Pruebas de carga

Curso de escalabilidad v2, día 2
Programa
Uso de herramientas
Herramientas a medida
Variabilidad y percentiles
Leyes de Pareto y Amdahl
Incertidumbre y error
Uso de herramientas

Apache ab
Parte del paquete Apache
$ ab -n 1000 -c 10 http://service.pinchito.es:3000/a Opciones:
-
-n [N]: número total de peticiones -
-c [C]: concurrencia, número de hilos -
-t [T]: tiempo de prueba
wrk
Escrito por Will Glozer
Diseño multi-hilo
$ wrk -t10 -c400 -d30s http://service.pinchito.es:3000/a Opciones:
-
-t[T]: usa T hilos (threads) -
-c[C]: número de conexiones abiertas -
-d[D]: duración de la prueba (con unidades)
wrk2
Forqueado por Gil Tene
Añade una nueva opción
--rate o -R$ wrk -t10 -c400 -d30s --rate 2000 http://service.pinchito.es:3000/a
Opciones:
-
--rate [R]: tasa de peticiones por segundo -
--latency: muestra latencia con percentiles
Modos de carga
Modo "amable": espera a que termine una petición
antes de lanzar otra
Simula sistemas batch
Modo "agresivo": lanza R peticiones por segundo
incluso aunque no hayan terminado las anteriores
Simula sistemas online
Un servicio mal diseñado aguantará mucho menos
en el modo agresivo que en el amable

loadtest
Autor principal: vuestro humilde servidor
Contribuciones de 36 devs
Modo agresivo: --rps
$ loadtest -n 1000 -c 10 --rps 2000 --keepalive http://service.pinchito.es:3000/aOpciones:
-
-n N: número total de peticiones -
-c C: concurrencia -
-t T: tiempo en segundos -
--rps R: peticiones sostenidas por segundo
autocannon
Autor: Matteo Collina, miembro del TSC de Node.js
Inspirado por wrk, wrk2
Modo "agresivo": -R
$ autocannon -c 400 -d 10 -R 2000 http://service.pinchito.es:3000/aOpciones:
-c C: conexiones-d S: duración en segundos-R R: peticiones por segundoEjercicio: Pruebas de carga
Crea una instancia en AWS EC2
Región eu-west-3, Europe (Paris)
Tipo t2-small (o superior)
Imagen pinchito-loadtest-2020-11-08
Lanza pruebas contra http://service.pinchito.es:3000/a
Usa ab, wrk2, loadtest, autocannon
Comprueba si la frecuencia "natural" es la misma
⮯
Ejercicio +
Lanza pruebas de carga a tasa de RPS constante
$ autocannon -R [R] ...
$ loadtest --rps [R] ... Usa una tasa algo por encima y por debajo de la frecuencia natural
Comprueba si los resultados son consistentes
Si varían, ¿por qué lo hacen?
⮯
Ejercicio +
Ahora prueba contra http://service.pinchito.es:3000/d
¿Cambian los resultados?
¿Por qué?
⮯
You broke it!

Entornos de prueba

Herramientas a medida

¡Crea tu propio loadtester!
Lanza peticiones concurrentes http
Recoge las respuestas:
- 200: OK
- 204: sin respuesta
- 301: moved permanently
- 302: moved
- 4xx: bad request
- 5xx: server error
Modo amable: cada hilo envía peticiones seguidas

Proyecto lambda-loadtester
Autor: vuestro humilde servidor
Pruebas de AWS Lambda
Acumula promesas en un array
Lanza las promesas con la concurrencia pedida

Tasa de RPS fija
Modo agresivo: R peticiones por segundo
Una petición cada 1000/R milisegundos

Se puede usar por ejemplo setInterval() en Node.js
¿Qué pasa cuando 1000/R es una fracción?
Ejercicio: Diseña un temporizador
Modo "agresivo" de peticiones fijas
Primero intenta con una tasa redonda: 10 rps
Estudia cómo poner un intervalo
¿Qué pasa si una petición tarda demasiado?
¿Qué pasa cuando hay un retraso del sistema?
⮯
Ejercicio +
Ahora intenta que funcione con tasas fraccionales, e.g. 400 rps
¿Cómo gestionas fracciones de milisegundo?
⮯
Ejercicio +
Ahora piensa que tienes que lanzar más de 1000 rps
¿Se puede garantizar que la tasa sea ± constante?
¿Se puede garantizar al menos que el retraso no se acumule?
⮯
Ejercicio +

⮯
A prueba de balas!

