Open Journal Systems, DOIs, and DataCite
A Webinar from the Public Knowledge Project (PKP) and DataCite.
Mike Nason
Open Scholarship & Publishing Librarian @ UNB Libraries
Open Scholarly Infrastructure Advisor @ Public Knowledge Project (PKP)


A Brief Intro to PKP
About PKP
PKP is a software development and research facility at Simon Fraser University.
- We conduct research into issues impacting scholarly communication.
- We develop free and open source software (FOSS) towards a more diverse, inclusive, and accessible model for scholarly publishing.

Our Mission
Since 1998, PKP's mission has been to research, develop, and support open infrastructure to increase the quality, diversity, and reach of scholarly publishing.
Our Software
The Public Knowledge Project develops open source software which is used around the world for scholar-led, community driven publishing of journals, preprints, and monographs.



Global use of OJS
- 55,000+ active journals world-wide
- publishing across 150 countries
- journals publishing in 60 languages
PKP is best known for the development of OJS – the world's most widely used journal management and publishing system.
OJS for Authors
A system for authors to submit to a scholarly journal, track their submission through the editorial process, upload revisions, and publish, often open access.
OJS for Editors
A system for editors to manage submissions at different stages, track manuscript versions, and manage comms between authors, editors, and reviewers.
OJS for Reviewers
A system for reviewers to accept or decline peer review requests, see submissions, communicate with editors, and submit peer review materials.
OJS for Researchers
A customizable, multilingual publication website with built-in indexing, dissemination, and preservation tools.

A Global Community
PKP software is developed, maintained, and sustained by a global community of developers, users, translators, financial contributors, and strategic partners.
Support & Resources
PKP Provides resources to help our software users build their knowledge and enhance their scholarly publishing practices.
- Detailed documentation for administrators, managers, editors, and more @ https://docs.pkp.sfu.ca
-
A Community Forum where users engage with colleagues around the world, ask and answer questions, request features, and share ideas
@ https://forum.pkp.sfu.ca


Support & Resources
PKP has builds and maintains PKP School, a set of online, open, self-paced courses designed to help improve the quality of scholarly publishing around the world.

Let's Talk OJS
Open Journal Systems
Out of the box, Open Journal Systems is hugely supportive of open scholarly infrastructure. In fact, OJS is an example of open scholarly infrastructure.
Things will vary a bit depending on the version of OJS you're running. If you're leveraging PIDs and other connections to open infrastructure, it's likely best to stay updated to, at least, the latest Long Term Support (LTS) version.
Versions // General
OJS 3.3.X // (LTS)
MOST RECENT LTS VERSION
LARGE INSTALL BASE
BIG SELECTION OF 3RD PARTY PLUGINS
DOI DEPOSIT BY PLUGIN
WILL BE FLAGGED FOR EOL WITHIN A YEAR AFTER OJS 3.5 GETS LTS DISIGNATION
OJS 3.5
MOST RECENT RELEASE
WILL BE THE NEXT LTS
SIGNIFICANT IMPROVEMENT TO PUBLISHING WORKFLOW
SIGNIFICANT UI IMPROVEMENTS
OJS 3.4.X
BROUGHT A NUMBER OF CHANGES TO STATISTICS, USER MANAGEMENT, AND SUBMISSION WORKFLOWS
MORE ITERATIVE FEATURES
DOI MANAGEMENT/DEPOSIT WORKFLOWS OVERHAULED
OJS 3.4.X
BROUGHT A NUMBER OF CHANGES TO STATISTICS, USER MANAGEMENT, AND SUBMISSION WORKFLOWS
MORE ITERATIVE FEATURES
DOI MANAGEMENT/DEPOSIT WORKFLOWS OVERHAULED
Versions // Pid-ciderations
OJS 3.3.X // (LTS)
DOI MANAGEMENT TIED TO REGISTRATION AGENCY PLUGINS
ROR SUPPORT
ORCID SUPPORT
OJS 3.5
LEVERAGES NEW DOI MANAGEMENT FROM 3.4
IMPROVED ROR INTEGRATION
IMPROVED ORCID INTEGRATION
UPDATES TO PID METADATA SCHEMAS FOR BETTER METADATA FIDELITY
OJS 3.4.X
DOI MANAGEMENT MOVED TO CORE CODE AND OVERHAULED
NO ROR SUPPORT
ORCID SUPPORT
What version should I use?
At an absolute minimum, I'd recommend running the latest version of OJS 3.3.X to make sure you've got all the latest patches and security updates. Staying up to date on the LTS version is good practice and will help ensure a stable, secure platform for your journal.
That depends! Your experience with the software will be different depending on the version you have installed. Often, the tradeoff for newer versions of a platform is that you get the best, newest features but also need to apply more frequent updates to keep things secure and bug-free.
Does it matter?
What version should I use?
However, if you're currently on a version of OJS 3.2 or older, it matters a great deal. You should definitely – at least – upgrade to the latest version of OJS 3.3.X.
OJS 3.2 is no longer supported and you'll be missing out on security updates and bug fixes.
Does it matter?
What version should I use?
If you're on 3.3.X and are happy with how things are, you can safely wait until OJS 3.5 gets it's long term support (LTS) designation before upgrading.
If you're on 3.4.x and are happy, you can also wait!
Once 3.5 gets LTS, you'll have ~ a year to upgrade from 3.3.X.
Does it matter?
What version should I use?
Do I need to upgrade?
Intro to DataCite...
Let's talk DOIs
Open Journal Systems
I'll also note that everything we'll be going over in this section can be found in more detail in the PKP docs hub or in the readme.txt files for any individual plugin in the plugin gallery.
- DOI Plugin
- Crossref Manual (DataCite works basically the same way, but a new DataCite-specific guide is also currently in development)
- ORCiD Plugin Guide
- ROR Plugin Guide
- ORCiD Profile Plugin
- QuickSubmit Plugin and DOIs
A quick word on installing plugins.
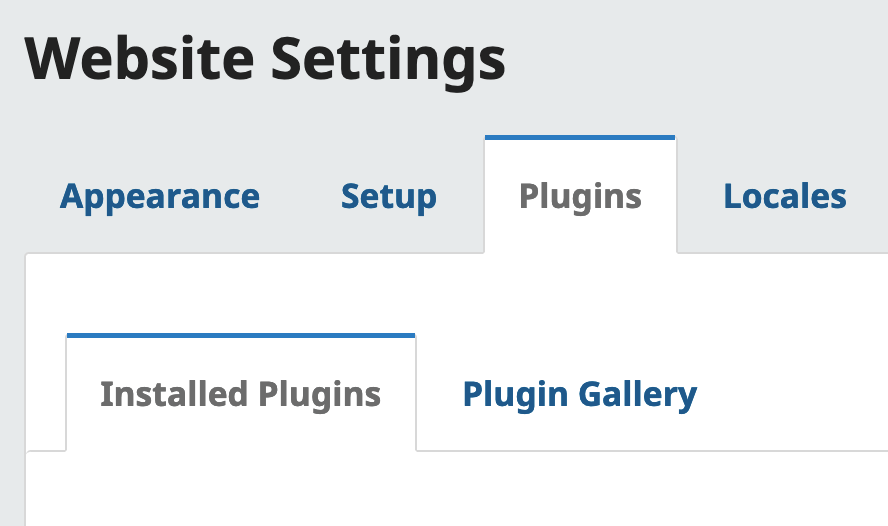
Plugins

