全球知識鏈結與在地資料串連
維基數據的發展與應用
王文岳 Allen Wang
Wikidata Taiwan
王文岳
- Wikidata Taiwan 共同發起人
- 立法院開放國會第一屆委員
- 前台灣維基媒體協會秘書長
- 李梅樹紀念館資訊組召集人
- 國家文化記憶庫社群經營研究:資訊技術協力

全球知識鏈結與在地資料串連?
題目好像訂有點大
但,我想回到資料本身
有資料、給資料、找資料
內容
人
我們常說找資料真的是人在找資料嗎?
內容
Content
人
People
數位時代下內容流通
後設資料
Metadata
搜尋引擎/機器
Search Engine/Bot
搜尋行為/資料存取
人為編寫/機器生成
或是你也可以問 AI 就好
就算答案可能很爛但他還是有答案
請問什麼是淡水?


什麼是東區?


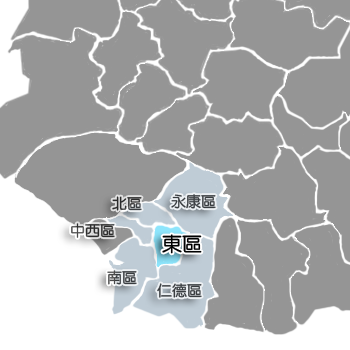
臺灣有三個行政區有東區
而台北東區不是行政區劃
我們要如何避免同樣的語言指稱不同資料?
你知道林掄元是誰嗎?
他總是常常塗抹孩子們的微笑
喔對 他今年50歲

都省瑞有聽說過嗎?

