Open source AFU framework for streaming applications with CAPI connected FPGAs
Matthijs Brobbel
October 7, 2015
Delft University of Technology
CAPI
- Coherent Accelerator Processor Interface (CAPI)
- Coherent Attached Processor Proxy (CAPP)
- POWER Service Layer (PSL)
- Application Functional Unit (AFU)
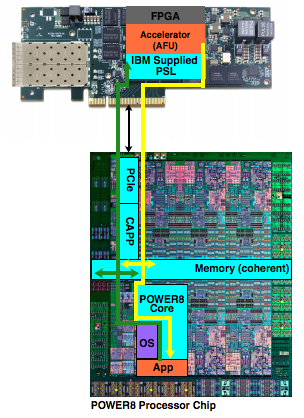
Coherent Accelerator Processor Interface Overview (From: Coherent Accelerator Processor Interface Users Manual, IBM, Jan 2015)
AFU
PSL
CAPI
CAPP
libcxl
APP
Memory
Cache
FPGA
PCI-E
POWER8
Work Element Descriptor
- Struct in system memory with task description
- Status byte
- Pointers to source data
- Pointers to allocated memory for results
- Function arguments
- Pointer to next WED
- Pointer to WED is passed when attaching the AFU
Original
Compute intensive kernel
...
...
...
with CAPI
...
...
...
Setup WED
Attach AFU
Wait for AFU
Host application
Setup WED
Attach AFU
Wait for AFU
struct wed {
__u8 volatile status; // 7 downto 0
__u8 wed00_a; // 15 downto 8
__u16 wed00_b; // 31 downto 16
__u32 size; // 63 downto 32
__u64 *source; // 127 downto 64
__u64 *destination; // 191 downto 128
__u64 wed03; // 255 downto 192
__u64 wed04; // 319 downto 256
__u64 wed05; // 383 downto 320
__u64 wed06; // 447 downto 384
__u64 wed07; // 511 downto 448
__u64 wed08; // 575 downto 512
__u64 wed09; // 639 downto 576
__u64 wed10; // 703 downto 640
__u64 wed11; // 767 downto 704
__u64 wed12; // 831 downto 768
__u64 wed13; // 895 downto 832
__u64 wed14; // 959 downto 896
__u64 wed15; // 1023 downto 960
};
// allocate memory for WED
struct wed *wed0 = NULL;
if (posix_memalign ((void **) &(wed0), CACHELINE_BYTES,
sizeof(struct wed))) {
return -1;
}
// set WED fields
wed0->status = 0;
...Setup WED
Attach AFU
Wait for AFU
// libcxl
#include "libcxl.h"
#define DEVICE "/dev/cxl/afu0.0d"
...
// open afu device
struct cxl_afu_h *afu = cxl_afu_open_dev ((char*) (DEVICE));
if (!afu) {
perror ("cxl_afu_open_dev");
return -1;
}
// attach afu and pass wed address
if (cxl_afu_attach (afu, (__u64) wed0) < 0) {
perror ("cxl_afu_attach");
return -1;
}Setup WED
Attach AFU
Wait for AFU
while (!wed0->status) {}A framework. Why?