You can view your plugins from the Dashboard by clicking on Website under the "Settings" header on the left sidebar.
The UI might look a little different, but these steps are the same in 3.3 and 3.5.
Plugins
You can view your plugins from the Dashboard by clicking on Website under the "Settings" header on the left sidebar.
Then, on the main screen of the Dashboard, click the Plugins tab.
"Installed Plugins" shows you all the plugins installed by default or added for your journal. All other compatible plugins are viewable in the gallery.
Installing Plugins
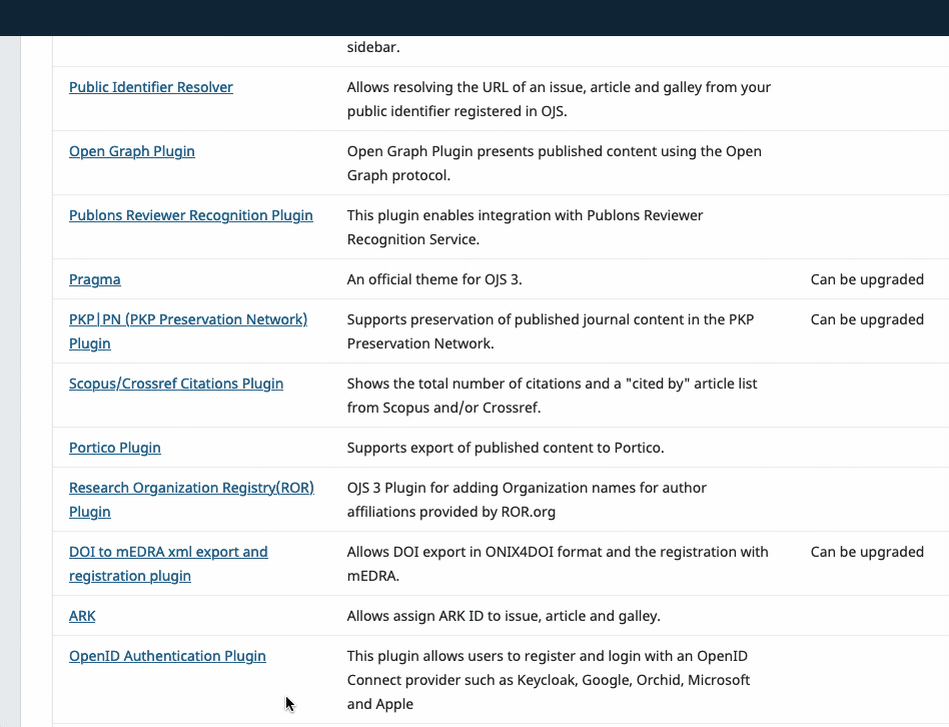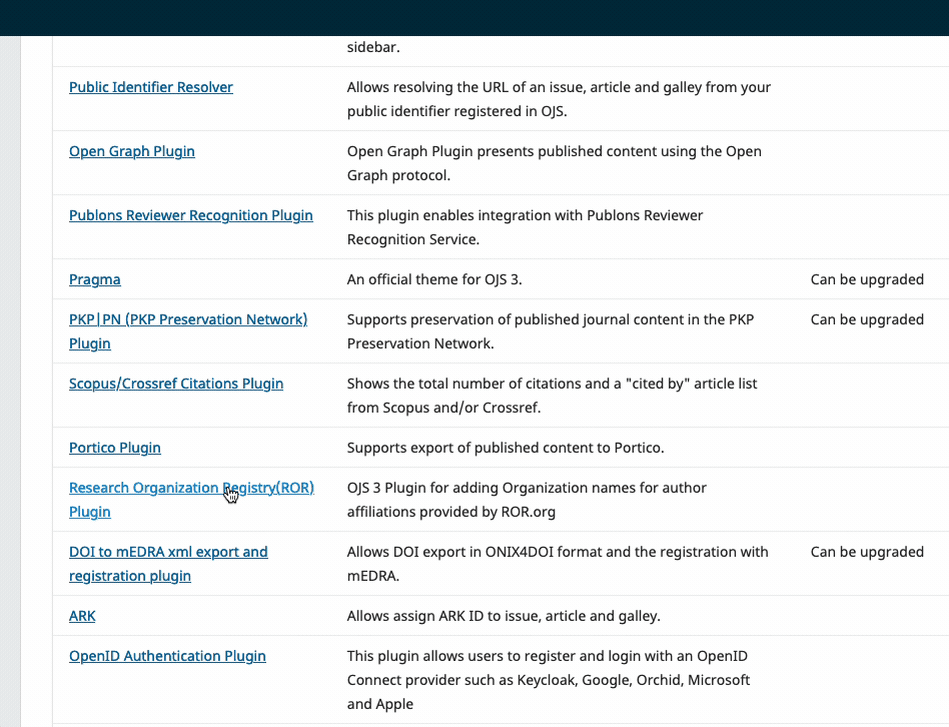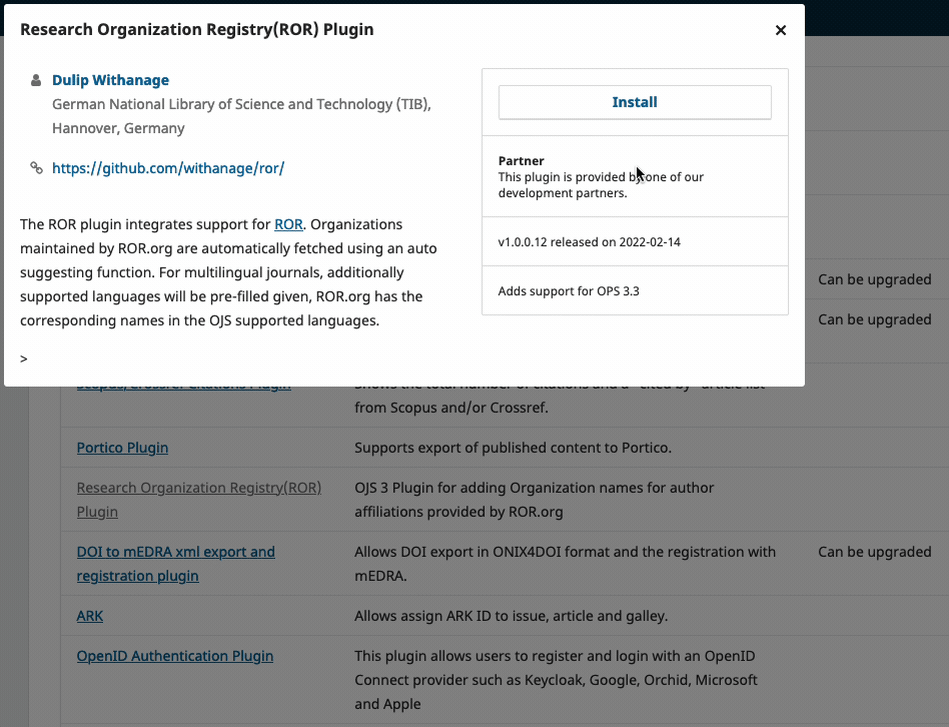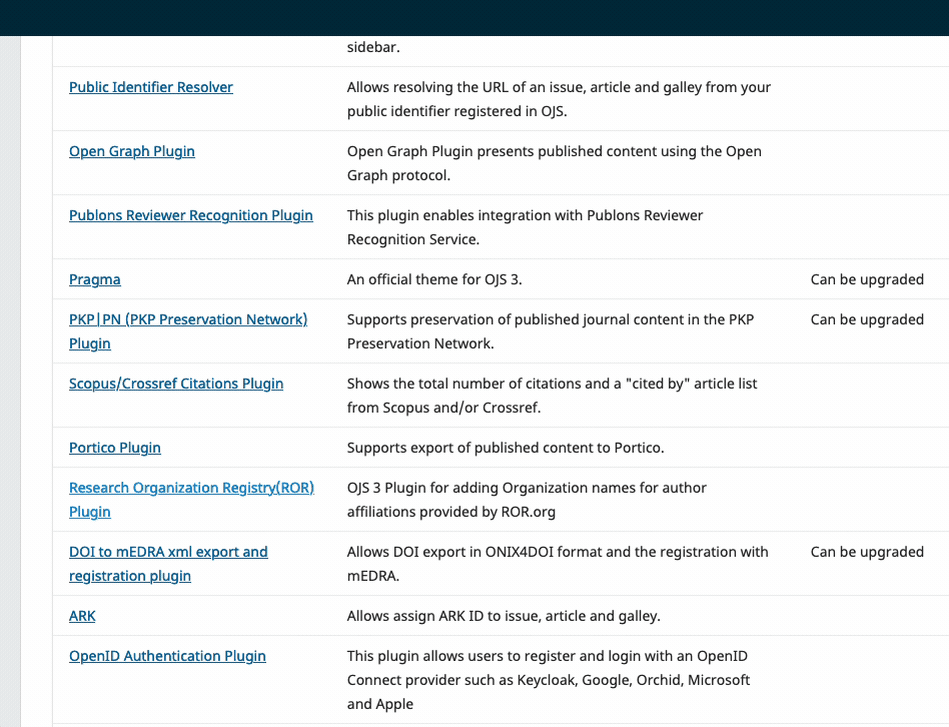
