DitC: Data Management
Naive engineer's approach
- Leverage thin cloning (ZFS/NetApp/dotscience style)
- Reset on every test/service initialization, flush out order/state-dependent pieces, work towards code-driven seeding and services being responsible for their minimum-viable data.
- https://www.slideshare.net/SeanChittenden/postgresql-zfs-best-practices
- https://github.com/dotmesh-io/dotmesh
DataOps, what hath god wrought
Like VCS, but for Data

"Like Git LFS, it just works!"
The measured middleground
no fun for anyone
Follow best practices, work less hard
- https://github.com/snowplow/iglu/ (artifacts management, versioning, data hub, for structured data)
- https://github.com/pachyderm/pachyderm (full lifecycle management, acquisition, cleaning, versioning, etc. It's a pipeline.)
-
Full cowboy: mkdir -p volume-snapshots && docker run --rm --volumes-from mariadb -v $(shell pwd)/volume-snapshots:/docker-volume-snapshots debian:stretch-slim tar -czvf "/volume-snapshots/snapshot$(DATE).tar.gz" /var/lib/mariadb
Follow best practices, work really hard
- Liquibase, datical, Flyway
- Don't want to maintain it all over the shop?
- Specify consumers, call an API (versioned!), bulk load schema and minimal data on instantiation. Document once, profit over and over.
careful thought > more tech
It's hard out here.
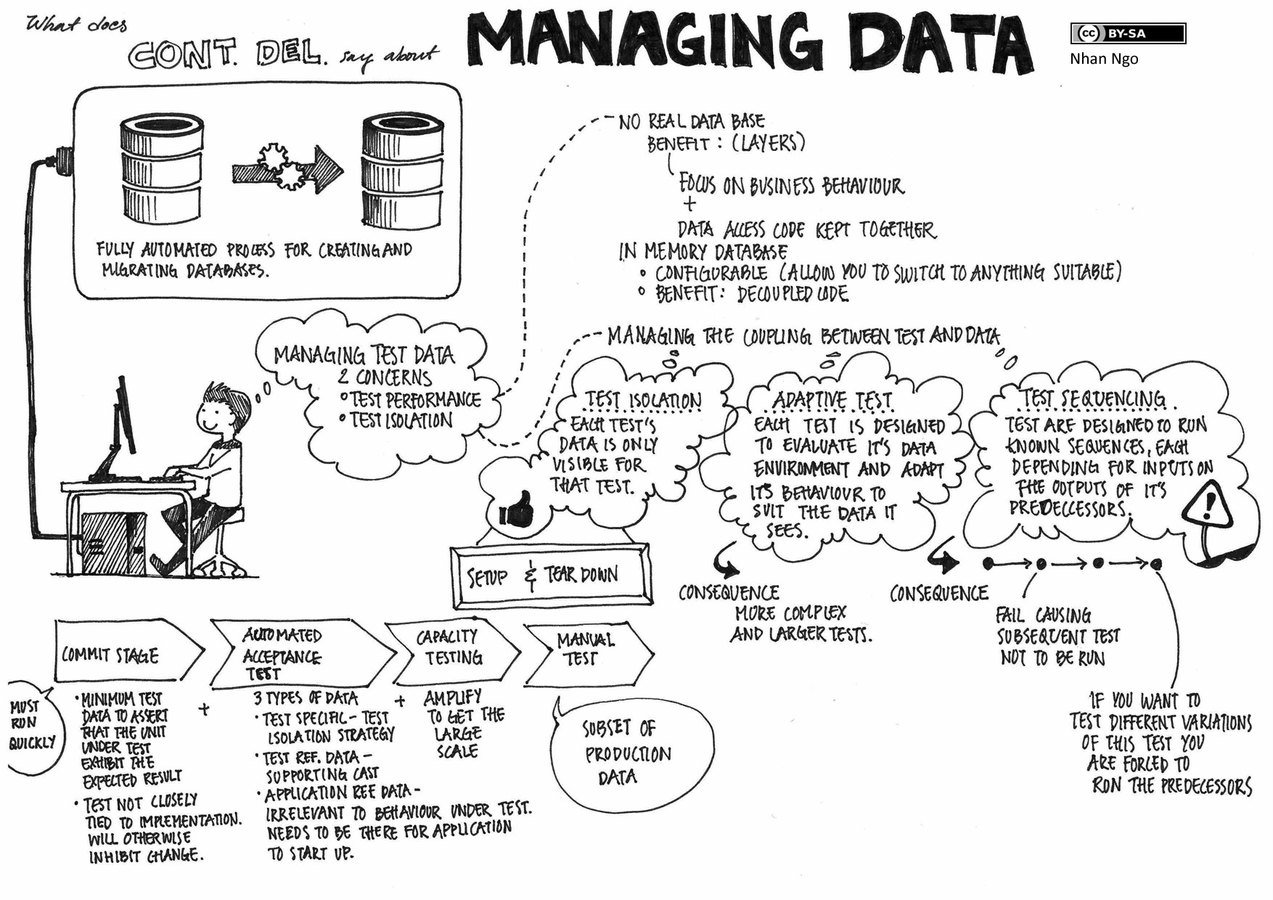
Are we solving the right problem?
