VLMs in the Stacks
— Andy Janco, RSE, Firestone Library
TOC
AI Librarians
Quick introduction to AI in libraries and information science.
1.
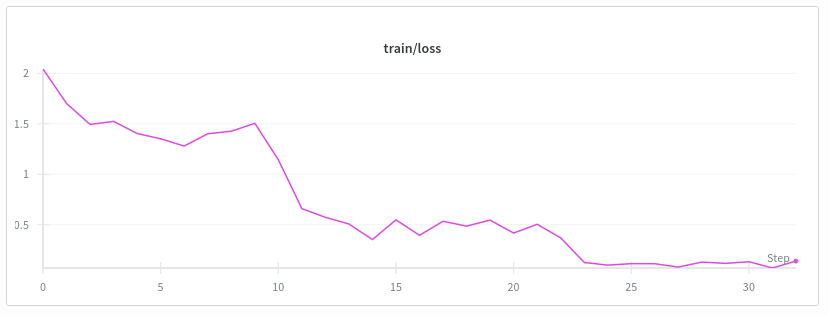
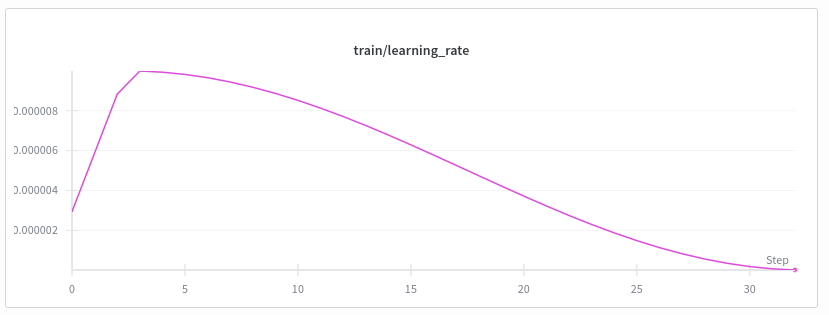
Fine-tuning
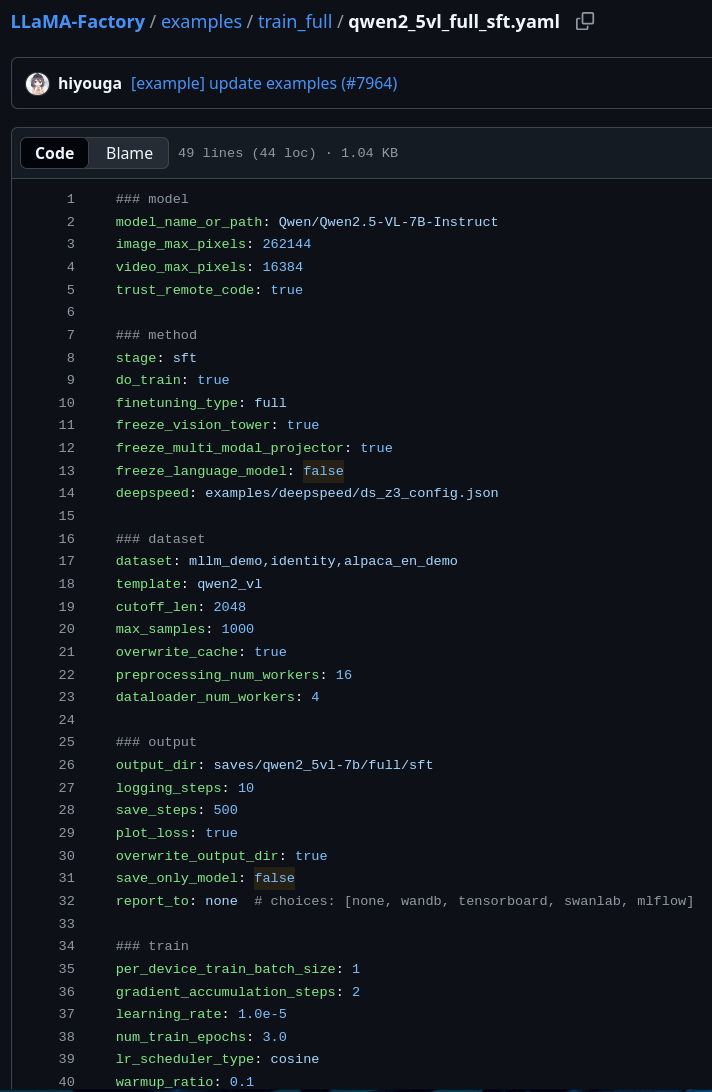
