Explaining the Encoder with the Activations
Ahcène Boubekki
PTB, Germany
Samuel G Matthiesen
Sebastian Mair
Linkøping/DTU soon
Linkøping
Motivation
Motivation


Objective: Learning Causal Relationships
How do we do that
for complex data?
Rios, F. L., Markham, A., & Solus, L. (2024).
Scalable Structure Learning for Sparse Context-Specific Causal Systems.
arXiv preprint arXiv:2402.07762.
What are the features?
Certainly not the pixels...
Motivation

What did you see?
Where did you look?
Where were
the eyes?
How many eyes
were there?
Motivation
Objective: Learning Causal Relationships
How do we do that
for complex data?
Rios, F. L., Markham, A., & Solus, L. (2024).
Scalable Structure Learning for Sparse Context-Specific Causal Systems.
arXiv preprint arXiv:2402.07762.
What are the features?
Certainly not the pixels...
Semantics?
Concepts?
How to see what
a model sees?
How to see what a model sees?

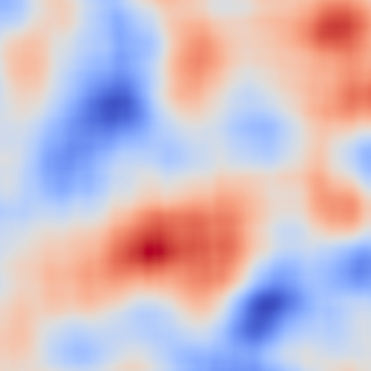
RISE
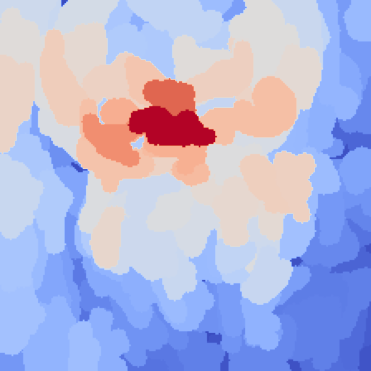
XRAI

GradCAM

LRP

IG





Dingo or Lion
These do not answer directly
what does the model see?
Deep Dream?
What makes it more a tiger than a tiger?
Too slow, impossible to train, not really useful.
What is important for the prediction?
Inconsistent, difficult to read, objective unclear.
Saliency Maps?
How is the neighborhood in the embedding?
Inspection of the embedding, "biaised" justification..
Prototypes/Concepts?
Counterfactual?
What should I change to change class?
Tricky to compute, but nice!
How to see what a model sees?
Standard Image Classifier

Encoder
convolutions, pooling, non-linearity, skip-connections, attention, etc.
Classifier
Single linear layer... eventually a softmax










clustering
k=10
k=5
What can we "explain"?
What can we explain?
Explain explanations