本人好像很困擾本名很少被念對
那要怎麼處理不同說法
但應該要指向同一筆資料
鏈結資料簡介
Wikidata / Wikibase 簡介
Wikidata 應用於資料檢索機制與案例
Linked Data
我們要來談談鏈結資料
鏈結資料 (Linked Data):
-
利用 URI 為事物命名
-
以 HTTP 做為客戶端和伺服器端之間查詢及傳送URI的機制,使人或電腦可以查詢特定 URI 所代表事物的相關資訊
-
伺服器端使用 RDF 與 SPARQL 等標準,提供更多的資訊。當伺服器端接獲客戶端對於特定 URI 的請求時,伺服器端會以標準格式將該 URI 所代表事物的相關資訊傳 回給客戶端。若客戶端是「人」,則伺服器端可回傳 HTML 格式的文件;若客戶端是「應用程式」,則伺服器端可回傳 RDF 格式的文件,以方便客戶端的應用程式再利用這些資訊
-
對於特定URI所代表事物的相關資訊中,應包含與其他相關事物的連結(連結到該事物的URI),使得事物間得以串連,以達成構築全域資料空間的目標
--【鏈結資料在圖書館的應用】
什麼是 URI?
統一識別碼
在單一個資料庫中一個統一格式的號碼配發
通常單一筆資料只會對應一個號碼
像是身份證字號、信用卡號、郵局帳號都是等等
簡單來說:電腦看得懂的資料
跟當代AI的邏輯相反
直接把資料轉成電腦好懂的格式
我們來看看怎樣的資料電腦才比較容易看懂
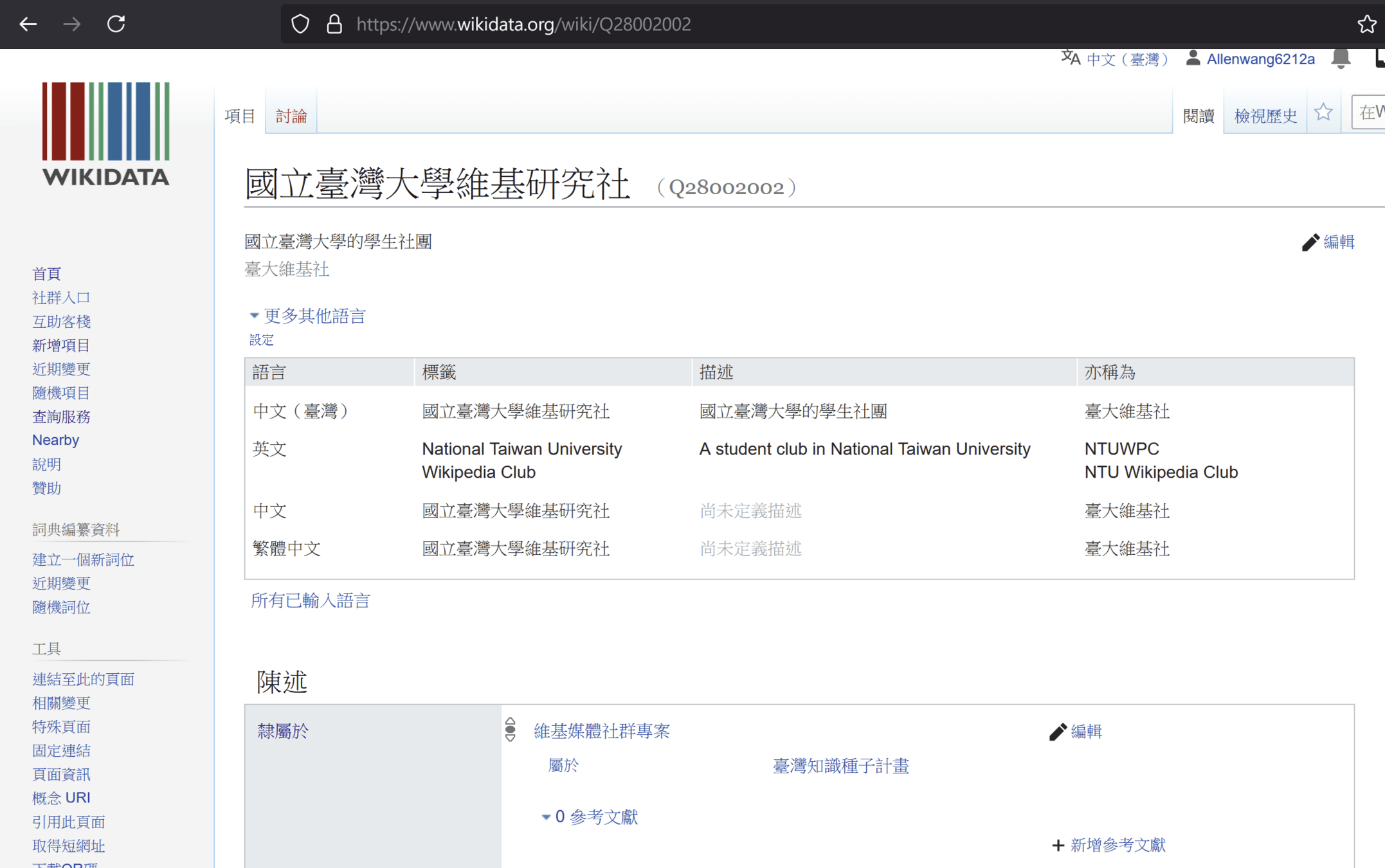
以統一識別碼(URI)為物件命名
以HTTP服務提供URI的查詢與資訊提供
特定URI的內容應保留連結到其他URI的連結
國立臺灣大學維基研究社
Q28002002
國家 P17
中華民國
Q865
資料的描述都是一對一的
並且每一筆資料都會有獨一無二的識別碼
也不會搞混
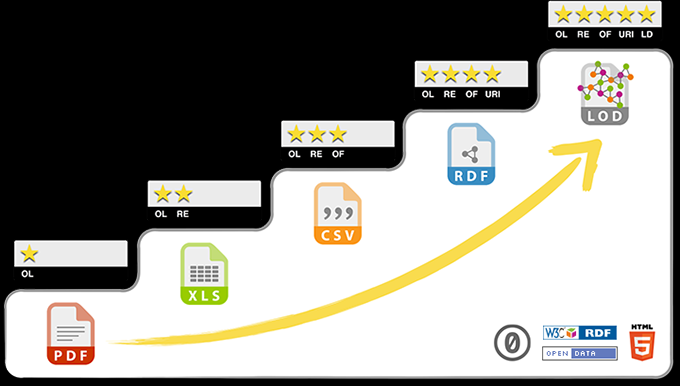
開放資料五顆星
大漢溪
Q199374
河流
Q4022
P31
P31
三峽河
Q199374
支流
P974
注入河流P403
大安圳
Q4022
注入河流P403
分流 P5998
人造水道
Q12284
橫溪
Q11122285
支流
P974
注入河流P403
P31
P31
支流
P974
湳仔溝
Q10395799
支流
P974
注入河流P403
三峽河的水系圖用 Wikidata 的結構表示
Wikidata/Wikibase 作為 LoD 平台
Q
Q
P
P
P
Q
P
P
P
在 Wikidata 裡面我們不再用散文的方式在紀錄資料
而是改變成為單字、片語的方式進行
讓跨語言的資料只需要翻譯單詞或片語
就能用最低的成本做到多語言呈現

