Building an analytics database
on a dime

{kind=link}
Your Host Tonight

Lucía: Daddy, 2014
Alex Fernández
Chief Senior Data Scientist at MediaSmart Mobile
What we will cover
- Our Mission
- Back to SQL
- Aggregation and Accumulation
- Our Next Challenge
- Analytical DBs are hard
What We Do
Serve Mobile Ads
Real Time Bidding (RTB)
Performance campaigns
85 K+ requests / second
10 M+ impressions / day
40+ servers
20+ countries
Guilty!

Image source: Stupid Zombies 2
We help pay for your entertainment
Taming Big Data
How big is "big data"?
Check
Inventory
3+ MM bid offers per day
About 100 MM per month
Ask simple questions
On a budget!
We are a startup
our mission
 Sassetta: Freeing the Poor from a Prison, c 1440
Sassetta: Freeing the Poor from a Prison, c 1440Previous Attempts
Sent over RabbitMQ
Gobbled our systems
Stored in CouchBase
Too slow to query
Stored in Redis
Too much information
Requirements
Visualize one month inventory
Run most queries in < 1 sec
Development: a few weeks
Budget: < 1% of income
~ $1K / month budget
We Paid Close Attention
At BSD'13

Well, most of the time
What We Explored
MetaMarkets
Hadoop
Cassandra
Amazon RedShift
Google BigQuery
Amazon Kinesis
Amazon Data Pipeline
Amazon RedShift
Columnar database
"Petabyte-scale"
Cheap! All you can eat!
160 GB SSD: $700 / month
PostgreSQL Interface
Redshift peculiarities
Full scans are not evil anymore!
but the usual way of access
Constant look-up times
1 second per 4 M values per node
Does not cache subqueries well
Back to SQL

Goya: Interior of a Prison, 1793
Our Data Structure
region
day
hour
ad size
language
country code
operating system
...
Raw data
3 MM events / day
Each event characterized by 24 fields
Each field can take 2~20 values
Can simply count events with fields
Table Design: Star
Recommended by Amazon
Type tables, main data with foreign keys
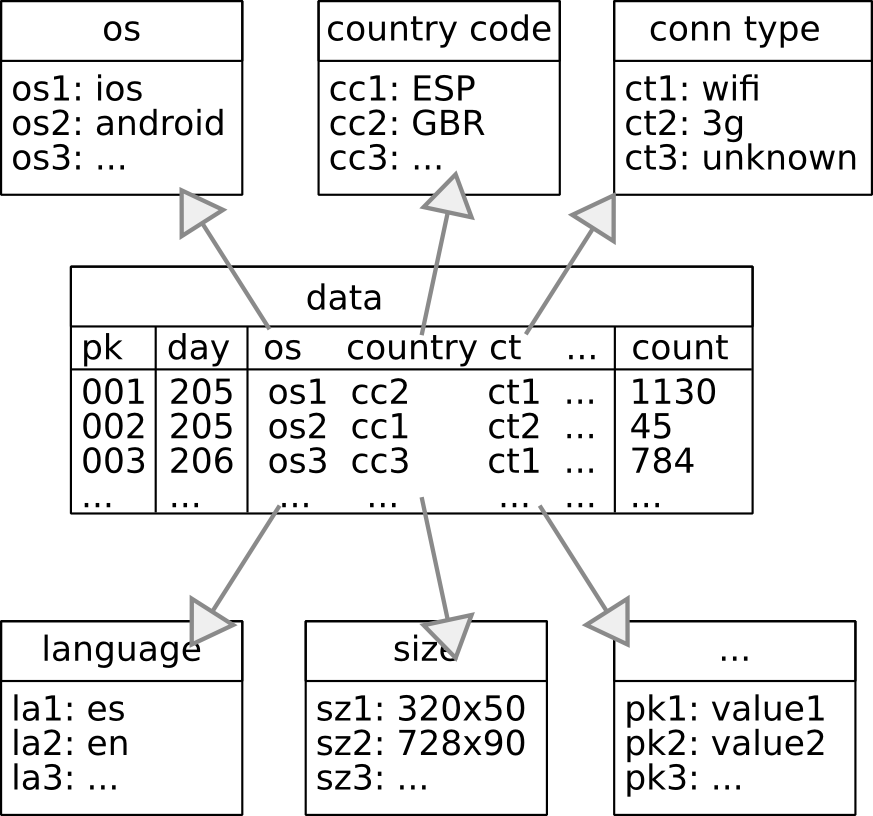
Data loading becomes very hard
Table Design: Refs
Each combination of values is stored only once
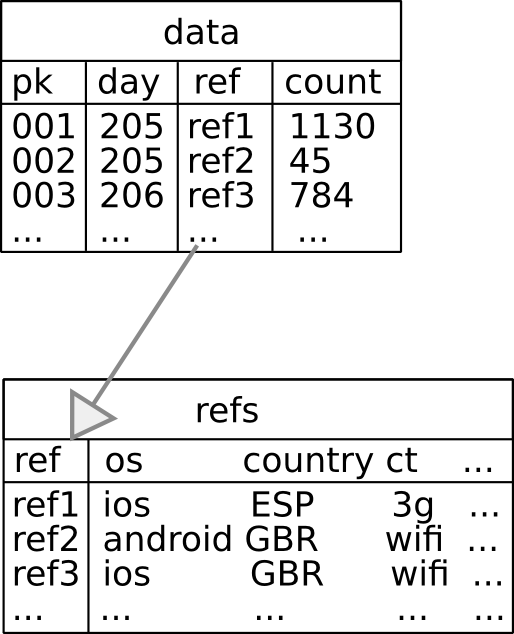
Takes ~half the space, > 2x the querying time
Several refs: hits a bottleneck
Table Design: Flat
Data lines are loaded as is