IG
LRP
GradCAM
RISE
XRAI
color gradient ~ rank
What can we explain?
Maximize the AUC-LeRF
Superpixelif.
improves AUC
SLIC and NAVE
return same perf?
AUC-LeRF is the problem!
Negative image of the bird max the AUC
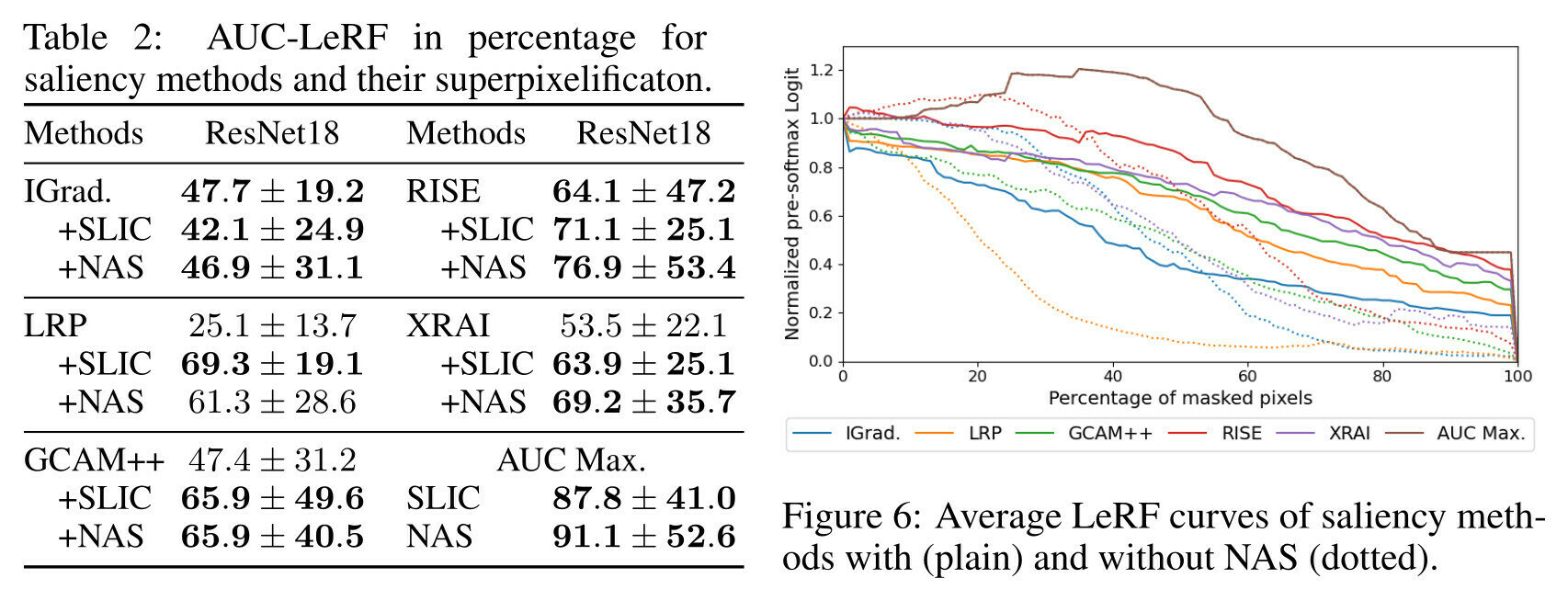
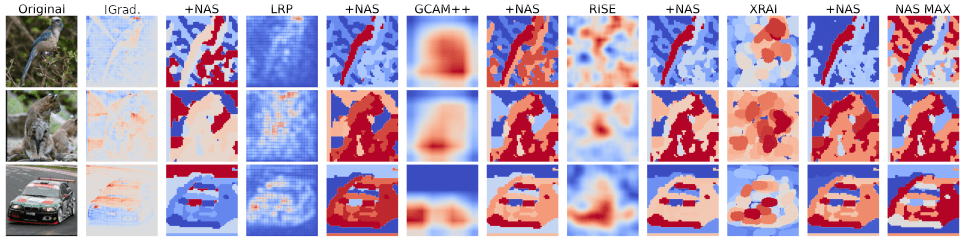
AUC MAX
What can we explain?
Connect Explanations and Semantics

