Intro to Data Cleaning
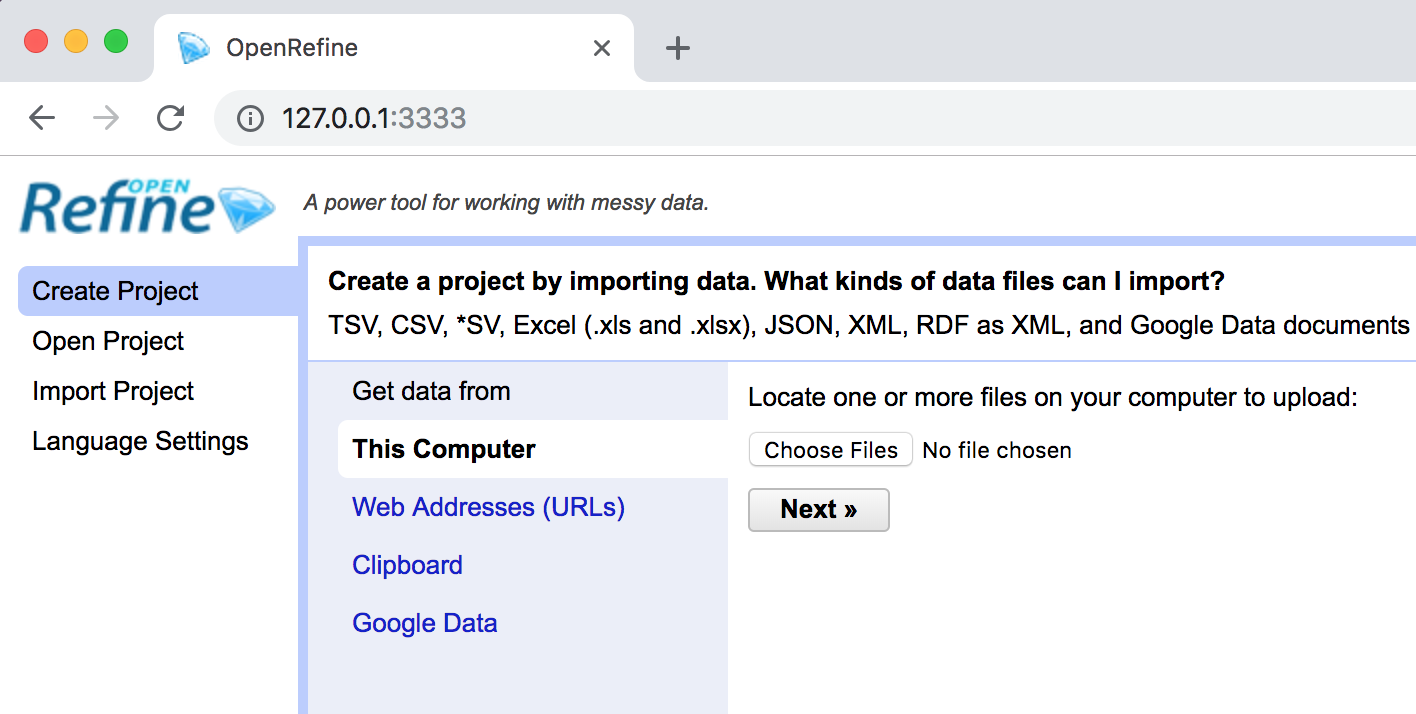
Start OpenRefine
Usually OpenRefine will open on its own when you click it, but if it doesn't, you can open it in a browser by typing in 127.0.0.1:3333
OpenRefine opens in your browser, but it's not connected to the internet! Your files "live" on your computer and can't be accessed online.
Start a new project by clicking "Create Project" and selecting a file from your computer or the web address on the next slide
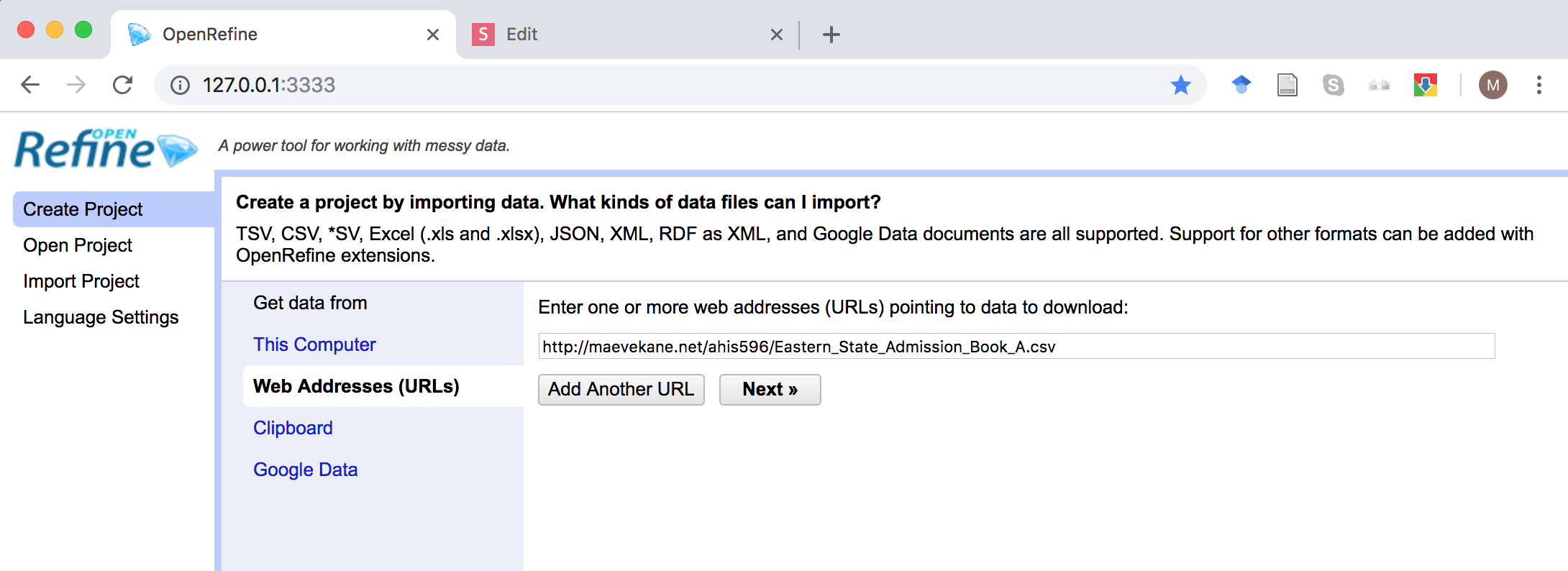
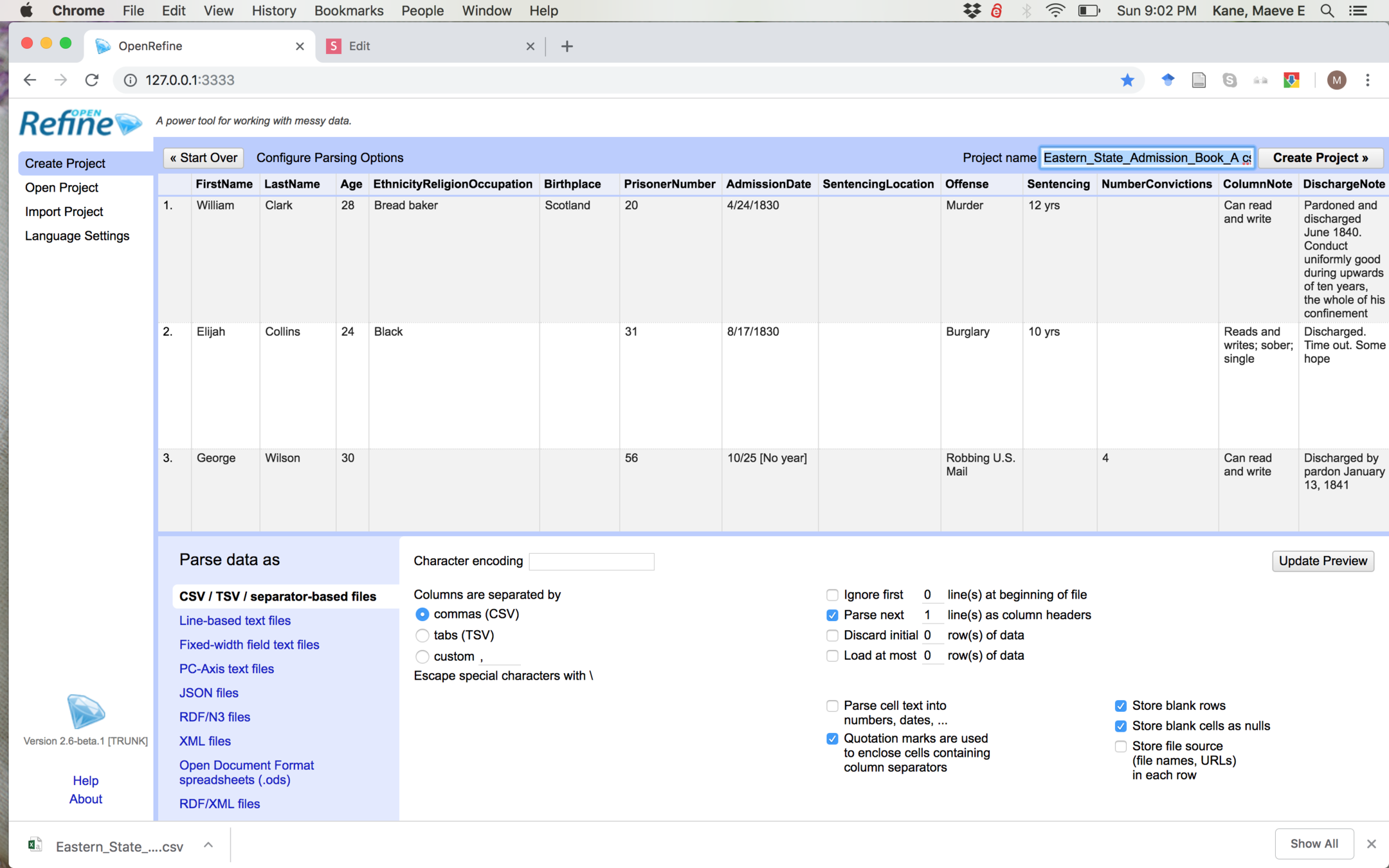
OpenRefine will preview your data
It should look like this; if not, try changing some of the settings to see what they do. Give your project a nice name and click "Create Project"
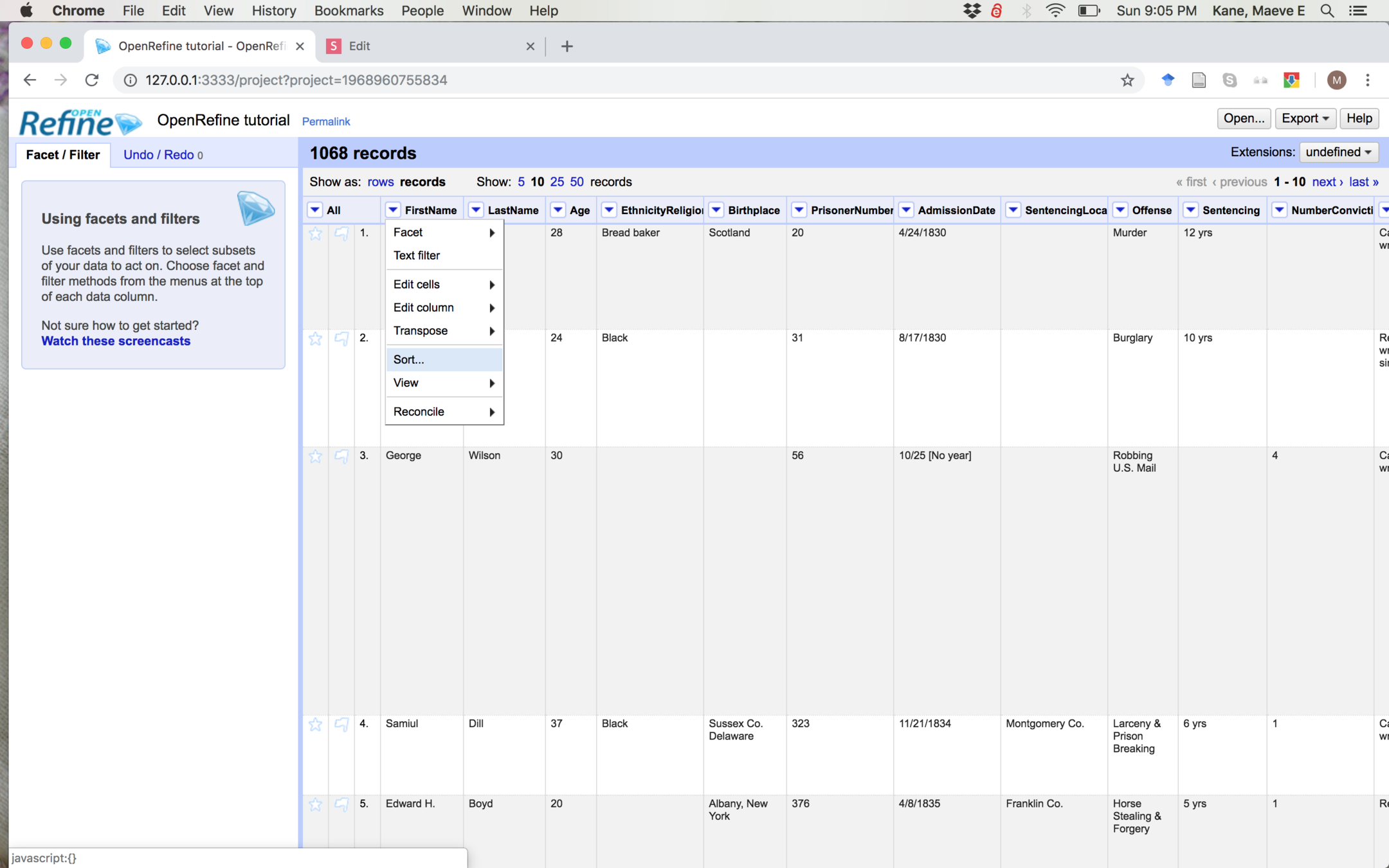
Openrefine looks like a spreadsheet
But it's for manipulating data, not entering data. The down arrows for each column give options, like sorting, editing, and filtering.