From the plugin gallery, click on the name of the plugin you want to install. This will open a window with information about the plugin (including the GitHub repo that houses the source code).
Clicking on the "install" button in the top right of this window will install the plugin.
Enabling Plugins
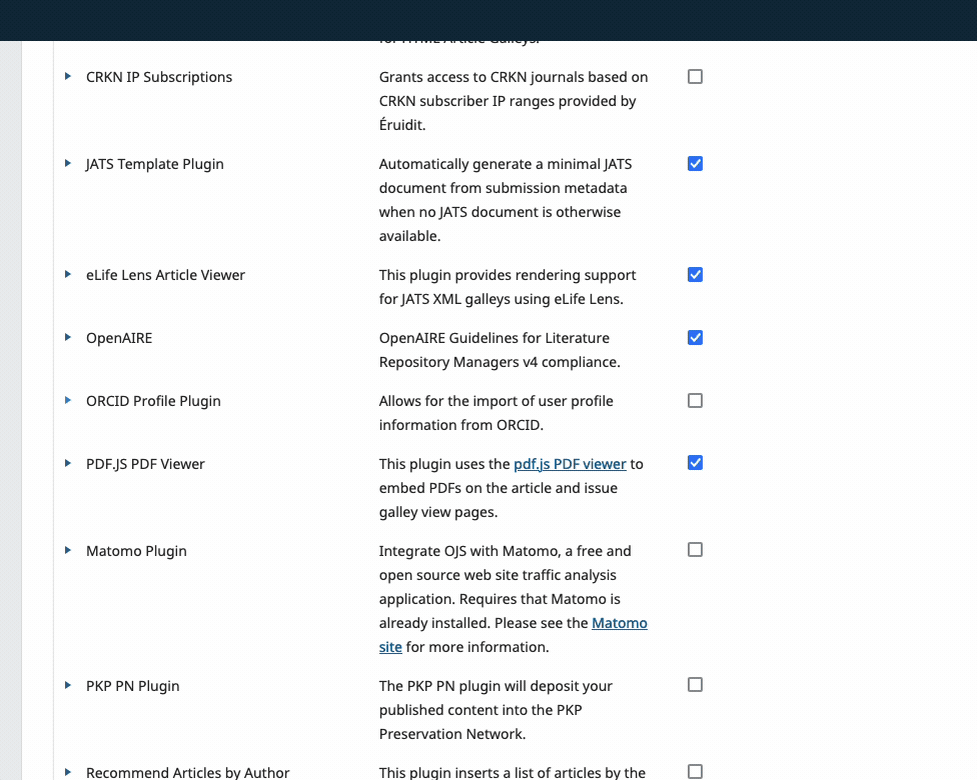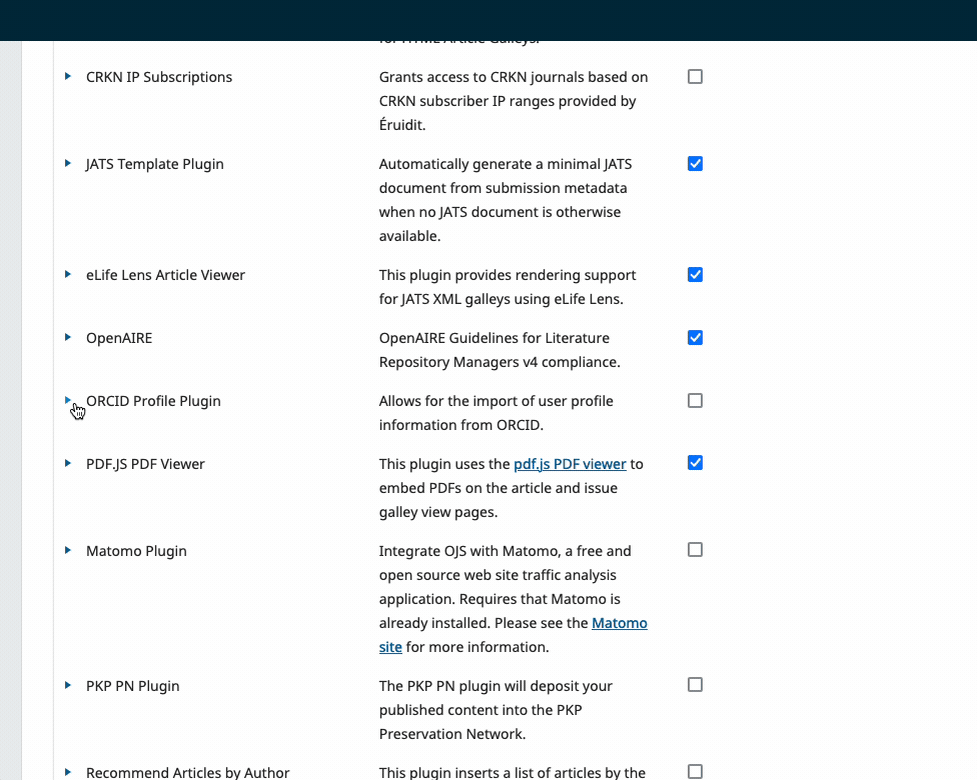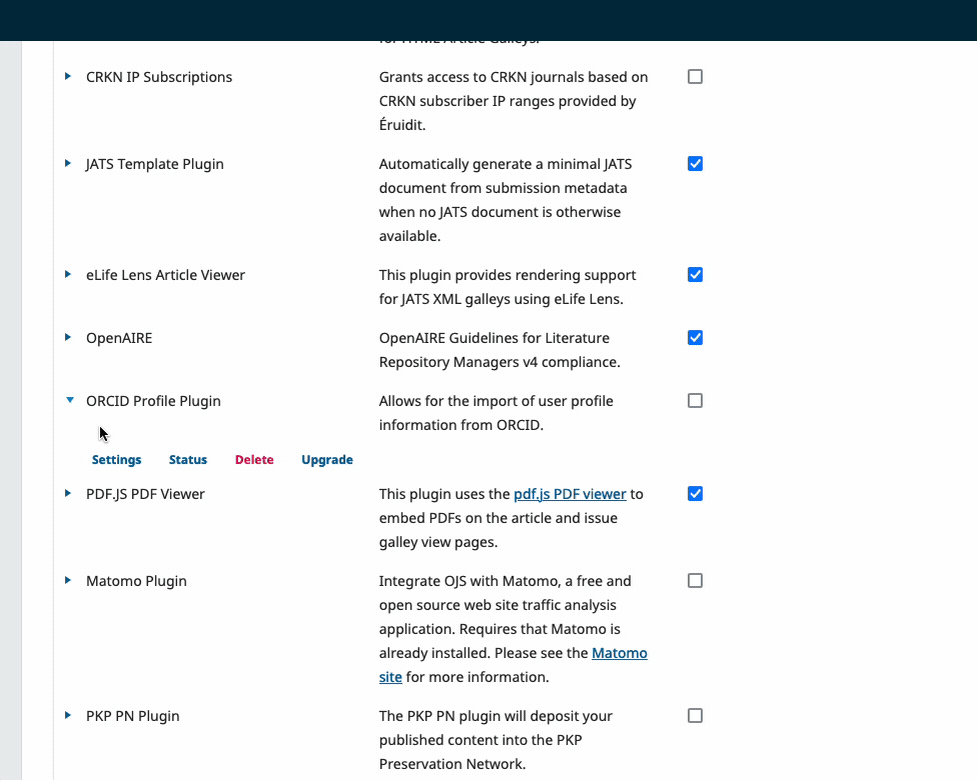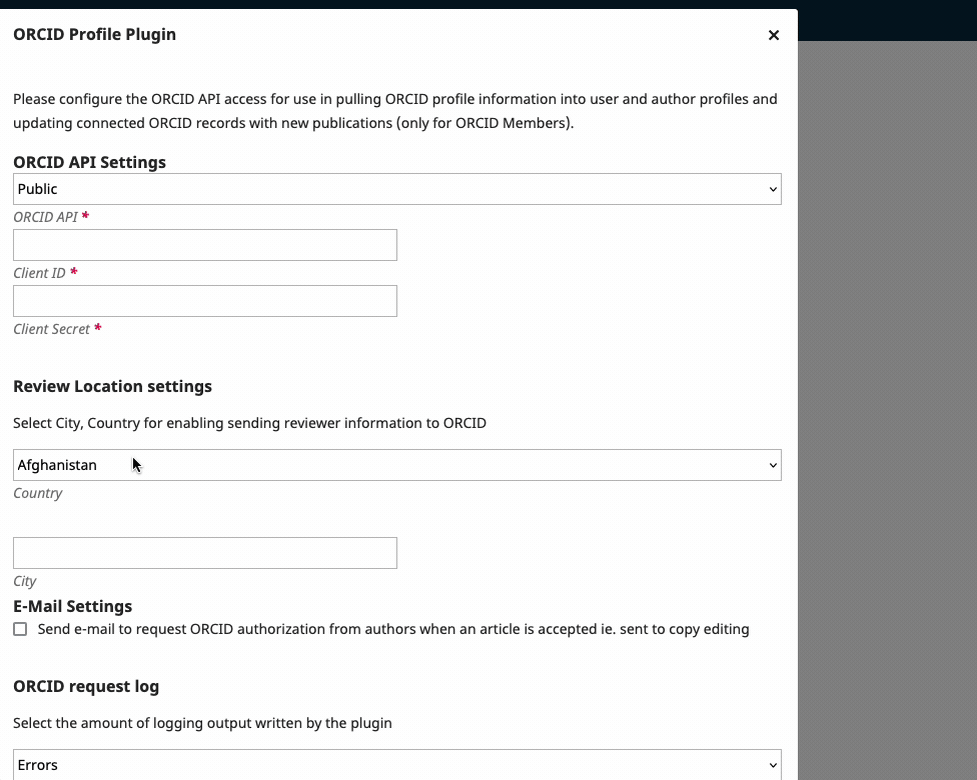
Once your plugins are installed, you can enable them from the "Installed Plugins" tab.
There's a checkbox on the right showing enabled status.
- grey checkboxes are default plugins you cannot disable
- blue checkboxes are enabled plugins
- empty boxes are disabled plugins

