What's new in Solr 6
But before we start
The standard for enterprise search.

Truly open source & proven at scale
Fast, scalable, reliable, distributed
NRT indexing and search
Stats, analytics, geospatial
Extremely pluggable

Solr in 2 minutes
Are you ready?
Quick start Solr
Extract:
tar xvf solr-6.0.1.tgz (linux/mac)
Run:
./bin/solr start -e schemaless
./bin/solr start -e cloud (interactive cloud setup)
./bin/solr start -e cloud -noprompt (zero effort demo cloud setup)
./bin/solr -help
Index documents:
./bin/post -c gettingstarted /path/to/local/data.extn
./bin/post -help
# Extn = {xml,json,jsonl,csv,pdf,doc,docx,ppt,pptx,xls,xlsx}
# Extn = {odt, odp, ods, ott, otp, ots, rtf, htm, html, txt, log}
Search:
curl 'http://localhost:8983/solr/gettingstarted/select?q=*:*'
curl 'http://localhost:8983/solr/gettingstarted/select?q=my_query'
Stop:
./bin/solr stop
./bin/solr stop -p 8983
./bin/solr stop -allSolr 5.x
Past and present
State of the project
- API: search, update, collection, schema, config
- Faceting: term, range, query, pivots, multi-select, heatmap
- Stats: min, max, mean, stddev, percentiles, count distinct
- Security: Basic auth, SSL, kerberos
- SolrJ streaming API
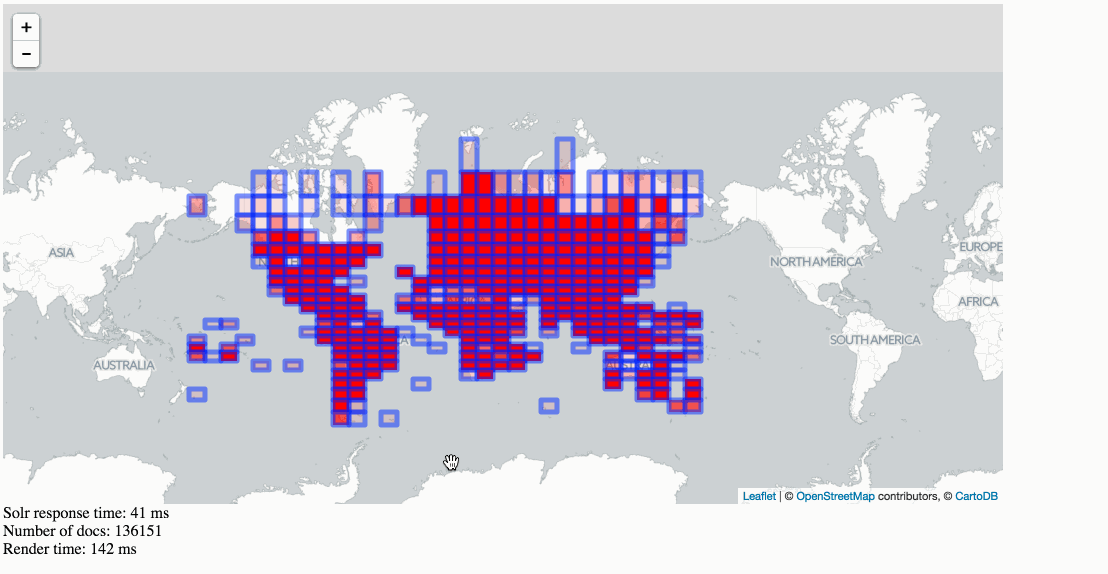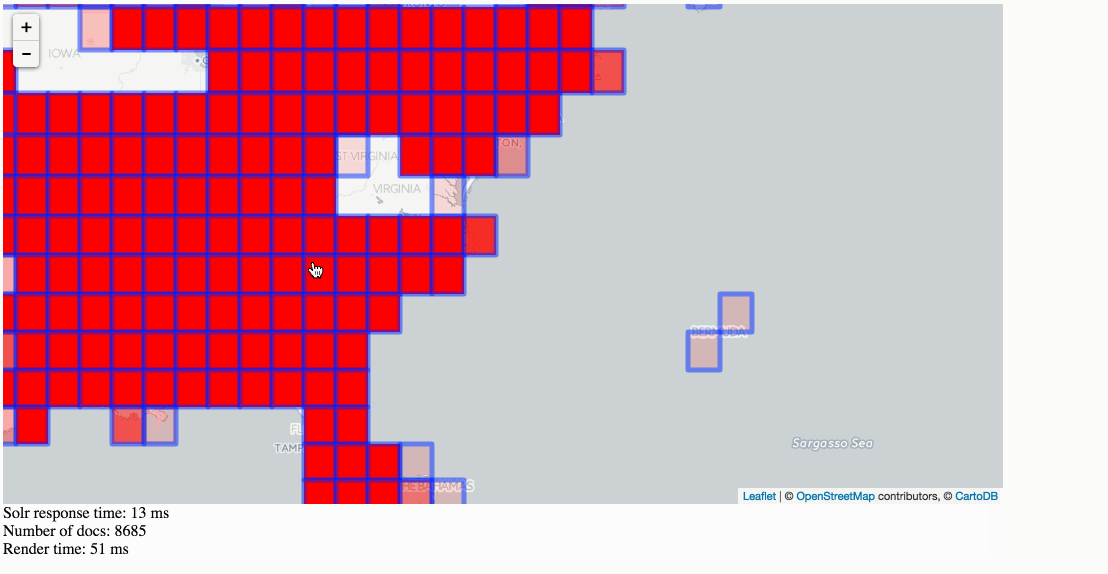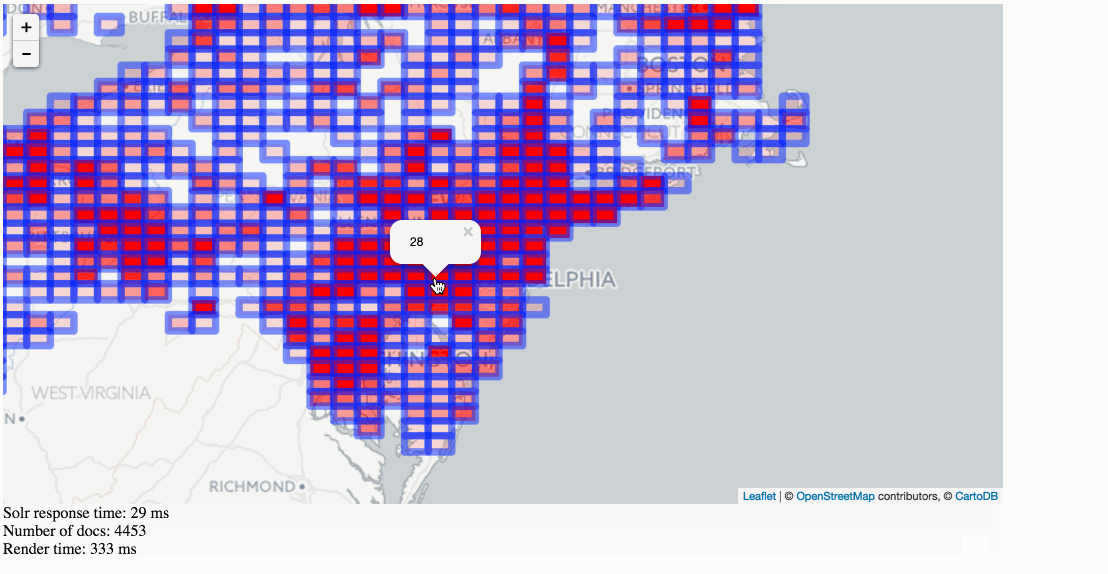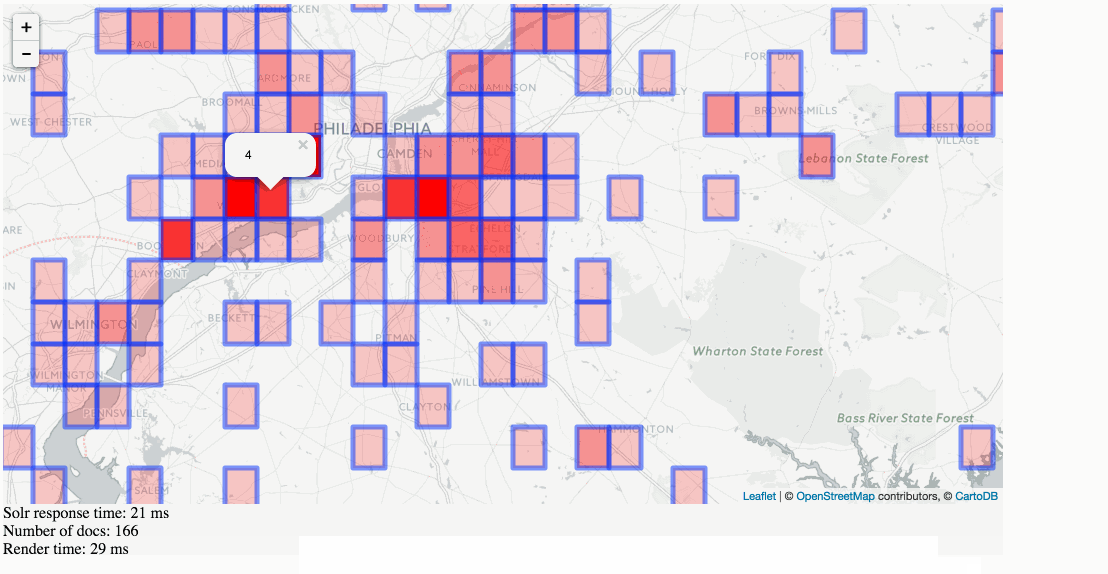
Solr Heatmaps in action
Solr 6
Solr 6
- Released in April 2016
- Developed on master branch
- Solr 6.0.1 released last week
Solr 6: Parallel SQL
- Parallel execution of SQL across SolrCloud collections
- Compiled to SolrJ Streaming API which supports parallel relational algebra and real-time map/reduce
- Executed in parallel over SolrCloud worker nodes
- SolrCloud collections are relational 'tables'
- JDBC thin client as a SolrJ client
select category, count(*), sum(inventory), min(price),