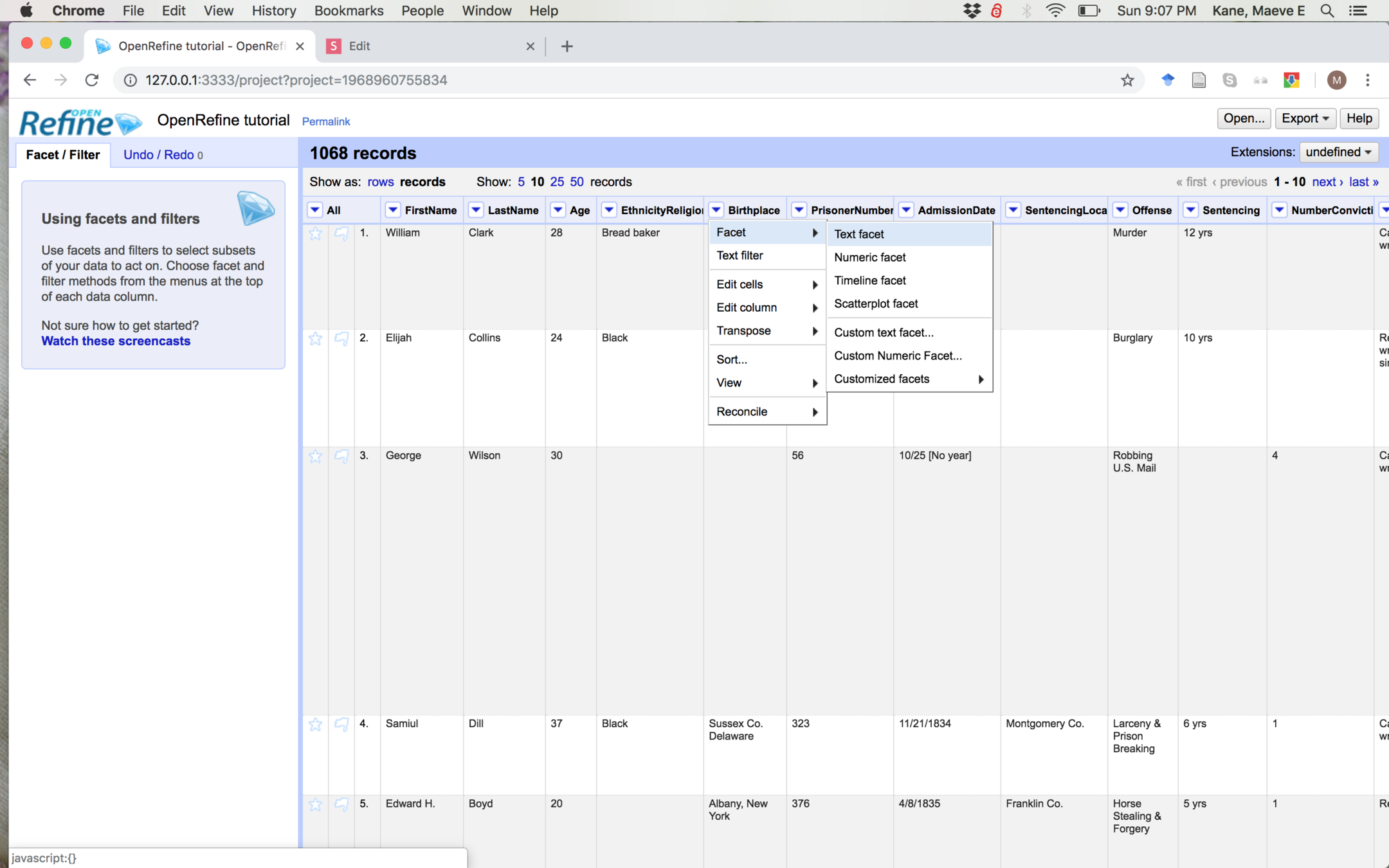
Facets
It also lets you group and clean information.
Try "Facet" > "Text Facet" on Birthplace.
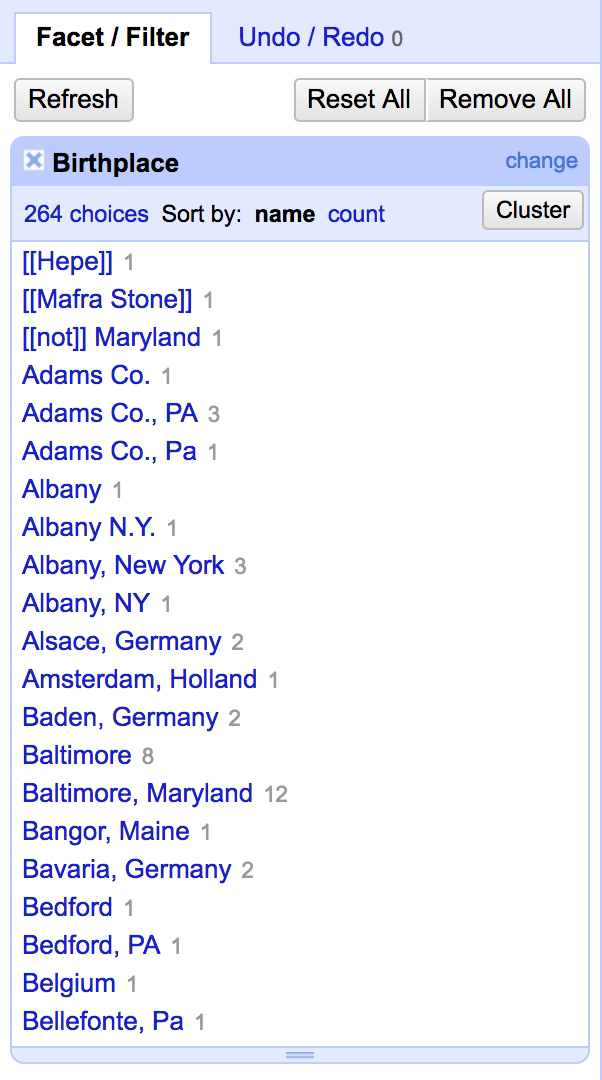
Working with Facets
Facets let you see the range of data in a column (like a filter in a spreadsheet. Try sorting the birthplace facet by count--you'll see the most-frequent birthplaces.
But what about all the different ways Albany is entered? A computer understands "Albany N.Y." and "Albany, NY" as two different places.
We could go through the column and hand-correct all of these errors so they're all the same, but that takes forever and we're lazy.
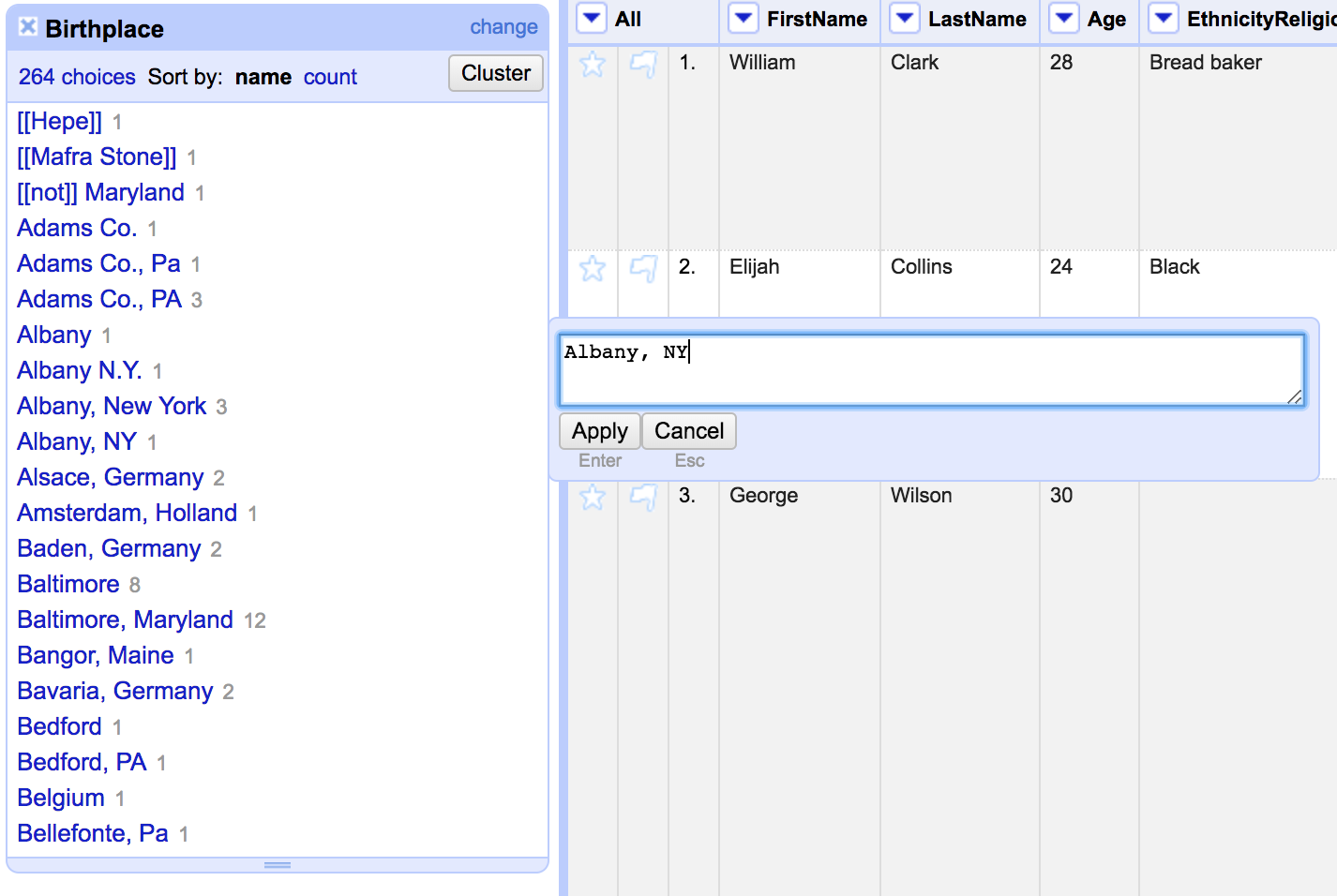
We could hover over each incorrect place, hit edit, and correct it that way. But we're still so lazy.