三元組的描述方式可以更快速進行內容比較
三元組的呈現方式
可以協助資料跨語言展示


trv
tay

szy
中華民國
教育部
教育部
性質
Q697093
P31
Q2269756
Mklawa ttgsa klwaan Cunghwu Minkwo
性質
教育部
Kyo’ikbu
性質
教育部
trv
tay
en
Ministry of Education (R.O.C)
instance of
ministry of education

Wikidata 地方學聚會
轉譯地方志內容為鏈結資料


轉置地方志內容為結構化資料
開展更多應用的可能性



結構資料再處理與應用

開放鏈結資料維基媒體生態系
Wikidata.org
是美國維基媒體基金會繼維基共享資源後
第一個跨語言專案

維基百科基於人類閱讀的需求
使得部分瑣碎資料無法被獨立紀錄與分述

機讀對於關聯的需求更甚
Wikidata 得以收錄更細節更多元的內容
提供基礎資訊的建構


Wikidata 同時透過「亦稱為」一欄
以及多語言欄位
提供跨語言對照以及權威詞彙對照的功能
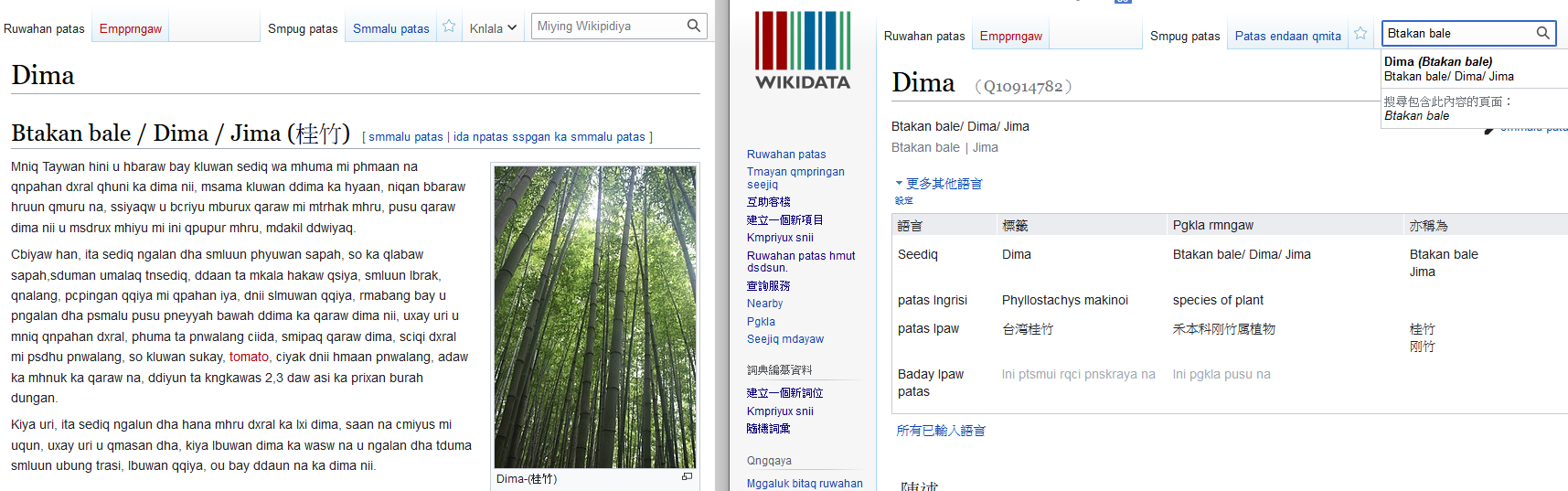
樂信·瓦旦
- 音界號?
- 樂信·瓦旦? 樂信‧瓦旦?
- 拼寫不同或是各不同語言
- Losing Watan 、樂信·瓦旦
- 不同時期的姓名
- 渡井三郎、日野三郎
語言欄位連結各語言與各通同名稱
並使用唯一識別碼互相溝通
提供權威對照的功能

