Building a data warehouse using Spark SQL
Budapest Data Forum 2018
Gabor Ratky, CTO
About me
- Hands-on CTO at Secret Sauce to this day
- Software engineer at heart
- Made enough bad decisions to know that everything is a trade-off
- Code quality and maintainability above all
- Not writing code when I don't have to
- Not building distributed systems when I don't have to
- Not a data warehouse guy, but ❤️ data
Simple is better than complex.
Complex is better than complicated.
The Zen of Python, by Tim Peters
About Secret Sauce
- SV startup in Budapest
- B2B2C apparel e-commerce company
- Data driven products to help merchandising
- Services build on top of the data we collect
- Cloud-based infrastructure (AWS)
- Small, effective teams
- Strong engineering culture
- Code quality
- Code reviews
- Testability
- Everybody needs data to do their jobs
Early days
Partner data


MongoDB
$ mongoimport

MongoDB

Redshift
S3


PostgreSQL
PostgreSQL


Partner data
Event analytics
kafka
kafka





MongoDB
Databricks
S3
PostgreSQL
PostgreSQL
Partner data
Data warehousing
kafka
kafka

Why Databricks and Spark?
- Storage and compute are separate
- Managed clusters operated by Databricks
- Fits into and runs as part of our existing infrastructure (AWS)