Example from archives in Colombia. Use of "small" VLMs for text extraction and document understanding.
2.
Inference
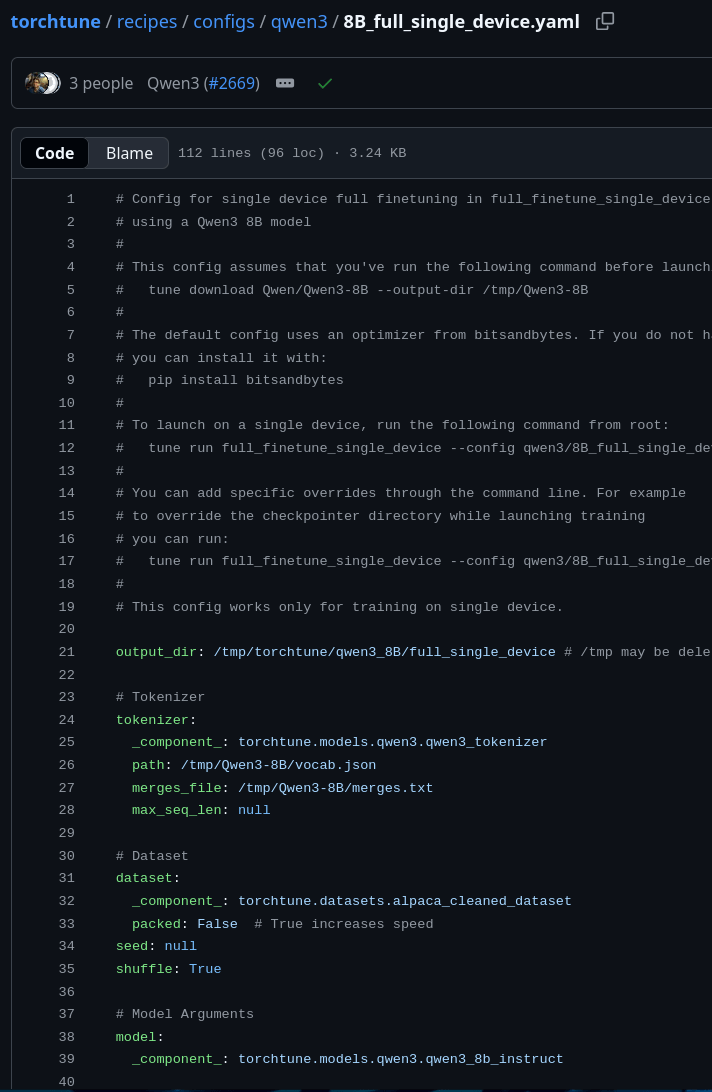
Lessons learned from processing all of Princeton's Senior theses and Dissertations.
3.


