Tokenizaton
parsing
compilation
IN
ruby
Tomasz (warkocz) Warkocki
plan
- Ruby
- Tokenization
- Parsing
- Compilation?
ruby

ruby
- dynamic, object-oriented programming language
- Yukihiro “Matz” Matsumoto
- public release 1995
- inspired by: Perl, Smalltalk, Eiffel, Ada and Lisp
- various versions: MacRuby, IronRuby, Topaz, JRuby
- presentation is based on MRI (Matz’s Ruby Interpreter)
processing steps
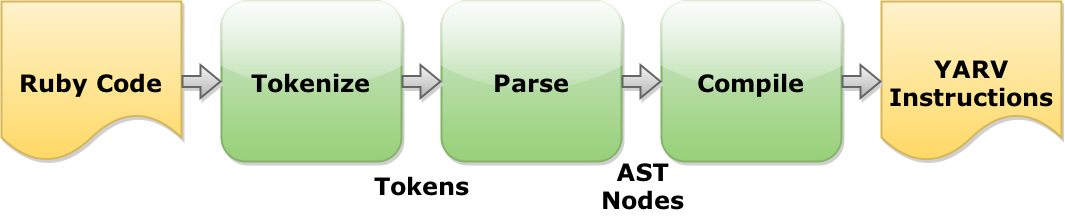
Tokenization
10.times do |n|
puts n
end
parse.y and parser_yylex method
ripper
require 'ripper'
require 'pp'
code = <<STR
10.times do |n|
puts n end
STR
puts code
pp Ripper.lex(code)[[[1, 0], :on_int, "10"],
[[1, 2], :on_period, "."],
[[1, 3], :on_ident, "times"],
[[1, 8], :on_sp, " "],
[[1, 9], :on_kw, "do"],
[[1, 11], :on_sp, " "],
[[1, 12], :on_op, "|"],
[[1, 13], :on_ident, "n"],
[[1, 14], :on_op, "|"],
[[1, 15], :on_ignored_nl, "\n"],
[[2, 0], :on_ident, "puts"],
[[2, 4], :on_sp, " "],
[[2, 5], :on_ident, "n"],
[[2, 6], :on_sp, " "],
[[2, 7], :on_kw, "end"],
[[2, 10], :on_nl, "\n"]]parsing
bison

Next version of Yacc (Yet Another Compiler Compiler)
Look-Ahead Left Reversed Rightmost Derivation (LALR) Parse Algorithm
SpanishPhrase : me gusta el ruby {
printf("I like Ruby\n");
}
- Me gusta el Ruby.
- I like Ruby.
- Me gusta el Ruby.
- Le gusta el Ruby.
SpanishPhrase: VerbAndObject el ruby {
printf("%s Ruby\n", $1);
};
VerbAndObject: SheLikes | ILike {
$$ = $1; };
SheLikes: le gusta {
$$ = "She likes";
}
ILike: me gusta {
$$ = "I like";
}
$$ - returns a value from a child grammar rule to a parent
$1 - refers to a child’s value from a parent


Shift or reduce, that is the question? ;)
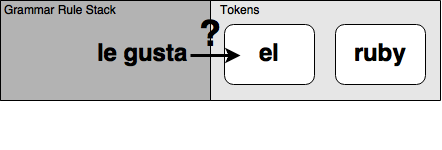
Look ahead and check table of possibilities (complex state machine)

Real example
wrug$ ruby -y simple.rb
Starting parse
Entering state 0
Reducing stack by rule 1 (line 903):
-> $$ = nterm $@1 ()
Stack now 0
Entering state 2
Reading a token: Next token is token tINTEGER ()
Shifting token tINTEGER ()
Entering state 41
Reducing stack by rule 505 (line 4411):
$1 = token tINTEGER ()
-> $$ = nterm simple_numeric ()
Stack now 0 2
Entering state 112
Reducing stack by rule 503 (line 4399):
$1 = nterm simple_numeric ()
-> $$ = nterm numeric ()
Stack now 0 2
Entering state 111
Reducing stack by rule 451 (line 3874):
$1 = nterm numeric ()
-> $$ = nterm literal ()
Stack now 0 2
Entering state 99
Reducing stack by rule 276 (line 2627):
$1 = nterm literal ()
-> $$ = nterm primary ()
Stack now 0 2
Entering state 85
Reading a token: Next token is token '.' ()
Reducing stack by rule 340 (line 3100):Again Ripper tool, this time parsing
require 'ripper'
require 'pp'
code = <<STR
10.times do |n|
puts n
end
STR
puts code
pp Ripper.sexp(code)wrug$ ruby lex2.rb
10.times do |n|
puts n
end
[:program,
[[:method_add_block,
[:call, [:@int, "10", [1, 3]], :".", [:@ident, "times", [1, 6]]],
[:do_block,
[:block_var,
[:params, [[:@ident, "n", [1, 16]]], nil, nil, nil, nil, nil, nil],
false],
[[:command,
[:@ident, "puts", [2, 5]],
[:args_add_block, [[:var_ref, [:@ident, "n", [2, 10]]]], false]]]]]]]Abstract Syntax Tree (AST)

[[:command,
[:@ident, "puts", [2, 2]],
[:args_add_block, [[:var_ref, [:@ident, "n", [2, 7]]]],
false]]]require 'ripper'
require 'pp'
code = <<STR
2+2*3
STR
puts code
pp Ripper.sexp(code)wrug$ ruby lex3.rb
2+2*3
[:program,
[[:binary,
[:@int, "2", [1, 2]],
:+,
[:binary, [:@int, "2", [1, 4]], :*, [:@int, "3", [1, 6]]]]]]
# @ NODE_SCOPE (line: 1)
# +- nd_tbl: (empty)
# +- nd_args:
# | (null node)
# +- nd_body:
# @ NODE_FCALL (line: 1)
# +- nd_mid: :puts
# +- nd_args:
# @ NODE_ARRAY (line: 1)
# +- nd_alen: 1
# +- nd_head:
# | @ NODE_CALL (line: 1)
# | +- nd_mid: :+
# | +- nd_recv:
# | | @ NODE_LIT (line: 1)
# | | +- nd_lit: 2
# | +- nd_args:
# | @ NODE_ARRAY (line: 1)
# | +- nd_alen: 1
# | +- nd_head:
# | | @ NODE_CALL (line: 1)
# | | +- nd_mid: :*
# | | +- nd_recv:
# | | | @ NODE_LIT (line: 1)
# | | | +- nd_lit: 2
# | | +- nd_args:
# | | @ NODE_ARRAY (line: 1)
# | | +- nd_alen: 1
# | | +- nd_head:
# | | | @ NODE_LIT (line: 1)
# | | | +- nd_lit: 3
# | | +- nd_next:
# | | (null node)
# | +- nd_next:
# | (null node)
# +- nd_next:
# (null node)wrug$ ruby --dump parsetree simple2.rbcompilation...


Ruby <= 1.8
Ruby >= 1.9
Based on:

Thank you!
Any questions? :)