- Right tool for the job
- Data engineers use pyspark
- Data analysts use SQL
- Data scientists use Python, R, SQL, H2O, Pandas, scikit-learn, dist-keras
- Shared metastore (databases and tables)
- Collaborative, interactive notebooks
- Github integration and flow
- Automated jobs and schedules
- Programmatic API
Clusters
Workspace
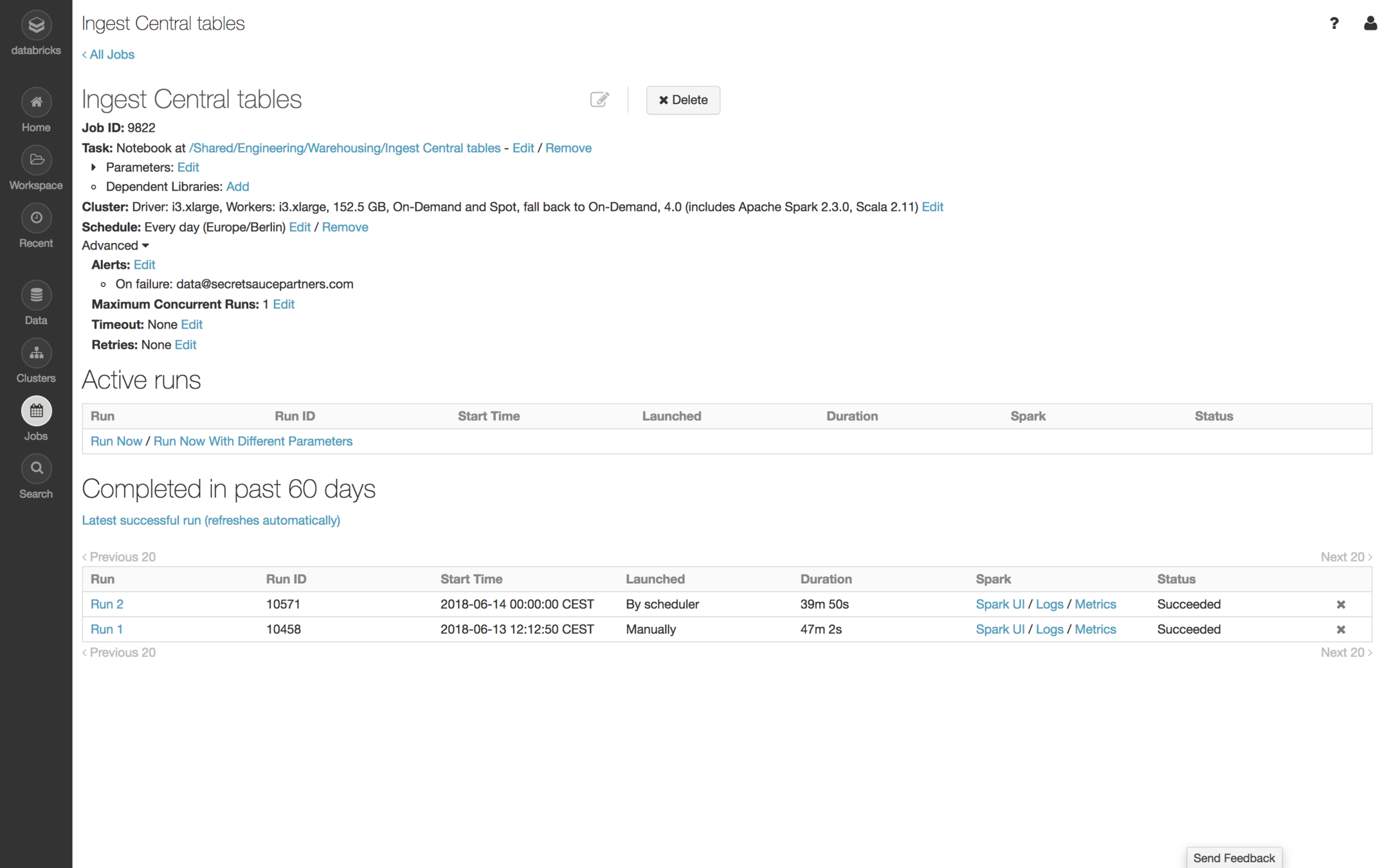
Notebooks
Jobs
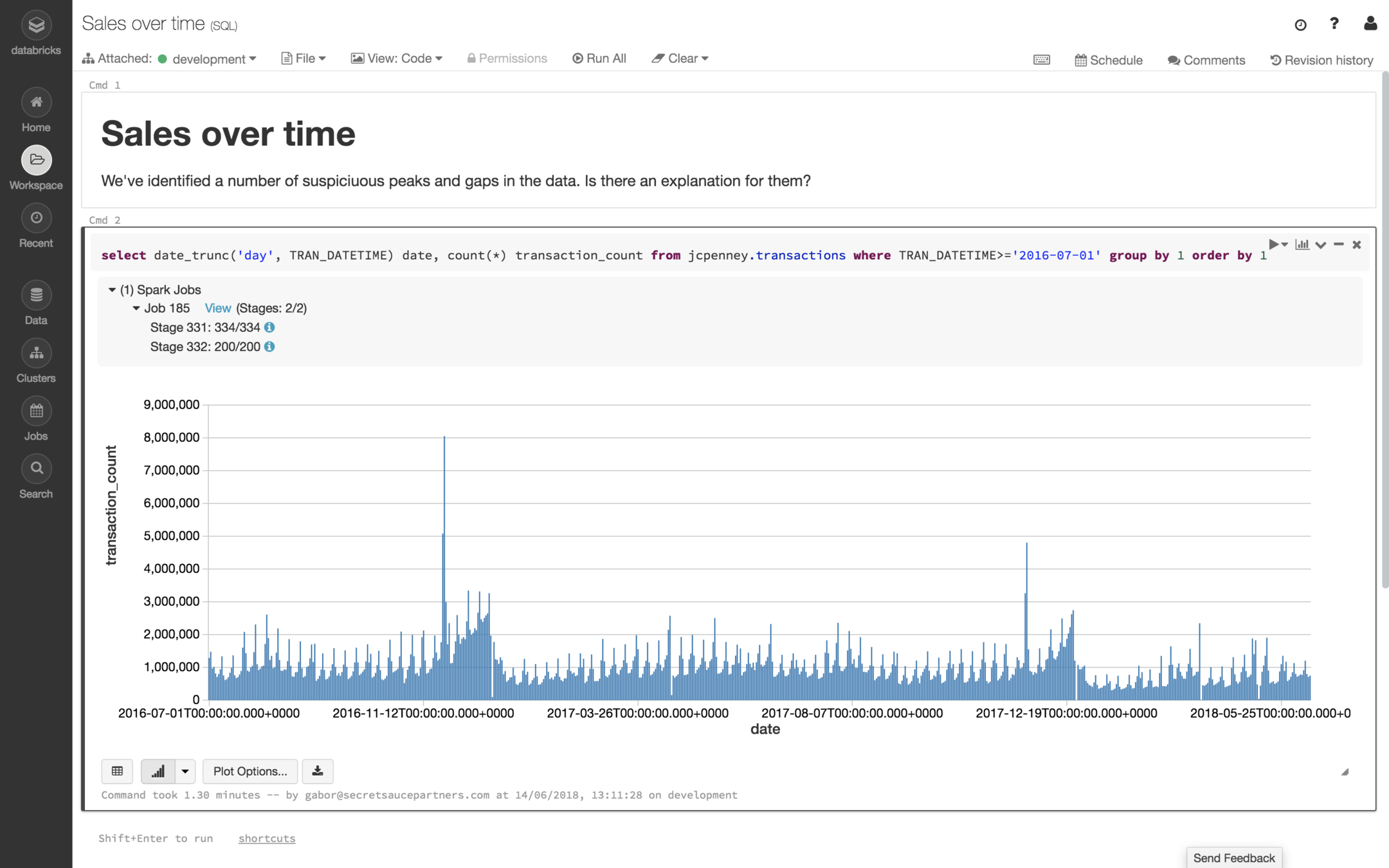
Analytics
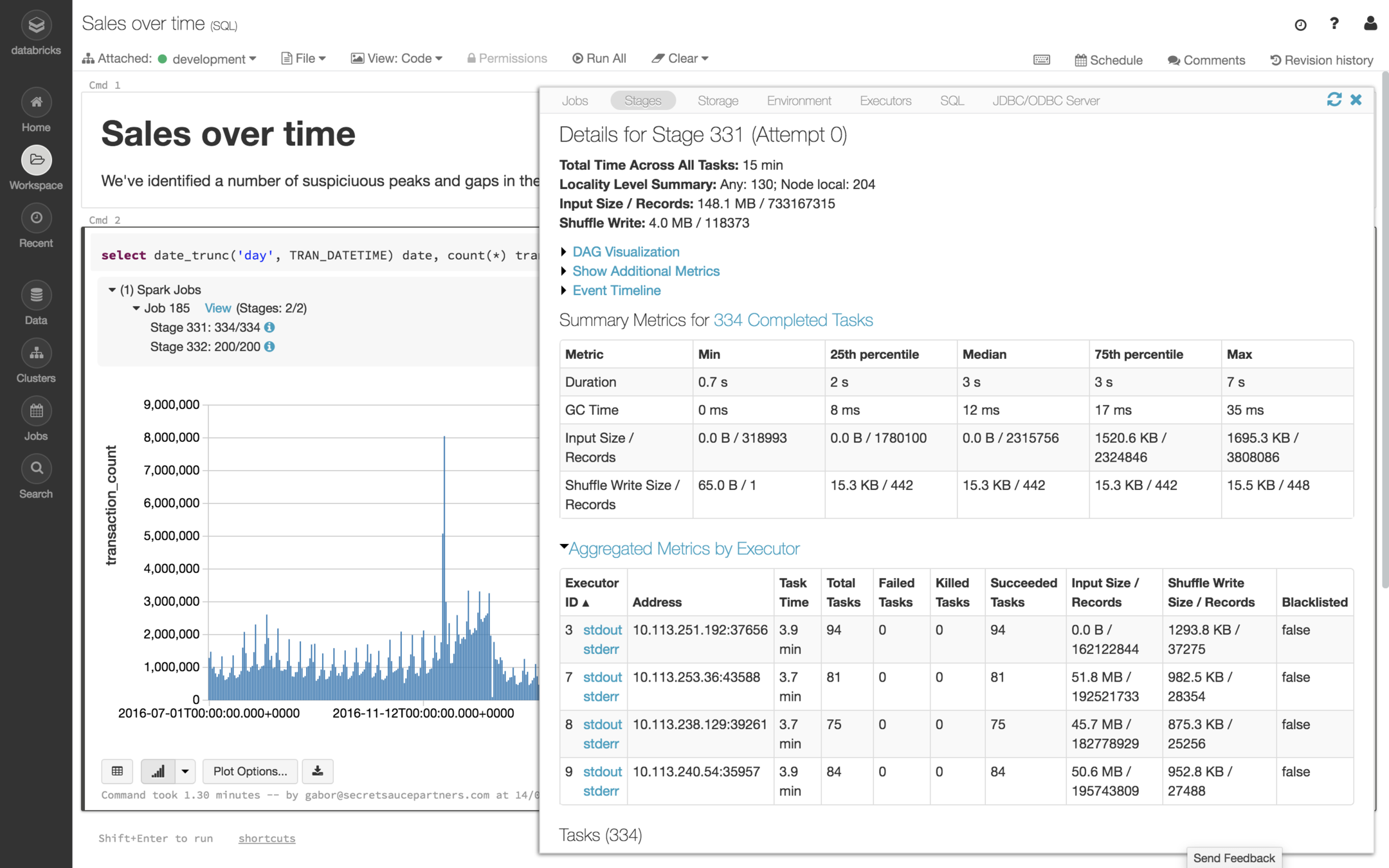
Analytics
Build vs buy
BUY
Cost
Cost (Redshift)
- Persistent data warehouse
- 4x ds2.xlarge nodes (8TB, 16 vCPU, 124GB RAM)