- CAPI offers tons of possibilities and design choices
- Very powerful but time consuming for simple designs
- Not a lot of examples out there
- memcpy (CAPI's Developer Kit)
- capi-textswap (https://github.com/sbates130272/capi-textswap)
-
Implement the actual function in a Computing Unit (CU) which interfaces with some simple control signals and a Direct Memory Access (DMA) engine
Before
After
PSL
AFU
CU
PSL
Abstraction Layer
Abstract over the PSL
- Interface between AFU and CAPP through CAPI
- Works on cache-line basis (128 bytes)
- Credit and tag based request system (64 credits)
- 32 read- and 32 write state machines
- Returns read data out of order
- Effective-to-real-address-translation (ERAT)
- Coherent PSL cache (256 KB)
- 16 opcodes directed at the PSL cache
- 4 opcodes which do not allocate in the PSL cache
- 3 opcodes which can be used for management
- 5 interfaces
Control
MMIO
Command
Buffer
Response
Control
MMIO
Command
Buffer
Response
Start, reset and stop the AFU
Send read and write commands from the AFU
Receive read data and send write data
Acknowledge completed commands
AFU descriptor, debugging and control
Streaming applications
- Read large amounts of data and receive them in order
- Multiple read and write streams
- Queue multiple read and write requests
- Rarely any benefit from the PSL cache
Control
MMIO
Command
Buffer
Response
Control
CU
DMA
MMIO
Framework
Control
- Take care of start and stop phase of the AFU
- Grabs the WED data, parses it into a record and sends it to the CU together with a start signal
- Connects the CU to the DMA engine and wait for completion of the CU
- Update the status byte in the WED upon completion of the CU
MMIO
- Registers within the AFU that can be read and written from both the host and the AFU
- Used during initialization to get the AFU descriptor
- Can be used for debugging and polling from the CU side
- Could also be used for control from the host side
DMA
- Relatively simple read and write interface
- Unrolling of large requests
- Uses non-allocate opcodes
- Returns read data in order
- Read and write queues
- Write data buffers
- Multiple read and write stream engines (Round-robin like scheduling)
- Option to send touch commands for large requests hitting multiple pages to hide ERAT miss penalty
CU
- Implements accelerator function
- Simple control interface
- Simple DMA interface for data movement
CU I/O
cr.clk
[0]
250 MHz clock
cr.rst
[0]
Reset
start
[0]
Gets set to start CU
wed
[X:0]
Parsed WED record, valid on start
id
[X:0]
Unique identifier for requests
read.
valid
[0]
Valid read data present
id
[X:0]
Identifier for valid read
stream
[X:0]
Stream identifier for valid read
data
[1023:0]
Read data
full
[X:0]
Queue full flag
write.
valid
[0]
Write request completed
id
[X:0]
Identifier for valid write
stream
[X:0]
Stream identifier for valid write
full
[X:0]
Buffer or queue full flag
CU I/O
done
[0]
Set when CU is done
read.
valid
[0]
Present read request
stream
[X:0]
Target stream engine for request
address
[63:0]
Effective read address
write.
request.
valid
[0]
Present write request
stream
[X:0]
Target stream engine for request
address
[63:0]
Effective write address
size
[X:0]
Write size in bytes
data.
valid
[0]
Present write data
stream
[X:0]
Stream identifier for write data
data
[1023:0]
Write data
size
[X:0]
Read size in bytes
DMA procedures
read_byte (v.o.read, address)
read_byte (v.o.read, address, stream)
read_bytes (v.o.read, address, size)
read_bytes (v.o.read, address, size, stream)
read_cacheline (v.o.read, address)
read_cacheline (v.o.read, address, stream)
read_cachelines (v.o.read, address, size)
read_cachelines (v.o.read, address, size, stream)
write_byte (v.o.write, address, data)
write_byte (v.o.write, address, data, stream)
write_cacheline (v.o.write, address, data)
write_cacheline (v.o.write, address, data, stream)
write_bytes (v.o.write.request, address, size)
write_bytes (v.o.write.request, address, size, stream)
write_cachelines (v.o.write.request, address, size)
write_cachelines (v.o.write.request, address, size, stream)
write_data (v.o.write.data, data)
write_data (v.o.write.data, data, stream)
DMA parameters
constant DMA_SIZE_WIDTH : natural := 32;
constant DMA_ID_WIDTH : natural := 32;
constant DMA_READ_QUEUE_DEPTH : natural := 8;
constant DMA_WRITE_QUEUE_DEPTH : natural := 8;
constant DMA_WRITE_BUFFER_DEPTH : natural := 8;
constant DMA_READ_ENGINES : natural := 1;
constant DMA_WRITE_ENGINES : natural := 1;
constant DMA_READ_TOUCH : std_logic := '0';
constant DMA_WRITE_TOUCH : std_logic := '0';
constant DMA_TOUCH_COUNT : natural := 1;
constant DMA_WRITE_PRIORITY : std_logic := '1'; Organization
├── accelerator
│ ├── lib
│ │ ├── functions.vhd
│ │ ├── psl.vhd
│ │ └── wed.vhd
│ ├── pkg
│ │ ├── control_package.vhd
│ │ ├── cu_package.vhd
│ │ ├── dma_package.vhd
│ │ ├── frame_package.vhd
│ │ └── mmio_package.vhd
│ └── rtl
│ ├── afu.vhd
│ ├── control.vhd
│ ├── cu.vhd
│ ├── dma.vhd
│ ├── fifo.vhd
│ ├── frame.vhd
│ ├── mmio.vhd
│ └── ram.vhd
├── host
│ ├── app
│ │ └── src
│ │ └── example.cpp
├── LICENSE
├── Makefile
├── README.md
└── sim
├── pslse
├── pslse.parms
├── pslse_server.dat
├── shim_host.dat
├── vsim.tcl
└── wave.dowed.vhd
cu_package.vhd
cu.vhd
example.cpp
...