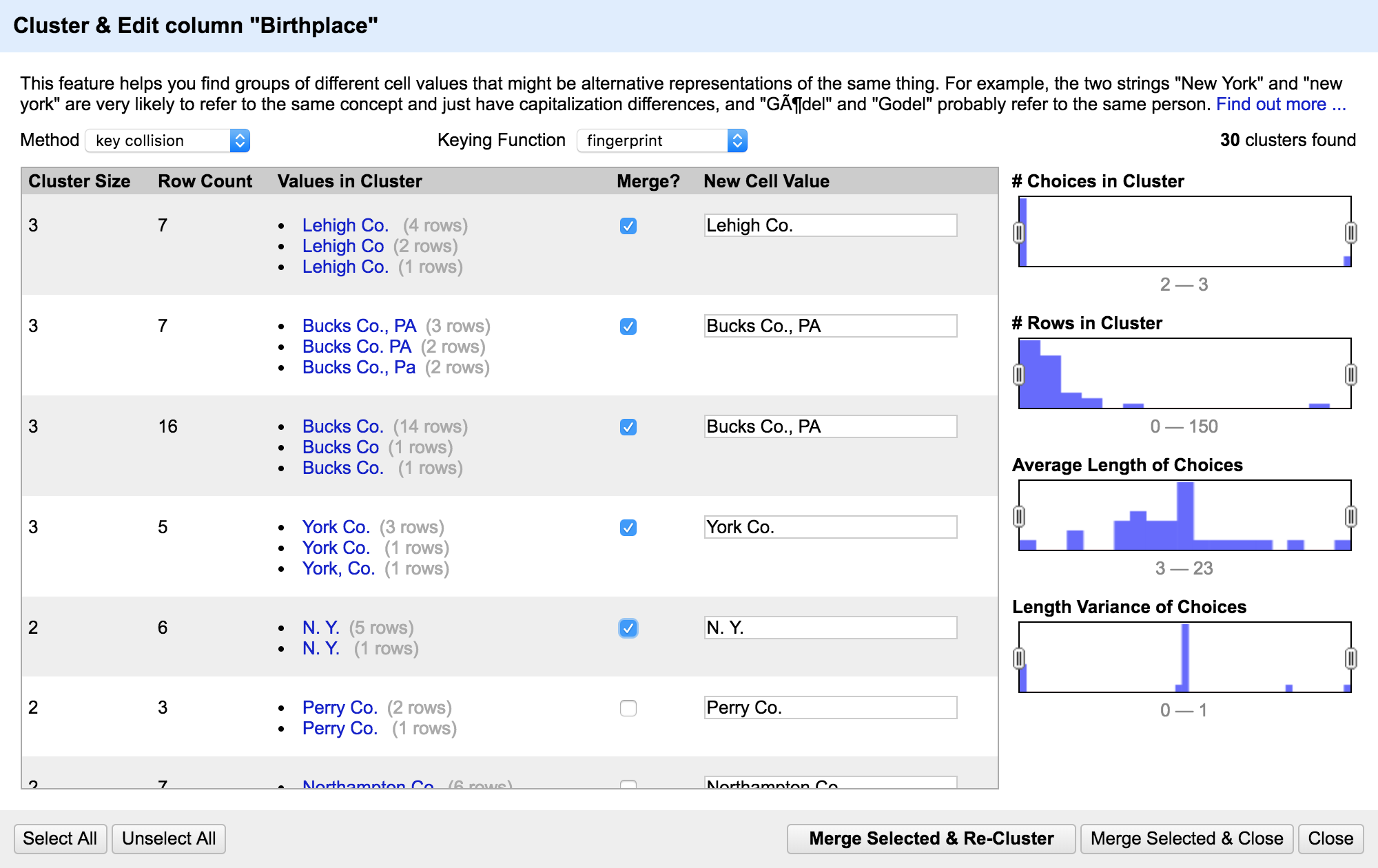
Clustering
If you hit "Cluster" at the top of the facet pane, you'll get this--what the computer thinks looks similar. You still need to go through and check the box to merge groups. Click "Merge selected & re-cluster"
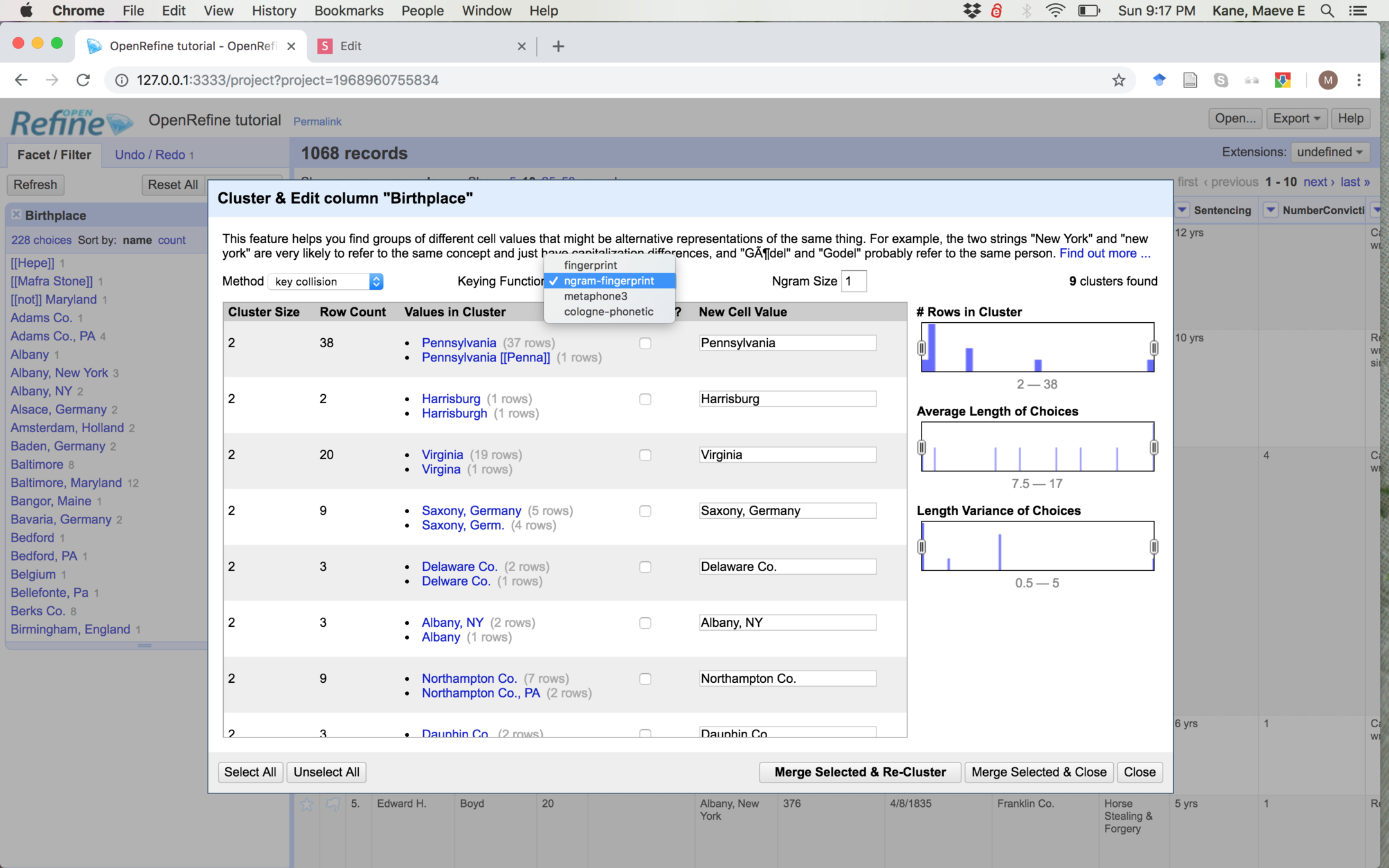
There's several different algorithms for finding clusters--try each of them out, and change the settings. Ngram-fingerprint didn't find clusters with size 2, but founds lots of clusters with size 1.
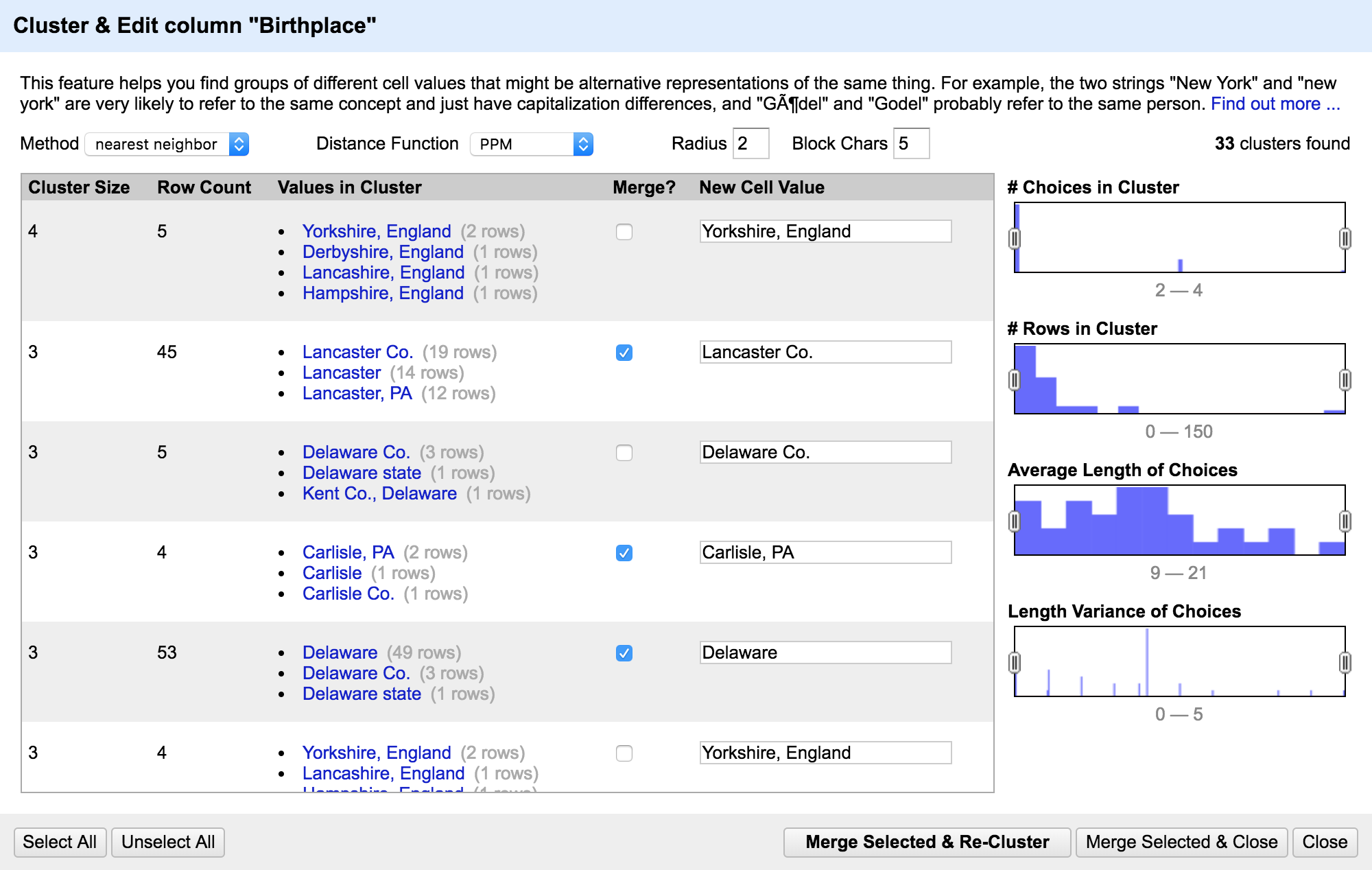
Don't be too trusting!