Very simple code
Easy loading, no foreign keys
Redshift behaves surprisingly well
Aggregation
and accumulation

Wright: An Experiment on a Bird in an Air Pump, 1678
Aggregation
Group events by fields
Pure exponential:
-
2 values/field: 2 24 ~ 16 M refs
-
3 values/field: 3 24 ~ 282 MM refs
Actual values:
Hourly: ~200M events → ~2M refs
Daily: 3.5 MM events → 8M refs
Unique / total
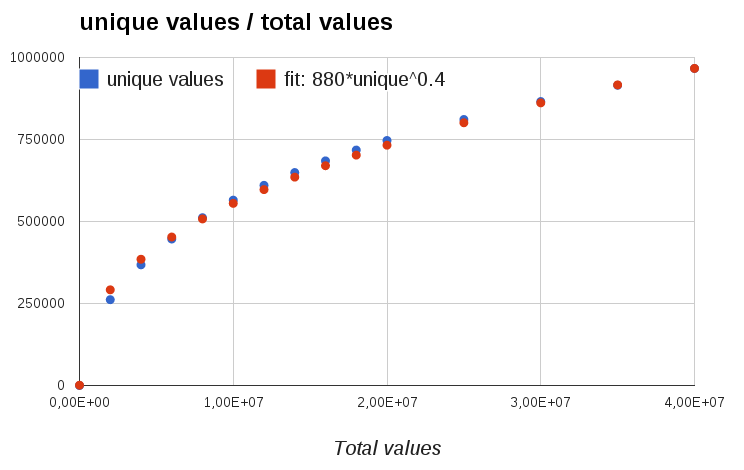
That is convenient!
Exponential fit
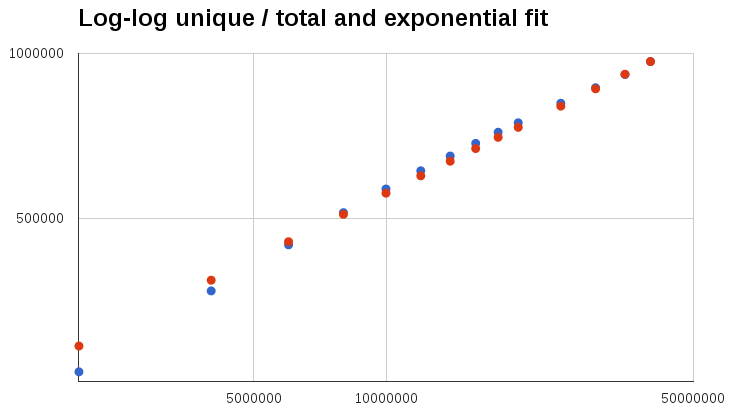
Close, but no cigar
generalized coupon collector problem