AI Librarians

Dan Cohen
Benjamin Kiessling


Daniel van Strien 🤗


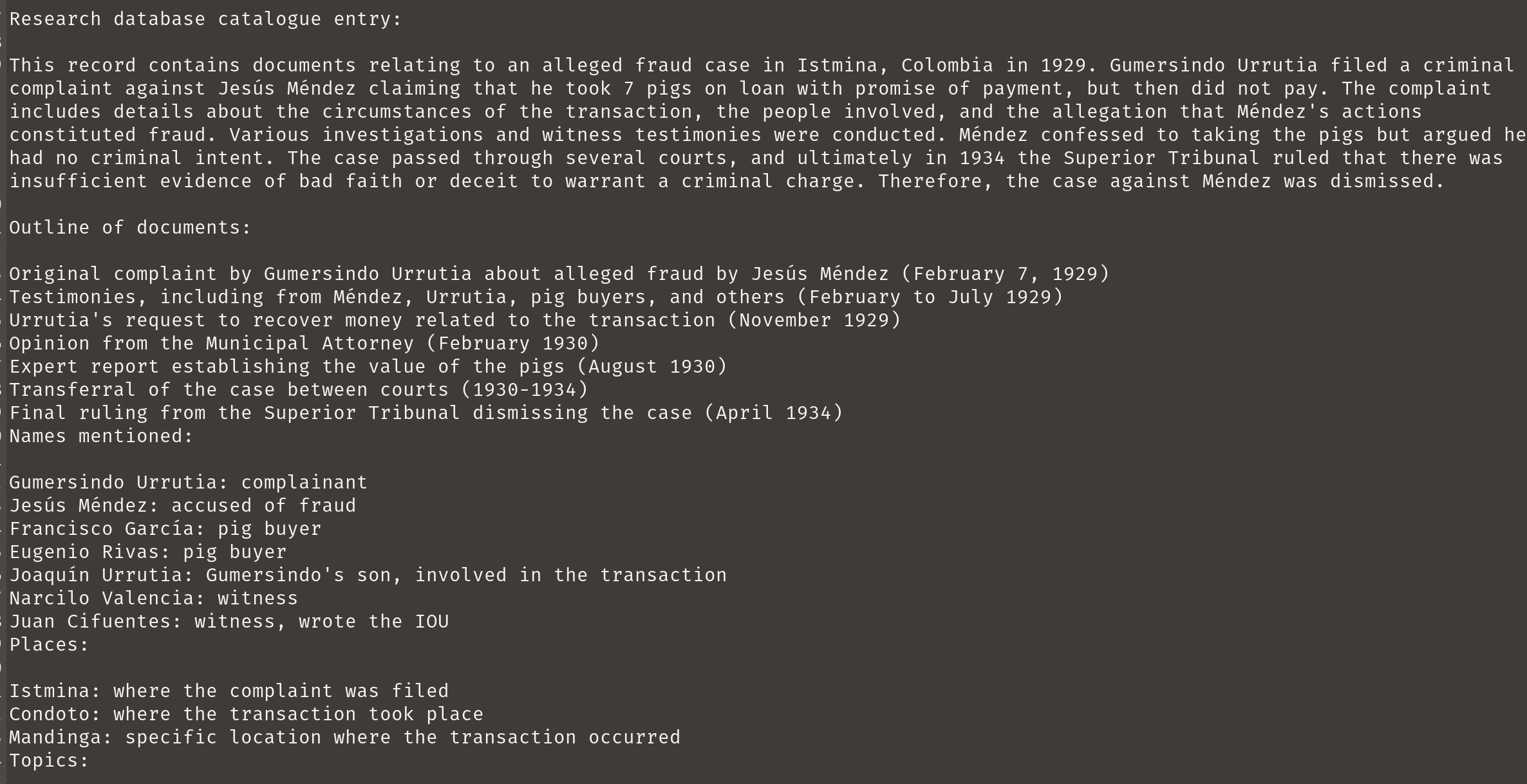
Circuit Court of Istmina, Chocó, Colombia