The computer thinks that Yorkshire, England and Hampshire, England are the same! You need to use your own judgement.
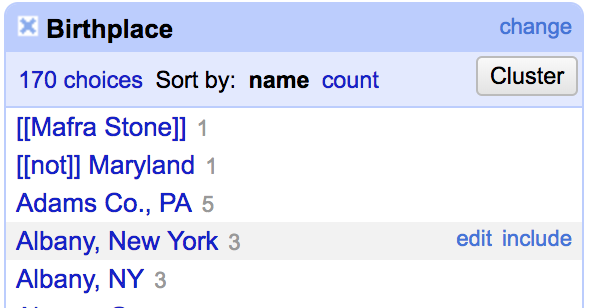
When you're done, hit close and look at the facet pane again. You may still need to hand-edit some things, but a lot less now!
Go through and hand-correct some of the remaining typos.
Faceting & Clustering
Try faceting and clustering other columns, like EthnicityReligionOccupation, Sentencing Location and Offense
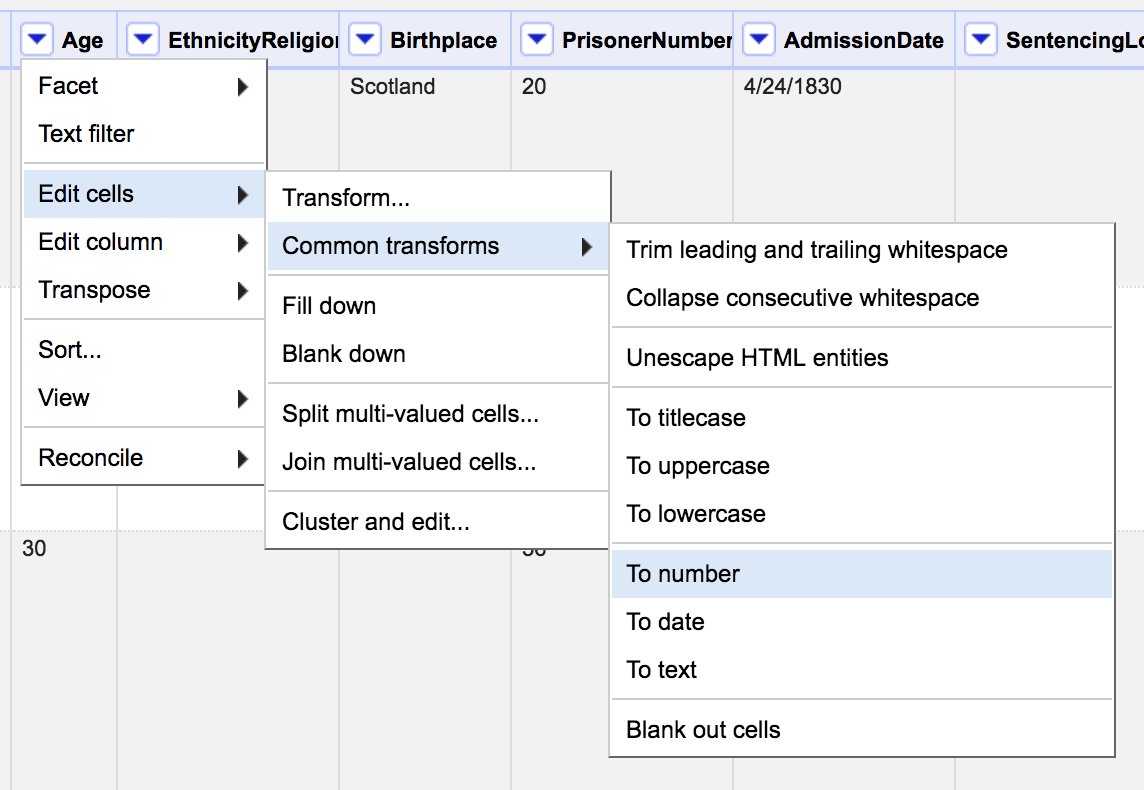
You can also facet by number, but sometimes OpenRefine doesn't recognize columns as numbers right away.
To change this, select Edit cells > Common transforms > To number
If OpenRefine recognizes something as a number, it will turn green instead of black
Try a numeric facet on Age
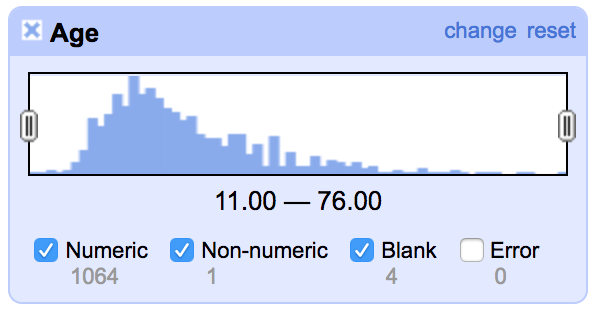
Numeric errors
Sometimes there's non-numeric errors in columns we want only numbers in. De-select everything except "non-numeric" and correct the error by hovering over the resulting cell and clicking edit.
Row errors
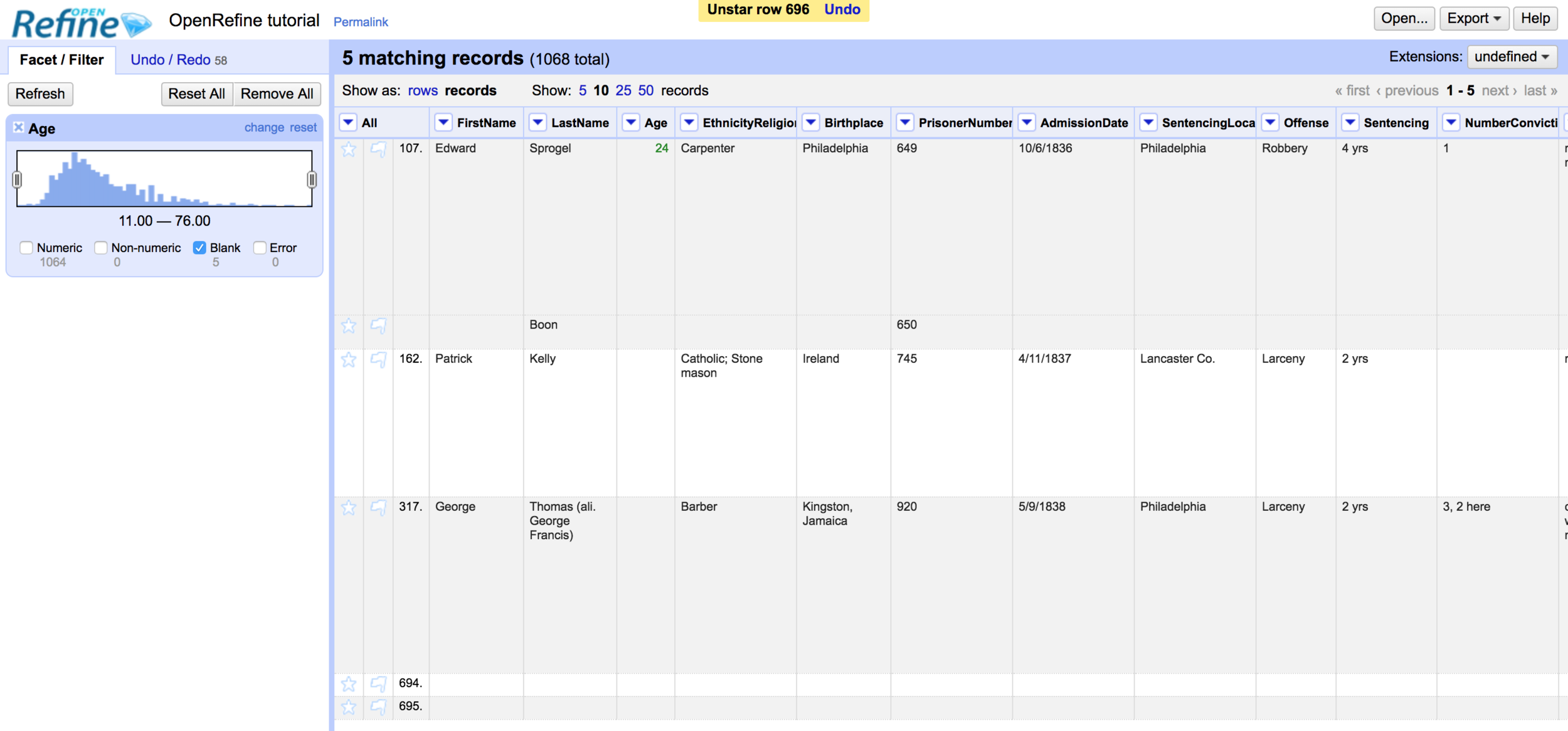
If we go back to the facet pane and only select "blank," we get some odd rows that appear to have no or little data.
Sometimes our data is incomplete or includes blank rows, and we have to decide what to do with these.
