
Занятие №12:
Улучшения глубокого Q-обучения
Основные понятия
Улучшения
-
Дуэльная сеть DQN (DDQN);
-
Двойная DQNs;
- Фиксированные целевые значения (Q-targets).
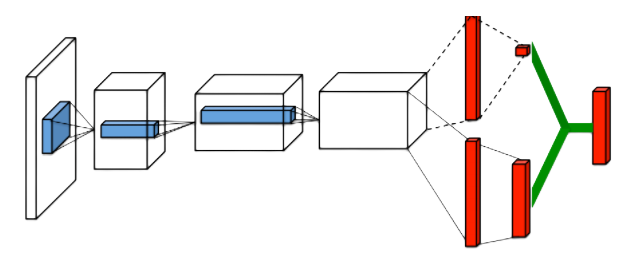
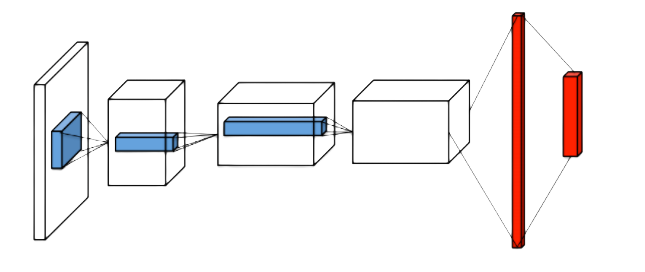
Дуэльная сеть DQN (DDQN)
Q-значения, Q(s,a), которые нейронная сеть пытается аппроксимировать, можно разделить на следующие величины:
- V(s) - значение состояние, то есть ценность пребывания в нем;
- A (s, a) - преимущество выполнения этого действия в этом состоянии (насколько лучше выполнить это действие по сравнению со всеми другими возможными действиями в этом состоянии).
Дуэльная сеть DQN (DDQN)
Используем данную сеть

Q(s,a1)
Q(s,a2)
Q-значения
Q(s,a1)
Q(s,a2)
Q-значения
Дуэльная сеть DQN (DDQN)
Агрегация
Пример


Значение
Преимущество
Значение
Преимущество
Фокус на 2-ух вещах:
-
Горизонт, где появляются новые машины;
-
На табло с очками.
Если нет машины впереди, то не обращаем особого внимания на дорогу, так как выбор действий не актуален.
Обращаем внимание на впереди идущую машину, так как в этом случае выбор важен для выживания.
Агрегация
Двойная DQNs
Этот метод решает проблему завышения Q-значений.
Целевое Q-значение
Награда за выполнение этого действия в этом состоянии
Дисконтированное максимальное Q-значение среди всех возможных действий из следующего состояния
Вычисление Q-значения в обычном DQN
Двойная DQNs
- Используйте нашу сеть DQN, чтобы выбрать наилучшее действие для следующего состояния (действие с наибольшим значением Q);
- Используйте нашу целевую сеть, чтобы вычислить целевое Q-значение для выполнения этого действия в следующем состоянии.
Целевое TD значение
Сеть DQN выбирает действие для следующего состояния
Целевая сеть вычисляет Q-значение выполнения этого действия в этом состоянии
Пример
Фиксированные Q-targets
- Создаем сеть DQN и целевую сеть;
- Использование отдельной сети с фиксированным параметром для оценки TD target;
- После завершения эпизода мы копируем параметры из нашей сети DQN для обновления целевой сети.
Для магистров.