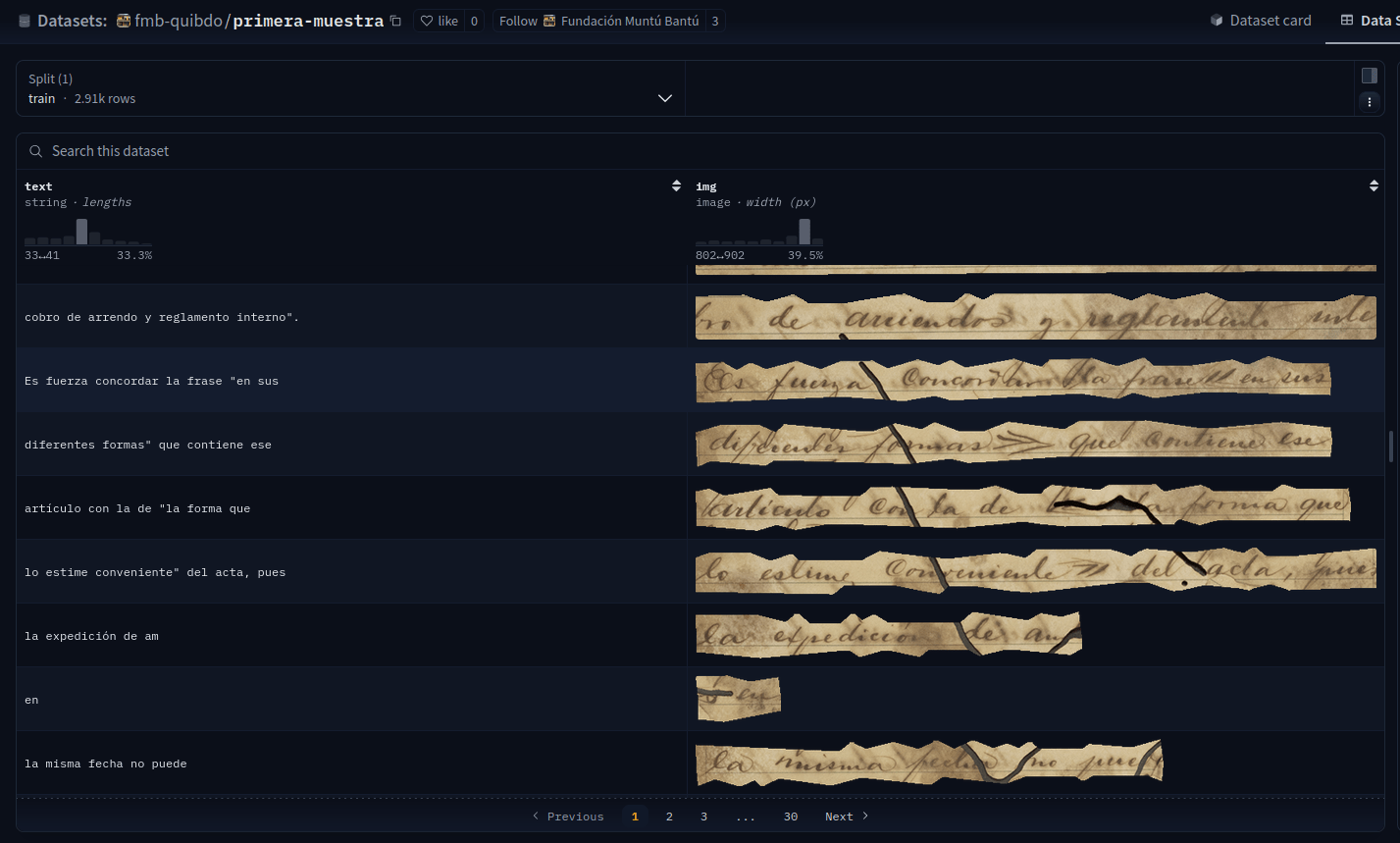
Fine-tuning "small" VLMs on line-level text-image pairs from eScriptorium
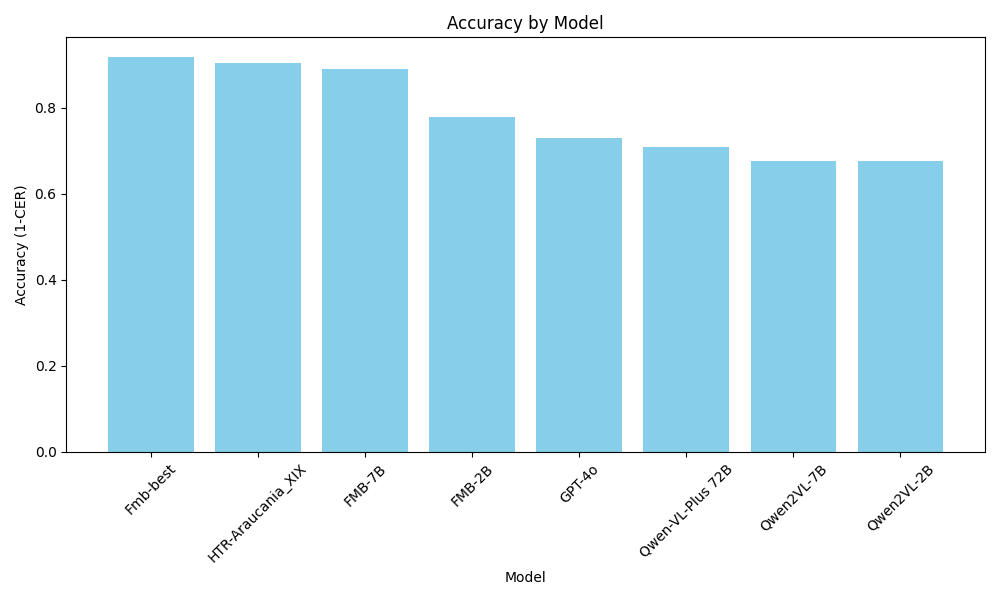
CNN
base
FT
VLM
FT
7B
FT
2B
base
7B
base
2B
{
"messages":[
{
"content":"<image>extract text",
"role":"user"
},
{
"content":"plotar dichas minas en la forma que lo",
"role":"assistant"
}
],
"images":[
"fmb_images/055e42a3-a5c9-40f8-9bf6-3cd5e82dcc1c.png"
]
},
qwen2_vl-7b
4 x L40S

