Blaze: an interface to all the things
about me
- MA Psychology
- Computational Neuroscience
- Pandas core dev
- blaze, odo, et al @ContinuumIO
How do i interact with all the things?
lists of things
In [79]: gb = toolz.groupby('passenger_count',
....: (x for x in dicts if x['passenger_count'] < 6))
In [80]: {k: sum(y['fare_amount'] for y in v) / len(v) for k, v in gb.items()}
Out[80]:
{0: 37.166666666666664,
1: 12.068150330050502,
2: 11.974952289774347,
3: 11.876616991857428,
4: 12.034261638063919,
5: 11.938438450392496}databases
In [91]: d = sa.Table('nyc',
....: sa.MetaData(bind=sa.create_engine('postgresql://localhost')),
....: autoload=True)
In [92]: sel = sa.select([d.c.passenger_count, sa.func.avg(d.c.fare_amount)])
In [93]: result = sel.where(d.c.passenger_count < 6).group_by(d.c.passenger_count)
In [94]: result.execute().fetchall()
Out[94]:
[(4, 12.8474578145854),
(5, 12.4340166757418),
(1, 12.1857106698121),
(2, 13.0082269224776),
(3, 12.620676158505),
(0, 23.5708381330686)]kdb
In [4]: from qpython.qconnection import QConnection
In [5]: c = QConnection(port=5000, host='localhost', pandas=True)
In [6]: c.open()
In [7]: r = c.sync('select avg trip_time_in_secs by passenger_count from trip')
In [8]: r.head()
Out[8]:
trip_time_in_secs
passenger_count
0 122.071500
1 806.607092
2 852.223353
3 850.614843
4 885.621065Yay string programming!
spark
In [21]: sdf[sdf.passenger_count < 6].groupby('passenger_count').agg({'fare_amount': 'avg'}).collect()
Out[21]:
[Row(passenger_count=0, AVG(fare_amount)=50.0),
Row(passenger_count=1, AVG(fare_amount)=12.085692890743172),
Row(passenger_count=2, AVG(fare_amount)=11.904175317185697),
Row(passenger_count=3, AVG(fare_amount)=11.670360110803324),
Row(passenger_count=4, AVG(fare_amount)=12.041448058761805),
Row(passenger_count=5, AVG(fare_amount)=12.00365975807073)]Dataframes
In [37]: df[df.passenger_count < 6].groupby('passenger_count').fare_amount.mean()
Out[37]:
passenger_count
0 37.166667
1 12.068150
2 11.974952
3 11.876617
4 12.034262
5 11.938438
Name: fare_amount, dtype: float64let's drive them all!
blaze =
exprs+
all the things
10,000 foot view

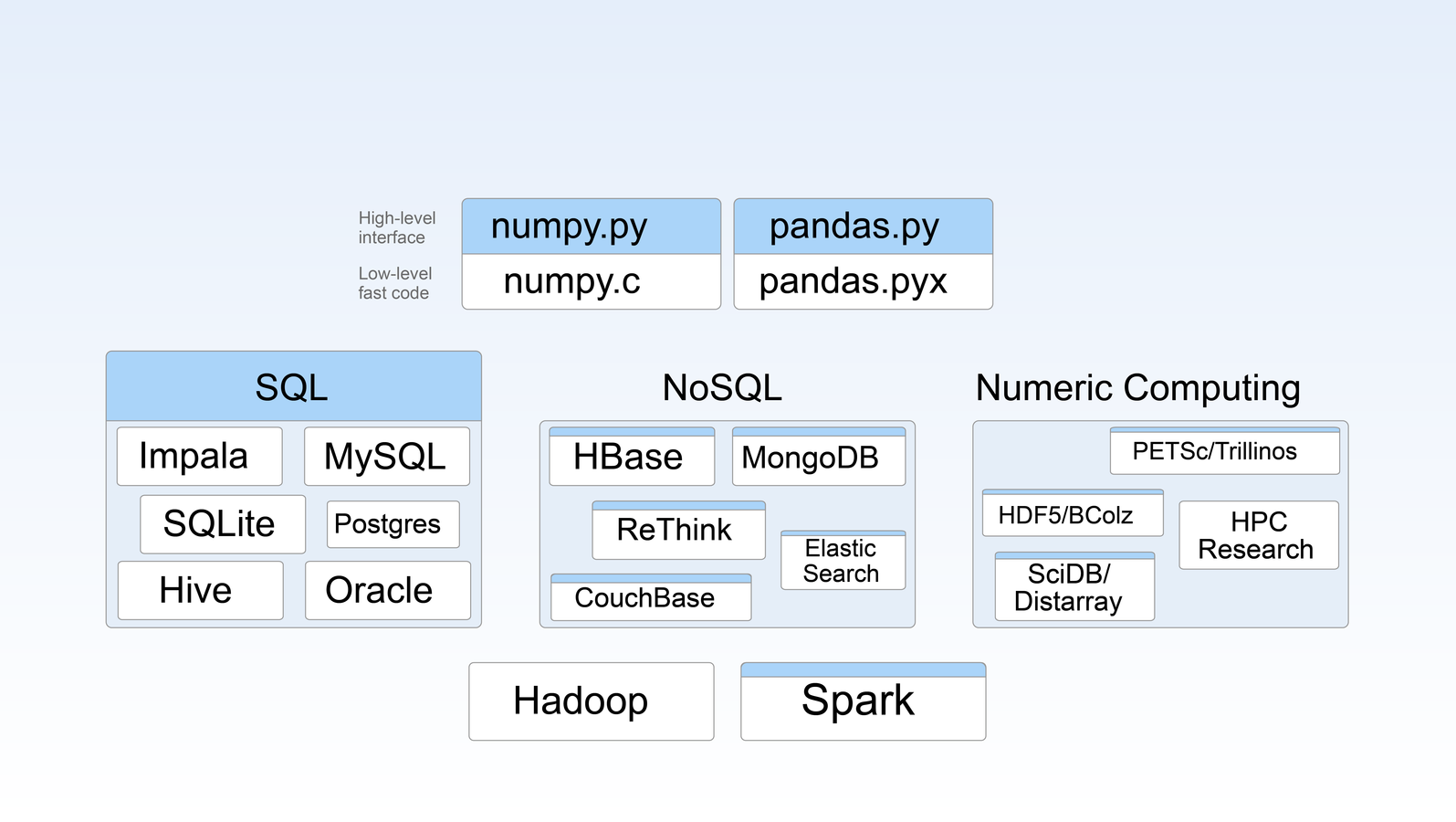
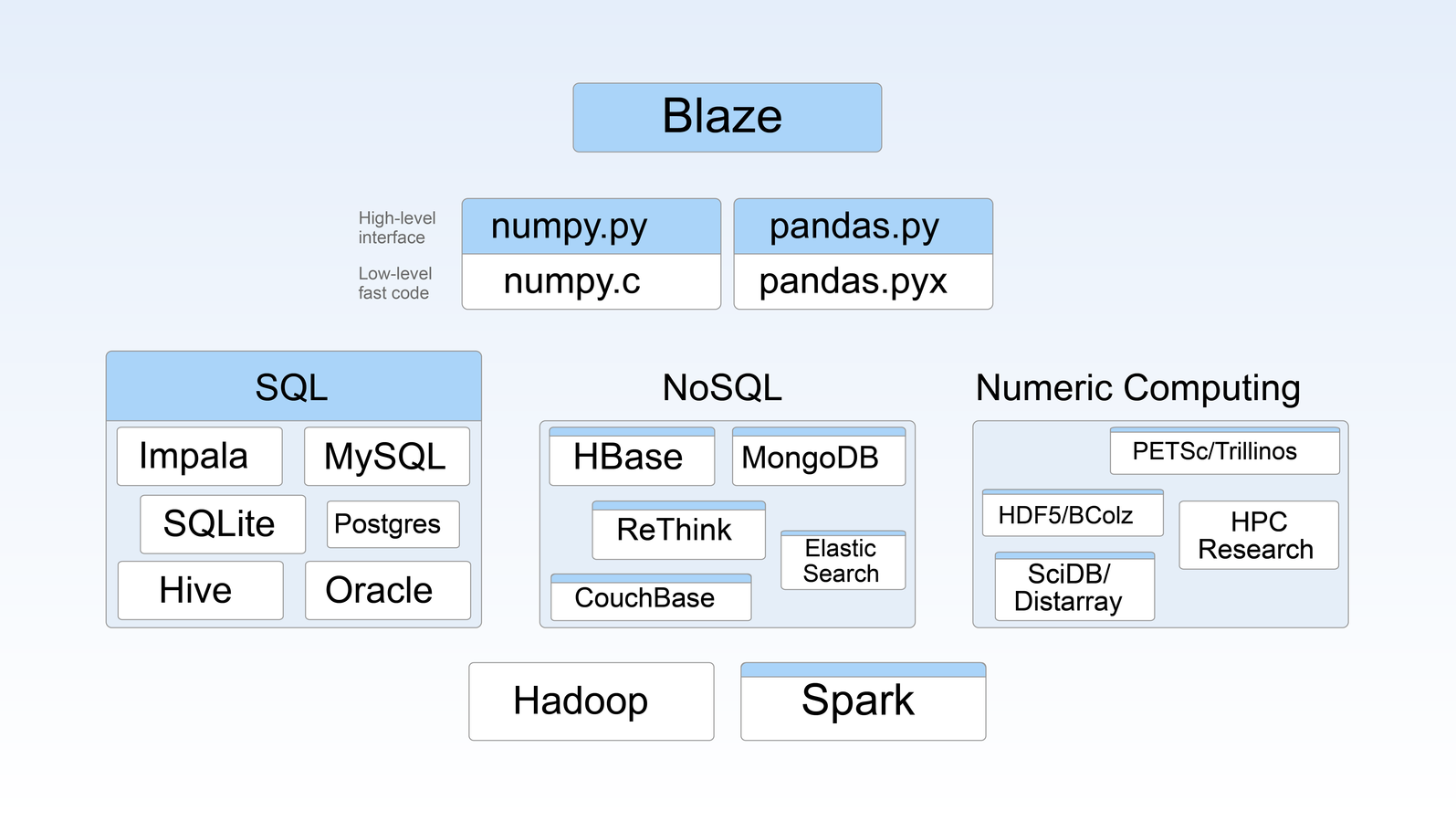
expressions
- Separate data from computation
- Write down what you want to compute without worrying about how it will be computed
use case: drive Q from Python
Q overview
Who's hearD of q?
for something other than a binary store.
Who's used q?
the language
- Written by Arthur Whitney
- Derived from and written in K
- K is similar to APL
- Tons of operators
- Parses from right to left
- Unless you're in qsql land
q demo!
Pray to the q gods and the demo gods
The database
- Column store
- Handles null values for all types
- Nice support for slowly changing string values (symbols)
- Excellent time series support
- Support for different storage formats that scale to huge tables
- Matrix math
The GOOD
- Column store
- Extremely fast queries
- Concise querying via qsql
- Great time series support
