From Clustering to
Deep Clustering
Ahcène Boubekki
UCPH, Denmark
Affinity-based Clustering















We cannot make everyone happy !
Problem:
Group super heroes
Objective:
Everyone is happy
Minimize unhappiness
Affinity-based Clustering
0.6
0.4
0.3
0.9
0.1
0.6
0.7
0.8
0.9
0.1
0.4
0.2
0.1
0.9
0.1
0.2
0.3
0.7
0.5
0.8
0.9
0.5
0.4
0.3
Memory
expensive
How many
groups?
Where should we cut the graph?
✂
Affinity-based Clustering
Group together those that are clearly similar
Strategy:
and treat the rest as noise.
DBSCAN
Ester, Martin, et al. "A density-based algorithm for discovering clusters in large spatial databases with noise." kdd. Vol. 96. No. 34. 1996.
Affinity-based Clustering
Group together those that are clearly similar
Strategy:
Merge if one member is similar enough to one other member.
Until enough is not satisfied anymore.
Until 3 clusters are formed.
Agglomerative Clustering
Single-linkage
Different merging strategy,
different linkage
still queries the Affinity matrix
(N×N)
Affinity-based Clustering
Remarks:
Which similarity measure?
Euclidean distance is easy
Not always cluster vectors
Cost of the
affinity matrix
Compute over mini-batches
Might repeat computations
Objects don't move!
The decision borders move
Let's make the objects move!
Affinity-based Clustering
Euclidean distance is easy
Compute over mini-batches
Let's make the objects move!
Euclidean distance is easy
Compute over mini-batches
Let's make the objects move!
color
shape
What are we actually doing?
We learn a similarity measure
We learn a Kernel!
Feature map
Euclidean
Unknown
How do we guide the learning?
Affinity-based Deep Clustering
Let be a dataset that we want to cluster using a feature map .
We want that in the embedding space:
- similar objects are close to each other,
- dissimilar ones are far from each other.
For each datapoint , we have a set of positive examples
and of negative ones .
Triplet Loss
How do we get these sets?
Euclidean norm not good in practice
InfoNCE
Contrastive Learning
Augmentations are pulled closer
Other instances are pushed away
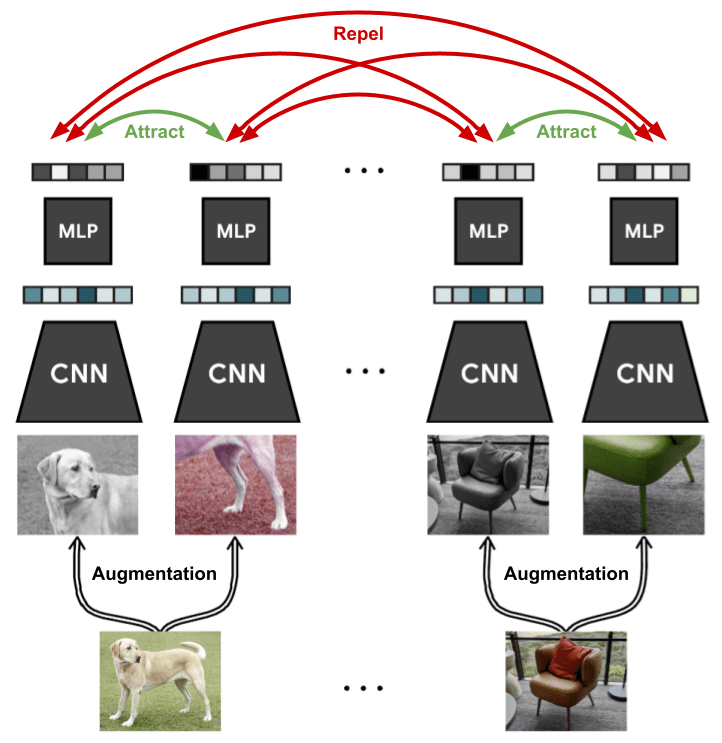


Centroid-based Clustering
Choose three representatives.
Strategy:
Group by similarity.
Update the representatives.
Continue until convergence.
k-Medoids
Can we learn k-means with a neural network?
If the representatives are not necessarily instances
k-means

From Clustering to
Deep Clustering
Ahcène Boubekki
UCPH, Denmark