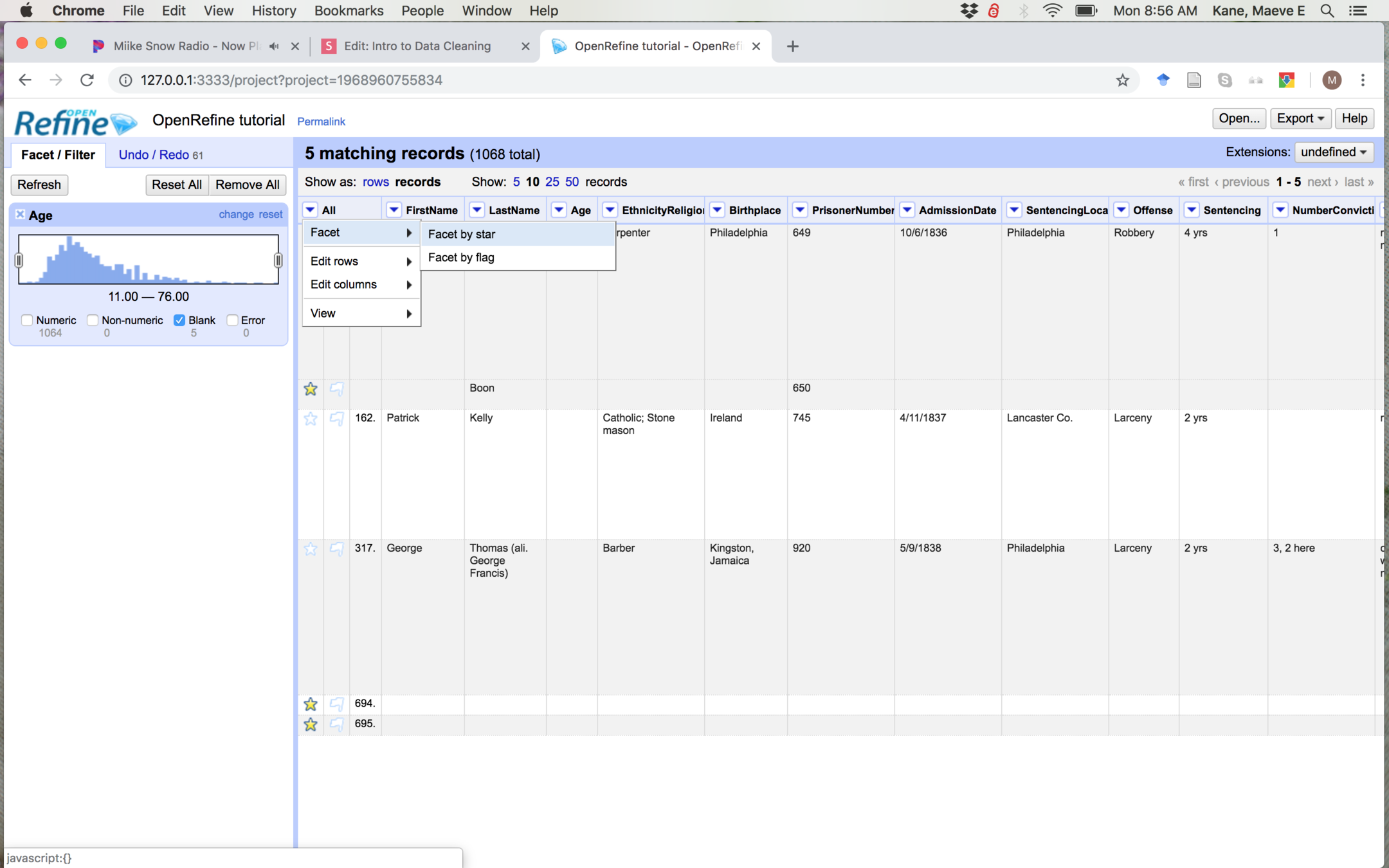
Getting rid of rows
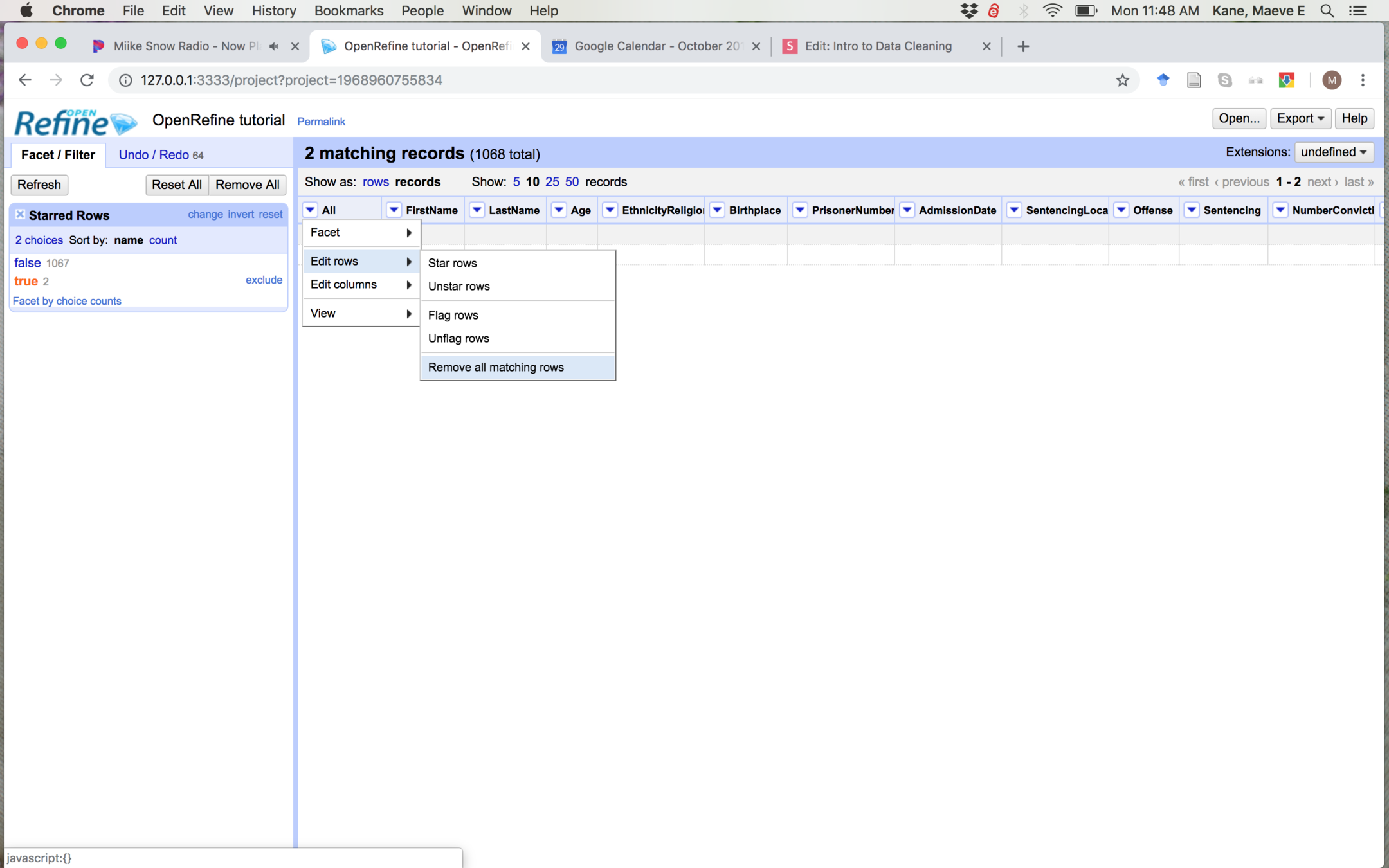
For now, we'll just get rid of these rows. Select the blank rows by clicking the star on the far left of the row, and then facet by star.
In the facet pane, select only true. In the All column, select Edit rows > Remove all matching rows to get rid of the blanks.
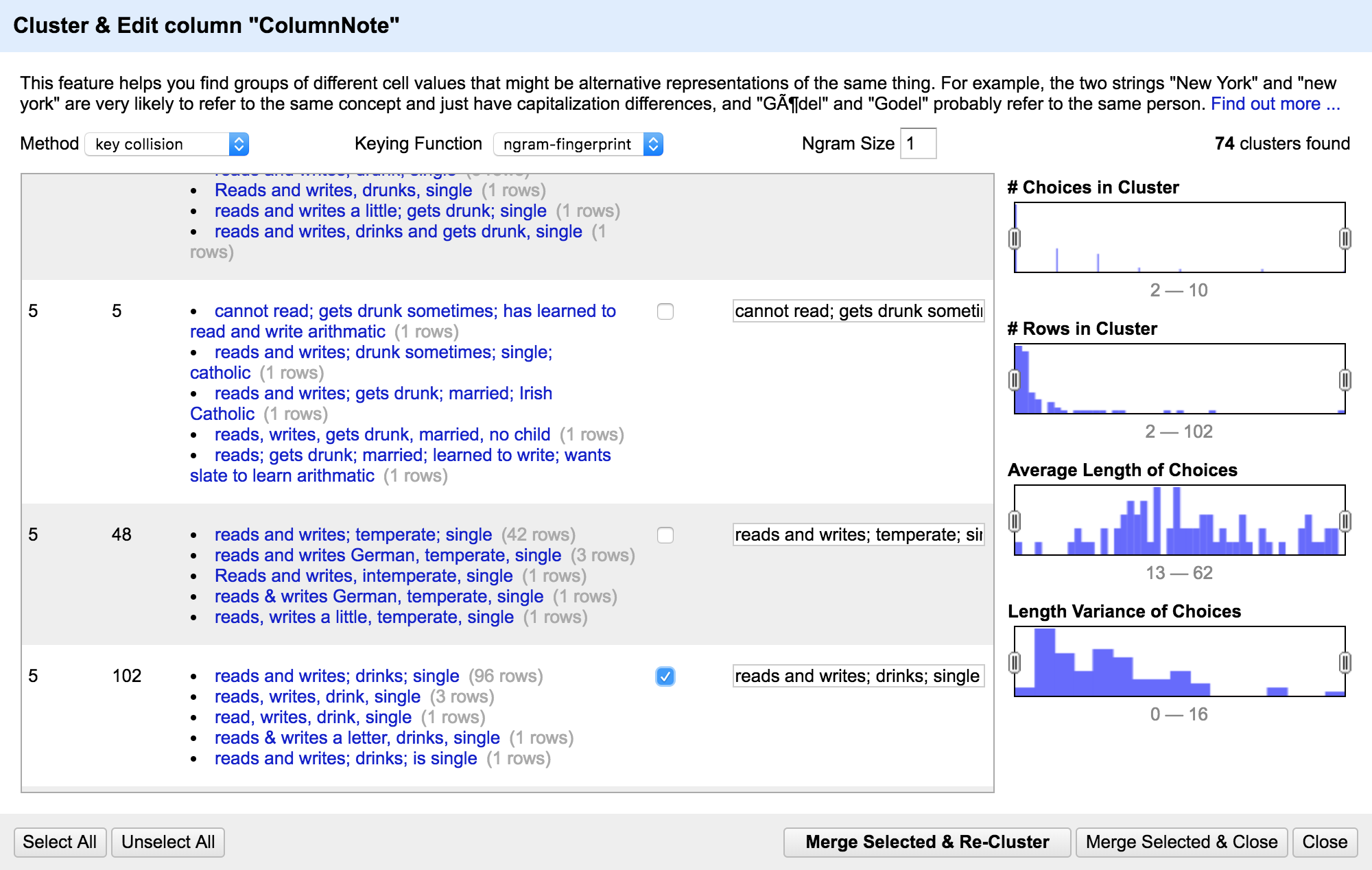
Historical judgement
Next do a facet & cluster on "ColumnNote." This is a hard column to cluster--is "drinks a little" the same as "got drunk"? Is "reads, writes a little" the same as "reads and writes"?
This is the scary part!
You have to use your best judgement in clustering things sometimes. What differences are you tracking? Is "drinks a little" an important distinction from "drinks" or "got drunk"?
You might decide that some differences aren't important to the questions you're asking--just be aware that you're making those choices and why you're making them!