- Nice foreign key syntax
The BAD
- Hardly anyone knows q
- Operators > Names
- Cryptic error messages
- Large programs are unreadable by anyone except the q gods
- q gods never make errors
- Strange API breaks
- dev to sdev
- Hard to apply traditional database knowledge
THE ugly
q)x:"racecar"
q)n:count x
q)ispal:all{[x;n;i]x[i]=x[n-i+1]}[x;n]each til _:[n%2]+1
q)ispal x
1bq)1 % "cat"
0.01010101 0.01030928 0.00862069q)-1["foo"]
foo
-1
q)1["bar"]
bar1
please q gods, give me whitespace
kDBPY
the stack
- A SQLAlchemy dialect
- That can be driven from Blaze
- With odo for moving data around
- Using qpython to talk to a q process
sqlalchemy Dialect
class QDialect(Dialect):
def visit_select(self, select, **kwargs):
# ...
def visit_insert(self, insert, **kwargs):
# ...
# and so on- Generate (some variant of SQL) using the visitor pattern
sqlalchemy Dialect
>>> import sqlalchemy as sa
>>> engine = sa.create_engine('q://localhost/path/to/db')
>>> meta = sa.MetaData(bind=engine)
>>> t = sa.Table('t', meta, autoload=True)
>>> expr = sa.select([t.c.name, sa.func.avg(t.c.amount)]).group_by(t.c.name)
>>> result = conn.execute().fetchall() # <- a pandas DataFrame- Build up expressions
demo time!
wish/bug list
- DDL for splayed and partitioned tables not yet ready for primetime
- Foreign key support in blaze expressions
- Very close to merging
- Better time series support all around
- Transparent insert to special table types
- Python 3 support
- Streaming results from q
- Open source it!