Thanks to an answer on
Cross Validated
There are many possible values
with different frequencies
Normal distribution?
Quite a few papers about it
None that clarify our case
Fast Path: six fields
Initially visible fields
Accumulated on their own
A whole day → 20K values!
A new accumulation process
What It Looks Like
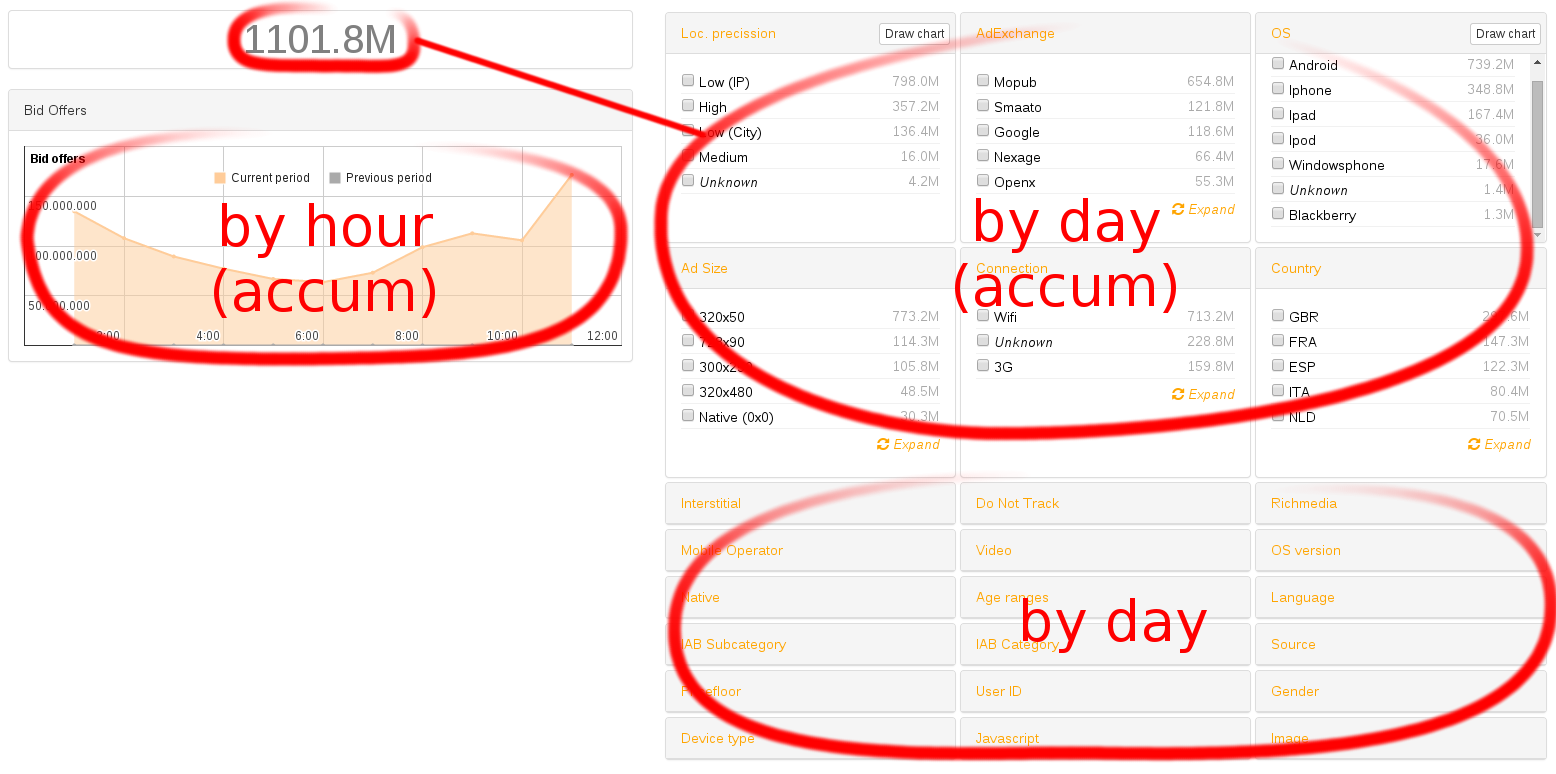
Three/four different tables per view
Demo
Bids in real time:
Inventory analysis:
Our Next Challenge
Bidding Data
Less events (10~60 M / day)
Additional fields (50% more)
Does not aggregate as nicely
Challenge Accepted