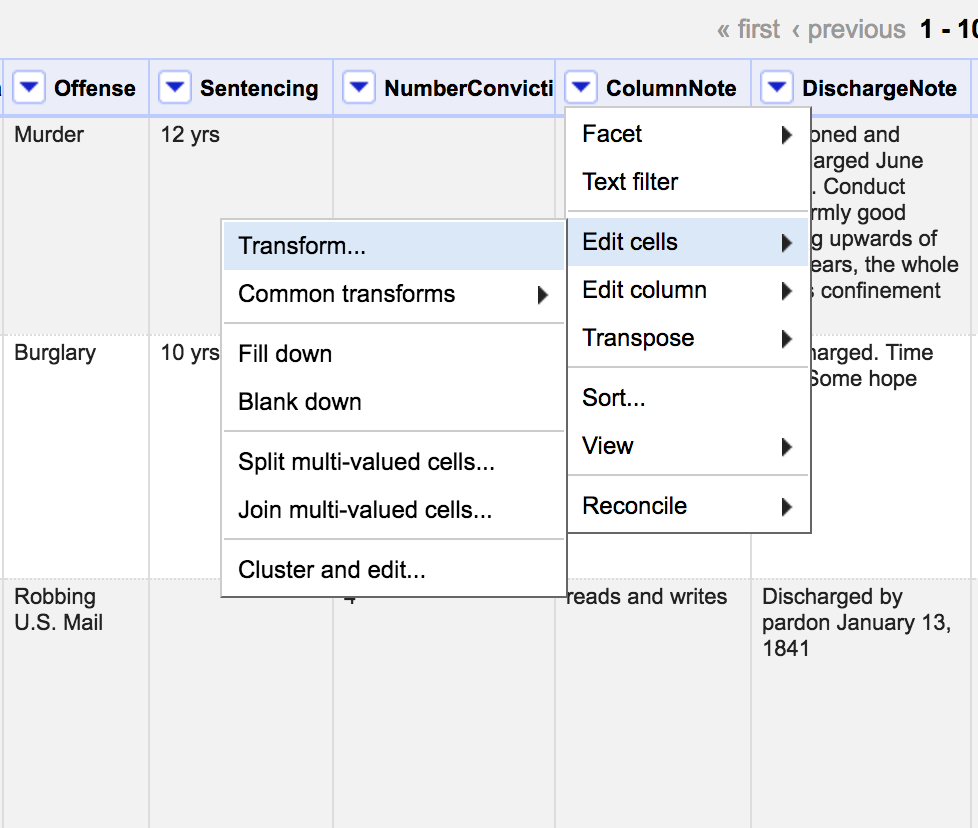
Splitting Values
ColumnNote is difficult to cluster because there's several kinds of information in it. What if we split it up to make our lives easier? Then we could edit "drinks" and "drinks a little" separate from "reads" and "reads a little"
Let's start by editing the cells using a transform
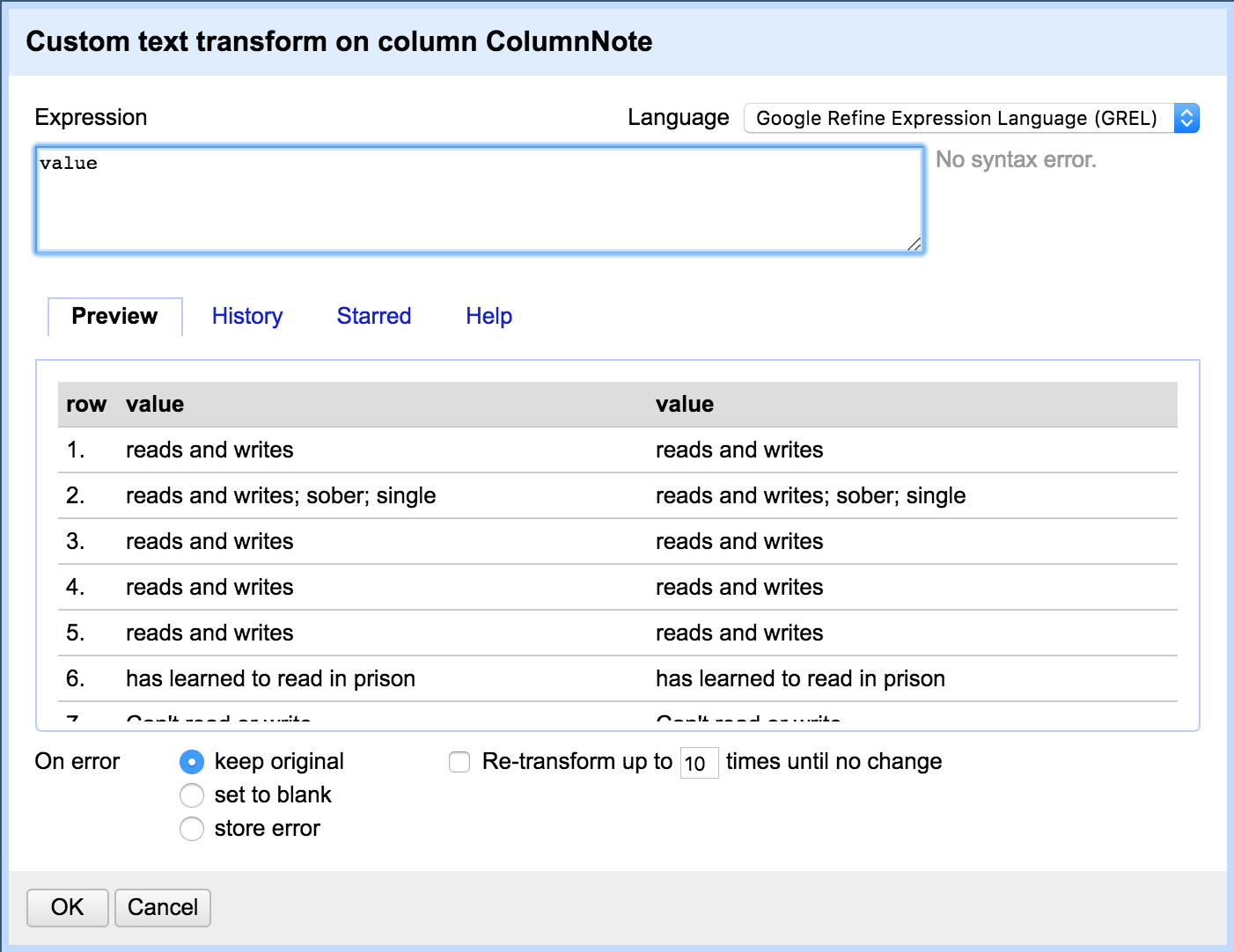
Scary!
This looks scary!
But don't worry, we're going to write a small piece of code telling OpenRefine how to edit the cells.
Value is the current contents of the cell. Think of it like x + 1, where x can be anything, and we're adding 1 no matter what x is.


Replacing text
ColumnNote's reads/drinks/married information is sometimes separated by commas and sometimes by semicolons
To make it easier to split up this information into separate columns, we're going to replace the commas with semicolons.
So we tell OpenRefine to take the current value, and replace "," with ";" [ value.replace(",", ";")
The quotation marks around the comma and semicolon characters are important! OpenRefine won't know how to interpret the characters otherwise. Also notice there's a comma separating "," and ";"
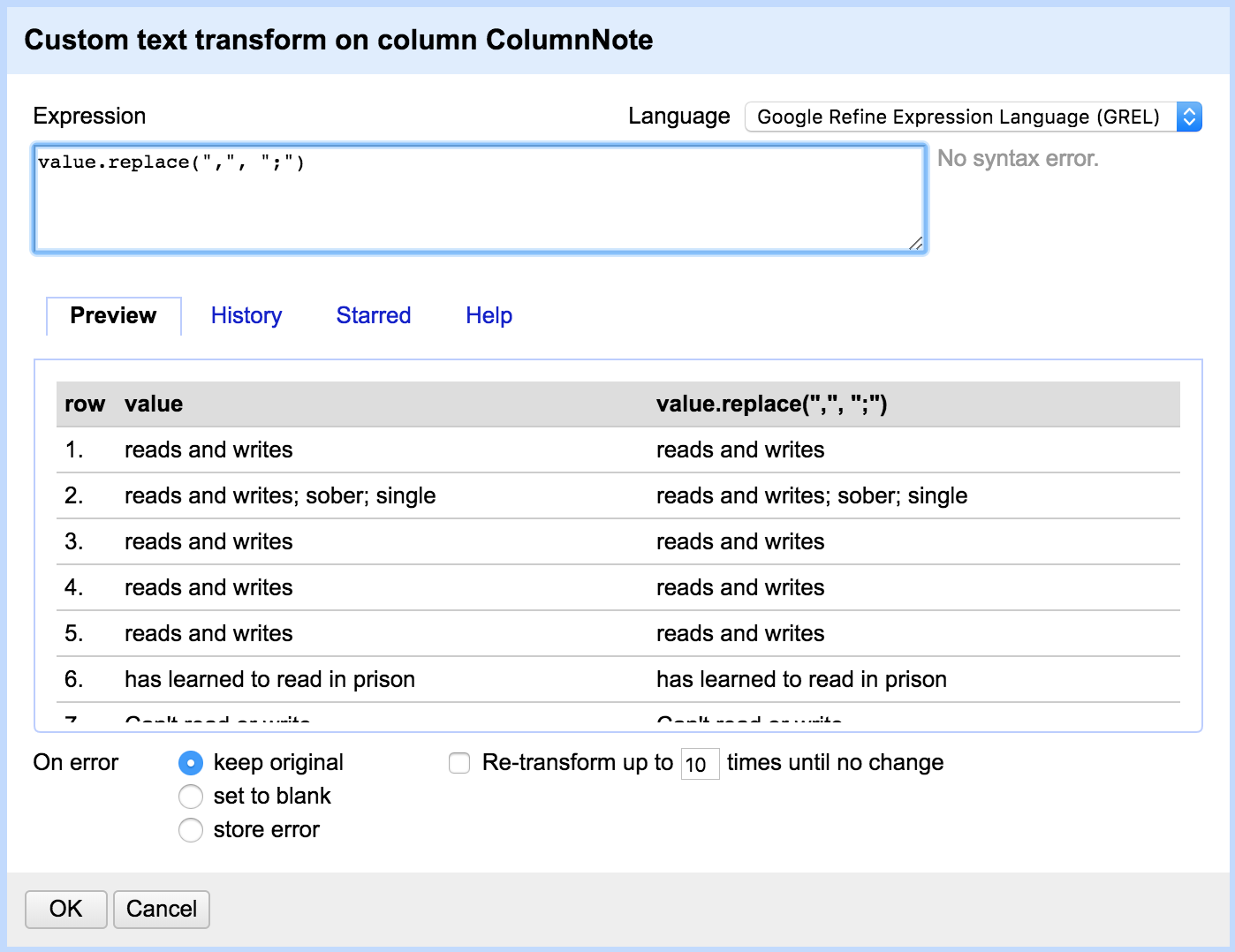
Replacing Text
If your code works, you should see a preview of the changes you can check before hitting OK
If you get an error, double check your quotation marks, parentheses, and other punctuation

You did it!
