Kindle notes and highlights is closing
(August 1st, originally July 3rd)

New site for highlights
New site for Kindle notes and highlights
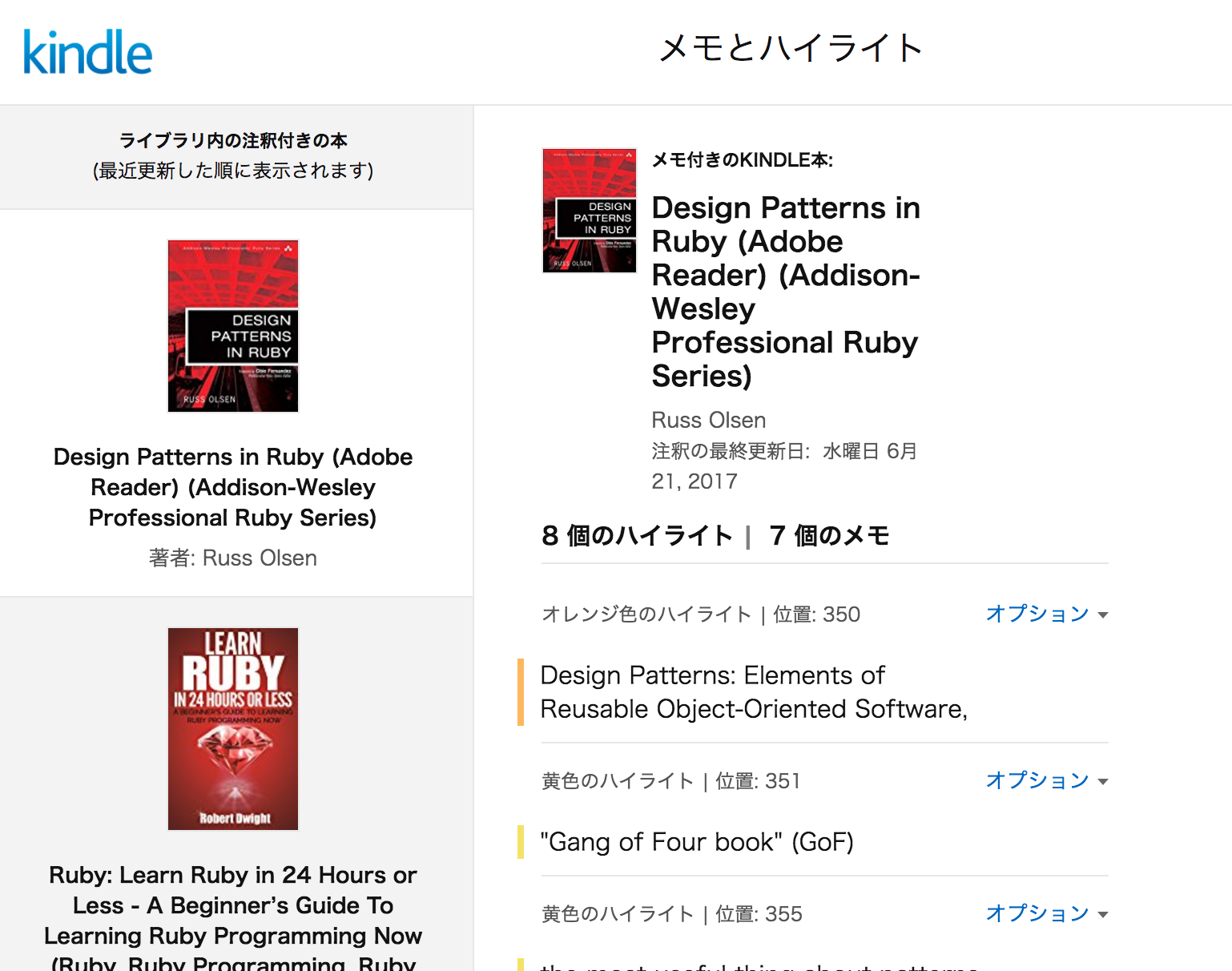
Demo app for kindle highlights
I have an app to collect kindle highlights
- Check out kindle_highlight app
- And kindle_manager gem.
- kindle_manager now supports to get kindle highlights
- kindle_manager works inside heroku
Use chromedriver in heroku
heroku buildpacks:add https://github.com/heroku/heroku-buildpack-chromedriver
heroku buildpacks:add https://github.com/heroku/heroku-buildpack-xvfb-google-chrome
Any questions
I have some experience of capybara/testing.
