Comparative Analysis of Time Series Databases
in the Context of Edge Computing for Low
Power Sensor Networks
Piotr Grzesik
dr hab. inż. Dariusz Mrozek, prof. PŚ
Agenda
- IoT applications
- Processing at the edge
- Edge devices
- Time-Series Databases
- Related works
- Testing environment and used data model
- Selected databases
- Performance experiments
- Summary
- Next steps
IoT applications
- Environmental monitoring
- Air quality monitoring
- Telemedicine & healthcare
- Smart cities & smart homes
- Agriculture, farming
- Energy consumption monitoring
- ...and many more
Processing at the edge
Edge computing is a computing paradigm that brings the data processing and storage closer to a place where it is needed. It allows to reduce the volume of data that needs to be send over the Internet, allows to improve reaction time to the changing state of the system and improves resilience and allows for data loss prevention where Internet connection is not reliable or not available at all most of the time.
Edge devices




Jetson Nano
Source: https://www.nvidia.com/
Raspberry Pi 4
Source: https://www.raspberrypi.org/
Beaglebone Black
Source: https://beagleboard.org/
Coral Dev Board
Source: https://coral.ai/
Time-Series databases
- Designed and optimized to handle timestamped or time-series data
- Data characterized by low number of relationships between data, temporal ordering of records
- Data stored in the form of events, metrics or measurements, typically numerical, stored with timestamp and additional labels or tags
- Data is inserted and often queried (aggregated), updates are very rare
- Data is often chunked, based on timestamp, which in turn allows for fast and efficient time-based queries
- Time-Series databases are built in two ways - as a standalone database or as an extension to an existing database
Growing popularity of
Time-Series databases

Growth trend of various types of databases in the last 24 months according to DB-Engines.com
Related works
-
In his research, Bader et al., focused on open source time-series databases, examined 83 different solutions and presented a comparison of twelve selected databases, including InfluxDB, PostgreSQL, and OpenTSDB. All selected solutions were compared based on their scalability, functionality as well as licensing and support.
-
Wlodarczyk, in his article, provides an overview and comparison of four offerings, Chukwa, OpenTSDB, TempoDB and Squwk. The analysis focused on feature differences between selected technologies, without any performance benchmarks. The author identified OpenTSDB as a most popular choice for the time-series storage.
Related works
-
Pungila et al. compared the databases to use them in the system that stores large volumes of sensor data from smart meters. During the research, they compared three relational databases, SQLite3, MySQL, PostgreSQL, one time-series database, IBM Informix with DataBlade module, as well as three NoSQL databases, MonetDB, Hypertable and Oracle BerkeleyDB.
-
Fadhel et al. presented research concerning the evaluation of the databases for a low-cost water quality sensing system. Authors identified InfluxDB as the most suitable solution, listing the ease of installation and maintenance, support for multiple interface formats, and HTTP GUI as the deciding factors. In the second part of the research, they conducted performance experiments and determined that InfluxDB can handle the load from 450 sensors.
Testing environment
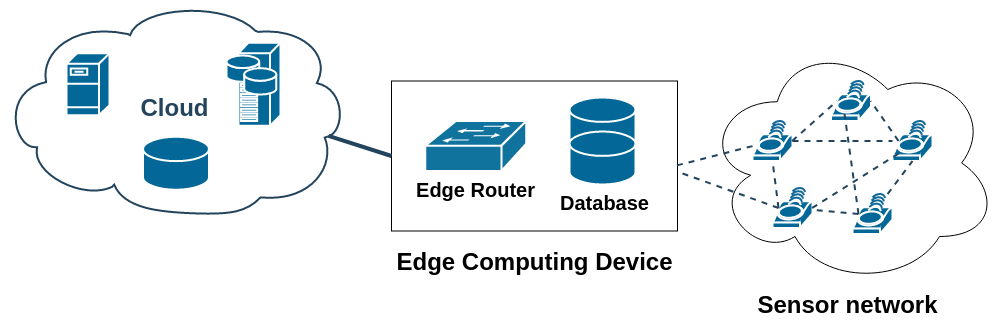
Testing environment
-
6LoWPAN-based sensor network, collecting measurements such as air quality and weather condition metrics
-
Edge device, that serves both as a 6LoWPAN gateway and as a database and analytical engine
-
Cloud-based service, long-term storage of aggregated metrics
-
During tests, sensor readings generator was used to allow for running tests multiple times in a short span of time
Edge device specification
- Single board computer - Raspberry Pi 4
- CPU - Broadcom BCM2711, Quad core Cortex-A72 (ARM v8) 64-bit SoC @ 1.5GHz
- Memory - 4GB LPDDR4-3200 SDRAM
- Storage - SDHC card (16 GB, class 10)
- OS - Raspbian GNU/Linux 10 (buster) with kernel version 4.19.50-v7l+
- TI CC2531
Readings data model