Replace image-wise clustering
by a class-wise clustering
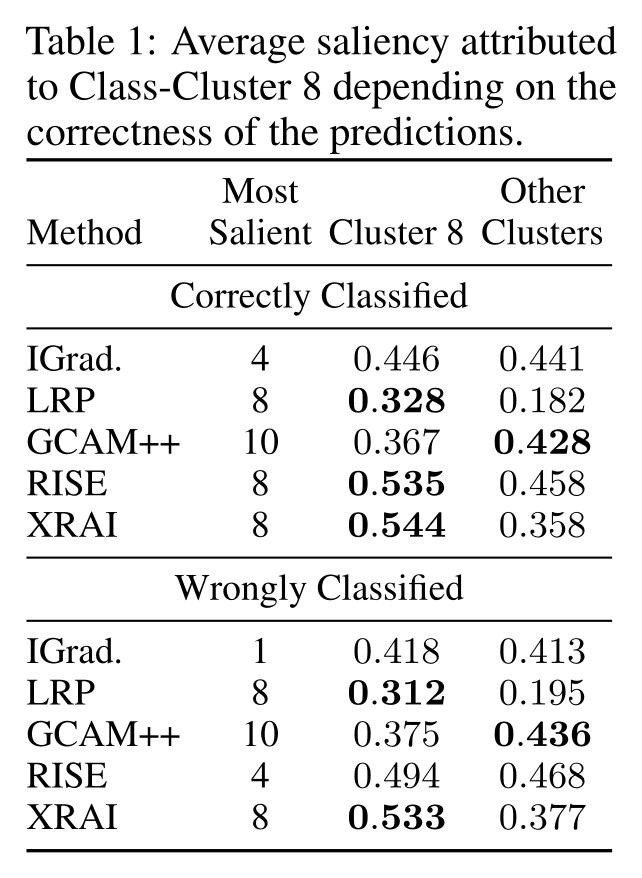
What can we explain?
Object Localization
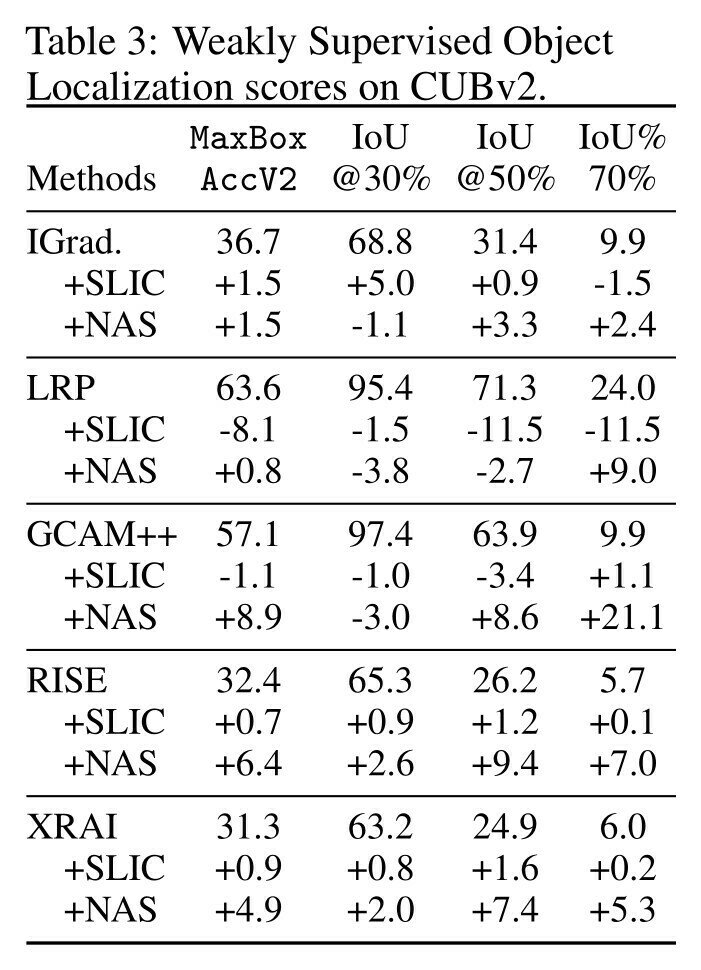
NAS always improves MaxBox
but not all thresholded IoU
Always improves the most difficult IoU@70%
NAVE captures
semantics
+
+
+
+
+
+
+
++
+
+
-
-
-
+
+
+
-
+
+
+
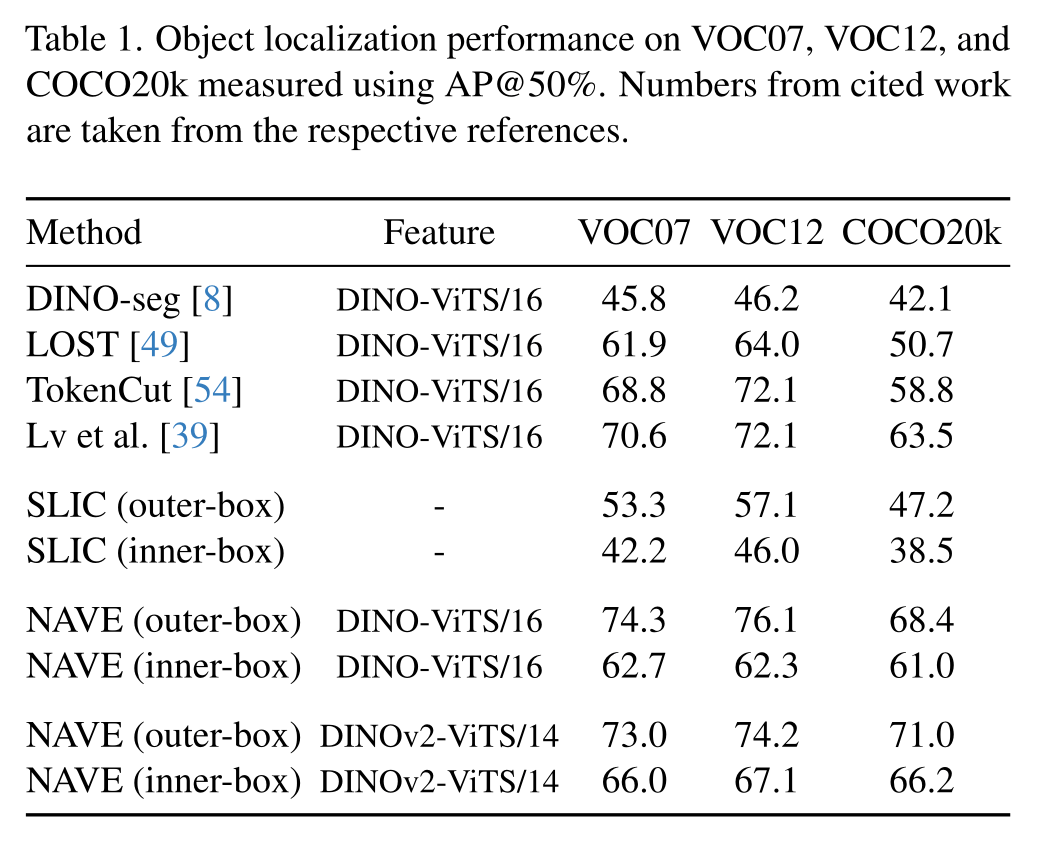
What can we explain?
Inspect Artifacts in ViT and Registers