Plugin Settings
Some plugins have settings. To see your options for any individual plugin, click on the arrow to the left of the plugin name to expand.
You can also update plugins the same way.
Assigning DOIs
Assigning DOIs
A Gentle Reminder
Assigning DOIs and Registering DOIs with a Registration Agency are two different things.
People often combine these two steps together and call it "minting".
If you only assign a DOI but don't register it with a DOI registration agency, it will not work.
This is more common than you might imagine.
Assigning DOIs
In OJS 3.3.x
DOIs in OJS 3.3.x (LTS)
No matter which DOI registration agency you have a membership with, the process of assigning DOIs is the same.
In 3.3.x, you will need to start by configuring your DOI plugin. You can find the DOI plugin and it's settings under Installed Plugins and the sub-heading "Public Identifier Plugins".

DOIs in OJS 3.3.x (LTS)
There's a space to put your prefix here. You'll be given a prefix by your registration agency or by your parent organization/publisher.
You can also choose which things to assign DOIs to. You might be tempted to click all of them. I recommend just assigning DOIs to Articles.

DOIs in OJS 3.3.x (LTS)
Next, are the suffixes. I more or less beg you to not think of these as meaning anything to readers or users. A DOI suffix shouldn't contain metadata. They ought to be opaque.
I recommend either using the default patterns here and just ignoring what they say, or creating a custom pattern with the bottom option that is even more simple than the default.

DOIs in OJS 3.3.x (LTS)
You cannot correct or change a DOI after it has been registered. If you register a DOI with a typo in it, that isn't a solvable problem.
You can edit registered metadata. You cannot edit the DOI itself.
Take typos right out of the equation!
%j.%a is a great custom option.
DOIs in OJS 3.3.x (LTS)
These are the final two options. They should be treated with caution.
Reassign DOIs will unassign all DOIs for your journal and reassign DOIs based on whatever your prefix settings are. If you've registered anything, do not click this.
Assign DOIs will assign a DOI to anything in your journal that does not already have one.

DOIs in OJS 3.3.x (LTS)
Lastly, you can make sure a DOI will be assigned at the article level. In the Publication tab for any submission, you can click on "Identifiers" in the sidebar and see DOI information.
You'll see an "assign" button to automatically generate a DOI based on your prefix settings. You can modify a DOI here until it is published.
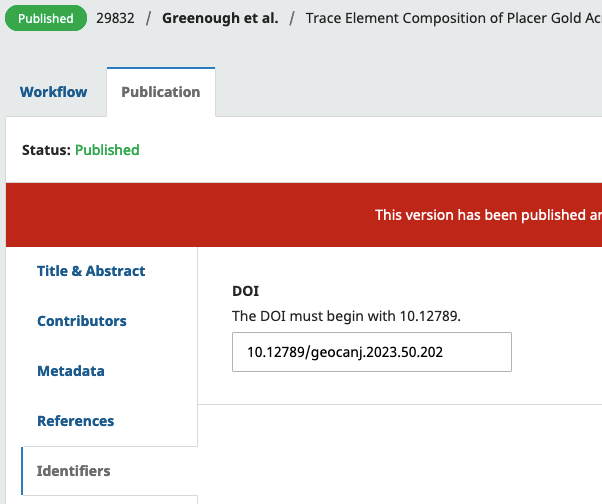
Assigning DOIs
In OJS 3.4.x - 3.5.x
DOIs in OJS 3.4.x - 3.5.x
No matter which DOI registration agency you have a membership with, the process of assigning DOIs is the same.
In 3.4.x and 3.5.x, you will need to start by configuring your DOI plugin. You can find the DOI plugin and it's settings under Installed Plugins and the sub-heading "Public Identifier Plugins".
You will also need to enable the plugin for the registration agency to which you are a member.

DOIs in OJS 3.4.x - 3.5.x
DOIs in OJS 3.4.x - 3.5.x
You can find your DOI settings from the plugin page, or you can navigate to Distribution > DOIs.
Let's discuss the settings.
On the left, you can see here the Registration tab, which is where you'll select your registration agency, toggle automatic deposit on/off, fill in user credentials, and can also access testing tools if necessary.
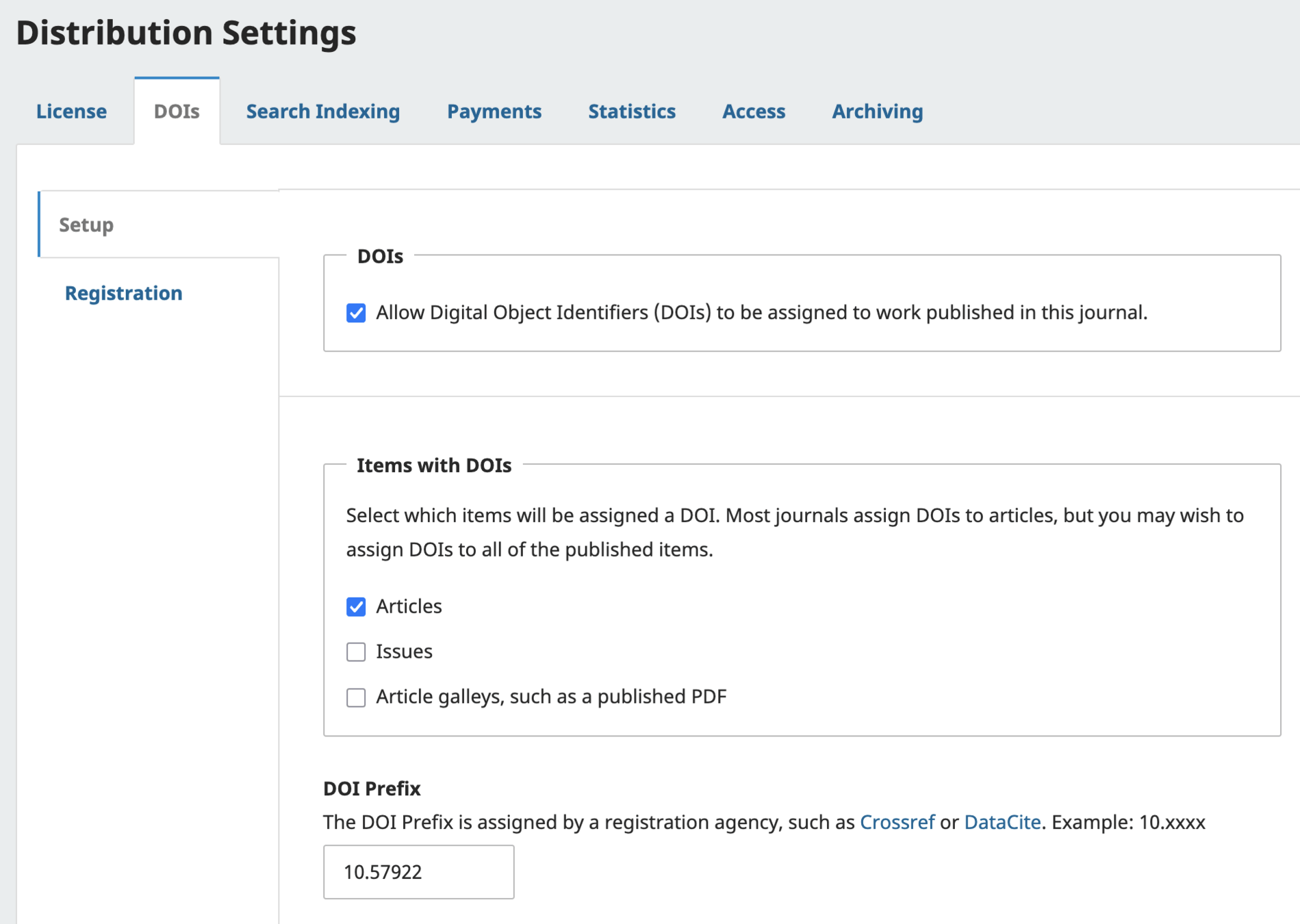
DOIs in OJS 3.4.x - 3.5.x
The other settings here include:
- DOI Assignment Toggle
- DOI Assignment per item type
- DOI Prefix
-
When a DOI is assigned to a work...
- at copyediting
- on publication
- never (for manual DOIs)
DOIs in OJS 3.4.x - 3.5.x
New to 3.4 and 3.5 is a feature for automatically generated, opaque DOIs based on a unique eight-character suffix. It's very much encouraged to use this new feature to save yourself pattern-based suffix issues.
You can also still highlight either manual suffix creation or custom patterns like you could in 3.3.x.
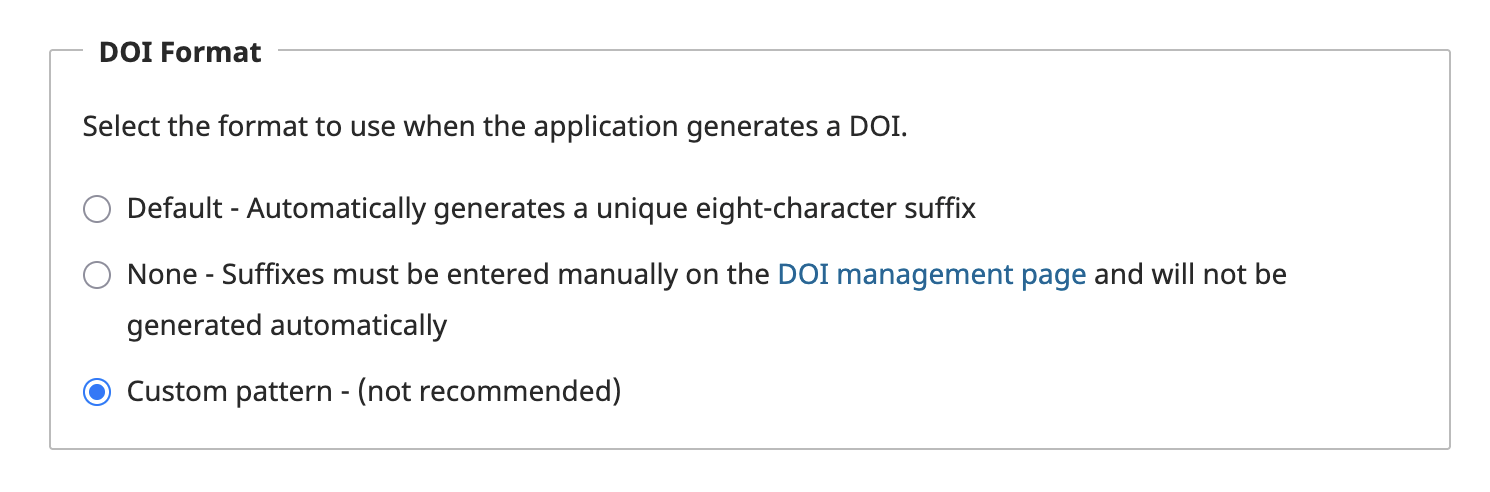
DOIs in OJS 3.4.X - 3.5.X
In OJS 3.4 and up, DOI management has been overhauled.
You can now find your DOI plugin settings in the left sidebar under the option Distribution.
You can set your prefixes, suffix patterns (now with opaque string generation), as well as choose your registration agency from a dropdown menu.