亦稱為 欄位同時也可以處理單一語言代碼下
多語言、多部落稱呼不同的問題
Wikidata 也能用於跨資料庫的檢索!
A資料庫
B資料庫
資料Z-B
資料Z-A
要確定兩者的通同性
就需要進行對照工作
在許多時候我們都可能需要進行資料庫對照
像是資料庫匯入、多資料庫整合等等
當只有兩個資料庫時
對照工作或許是可行的
但是當有數十個甚至更多的資料庫時...
同時對照工作還會牽涉到組織權責問題
大量增加成本跟可能的阻礙
A資料庫
B資料庫
資料Z-B
資料Z-A
加入 Wikidata 做為第三方
各資料庫之間對照只需要滿足與 Wikidata 之間的對照
就能在與其他資料庫進行對照
資料Z-W
QNNNNNNN
Wikidata
B資料庫
OSM
河川代碼
242000
10553609
花蓮溪
Q707891
Wikidata
XXXXX
阿美語/賽德克語/撒奇萊雅語/....
XXXXX
環境/水文/水保資料
XXXXX
文化/交通/觀光資料
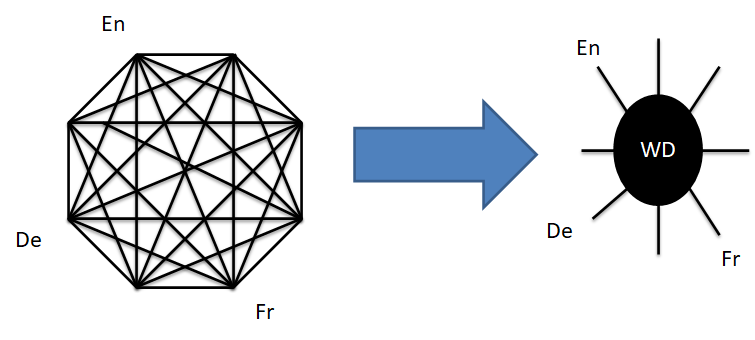
在維基媒體計畫內部
Wikidata 也扮演著多語言/多計畫資料整合對照
導出
應用
對照
跨域檢索
隨著資料的快速擴展
串聯多元資料庫/集將會是資料整合的關鍵

非洲的伊博族也透過 Wikidata 建構伊博語資料集
並正在討論如何應用在未來的新專案「節錄維基百科」
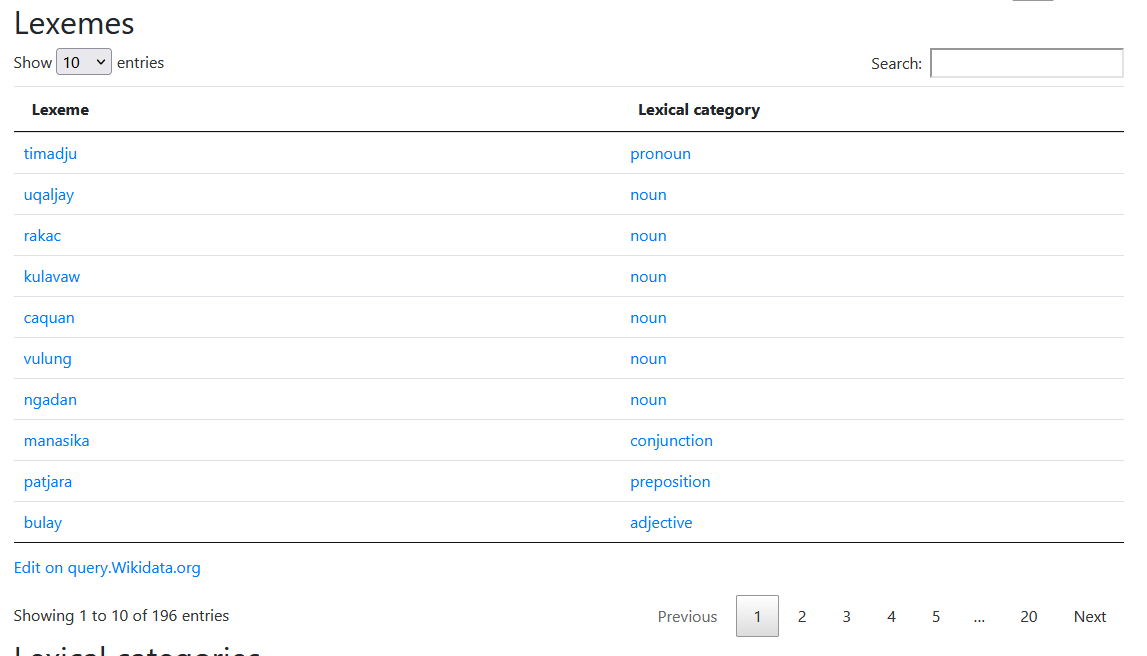
排灣維基用戶組則透過 Wikidata Lexemes 功能
來保存排灣語中各語言的用法
過去我們也曾帶撒奇萊雅社群協助
翻譯 Wikidata 上面各 item 的名稱