Sometimes it works
for small ViT
Often it doesn't work
for big ViT
What can we explain?
Inspect Clever Saturation Effect
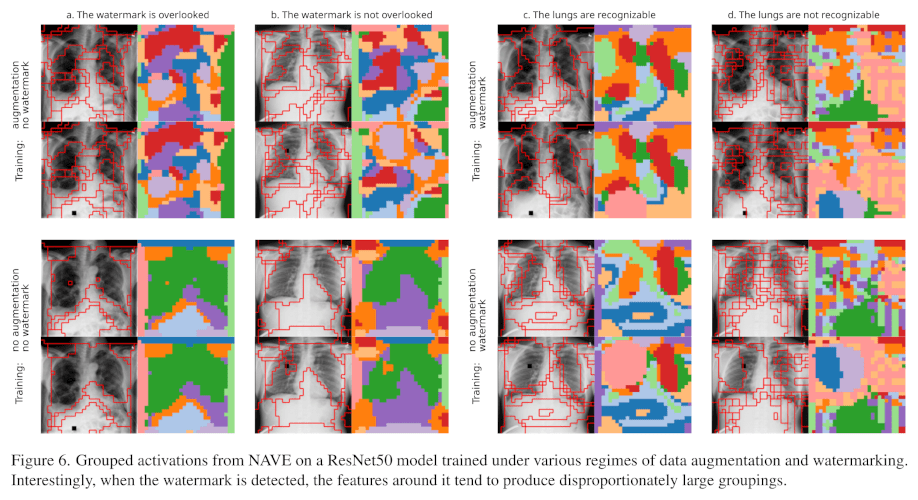
What can we explain?
Fake Tumor Localization

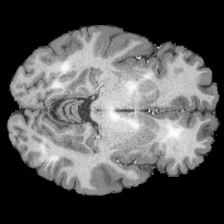
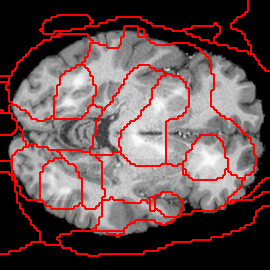

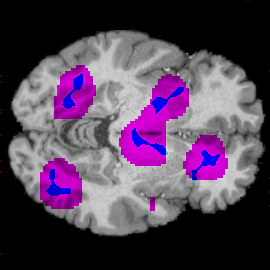
What can we explain?
ECG Segmentations
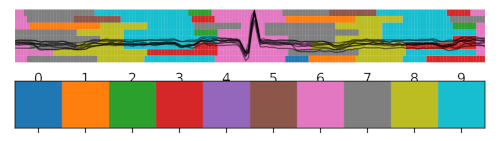
Summary
Summary
Can we see what the model sees?
Does it capture semantics?
- Ease interpretation of saliency maps.
- AUC-LeRF is broken.
- Unsupervised evaluation of local explanations.
- Object Localization
- Model inspection
- etc.
What can we explain?
Yes
Yes
Explaining the Encoder with the Activations
Ahcène Boubekki
PTB, Germany
Samuel G Matthiesen
Sebastian Mair
Linkøping/DTU soon
Linkøping