Registering DOIs
In OJS 3.3.x
In 3.3.x, you can find the registration options in the left sidebar of the dashboard, at the bottom, by clicking on the Tools link.
From here, choose either the Crossref or DataCite Export/Registration plugins.
They both operate very similarly!
DOIs in OJS 3.3.X (LTS)
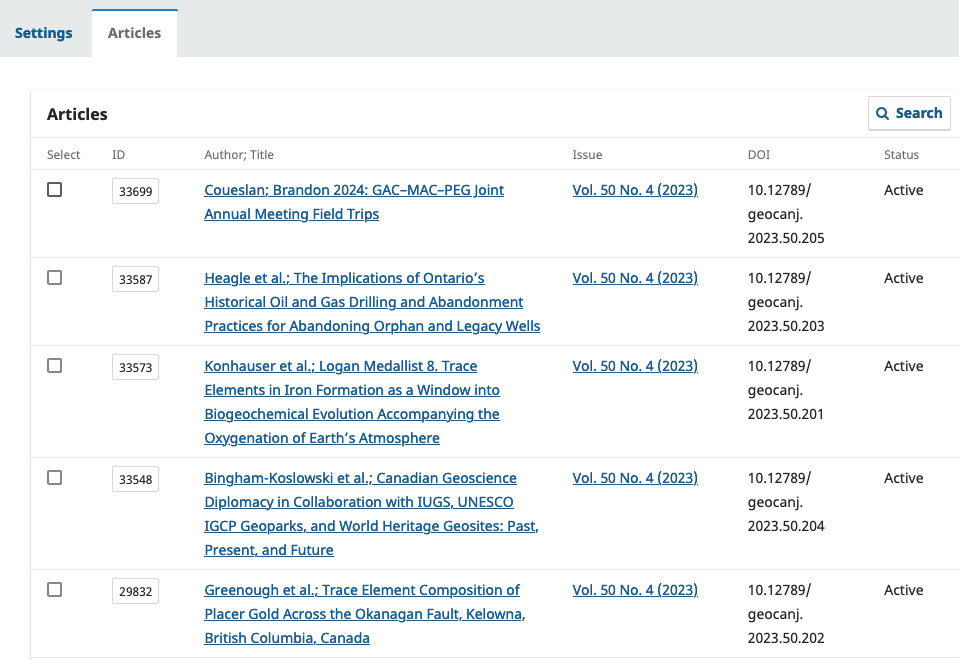
Each plugin starts with a settings page with a few options and your credentials for your membership. These credentials will always be your login credentials for DataCite or Crossref, not for this OJS install.
DOIs in OJS 3.3.X (LTS)
Each plugin has the same registration menu under the tab labelled "Articles". It shows you the article ID, author/title, issue, DOI to be registered, and a status.
"Active" means a DOI has been registered and is resolving.
If your plugin is set to automatic, you can basically ignore this. It will register for you within a few hours.
DOIs in OJS 3.3.X (LTS)
Registering DOIs
In OJS 3.4.x - 3.5.x
In OJS 3.4, all DOI management and registration can be accessed from the DOIs menu on the sidebar, in the top left.
DOIs in OJS 3.4.x