v := r;
v.pull := '0';
v.o.read.valid := '0';
v.o.write.request.valid := '0';
v.o.write.data.valid := '0';
case r.state is
when idle =>
if i.start then
v.state := copy;
v.wed := i.wed;
v.o.done := '0';
read_cachelines (v.o.read, i.wed.source, i.wed.size);
write_cachelines (v.o.write.request, i.wed.destination, i.wed.size);
end if;
when copy =>
if not(re.fifo.empty) and not(i.write.full(0)) then
v.pull := '1';
write_data (v.o.write.data, 0, re.fifo.data);
end if;
v.wed.size := r.wed.size - u(i.write.valid);
if v.wed.size = 0 then
v.state := done;
end if;
when done =>
v.o.done := '1';
v.state := idle;
end case;
...
end process;
fifo0 : entity work.fifo generic map (DMA_DATA_WIDTH, 14, '1', 0)
port map (
cr.clk => i.cr.clk,
cr.rst => i.start,
put => i.read.valid,
data_in => i.read.data,
pull => q.pull,
data_out => re.fifo.data,
empty => re.fifo.empty,
full => re.fifo.full
);
... struct wed {
__u8 volatile status; // 7 downto 0
...
__u32 size; // 63 downto 32
__u64 *source; // 127 downto 64
__u64 *destination; // 191 downto 128
...
};
...
int main (int argc, char *argv[]) {
__u32 copy_size = 512;
__u64 *source = NULL;
__u64 *destination = NULL;
// allocate memory
posix_memalign ((void **) &(source), CACHELINE_BYTES,
CACHELINE_BYTES * copy_size);
posix_memalign ((void **) &(destination), CACHELINE_BYTES,
CACHELINE_BYTES * copy_size);
...
// setup wed
struct wed *wed0 = NULL;
posix_memalign ((void **) &(wed0), CACHELINE_BYTES,
sizeof(struct wed));
wed0->status = 0;
wed0->size = copy_size;
wed0->source = source;
wed0->destination = destination;
// open afu device
struct cxl_afu_h *afu = cxl_afu_open_dev ((char*) (DEVICE));
// attach afu and pass wed address
cxl_afu_attach (afu, (__u64) wed0));
// wait for afu
while (!wed0->status) {}
printf("AFU is done.\n");
cxl_afu_free (afu);
...
