Scaling Facebook Analytics Infrastructure with MongoDB & node.js

Matt Insler, West Coast Director of Engineering, Unified Social
mattinsler.com
github.com/mattinsler
www.unifiedsocial.com
Street Cred:
Defense - I could tell you, but then I'd have to...
Banking - MongoDB version 0.4?
PageLever - First engineering hire
Unified - Head of West Coast DevMongo & node in production:
Analytics Minilytics Now
Facebook Analytics Data
(what we're working with)
- Page-level data published once a day at 2 AM PT, and varies between 2-7 days behind current date
- Post-level data published every 10-15 minutes
- Polling is the only option
- API limits are roughly 600 calls per 600 seconds per API token
Our first take, circa 2011:
- Monolithic Rails App
- MongoDB 1.8 on MongoHQ cloud
- queue_classic for jobs
- TONS of workers to pull down Page data
- 1 worker per page at a time
- ~1,000 Pages per hour
First Take - Problems:
- Little visibility into errors or problems (our fault)
- Just ~1000 Pages per hour (Ruby's fault)
- Data structure: KISS principal
- Dots in keys (our fault)
{
fb_page_id: '...',
metric: 'page_fans',
period: 'lifetime',
data: {
'2013-01-01': 0,
'2013-01-02': 3,
...
}
}But it got the job done.
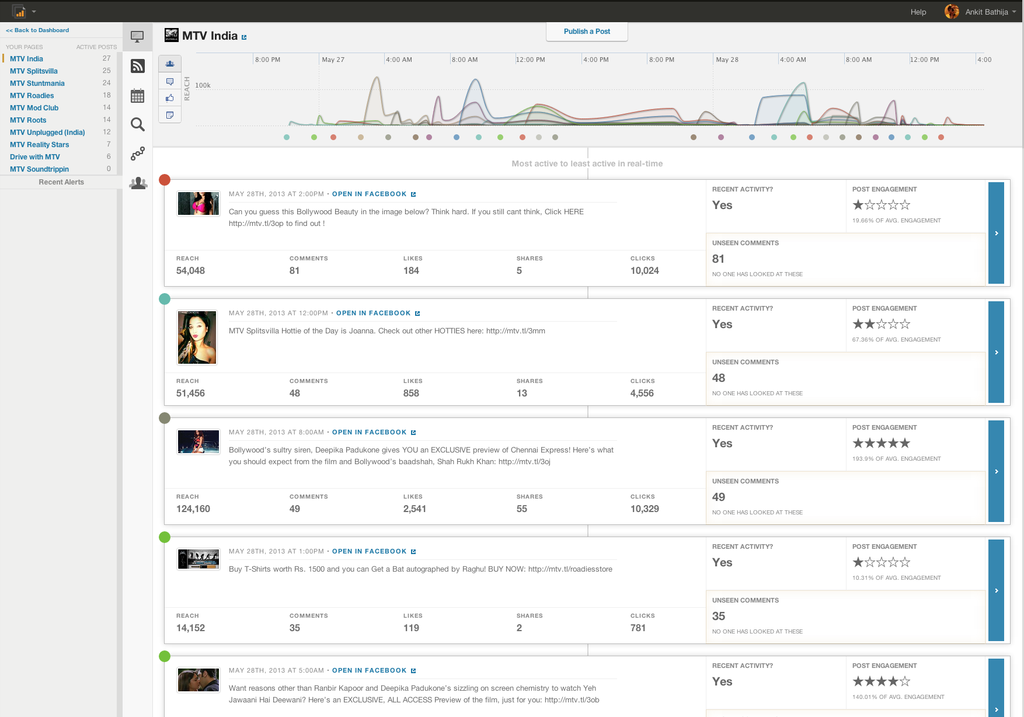
Then we started building new apps:
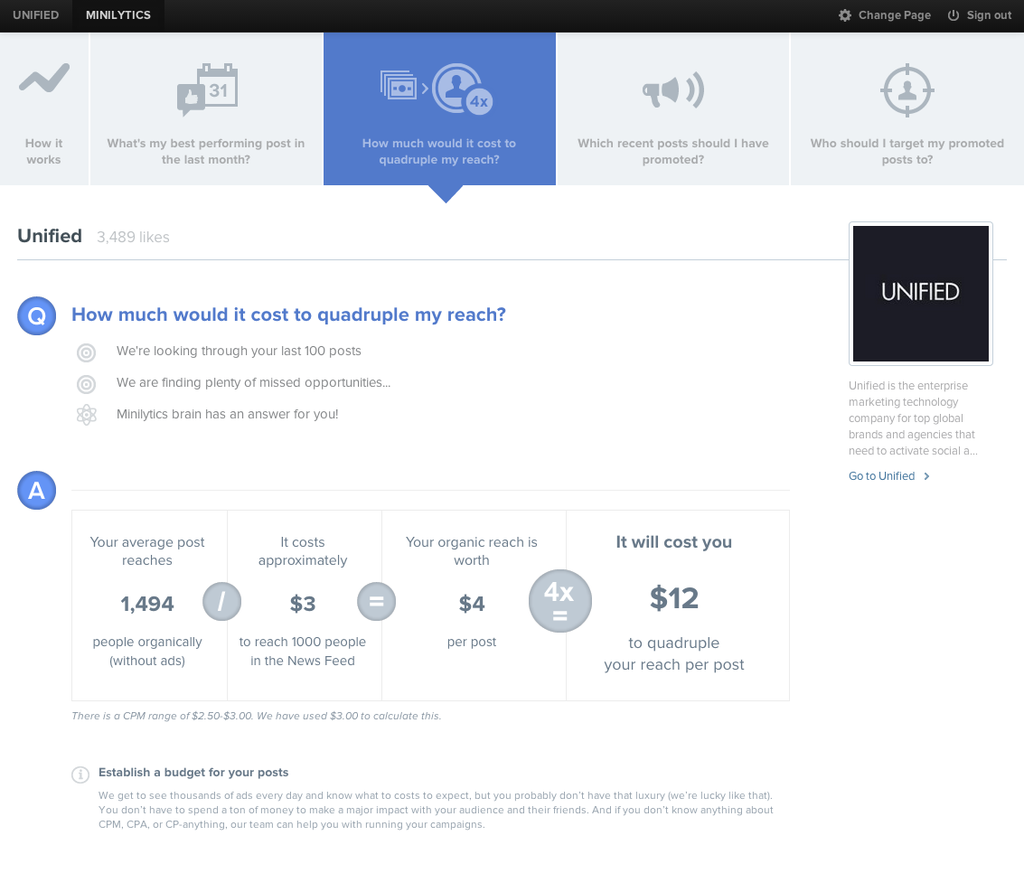
The Big Kahuna:
Requirements:
- Collect, store and update data in "real-time", despite the lack of a true real-time API
- Lots of data & lots of calls (posts, likes, comments, shares)
- Run custom logic for derived metrics
Thousands of Facebook Pages
x
Dozens of API requests per Page
x
Every 10-15 minutes
x
24/7
=
HARD.
Time for BIG changes:
- New sync system in node.js, complete rewrite
- New durable queuing system (home grown)
- Queue introspection