Dates & Numbers
Let's change the AdmissionDate to a date (rather than the default text) and start cleaning this column
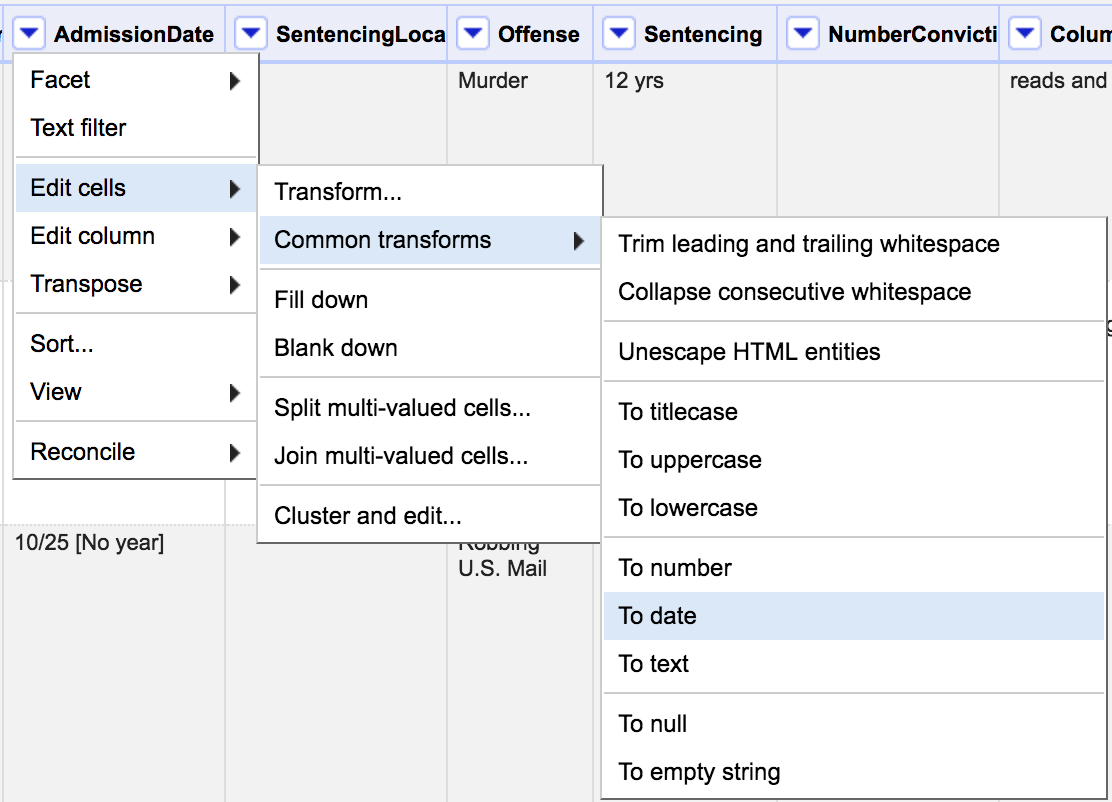
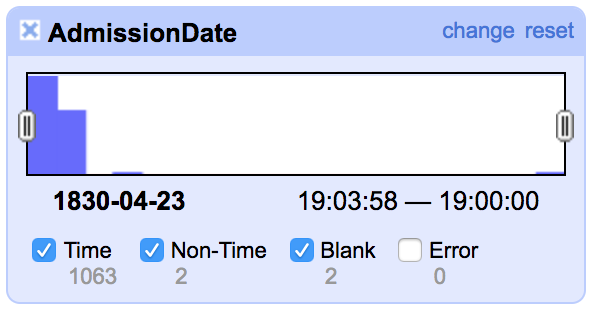
Timeline facet
OpenRefine and other programs can sometimes interpret dates in odd ways. Let's narrow the range of our timeline facet and make sure that all of this information is correct
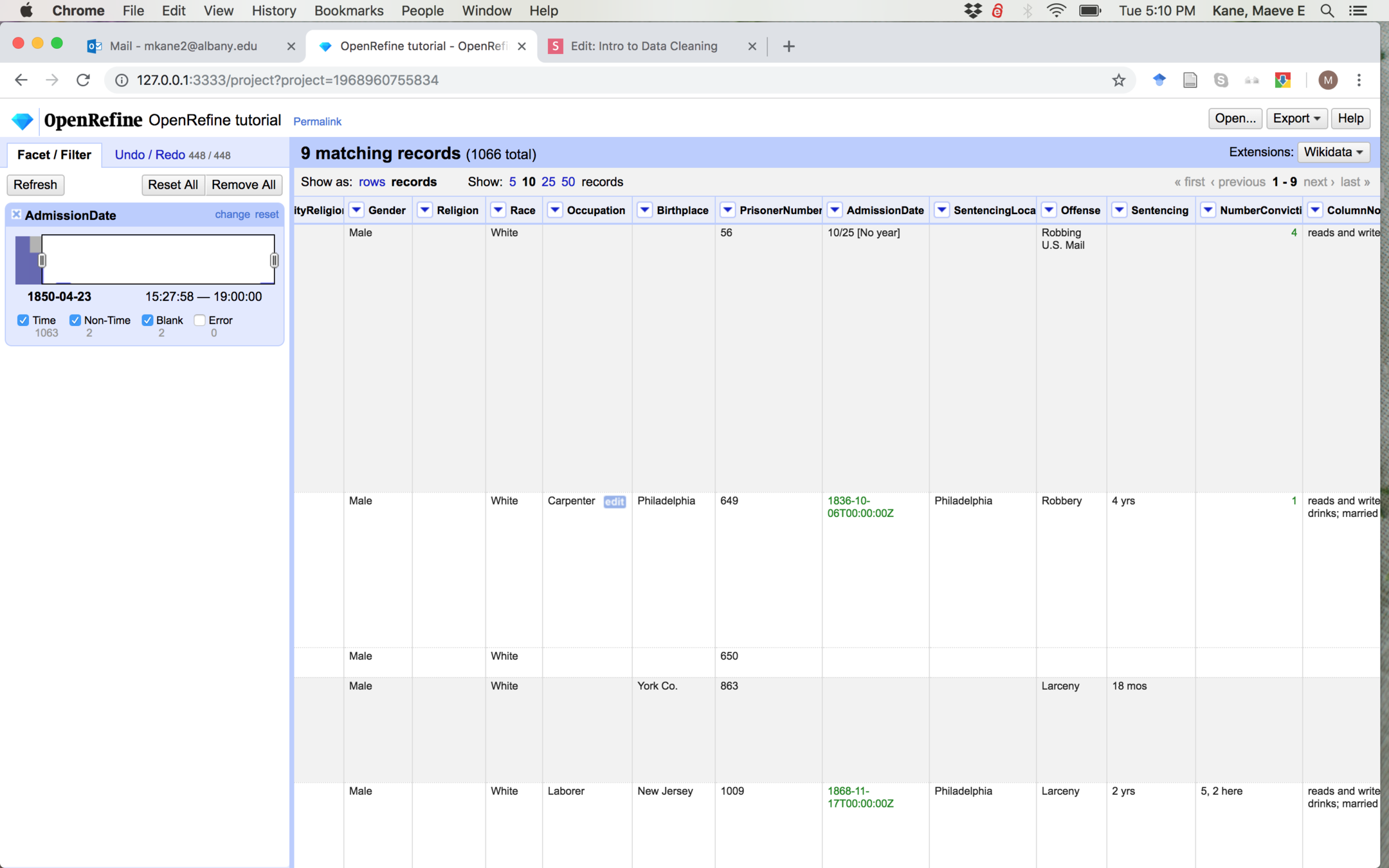
Some of this is correct, just later than we might have guessed
Some isn't correct
We'll have to hand-correct these
Is the month important to our question, or do we just need year?
ONE LAST THING
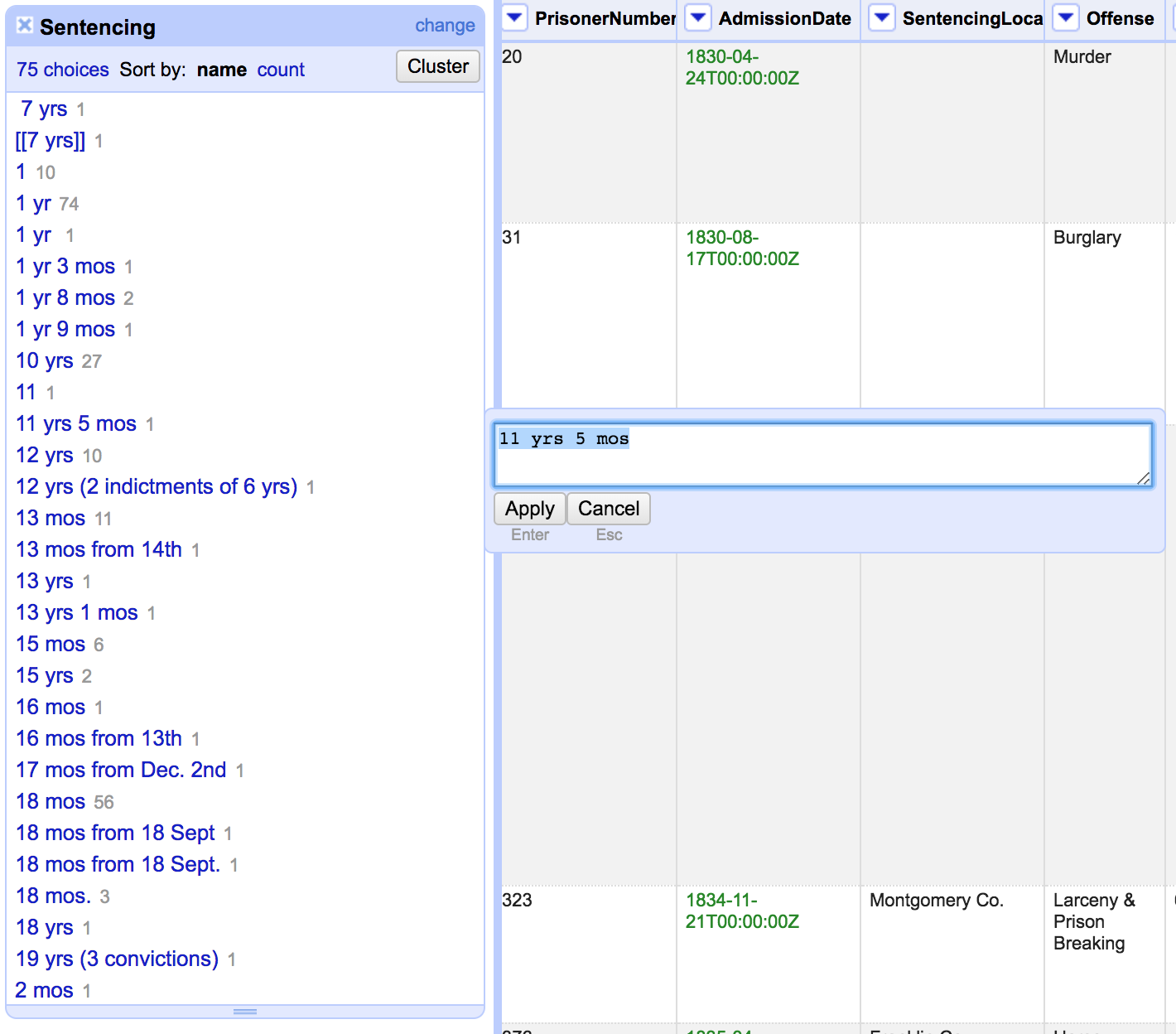
What if we want to compare sentence lengths?
We need to facet and edit out some of the non-time information like "from 14th" or "(3 convictions)"
Leave anything that's just yrs and mos alone for now!