Visual Reasoning and Tool-calling



Metadata context
Identifier: EAP699/23/1
Title: Photographs
Place: Moldova, EuropeZoom / select tool for
image search
multimodal-RAG
Visual Reasoning
Metadata context
Identifier: EAP699/23/1
Title: Photographs
Place: Moldova, EuropeFrantuz Alexei (b. 1964) with his relatives and friends from the commune Ciocîlteni, Moldova (1985-2000).





-
18,608 Senior theses and PhD Dissertations, 2013-2025
-
Metadata from DataSpace
-
Markdown from nanonets/Nanonets-OCR-s (Qwen2.5-VL)
-
4.4 GB, 1.1 billion tokens, 2 million pages
-
31 days, 531 HPC jobs, 4x4hours at a time
-
Average CPU utilization 99.5%, GPU utilization 86%
Princeton Thesis Dataset

- vLLM, gpu_memory_utilization
- efficent message batching
- worked with page images in memory
- 8B VLM runs on a single GPU, can scale with concurrent jobs.
What I did right
- Use metadata to sort the dissertations by page length, and quantify the relationship between the number of pages and memory usage. 61 jobs were OUT_OF_MEMORY.
- Work from the model's preference for HTML over md for tables. My prompt says MD, but the results are inconsistent.
- Faster and fewer jobs with multi-node vLLM with Ray?
If I could do it again
Adapted from uv-scripts/ocr by davanstrien




doc = pymupdf.open(pdf)
for i, page in tqdm(enumerate(doc)): # iterate through the pages
pix = page.get_pixmap(dpi=100)
img = pix.pil_image()
pdf_images.append({
"image": img,
"page": i + 1,
}) pdf_text = """"""
for batch in tqdm(image_batches, desc=f"Processing {pdf.stem}"):
batch_messages = [make_ocr_message(page["image"]) for page in batch]
# Process with vLLM
outputs = llm.chat(batch_messages, sampling_params)
# Extract markdown from outputs
for output in outputs:
markdown_text = output.outputs[0].text.strip()
pdf_text += markdown_text + "\n\n"
md_file.write_text(pdf_text, encoding='utf-8')

LLM Collective Nov 12, 2025, 4:00 pm – 5:00 pm, Commons Library Classroom
THANK YOU


slides.com/andrewjanco/vlms-in-stacks