From Collections to Data
Turning Raw Text into Structured Research Data
HOw Best to make the Prozhito collection available for scholarship?
Primary SourceS
Scholarship
Paper
SQL
CSV
?
Diaries by
2882 men
810 women
938 MB of text
32,064,212 Words
~64,000 pages
.
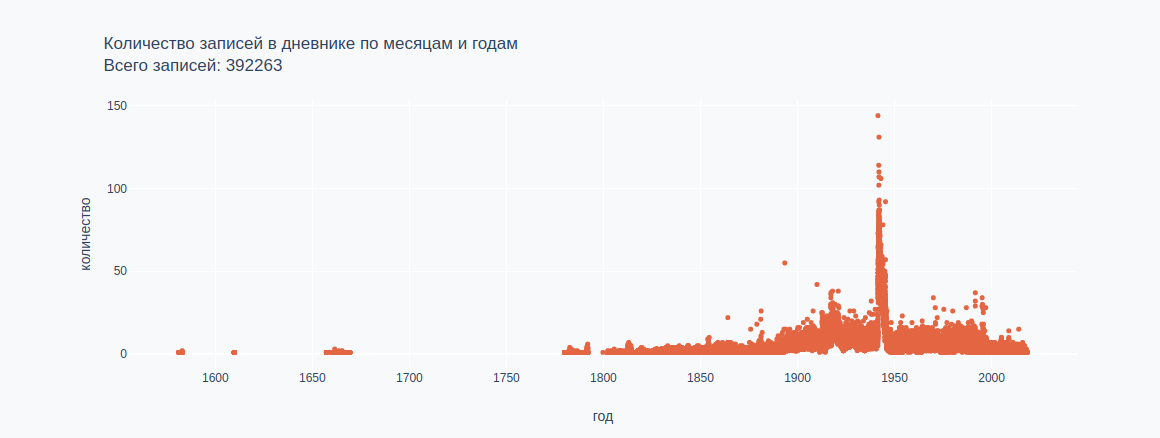
1581-02-01, "Приехал новый московский гонец"
2018-06-17, "Вся моя жизнь после ухода из отеческого дома в 1965 году была распятием на кресте жизни, как и жизнь каждого человека. "
1581-02-01, "Приехал новый московский гонец"
2018-06-17, "Вся моя жизнь после ухода из отеческого дома в 1965 году была распятием на кресте жизни, как и жизнь каждого человека. "
437 years, 4 months, 16 days


Import Script
if __name__ == __main__:
load_sql_file()
load_persons(cursor)
load_tags(cursor)
load_notes(cursor) # individual diary entries
load_diaries(cursor)
update_entries_with_tags(cursor)
lemmatize_texts('mystem')
RuBERT_ner()
geocode_places() # geopy OpenStreetMap
names_extractor() # Natasha
detect_sentiment() # Dostoevsky Machine Reading

RuBERT



RuBERT, ner_rus_bert
Multi-lingual BERT ner_ontonotes_bert_mult




Mystem
from geopy.geocoders import Nominatim
geolocator = Nominatim(user_agent="Prozhito")
location = geolocator.geocode('Хомяки')
print(location, location.latitude, location.longitude)
Хомяки, Свечинский район, Кировская область, Приволжский федеральный округ, Россия
58.1404076 47.631871from pymystem3 import Mystem
m = Mystem()
lemmas = m.lemmatize('В ногах правды нет.')
lemmas
['в', ' ', 'нога', ' ', 'правда', ' ', 'нет', '.', '\n']There are 108,000 entries that mention a place.
Geopy geolocated 3,742 distinct places

Russian name part extractor
from natasha import NamesExtractor
extractor = NamesExtractor()
text = """Иван Иваныч Самовар
Был пузатый самовар,
Трехведёрный самовар."""
matches = extractor(text)
for match in matches:
print(match.span, (text[match.span[0] : match.span[1]], match.fact))
[0, 19) ('Иван Иваныч Самовар', Name(first='иван', middle='иваныч', last='самовар', nick=None))Diary
Person
ENTRY
Diary
Person
ENTRY
3,702
3,705
392,264
Diary
Person
ENTRY
3,702
28,985
392,264
Sentiment Analysis
from dostoevsky.tokenization import UDBaselineTokenizer, RegexTokenizer
from dostoevsky.embeddings import SocialNetworkEmbeddings
from dostoevsky.models import SocialNetworkModel
tokenizer = UDBaselineTokenizer() or RegexTokenizer()
embeddings_container = SocialNetworkEmbeddings()
model = SocialNetworkModel(
tokenizer=tokenizer, embeddings_container=embeddings_container, lemmatize=False,
)
texts = ['Я люблю рыбные консервы',
'Я ненавижу рыбные консервы',
'Я люблю рыбные консервы, но я ненавижу консервированные устрицы'
]
results = model.predict(texts)
for text, result in zip(texts, results):
print(text, result)
Я люблю рыбные консервы positive
Я ненавижу рыбные консервы negative
Я люблю рыбные консервы, но я ненавижу консервированные устрицы negative