Data model used for the performance experiments
Each data point sent by the sensor consist of air quality metrics in the form of NO2 and dust particle size metrics PM2.5 and PM10. Besides, it also carries information about weather conditions such as ambient temperature, pressure, and humidity. Each reading is timestamped and tagged with the location of the sensor and the unique sensor identifier.
Selected databases
- TimescaleDB - open-source, time-series database, written in C programming language, distributed as an extension to relational database, PostgreSQL. Developed by Timescale Inc. Thanks to being an extension, it supports all functionalities of PostgreSQL, as well as the same client libraries. According to DB-Engines ranking, it is the 8th most popular time-series database.
- InfluxDB - open-source, time-series database, written in Go programming language, developed and maintained by InfluxDB Inc. It has no external dependencies, is distributed as a single binary which allows for easy deployment process. Supports InfluxQL, which is a custom, SQL-like query language with support for aggregation functions over time series data. According to DB-Engines ranking, it is the most popular time-series database.
Selected databases
- Riak TS - open-source, distributed NoSQL database, optimized for the time series data and built on top of Riak KV database, created and maintained by Basho Technologies. Riak TS is written in Erlang, supports masterless, multi-node architecture to ensure resiliency to network and hardware failures. It supports SQL-like query language with aggregation operations over time-series data. It offers both HTTP and PBC APIs. According to DB-Engines ranking, it is the 15th most popular time-series database.
- SQLite - open-source relational database, written in C language. The SQLite source code is available in the public domain. It is a lightweight, single file, implemented only as a library, does not require separate server process. It provides all functionalities directly by the function calls. It is widely used in embedded systems, also thanks to it's simplicity. It does not offer specific support for time-series data.
Selected databases
- PostgreSQL - open-source, relational database management system, written in C language and currently maintained by PostgreSQL Global Development Group. It runs on all major operating systems, is ACID compliant and supports various extensions, namely TimescaleDB. It supports a major part of the SQL standard. In addition, it offers support for storing and querying document data thanks to JSON, JSONB, XML and Key-value data types. According to DB-Engines ranking, it is the 4th most popular database overall. It does not offer any dedicated support and optimizations for time-series data.
Selected databases

Versions of databases and client libraries used during experiments
Performance experiments
-
Used data from 10 simulated sensors, where each sensor sends reading every 15 seconds over 24 hours, which results in 28800 data points
-
Insertion of data points, one-by-one and in batches of 10 points each batch
-
Insertion simulation ran 50 times (except for SQLite, where simulations were run 20 times due to relatively long simulation time)
-
Query for average temperature in the chosen period, grouped by location
-
Query for minimum and maximum values of NO2, PM2.5, and PM10 in the selected period, grouped by location
-
Query that counts data points grouped by sensor ID in the selected period, for which NO2 was larger than selected value and location was equal to a specific one
-
Each query was executed 5000 times
Insertion results

Number of data points ingested per second for each tested database
First query results
Tested aggregation query


Average query execution time
Second query results
Tested aggregation query
Average query execution time


Third query results
Tested aggregation query
Average query execution time


Summary
-
PostgreSQL emerges as the best performing solution for the evaluated workloads, with the exception for first evaluated query, where InfluxDB turned out to be more performant
-
Batching records for insertion causes performance gains, as high as 8.65 more data points ingested per second for InfluxDB
-
With the exception of Riak TS, all databases executed tested queries on average in less than 80 ms and the relative differences in performance for queries are not as high as in the case of insertion
Next steps
- Tests for higher volume of data to ingest
- Tests for higher volume of data to query
- Removing SD card bottleneck - using SSD storage
- Tests for improvements in network bandwidth use vs cloud-based solution
Bibliography
-
DBMS popularity broken down by database model (accessed on Februrary 2nd, 2020), https://db-engines.com/en/ranking_categories
-
InfluxDB overview (accessed on Februrary 2nd, 2020), https://www.influxdata.com/products/influxdb-overview/
-
PostgreSQL documentation (accessed on January 9th, 2020), https://www.postgresql.org/about/
-
Raspberry Pi 4 datasheet (accessed on February 4th, 2020), https://www.raspberrypi.org/documentation/hardware/raspberrypi/bcm2711/rpi_DATA_2711_1p0_preliminary.pdf
-
Riak TS datasheet (accessed on January 9th, 2020), https://riak.com/content/uploads/2016/05/Riak-Riak-TS-Datasheet.pdf
-
SQLite documentation (accessed on January 9th, 2020), https://www.sqlite.org/about.html
Bibliography
- TimescaleDB : SQL made scalable for time-series data (2017), https://pdfs.
semanticscholar.org/049a/af11fa98525b663da18f39d5dcc5d345eb9a.pdf - Bader, A., Kopp, O., Falkenthal, M.: Survey and comparison of open source time series databases. In: Mitschang, B., Nicklas, D., Leymann, F., Schoning, H., Herschel, M., Teubner, J., Harder, T., Kopp, O., Wieland, M. (eds.) Datenbanksysteme fur Business, Technologie und Web (BTW 2017) - Workshopband. pp. 249-268. Gesellschaft fur Informatik e.V., Bonn (2017)
- Fadhel, M., Sekerinski, E., Yao, S.: A Comparison of Time Series Databases for
Storing Water Quality Data, pp. 302-313 (04 2019) - Goldschmidt, T., Jansen, A., Koziolek, H., Doppelhamer, J., Breivold, H.P.: Scalability and robustness of time-series databases for cloud-native monitoring of industrial processes. In: 2014 IEEE 7th International Conference on Cloud Computing. pp. 602-609 (June 2014)
Bibliography
- Kiefer, R.: TimescaleDB vs. PostgreSQL for time-series: 20x higher inserts, 2000x faster deletes, 1.2x-14,000x faster queries (accessed on January 9th, 2020), https://blog.timescale.com/blog/timescaledb-vs-6a696248104e/
- Liu, X., Nielsen, P.: Air quality monitoring system and
benchmarking. pp. 459 470 (08 2017) - Paul, A., Pinjari, H., Hong, W.H., Seo, H., Rho, S.: Fog computing-based IoT for
health monitoring system. Journal of Sensors 2018, 1-7 (10 2018) - Pungila, C., Fortis, T.F., Ovidiu, A.: Benchmarking database systems for the requirements of sensor readings. IETE Technical Review 26, 342-349 (08 2009)
- Wlodarczyk, T.W.: Overview of time series storage and processing in a cloud environment. In: 4th IEEE International Conference on Cloud Computing Technology and Science Proceedings. pp. 625-628 (Dec 2012)