In OJS 3.5, all DOI management and registration can be accessed from the DOIs menu on the sidebar, below "Issues" and before "Settings" menus.
DOIs in OJS 3.5.x
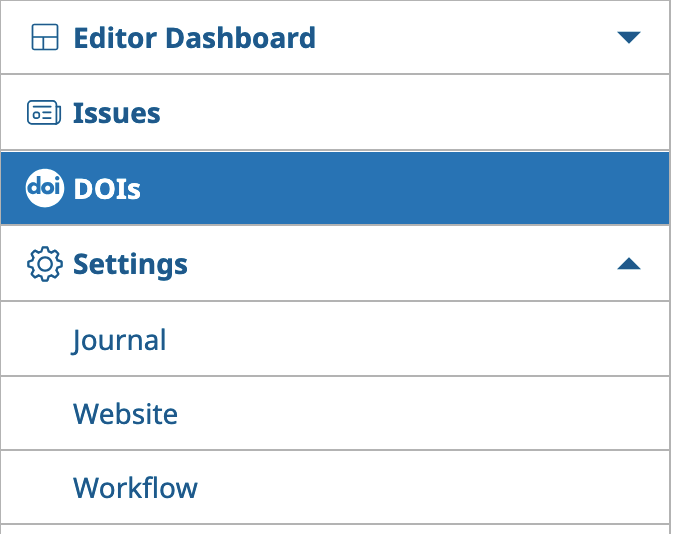
This DOI manager has significantly more features, including flags for DOIs that need updating (when their metadata has changed). You can also assign DOIs per article here if you wish, without having to navigate to an individual publication.
You can also cue up bulk updates or bulk registrations.
DOIs in OJS 3.4.X - 3.5.X
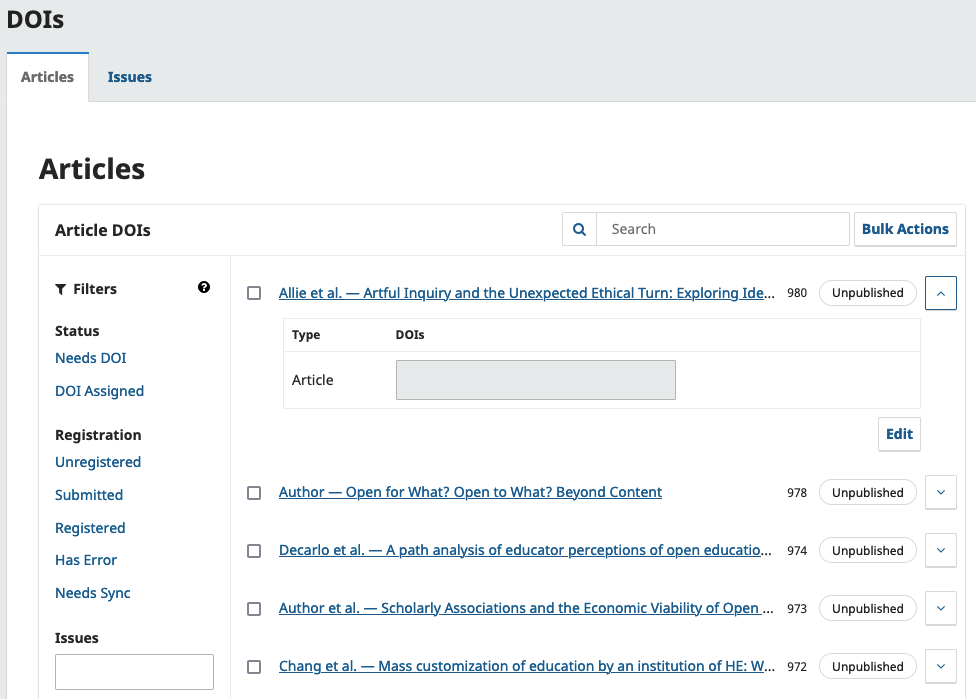
You can see that the plugin assigns labels like "needs doi" for works that have yet to be assigned one.
You can also see the operations available as bulk actions.
DOIs in OJS 3.4.X - 3.5.X
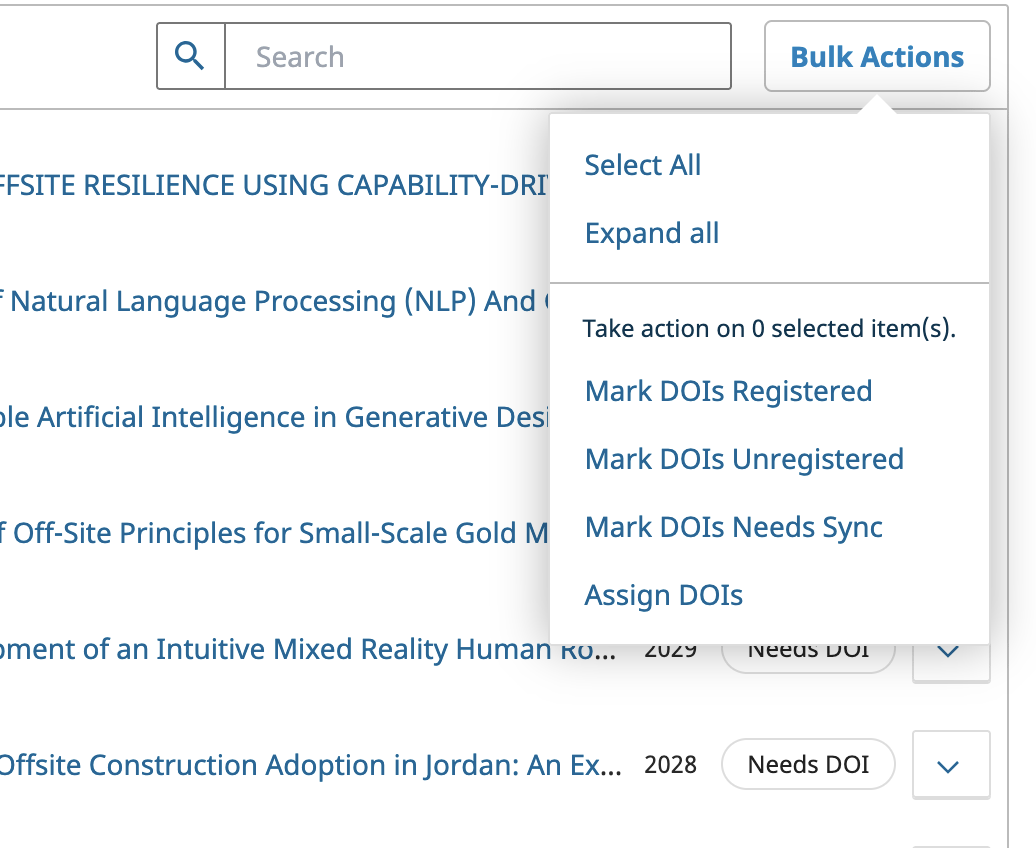
Bulk Actions is where you'll be doing manual assignment and registration if you need to. You can check the box for as many records as you need, and then select the relevant bulk action.
You'll also see information telling you if a record has been modified since the last registration, prompting you to push your updated metadata to your registration agency.
DOIs in OJS 3.4.X - 3.5.X
Please remember to update your DOI registration after you make metadata changes!
Other PIDs & OJS
ROR
ROR in OJS 3.3.X (LTS)
You can find the ROR plugin in the gallery with the name: Research Organization Registry (ROR) Plugin.
This plugin will allow for autocomplete against the ROR API within the "affiliation" metadata element for submissions.
It will also display ROR links on article landing pages.
- Navigate to the plugin gallery and install the ROR plugin.
- Navigate to your installed plugins and enable the ROR plugin.
End of list!
Currently, in 3.3.x, ROR metadata is only added to DataCite deposits.
ROR in OJS 3.4.X
Unfortunately, the ROR plugin has yet to be ported to OJS 3.4.
ROR in OJS 3.5.X
You can find the ROR plugin in the gallery with the name: Research Organization Registry (ROR) Plugin.
This plugin will allow for autocomplete against the ROR API within the "affiliation" metadata element for submissions.
It will also display ROR links on article landing pages.
- Navigate to the plugin gallery and install the ROR plugin.
- Navigate to your installed plugins and enable the ROR plugin.
End of list! ROR is also in the process of being integrated into the Funding Metadata plugin.
ORCID
ORCiD has two different APIs.
Public API
ORCiD's public API allows any journal to pull public metadata from ORCiD. In OJS, the public API option fascilitates:
- Authors can connect their ORCiD ID with their publications.
- ORCiDs recorded as metadata will be deposited in DOI registrations with Crossref and Datacite.
- Author ORCiDs will be linked on article landing pages.
ORCiD's member API allows journals to push metadata to ORCiD. The member API allows for all of the capability of the public, and also:
- Peer-review activity can be pushed to author's ORCiD profile.
- Article records can be pushed directly to ORCiD profiles.
Member API
It is totally fine to use the public API, and you'll still get a significant interaction with ORCiD this way.
The most important piece for authors here is the link to their profile. If you're using DOIs and profiles are configured for automatic addition, works will still be added to their ORCiD automatically.
The member API's strongest asset is the ability to push peer review work to ORCiD.