Variabilidad y percentiles

Ejemplo: altura


Distribución de alturas en USA, fuente
Fuente inagotable de preocupación entre padres novatos
Distribución de alturas

Distribución "normal"
Distribuciones importantes
Gaussiana (normal)

Poisson: llegada aleatoria

Binomial: monedas aleatorias

Zipf: frecuencia de palabras

Pareto: riqueza

Percentiles y servicio
La media da una idea sesgada de la experiencia
Los percentiles cuentan una historia más completa
Si hablamos del tiempo por petición:
- Percentil 50: la mitad de las peticiones están por encima
- Percentil 90: 1 de cada 10 peticiones está por encima
- Percentil 99: 1 de cada 100 peticiones por encima
Mal percentil 99, a 100 peticiones por segundo:
Estamos cometiendo 1 pifia cada segundo
Ejercicio: Tiempo total
Una consulta utiliza 10 servidores en paralelo

El percentil 50 es 50 ms
El percentil 90 es de 200 ms
Estima una cota mínima para el tiempo medio por consulta
⮯
Ejercicio +
Simula una distribución de Pareto

xm = 28 ms
α = 1.16
Como función U puedes usar
Math.random()
⮯
Ejercicio +
Simula 100k muestras de Pareto
Calcula la media, mínimo y máximo
Calcula los percentiles 5, 50, 90, 95, 99, 99.9
Nota para calcular percentiles:
- Ordena el array (¡como números!)
- Para el percentil 50%, vete a la mitad del array
- Para el percentil 90% vete a la posición 90k
- ...
⮯
Ejercicio +
Ahora simula peticiones con 10 llamadas a servidores en paralelo
= el máximo de 10 muestras de Pareto
Calcula mínimo, media, percentiles 50 y 90
¿Son iguales que antes?
⮯
Ejercicio +
Por fin, simula peticiones con 10 llamadas a servidores en serie

Será el resultado de sumar 10 muestras de Pareto
Calcula el percentil 50
¿Es 10 veces el valor de antes?
⮯
Ejercicio +
Para notísima: simula una petición a 10 servidores en serie,
cada una de las cuales hace 10 en paralelo

¿Cuáles son media, mínima, percentil 50?
⮯
Ejercicio +
Esta última parte no es ciencia ficción
En 2009 una búsqueda en Google usaba 1000 servidores

Tiempo total 200 ms
¿Se te ocurre alguna forma de mejorar la respuesta?
⮯
Timed out!

Paquete pareto-simulator
Instala pareto-simulator:
$ npm i -g pareto-simulator Ahora prueba con unos cuantos comandos:
$ pareto --xm 28
$ pareto --xm 28 --parallel 10
$ pareto --xm 28 --series 10
$ pareto --xm 28 --series 10 --parallel 10
$ pareto --xm 1 -n 1000 --parallel 30 --series 30 --timeout 10 --linear
¿A qué distribuciones te recuerdan?
Ley de Pareto

Regla del 80/20
Un 20% de las causas genera el 80% de los efectos
Aplica a un amplio espectro de fenómenos:
- Distribución de la propiedad de las tierras
- El 20% de los clientes generan el 80% de las ventas
- Distribución de las ciudades por población

Trabajo de optimización
Toca el duro trabajo de optimizar un servicio
Consume demasiado/a:
- CPU
- memoria
- descriptores de fichero
- búffers de entrada/salida
- ...
¿Por dónde empezamos?
Localizamos los 🔥hot spots🔥
¡Qué suerte!
Los 🔥hot spots🔥 siguen el principio de Pareto
Un 20% del código ocupa el 80% del tiempo de proceso
La ley aplica recursivamente...
Un 4% del código ocupa el 64% del tiempo de proceso
¿Vale la pena?

Ley de Amdahl
Una ley en apariencia complicada


Más fácil

Ejercicio: Límites de optimización
Petición get de nodecached: 37250 rps
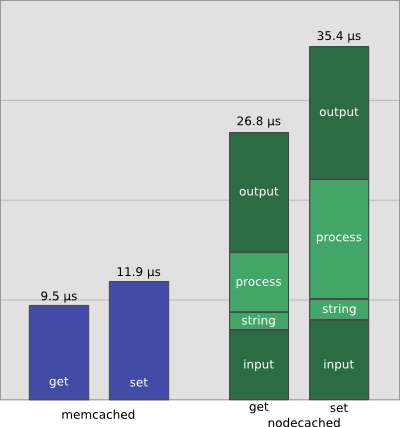
¿Cuánto podemos acelerar el servidor nodecached?
⮯
Ejercicio +
Nos centramos en la operación get:
- 2 µs: conversión a string
- 6 µs: procesamiento interno
- 7 µs: input
- 12 µs: output
Suponemos que optimizamos string y procesamiento (0µs)
¿Cuánto es el máximo teórico de peticiones por segundo?
⮯
Ejercicio +
Fórmula: R [rps] = 1000000 / t [µs]
Ejercicio de imaginación:
¿Qué estrategias podemos seguir para optimizar más?
⮯
Acelerando!