}example.cpp
cu.vhd
Preliminary results of memcpy
IBM Power System S822
256GB Memory
Ubuntu 15.04 ppc64le 3.19.0-22-generic
Page size 64KB
Nallatech P385-A7 FPGA Accelerator card with 8GB DDR3
Altera Stratix V GX A7 FPGA
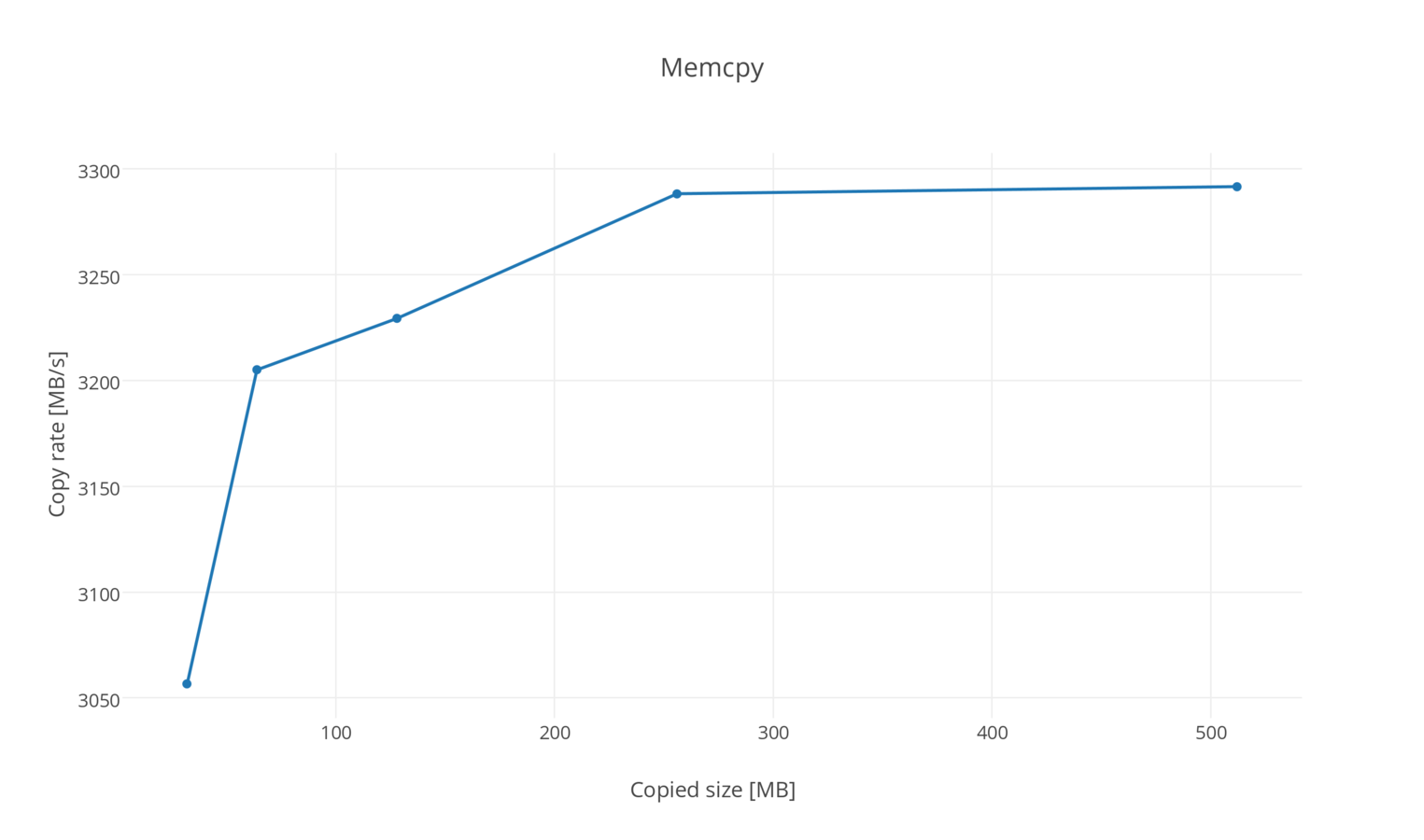
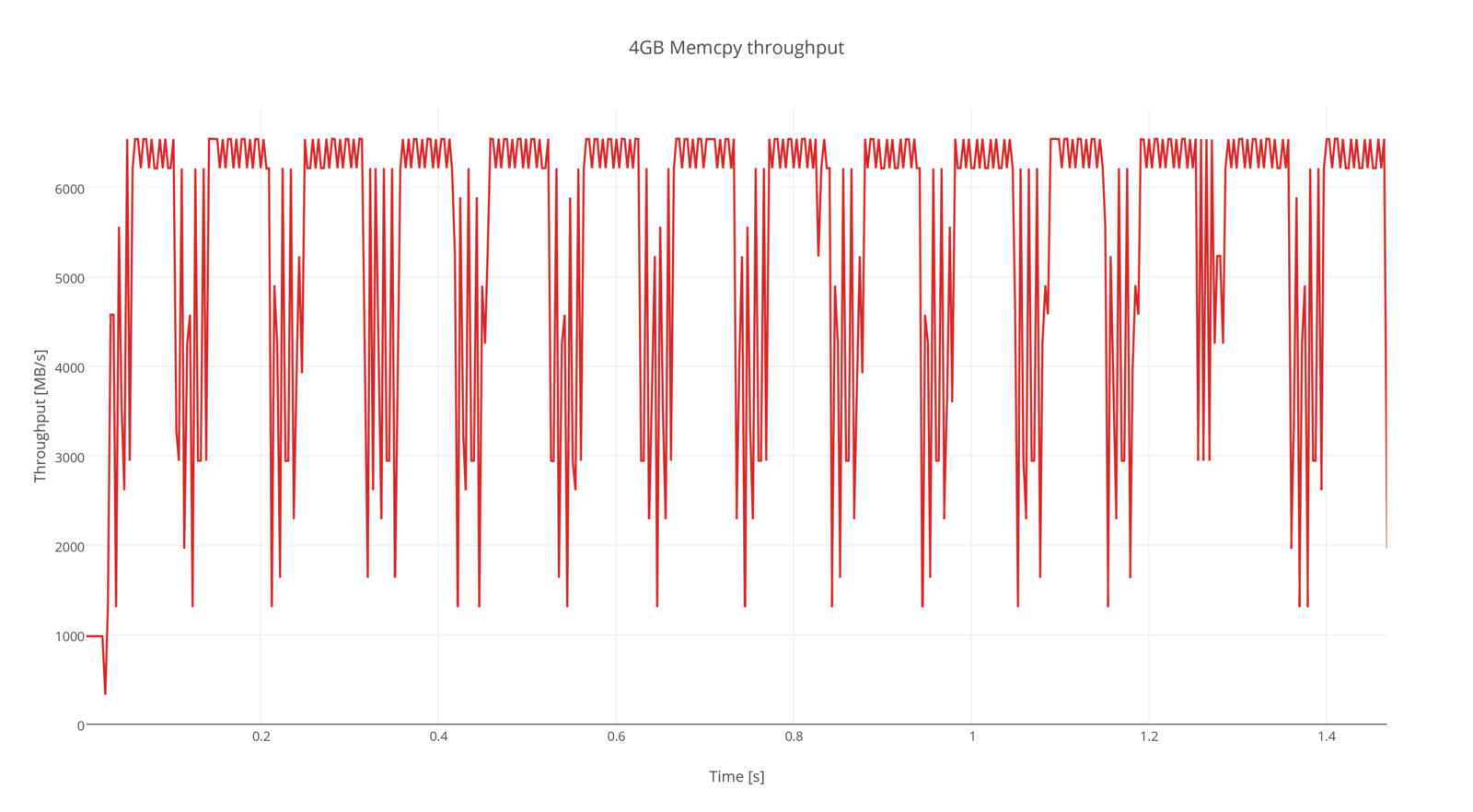
Notes
- VHDL 2008
- (System) Verilog wrapper for CU could be provided
- No device or vendor specific code
- Parameterized design
- Jiri Gaisler's structured design method for VHDL (2 processes) [ http://www.gaisler.com/doc/vhdl2proc.pdf]
- BSD 2-Clause License
- Available at Github
[https://github.com/mbrobbel/capi-streaming-framework] - Work in progress
Start accelerating today
?
Thank you!