max(price), avg(outstanding)
from mytable
where text='XXXX'
group by category
order by sum(inventory) asc limit 10
select id, category from collection1
where category = 'dvd bluray'
order by category desc limit 100
select fieldA, fieldB, count(*), sum(fieldC), avg(fieldY)
from collection1
where fieldC = 'term1 term2'
group by fieldA, fieldB
having sum(fieldC) > 1000
order by sum(fieldC) asc
limit 100Solr 6: Parallel SQL
Solr 6: Parallel SQL
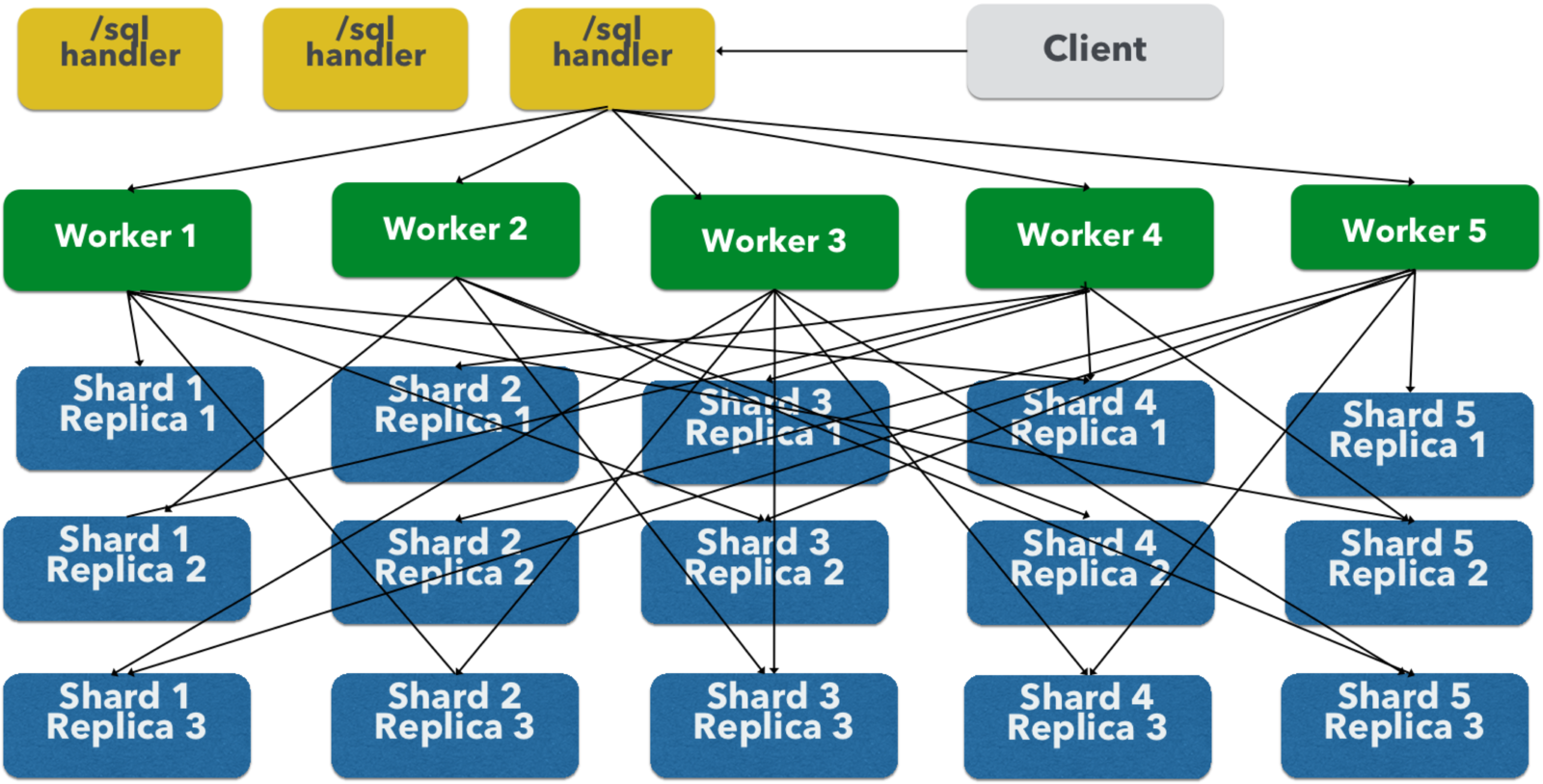
SQL over HTTP
curl "http://localhost:8983/solr/movies/sql" \
--data-binary \
"stmt=select name,rank from movies \
where rank='[0 TO 10]' order by rank desc limit 10"
curl "http://localhost:8983/solr/movies/sql" \
--data-binary \
"stmt=select avg(rating) from movies \
where nb_voters='[10000 TO *]' and director='scor*'"
curl "http://localhost:8983/solr/movies/sql" \
--data-binary \
"stmt=select director, avg(rating), count(*) from movies \
where nb_voters='[10000 TO *]' group by director"Solr 6:Graph traversal query
- Basic traversal that follows nodes to edges, optionally filtering during traversal
- Equivalent to a repeated join query
- BFS search with cycle detection
- Use cases: role based access control, query augmentation using hyponyms and hypernyms, hierarchy or ontology browsing
Solr 6: Graph traversal query
// Assuming each document is a person, find Philip and all his ancestors
fq={!graph from=parent_id to=id}id:"Philip J. Fry"
// assume each doc is a tweet
// search for all tweets mentioning java by me or people I follow
q=java&fq={!graph from=following_id to=id maxDepth=1}id:"shalinmangar"Solr 6: Cross DC replication
- Accommodate 2 or more data centers
- Active/passive disaster recovery
- Support limited bandwidth links
- Eventually consistent passive cluster
Why not a single SolrCloud?