Ley de retornos decrecientes
Según avanzamos en la optimización el retorno de inversión disminuye
Cuidado con la micro-optimización
Incertidumbre y error

Error sistemático o aleatorio

Error sistemático

Error aleatorio
Tipos de aleatoriedad



Ejercicio: Distribución real
Queremos medir la distribución de tiempos
Peticiones al servicio http://service.pinchito.es:3000/a
⮯
Ejercicio +
Bájate a local el proyecto loadtest
(Lo tienes preparado en la imagen pinchito-loadtest)
Trúcalo para que pinte el tiempo de cada petición
(También en la imagen)
Lanza las pruebas:
node bin/loadtest.js http://service.pinchito.es:3000/a -n 15000 -c 100 --rps 300 Usa rps por encima y por debajo del valor sin --rps (e.g. 300 y 500)
⮯
Ejercicio +
Saca el resultado a fichero y extrae los valores numéricos
$ comando | grep -v INFO > service-times-300.csv
Dibuja un histograma con los valores
Dibuja un histograma log-log
¿Qué te dicen las gráficas?
⮯
Awesome!

Ejercicio +
Perfilado de código

Perfilado con microprofiler
Paquete microprofiler
Permite ver en qué se va el tiempo de proceso
Es una capa fina sobre
process.hrtime()
Se instrumentan secciones de código:
const start = microprofiler.start() Empieza a medir
microprofiler.measureFrom(start, 'label', 10000) Mide el tiempo entre
start() y measureFrom()
Pinta un resumen para
label cada 10000 llamadasPerfilado nativo
Node.js incluye también un profiler majo:
$ node --prof ... Esto genera un fichero como
isolate-0x440c2f0-28473-v8.log
Se puede interpretar con el comando
node --prof-process isolate-0x440c2f0-28473-v8.log La salida tiene tres partes:
-
[Summary]: Resumen de tiempos -
[JavaScript],[C++ entry points]: Secciones desglosadas -
[Bottom up (heavy) profile]: Perfil jerárquico
Flamegraphs

Paquetes de flamegraphs
Paquete 0x
Demo en directo
Ejercicio: Ahorrando microsegundos
Queremos optimizar el código de pareto-simulator
¿Dónde se nos va el tiempo?
Vamos a ver dos enfoques alternativos
⮯
Ejercicio +
Clona el paquete pareto-simulator
$ git clone https://github.com/alexfernandez/pareto-simulator.git
$ cd pareto-simulatorInstala el paquete microprofiler
$ npm i microprofiler Léete las instrucciones
⮯
Ejercicio +
Instrumenta el código:
const microprofiler = require('microprofiler');
...
computeSamples() {
for (let i = 0; i < options.number; i++) {
const start = microprofiler.start()
const sample = this.computeSample()
microprofiler.measureFrom(start, 'sample', 10000)
this.samples.push(sample)
this.sum += sample
if (sample > this.max) this.max = sample
if (sample < this.min) this.min = sample
microprofiler.measureFrom(start, 'stats', 10000)
}
}
Ejecuta y mira los resultados:
$ node index.js --xm 1 -n 1000 --parallel 30 --series 30 --timeout 10 --linear
⮯
Ejercicio +
Ahora instrumenta la función
computeSample()
Mira a ver si hay alguna sorpresa
Intenta buscar alguna optimización...
Y vuelve a medir
⮯
Ejercicio+
En este último paso vamos a ejecutar el profiler de Node.js:
$ node --prof index.js --xm 28 -n 10000000 Y ahora interpretamos la salida:
$ node --prof-process isolate-0x...-v8.log
¿Te llama algo la atención?
¿Se te ocurre cómo optimizarlo?
¿Es este profiler igual de ágil que microprofiler?
⮯
Good job!

Bibliografía
pinchito.es: Optimizando sockets con node.js
pinchito.es: node.js: ¿rápido como el rayo?
pinchito.es: Pruebas de carga
Node.js: Flame Graphs
Netflix Tech Blog: Node.js in Flames