Wikidata 人文應用案例

使用 wikidata 做為關鍵字檢索依據

將文本資料庫化後
進行結構化資料的分析與圖像化
結構資料再處理與應用


MoMA 透過 Wikidata 與 Wikipedia 來提供基礎資訊
資料庫不再只服務人
服務機器的資料庫將是趨勢
越來越多資料庫導入機讀特性
在提高閱覽次數的同時
也是改善後續維護的方式
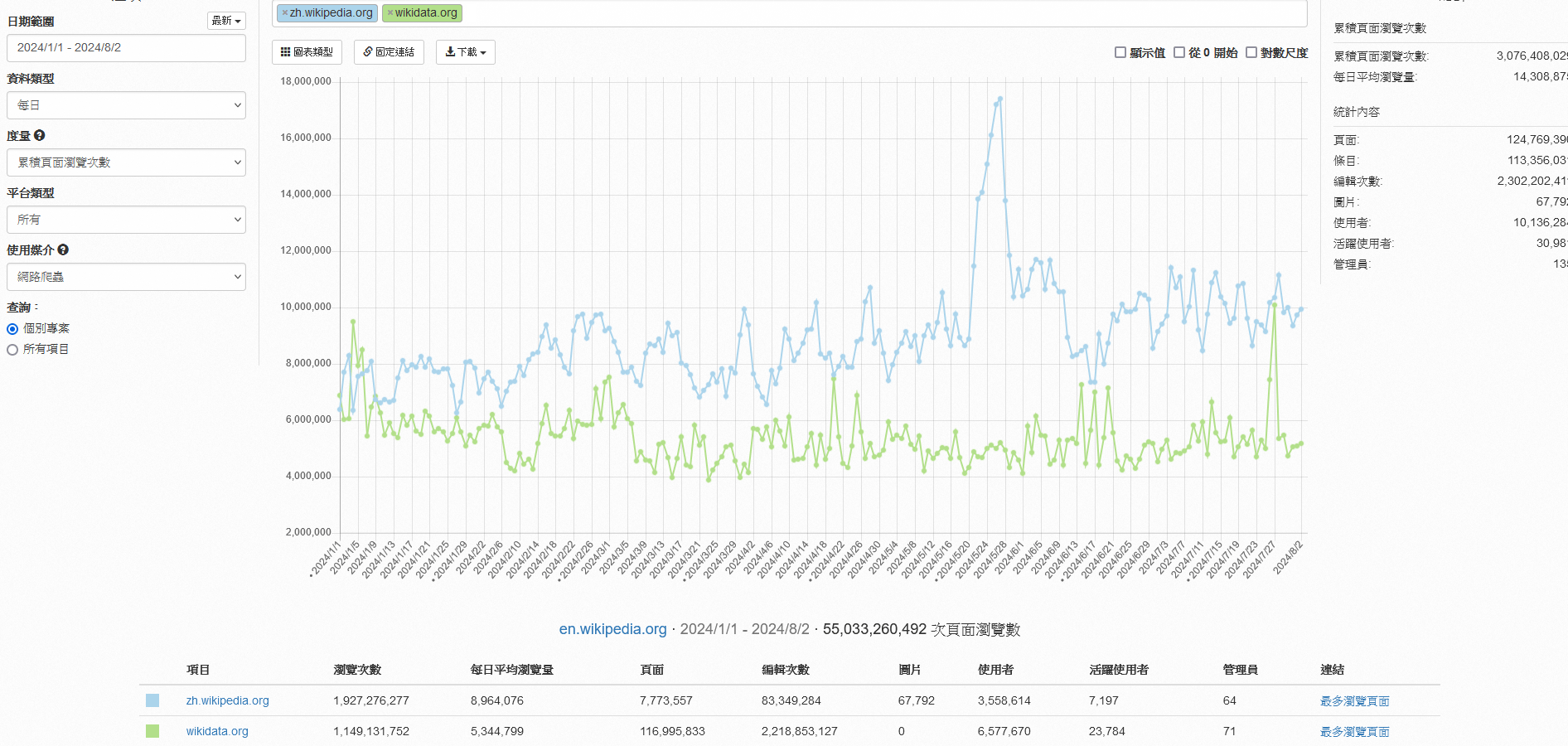
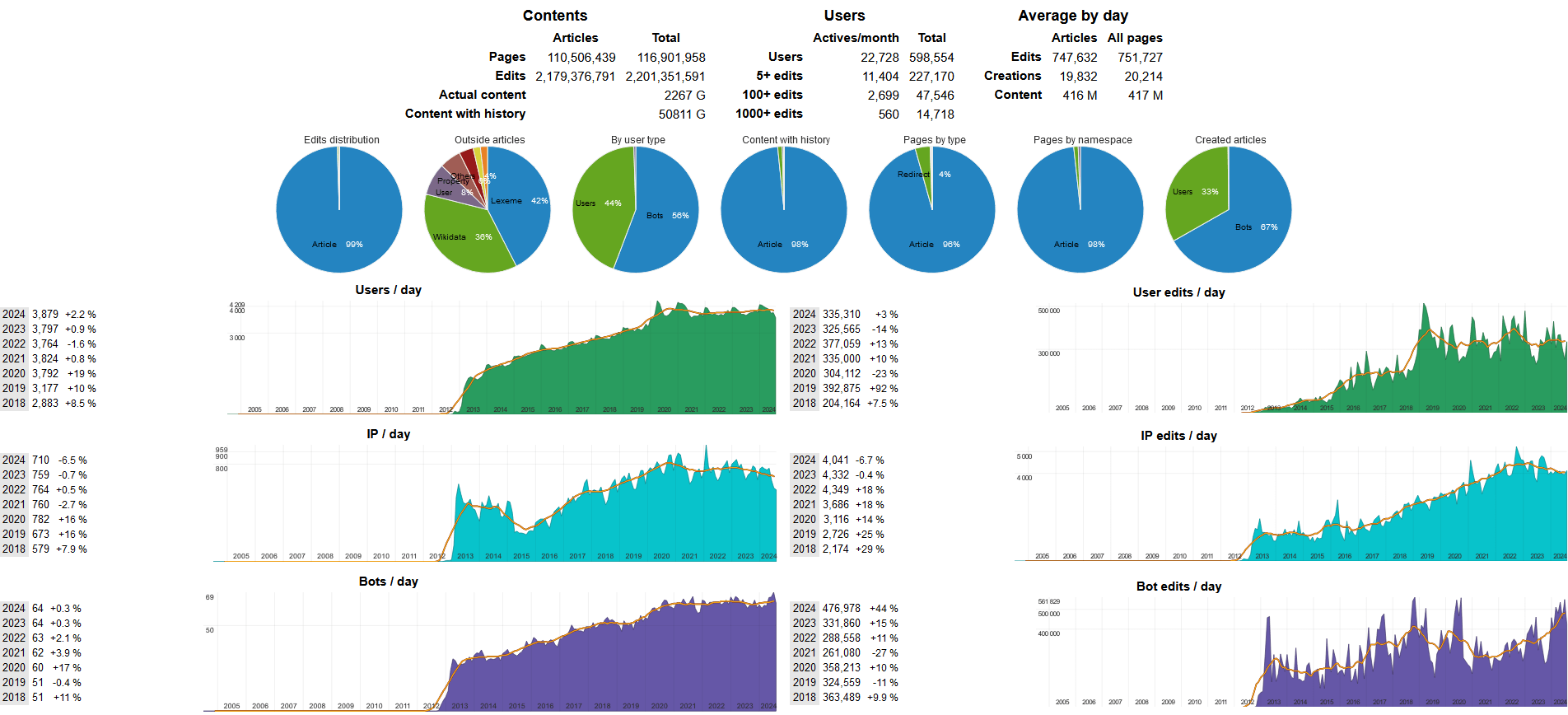
在每天都有1300萬"人"在看維基百科時
同時分別有534萬與快896萬個"機器人"
正看著 Wikidata 與 Wikipedia
機讀友善可創造
更多轉譯與應用的可能性
除了與人協作以外
更是與機器人協作
風險及其限制