Leutze: Westward the Course of Empire Takes Its Way, 1861
Bidding Data Issues
24 + 12 fields
Many values to accumulate:
bids sent, bid price, bids won...
Actual aggregation values:
10 M → 2 M unique events
Analytical DBs: hard

Bosch: Garden of Earthly Delights, Hell, c 1480 (detail)
Gathering Requirements
We want MetaMarkets!
We want all possible fields,
just in case
All fields should go equally fast
Actual quotes from our users
Lots of Bits and Pieces
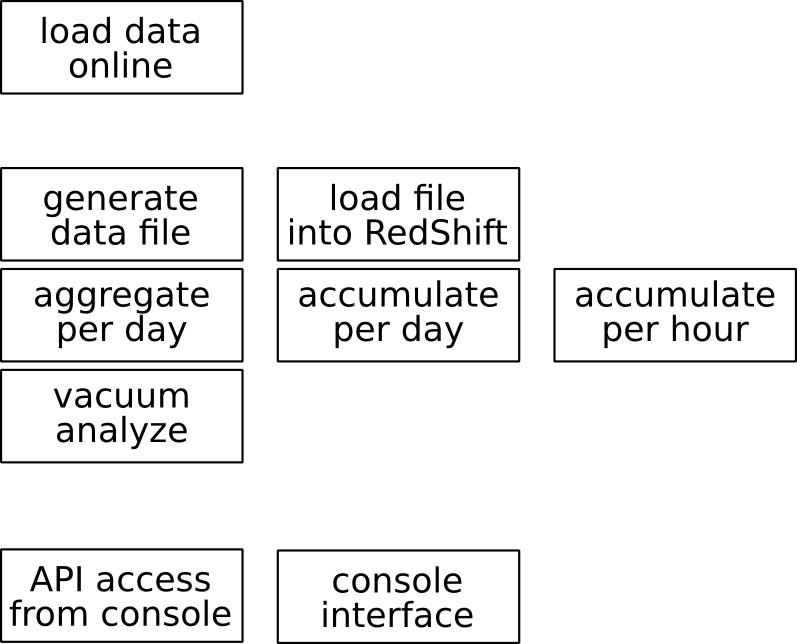
Amazon Data Pipeline: not so hot
Major Challenges
Big data is challenging
Near the operating limits of current tech
Performance should be key to user systems
Good engineering requires many iterations
Lessons Learned
Test everything
Aggregate everything
Build APIs to isolate systems
Deliver fast, iterate several times
Thanks!