Memberships to ORCiD tend to be institutional and aren't cheap. If you aren't concerned about automatic population of peer-review work to ORCiD, the public API will meet your needs plenty.
In the Interest of Brevity
I recommend you read the ORCiD plugin documentation.
The plugin is pretty straightforward to set up if you are a single journal.
However, if you are installing on a shared, multi-journal instance of OJS you will need access to your config file. You may require technical assistance for this, depending on your comfort level.
https://docs.pkp.sfu.ca/orcid/
You'll need an ORCiD account and will need to procure at least a public API key (this is free). Of the three PID integrations, this one has the most steps.
It is, however, very much worth the time to support your authors!
Bonus Round
I finished this deck and started thinking about, like... you know all of this documentation exists, and now you have these slides, and maybe I don't need to go clean through it all step-by-step. Or, maybe I've just gone through it all step-by-step and would like to leave you with something to think about on your own steam.
Forgive me...
...for being presumptive, but there is a general expectation that you want people to see the products of your hard work.
You want your work to be known and discoverable; accessible to the folks who might benefit from it.
I would think (hope).
And, you'd probably like it to be attributed to you, since you did the work and also since the implications of its value will have some impact on your career or the career of your authors.
It's possible...
this may seem weird because, depending on where you are in your career, you are maybe not used to doing this.
After all, most of the experience of dissemination as a student (for example) is submitting papers to one person who grades them.
It is certainly fine if this is the case. It's very normal. Fun fact, plenty of established researchers don't really think too hard about where and how their work is shared, either.
For students, this is what "disseminating your research" mostly looks like.
https://science.gc.ca/site/science/en/open-science
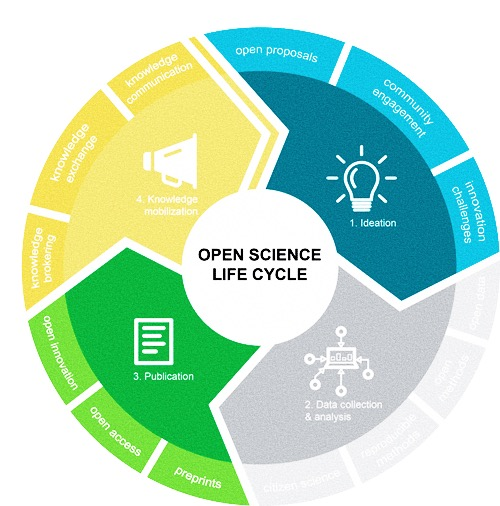
Submitting your work as a modern academic kicks off an enormous Rube Goldberg machine of scholarly publishing infrastructure. We're talking data, articles, preprints, presentations, proceedings, and countless other things.
Your work is going to end up in a lot of places, often without you even really being aware of it.
Where do the products of research go?
The Perception
I suspect a lot of folks don't really think too much about how publishing works. Generally, we know a few things happen.
Let's say I'm talking to researchers.
- you submit articles to a journal
- articles undergo peer review
- works are published
- the people who want to read those works can read them
- things will get cited
- number of citations is very important
- number of citations is directly correlated with where you publish
- OA might be required, somehow
The Perception
This isn't wrong, per se, but it's definitely not the whole story.
- you submit articles to a journal
- articles undergo peer review
- works are published
- the people who want to read those works can read them
- things will get cited
- number of citations is very important
- number of citations is directly correlated with where you publish
- OA might be required, somehow
journal
vor