- Same update is transferred to each replica
- Synchronous indexing means burst-indexing constrained by cross-DC link
- Increased latency for indexing operations
- Need a ZooKeeper node in a 3rd DC to break ties
- Search requests are not DC aware, may choose a remote replica
Solr 6: Cross DC Replication
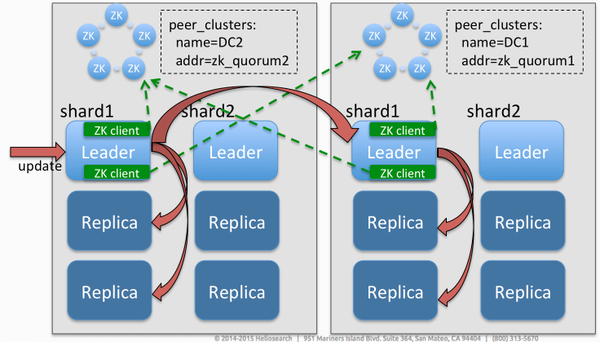
Solr 6: Cross DC Replication
- Scalable: no SPoF and/or bottleneck
- Peer cluster can have different replication factors
- Asynchronous updates, no penalty for indexing operations and burst indexing
- Push operations for low latency replication
- Low overhead -- uses existing transaction logs
- Leader-to-leader communication ensures an update is sent only once to peer cluster
Solr 6: BM25 scoring
- Default in Solr 6
- Tweak the scoring function per-field type
- Classic tf-idf vector space model still available
Solr 6: What else?
- SolrCloud Backup/Restore API
- Ability to read DocValues as if they were stored
- BKD tree based new numeric dimensional values
- Geo3d search
- New AngularJS based admin UI the default
- Java 8 only
Solr 6.1 and beyond
Streaming expressions++
- Graph traversals with shortest paths, node walking, Gremlin implementation
- Machine learning models -- Logistic Regression
- Alerts, pub-sub, updates
Solr 6: A modern API
- Query and updates continue to support JSON, XML, Binary, Smile, CSV)
- All other APIs are JSON by default, 'wt' still supported
- Input payloads will be HOCON (human-optimized config object notation), a super-set of JSON
- Requests that change state must be HTTP POST
- The new API is versioned at /v2. Old API is available at /v1
- Introspection support via JSON schema
Solr 6: A typical API call
curl -XPOST -H 'Content-type:application/hocon' --data-binary '{
operation : {
operation parameters
}
}' http://host:port/v2/endpoint
Solr 6: API introspection
http://localhost:8983/solr/v2/collections/_introspect?command=create-alias
{"spec":{
"collections.Commands": {
"documentation": "https://cwiki.apache.org/confluence/display/solr/Collections+API#CollectionsAPI-api1",
"methods": ["POST","GET"],
"url": {
"paths": ["/collections"]},
"commands": {
"create-alias":{
"description":"Create an alias for one or more collection",
"documentation":"https://cwiki.apache.org/confluence/display/solr/Collections+API#CollectionsAPI-api4",
"properties": {
"name": {
"type": "string",
"description": "The alias name to be created"},
"collections" :{
"type":"list",
"description":"The list of collections to be aliased"}},
"required" : ["name","collections"]}}}}}Solr 6: API endpoints
- /v2/collections/<collection-name>/* : Operations on specific collections. This could be collection APIs or a read/write operation on some collection
- /v2/cores/<core-name>/* : Operations on a core or a coreadmin call
- /v2/cluster/* : Cluster-wide operations which are not specific to any collections, overseer, cluster properties etc
- /v2/node/* : Operations on the node receiving the request. This is the counter part of the core admin API
Solr 6: API examples
// create a collection called 'golf'
curl -XPOST -d '{
create-collection : {
name : golf,
numShards : 2,
configTemplate : data_driven_schema_configs
}
}' http://localhost:8983/v2/collections/golf
// enable auto soft-commit every 2 seconds
curl -XPOST -d '{
set-property : { "updateHandler.autoSoftCommit.maxTime" : 2000 }
}' http://localhost:8983/v2/collections/golf/config
// index data
curl -XPOST -H 'Content-type: application/json' -d '[
{
"course": "fossil trace",
"city": "Golden",
"state": "CO",
"par": 72,
"score": 76,
"gir": 15,
"fairways": 10
}
]' http://localhost:8983/v2/collections/golf/update/json/docs
// query using JSON API
curl -d '{
query : "*:*",
rows: 10,
fields: [course, score, par, gir],
sort: "date desc"
}' http://localhost:8983/v2/collections/golf/query
What else?
- Update-able DocValues API
- Improved inter-node communication using async IO and http/2
- Expect to see more new Lucene features being exposed by Solr
- Many other optimizations, bug fixes and new features
Solr 6: Recap
- Massively scalable, streaming analytics
- Well known SQL interface to a powerful search engine
- Multiple data center support
- Scalable, fast, resilient SolrCloud
Questions?
shalin [at] apache [dot] org