- On-demand price: $0.85/hr/node
- 1 month ~ 732 hours
$2,488
Cost (Databricks)
- Ephemeral, interactive, multi-tenant cluster
- 8TB storage (S3)
- i3.xlarge driver node (4 vCPU, 30.5GB RAM)
- 4x i3.xlarge worker nodes (16 vCPU, 122GB RAM)
- Compute: $0.712/hr
- $0.312/hr on-demand price
- 4x $0.1/hr spot price
- Databricks: $2/hr
- $0.4/hr/node
- Storage: $188/mo + change
- 1 month ~ 22 workdays ~ 176 hours
$665
Utilization (Redshift)
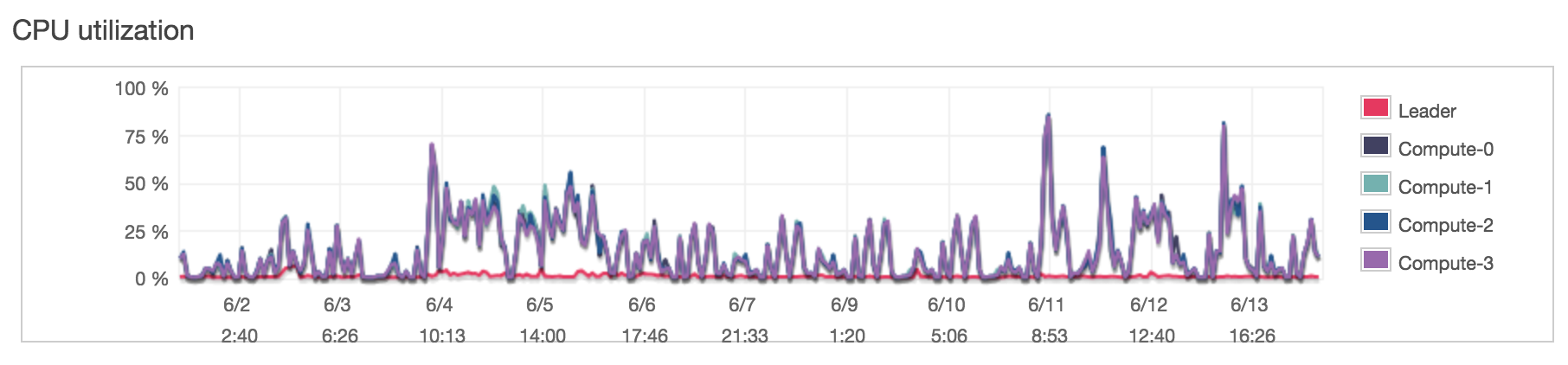
Utilization (Redshift)
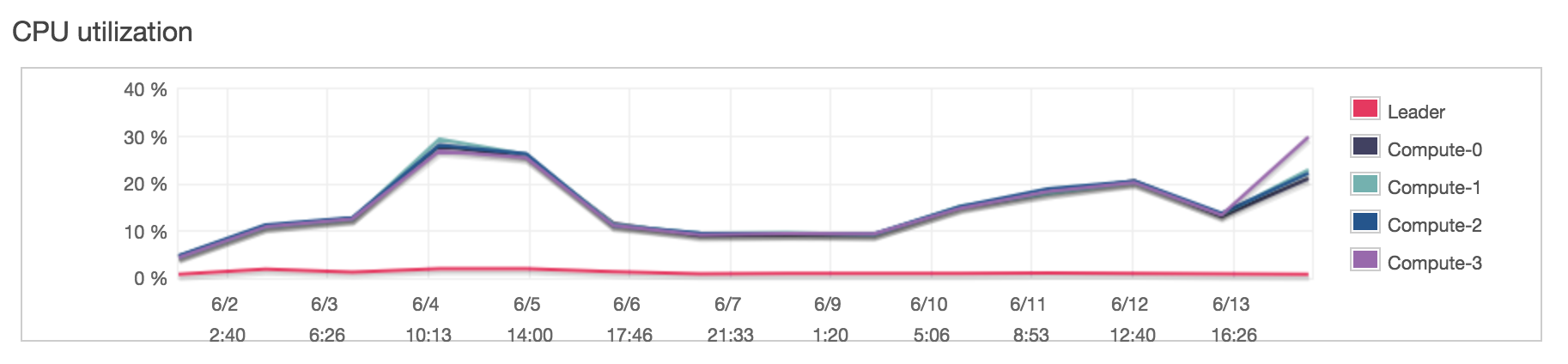
Utilization (Databricks)
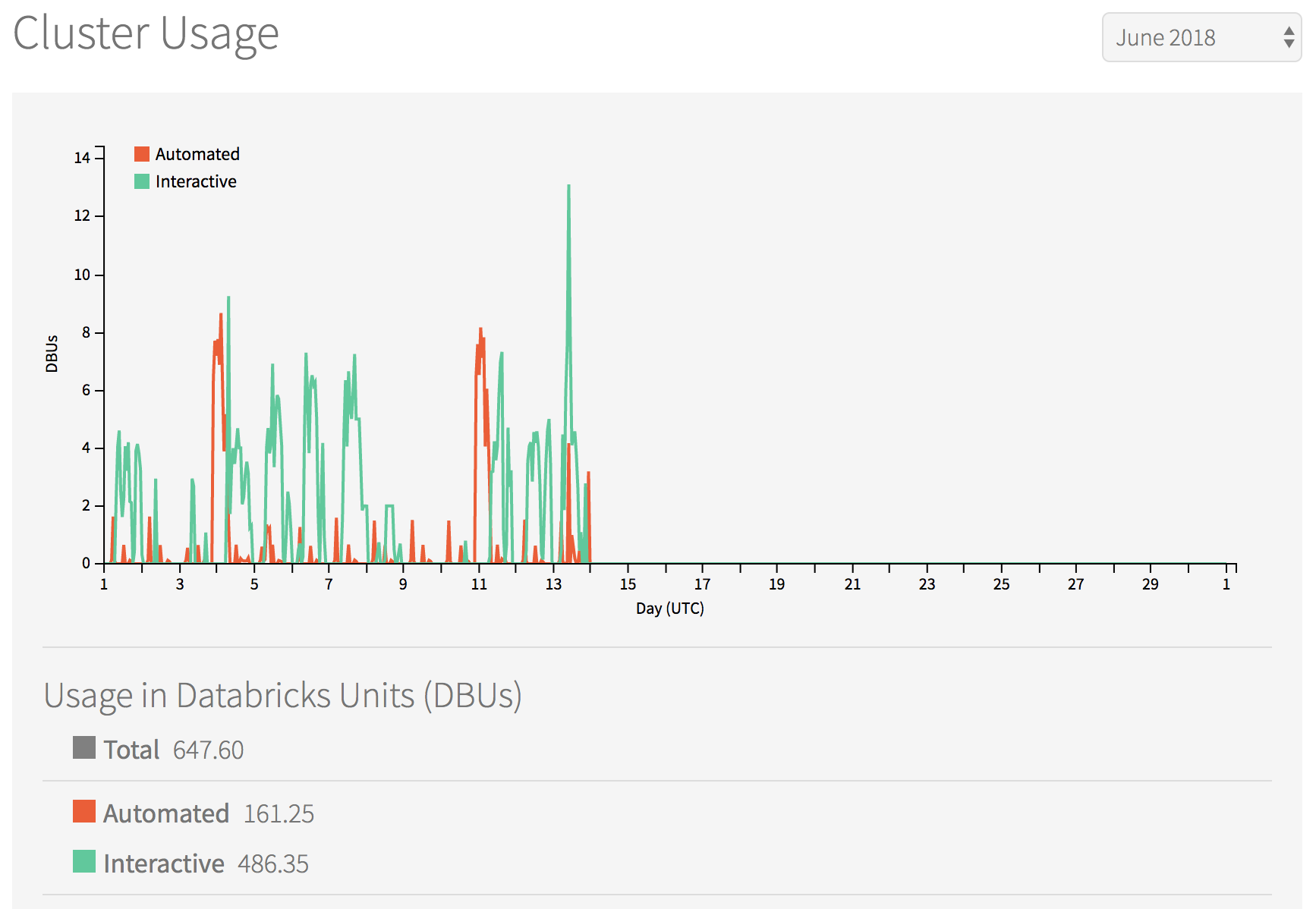
~34 DBU/day, ~4.5 DBU/hr
~11.5 DBU/day
Our experience so far
- Started using Databricks in January 2018
- Quick adoption across the whole company
- Fast turnaround on data requests
- Easy collaboration between technical and non-technical people
- Databricks allows us to focus on data engineering, not data infrastructure
- Github integration not perfect, but fits into our workflow
- Partitioning and schema evolution needs a lot of attention
- Databricks is an implementation detail, pick your poison
- Everything is a trade-off, make the right ones
NIHS*
* not invented here syndrome
Thanks!
Questions?
gabor@secretsaucepartners.com