Grab Months
Let's add a new column based on Sentencing by finding any numbers that precede "mos", joining them without additional spaces, and then replacing "mos" with nothing (see the next slide for the expression)
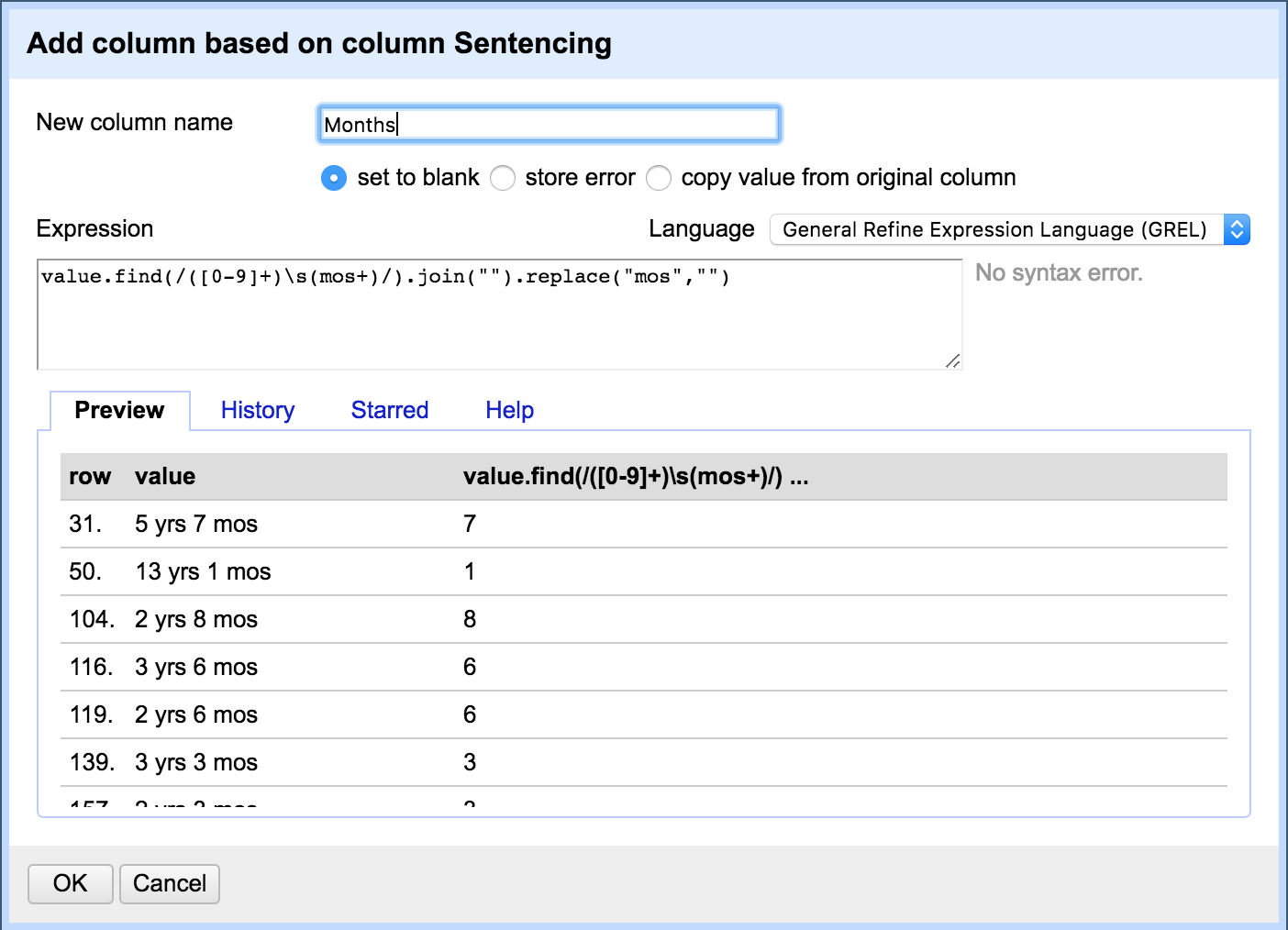
value.find(/([0-9]+)\s(mos+)/).join("").replace("mos","")
All these parentheses, backslashes, forward slashes, and quotation marks are important! If you get errors, ask a friend or double check your punctuation!
value.find(/([0-9]+)\s(mos+)/).join("").replace("mos","")
This is using regex or regular expressions to look for a specific pattern. Regex is used in many different programming languages to search for patterns.
In the snippet of code above, [0-9] searches for any number between 0 and 9; ([0-9]+) searches for any group of numbers.
\s(mos+) searches for a space followed by the exact letters mos, with any number of S's.
Regex is very powerful because if you can figure out the pattern you're looking for, you can use it to structure unstructured data!
Names are relatively hard to write regex for because they have many pattern variations and sometimes include punctuation like periods and hyphens that make them hard to distinguish from parts of sentences.
Years are relatively easy to write regex for. /[0-9]+/ will find any sequence of numbers together, but something like /1[7-9][0-9][0-9]/ will only find 4-digit numbers starting with 1, followed by 7, 8, or 9, followed by any other numbers.
Regex has a lot of ins and outs that can be both handy and confusing. If you find yourself doing a lot of this, testing your regex with something like https://regexr.com/ is handy.
Now try writing a formula to find numbers that precede yr!
We only want yr and not yrs so that we grab "1 yr" as well as "3 yrs" and put that into a new column.
This is our formula for mos:
value.find(/([0-9]+)\s(mos+)/).join("").replace("mos","")
What do you change to just do yr?
A little Algebra
We're going to multiply years by 12 (to get the total number of months) and then add this to the Months column.
First, we have to transform Years and Months from text to numbers. (look back on slide 13 for how to transform to number)
Once Years and Months are both numbers, we can add a new column "Sentence in Months."
We want to multiply the value of cells by 12, and then get the sum of that number and the value of the Months cell.
sum([value * 12, cells['Months'].value])

We're done!
We could keep cleaning our data, and for our final project data we should clean it a lot more, but this is all the major steps.
What's next
If you have trouble, ask on the course site or try Prof. Google.
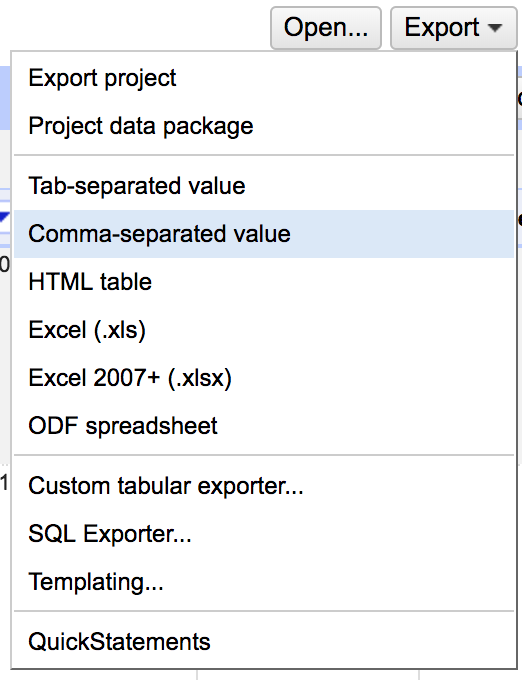
To use your data, you need to export it as a CSV (comma-separated value) file. Export yours and upload it to the course google drive Data Cleaning Folder. Make sure to rename it with your name so we can keep everyone's straight.
One last thing
Sometimes working on a project, you'll want to reproduce your steps. OpenRefine allows you to do this by going into Undo/Redo > Extract. Select all, hit the Export button, and save the file somewhere you'll find it. Upload this file to our shared Data Cleaning file as well (and remember to rename it something with your name).
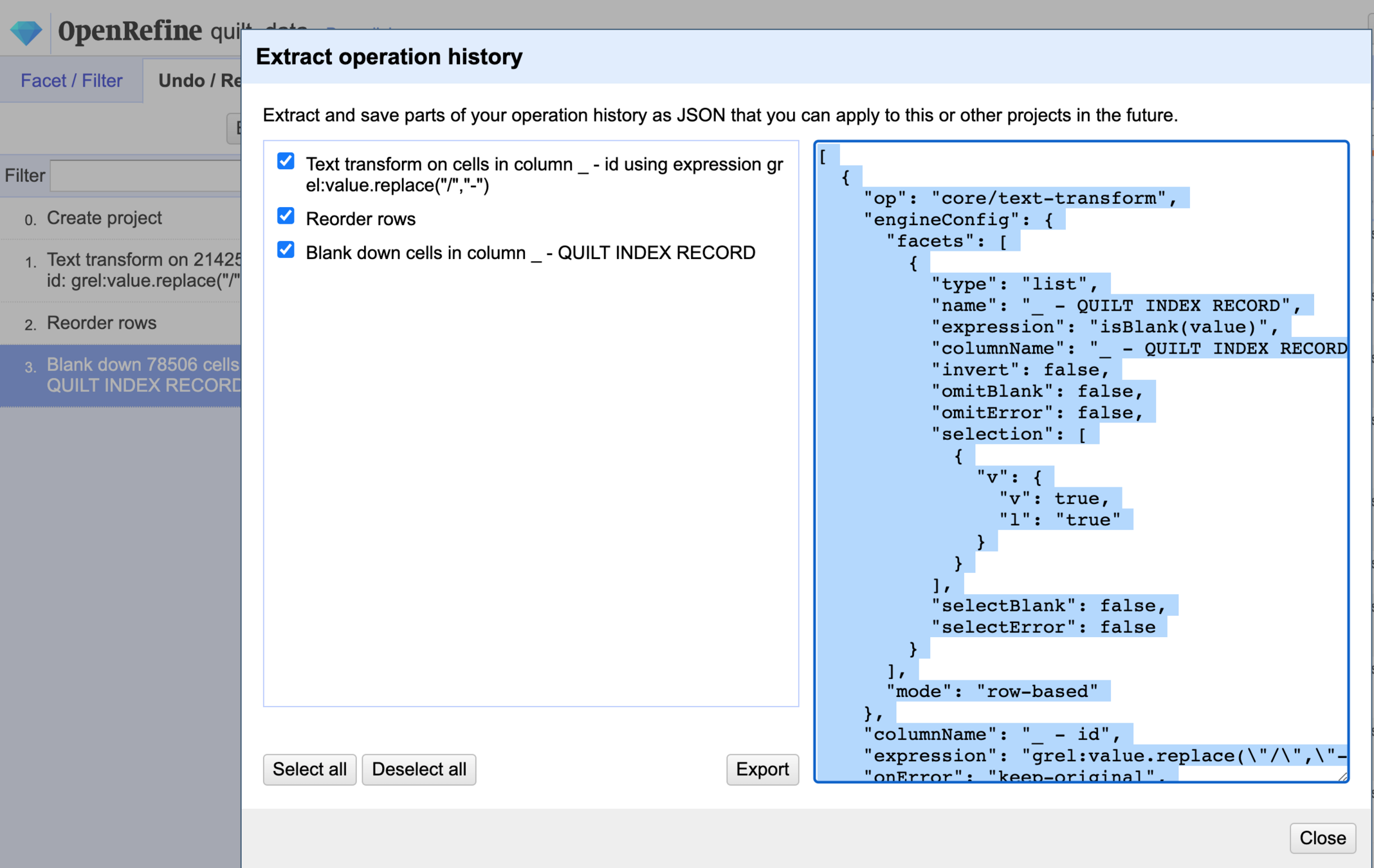
The extract operations file stores a record of all your cleaning operations in a .json file. This is useful if you ever want to repeat your actions--OpenRefine will repeat them exactly as long as your columns are named the same thing as the original. This is also important to keep a record of if you publish with your data.
.json is a file type that stores hierarchical information we'll use again in another module. It can look intimidating, but it stores information similarly to a spreadsheet. Think of the first item as the column name and the second item as the cell value.
This:
Reads as operation is column removal, column to be removed is Admission Date, and describes the action.
{
"op": "core/column-removal",
"columnName": "Admission Date",
"description": "Remove column Admission Date"
}
Good job!
You're done!