Ask me later if you have questions something like
- Debug spec which fails only on CI
- Take screenshots in closed instances(Travis CI, heroku)
- Keep(save/restore) cookies in different sessions
- vcr (Record api testing of external services)
How to keep cookies with capybara
session = Capybara::Session.new(:chrome)
# login
session.visit 'https://github.com/login'
session.fill_in 'login_field', with: ''
session.fill_in 'password', with: ''
session.click_on 'Sign in'
# store cookies
data = Marshal.dump session.driver.browser.manage.all_cookies
File.open('all_cookies.txt', 'wb') {|f| f.write(data)}
session.driver.quit
Restore cookies with capybara
session = Capybara::Session.new(:chrome)
# First visit is required before restoring cookies
session.visit 'https://github.com/'
# restore cookies
data = File.read('all_cookies.txt')
Marshal.load(data).each do |d|
session.driver.browser.manage.add_cookie d
end
session.visit session.current_url
Store cookies into database
- The data with Marshal doesn’t work with postgres text column
- Restored hash data from json column needs some conversion
# Store 'session.driver.browser.manage.all_cookies' into json column
cookies_from_db.each do |d|
# :name needs to be symbol on 'add_cookie'
d.symbolize_keys!
# :expires needs to be Time class
d[:expires] = Time.parse(d[:expires]) if d[:expires]
session.driver.browser.manage.add_cookie d
end
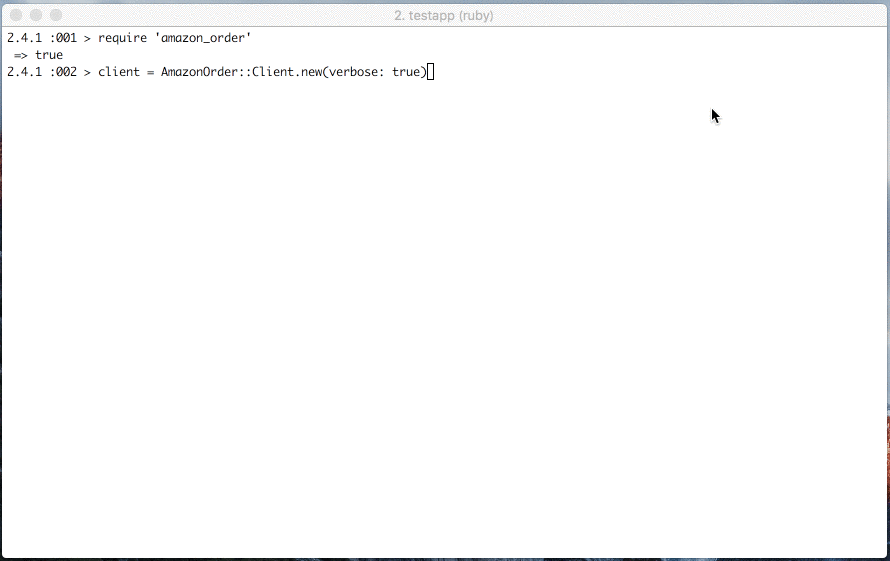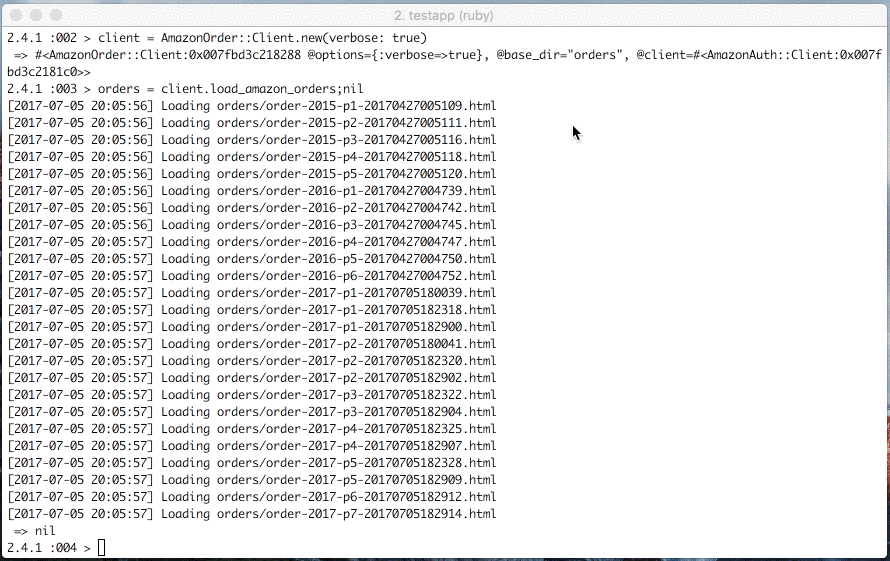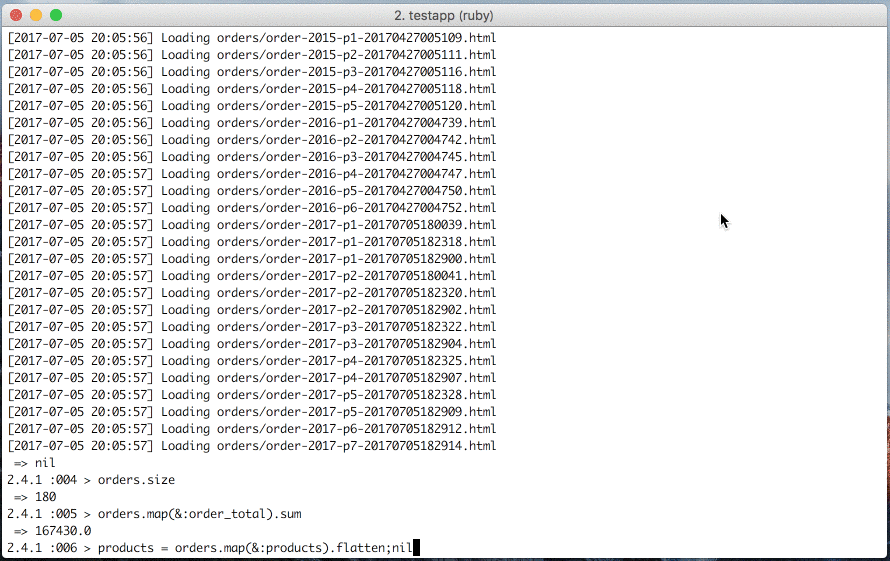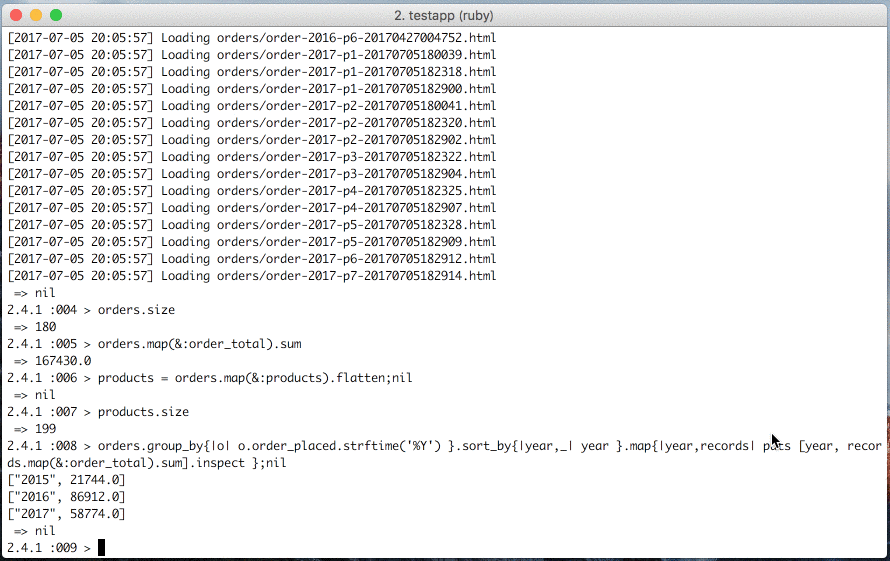
Fetch amazon orders
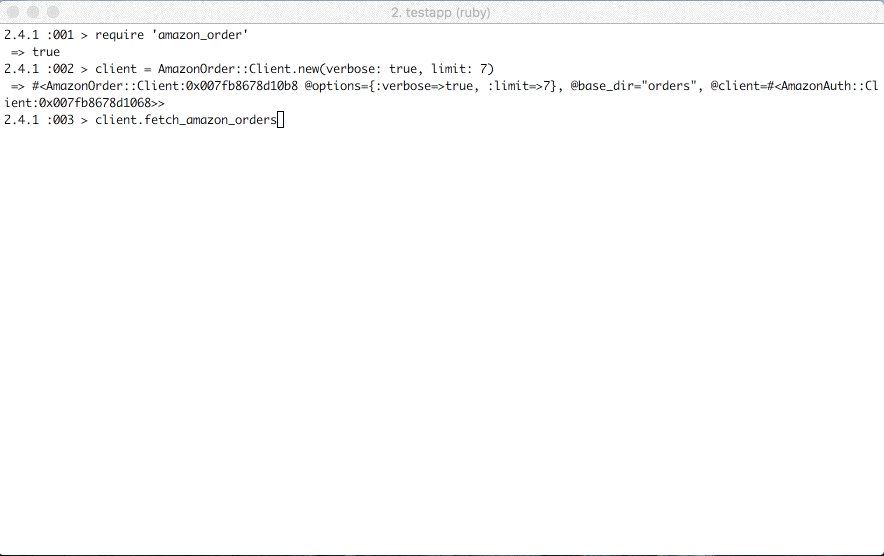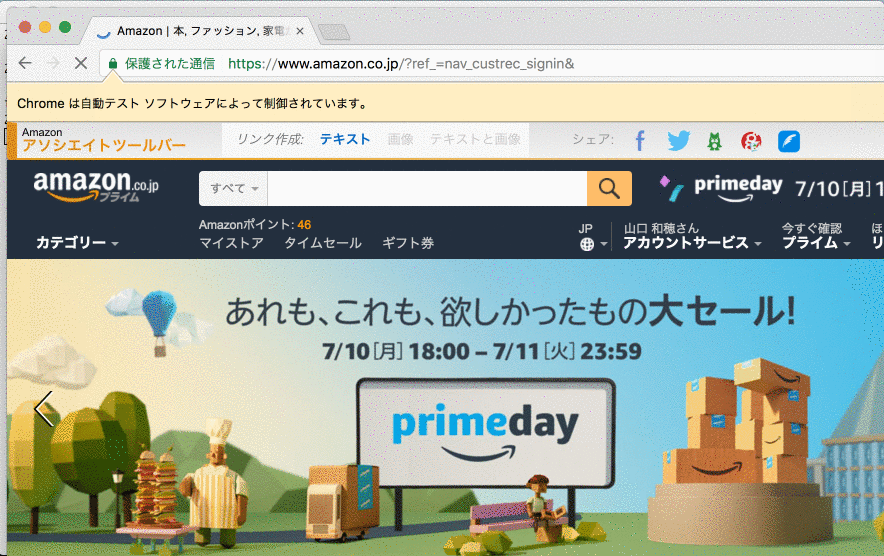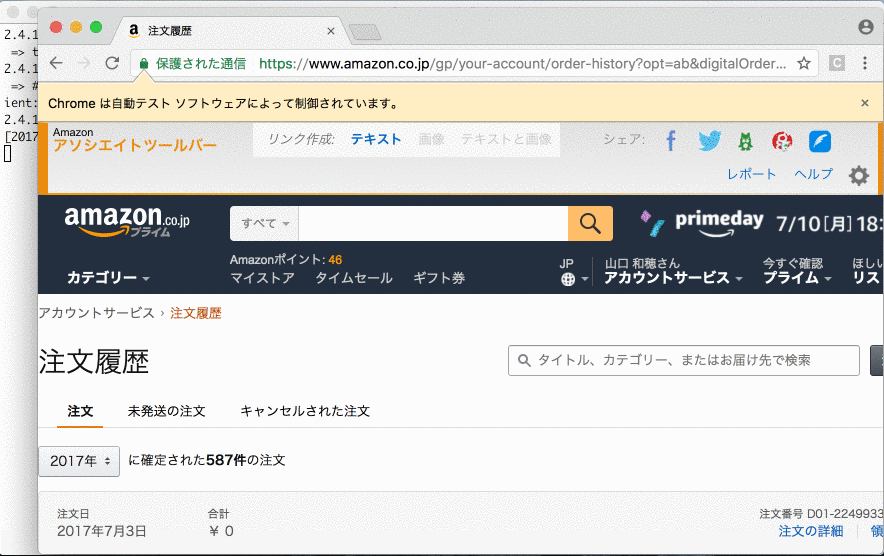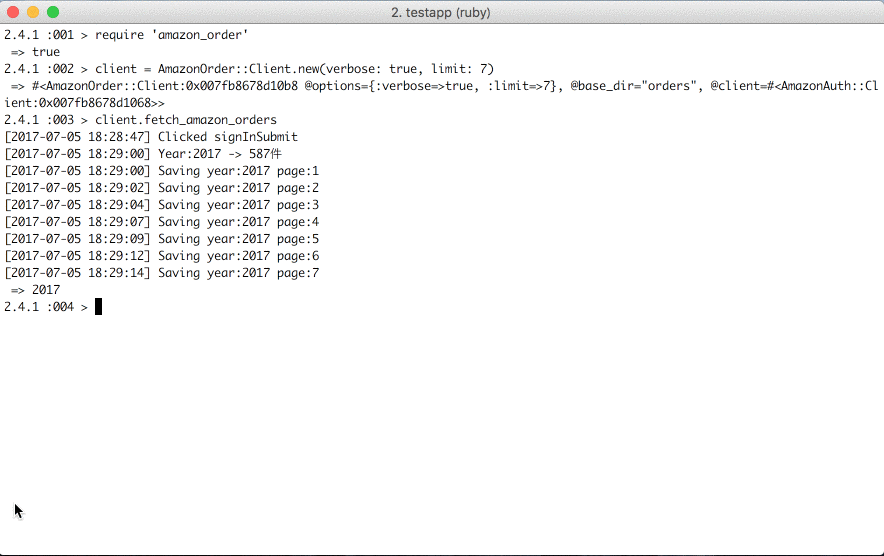
Load amazon orders