Browse diaries, people, places and entries
as a table

Browse diaries, people, places and entries
as a chart
| Швец, Владимир Афанасьевич |
9127 |
1940-07-14 |
1990-10-14 |
| Ларская, Галина Г. |
7414 |
1960-02-03 |
2017-12-06 |
| Пришвин, Михаил Михайлович |
7159 |
1905-01-14 |
1947-12-31 |
| Орешников, Алексей Васильевич |
6603 |
1913-07-12 |
1934-01-13 |
| Измайлов , Константин Федорович |
5817 |
1923-01-01 |
1941-10-08 |
| Японский, Николай |
5133 |
1883-01-01 |
1912-01-09 |
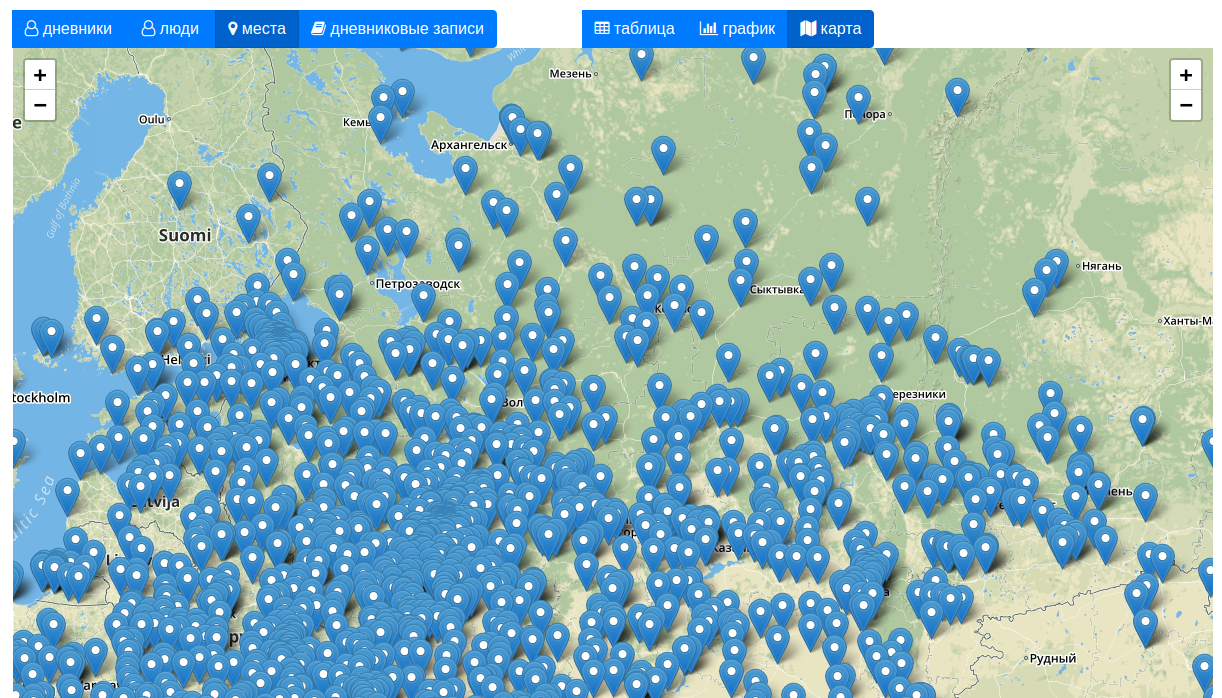
Browse diaries, people, places and entries
as a map
Search
Export
Text
Tasks
1: Provide clean and useful general-use research data with provenance and record of processing.
2: Provide tools to visualize and explore a corpus of text to assess its research value.
3: Transform data and generate features for specific research questions (emotions, networks, places).

Paper
SQL
CSV
① ② ③
Clean
Explore
Transform
import prozhito
for diary in prozhito:
diary.author # Author object
diary.entries # list of entry objects
diary.entries[0].places
Web-APP or API?
HOw Best to make the Prozhito collection available for scholarship?