peer-review
Every is, potentially, a new DOI.
journal
am
ir datacite
vor
peer-review
self-archiving
Every is, potentially, a new DOI.
The Reality
Publishing is more iterative (and tied to a wider range of accessible outputs) than it's ever been.
- submission still happens, but users might post their work on a preprint server before peer review
- a funder mandate might require open access or, at least, an open access version of the work
- if you're publishing in a major subscription journal, lots of people cannot read your work
- data management might require publication of a data set
arxiv
ir datacite
webpage
journal
ir crossref
ir handle
preprint
am
ir
pubmed
ir datacite
zenodo
dataset
vor
shareyourpaper
openaire
zenodo
dataverse
Every is, potentially, a new DOI.
THESE ARE ALL PLACES YOUR METADATA CAN/WILL GO!
If you jam, "Editors, The" into the name field for something that doesn't have an actual author, guess where that will end up?
If you manage a journal, you are standing at the nozzle of a metadata firehose.
This is important stuff for both a journal and for authors.
Authors will know what they worked on, for example, but people (researchers, funders, institutions, employers) looking for their work might not.
Maybe they share a name with another researcher and their results are always co-mingled. Or their field only uses first name initials in metadata.
Or, maybe they changed their name for any number of incredibly valid reasons and it's painful or unpleasant that all their old publications require others to know it.
Unless your name is wildly unique, accurate and/or reliable attribution can definitely be a problem.
Citation styles like APA are not equipped to deal with the varieties in both human identity and how modern research is shared.
Even this
required a student id number.