- Error Visibility
- Operation Statistics
- Retry to deal with 10-15% error rate from Facebook
- Heroku auto-scaling (homegrown)
- Write / Upsert-only methodology
Wins
- Loads of concurrency
-
1,000 Pages/hour => 1,000 Pages/minute
- Less servers, less $$
- 4k+ writes/sec to Mongo
Oh shit, mongo
-
Single documents for time-series data
- Documents grow and reallocate leaving huge holes in memory (oops, compaction issues in SQL vs Mongo)
-
Global write lock (CPU-bound)
-
Write queue length > 50 on average (up to 600 at times)
-
Not a ton of room to take on more data/concurrency
Fixing mongo (thanks MongoHQ)
- Time-series data laid out as single documents
- Moved to bare-metal boxes
- Sharded 8 DBs on 2 boxes (8x write throughput)
- 4 master/4 slave per box
- Moved to SSDs (10x write throughput)
Lesson
-
You can scale up for less than scaling out
-
Sharding on a single box can fix write throughput
-
Sharding makes backups difficult to deal with
Oh shit, node
- I/O Concurrency is different than concurrency
- CPU intensive tasks are still blocking
- RAM limitations on your hosting environment
- Just because you have 10MB of JSON, doesn't mean it's not 100MB parsed
- Log and catch errors everywhere
- Beware of DB server connection issues
My friend node
-
Make small jobs that mainly do I/O
- Limit work done per worker to fit in RAM
- Auto-scale to do more work when necessary
- Child processes catching 'uncaughtException' and logging
- Monitor DB connection errors and restart automatically
So much more
- Customer base is expanding
- Data collected is expanding
- So many social networks, so little time
Have ideas?
Want to help?
Unified Social
www.unifiedsocial.com
careers@unifiedsocial.com
Matt Insler
mattinsler.com
github.com/mattinsler
matt@unifiedsocial.com