Изменение весов
Максимально возможное Q-значение для следующего состояния
Текущее прогнозируемое q-значение
Градиент нашего текущего прогнозируемого значения Q
На каждом шаге T
Код
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, Conv2D, Flatten, BatchNormalization, ReLU, InputLayer
from tensorflow.keras.optimizers import Adam
import gym
import numpy as np
from collections import deque
import random
import vizdoomgym
from datetime import datetime
env = gym.make('VizdoomCorridor-v0')
n_outputs = env.action_space.n
observation = env.reset()
plt.imshow(observation)
plt.show()
Код preprocess_frame
def preprocess_frame(frame):
# Добавляем оттенок серого
frame = np.mean(frame,-1)
# Обрезать экран (удалить часть, не содержащую информации)
# [вверх: вниз, влево: вправо]
cropped_frame = frame[15:-5,20:-20]
# Нормализация значений пикселей
normalized_frame = cropped_frame/255.0
# Изменение размера
preprocessed_frame = transform.resize(cropped_frame, [240,320])
return preprocessed_framestack_size = 4 # Складываем 4 кадра
stacked_frames = deque([np.zeros((240,320), dtype=np.int) for i in range(stack_size)], maxlen=4)
def stack_frames(stacked_frames, state, is_new_episode):
frame = preprocess_frame(state)
if is_new_episode:
# Очистить наш stacked_frames
stacked_frames = deque([np.zeros((240,320), dtype=np.int) for i in range(stack_size)], maxlen=4)
stacked_frames.append(frame)
stacked_frames.append(frame)
stacked_frames.append(frame)
stacked_frames.append(frame)Код stack_frames
# Сложить кадры
stacked_state = np.stack(stacked_frames, axis=2)
else:
# Добавить кадр в двухстороннюю очередь, автоматически удалив самый старый фрейм
stacked_frames.append(frame)
# Создайте сложенное (stacked) состояние
stacked_state = np.stack(stacked_frames, axis=2)
return stacked_state, stacked_framesКод stack_frames
print(stacked_frames)Код
array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]])# Гиперпараметры
state_size = [240,320,4]
action_size = env.action_space.n
learning_rate = 0.00025
total_episodes = 50 # Общее количество эпизодов
max_steps = 50 # Максимально возможное количество шагов в эпизоде
batch_size = 64
explore_start = 1.0 # Вероятность исследования на старте
explore_stop = 0.01 # Минимальная вероятность исследования
decay_rate = 0.0001 # Скорость затухания для исследованийГиперпараметры
# Q learning параметры
gamma = 0.95 # Коэффициент дисконтирования
# Количество опытов, сохраненных в памяти при первой инициализации
pretrain_length = batch_size
# Количество опытов, которые может сохранить память
memory_size = 1000000 Гиперпараметры
Код
possible_actions = np.identity(action_size, dtype=int).tolist()
print(possible_actions)[[1, 0, 0],
[0, 1, 0],
[0, 0, 1]]Код ReplayBuffer
img_array= []
img_array_test= []
class ReplayBuffer:
def __init__(self, capacity=10000):
self.buffer = []
#self.buffer = deque(maxlen=capacity)
self.buffer_size = capacity
def add(self, state, action, reward, next_state, done):
if len(self.buffer) + 1 >= self.buffer_size:
self.buffer[0:(1+len(self.buffer))-self.buffer_size] = []
self.buffer.append([state, action, reward, next_state, done])Код ReplayBuffer
Код ReplayBuffer
def sample(self):
buffer_size = len(self.buffer)
index = np.random.choice(np.arange(buffer_size),
size = 32,
replace = False)
return [self.buffer[i] for i in index]
def size(self):
return len(self.buffer)Код
#Веса модели будут сохраняться в папку Models.
Save_Path = 'Models'
if not os.path.exists(Save_Path):
os.makedirs(Save_Path)
path = '{}_DQN'.format("Name")
Model_name = os.path.join(Save_Path, path)Код DQN с улучшениями
class DQN:
def __init__(self, state_dim, aciton_dim):
self.state_dim = state_dim
self.action_dim = aciton_dim
self.epsilon = 1.0
self.model = self.create_model()Код DQN с улучшениями
def create_model(self):
state_input = Input(shape=(*self.state_dim,), name="inputs")
conv2d_1 = Conv2D(filters = 32, kernel_size = [8,8], strides = [4,4], padding = "VALID",
activation = "relu")(state_input)
conv2d_2 = Conv2D(filters = 64, kernel_size = [4,4], strides = [2,2], padding = "VALID",
activation = "relu")(conv2d_1)
conv2d_3 = Conv2D(filters = 128, kernel_size = [4,4], strides = [2,2], padding = "VALID",
activation = "relu")(conv2d_2)
flatten_1 = Flatten()(conv2d_3)
dense_1 = Dense(units = 512, activation = "relu")(flatten_1)
value_output = Dense(units = 1)(dense_1)
advantage_output = Dense(units = self.action_dim)(dense_1)
output = Add()([value_output, advantage_output])
model = tf.keras.Model(state_input, output)
model.compile(loss='mse', optimizer=Adam(learning_rate=0.005))
return model Код DQN с улучшениями
def predict(self, state):
return self.model.predict(state)
def get_action(self, explore_start, explore_stop, decay_rate, decay_step, state, possible_actions):
state = np.reshape(state, (1, *state.shape))
self.epsilon = explore_stop + (explore_start - explore_stop) * np.exp(-decay_rate * decay_step)
q_value = self.predict(state)
if np.random.random() < self.epsilon:
action = np.random.choice(range(self.action_dim), 1)[0]
return action
action = np.max(q_value)
index = np.where(q_value == action)
return int(index[1])Код DQN с улучшениями
def train(self, states, targets):
self.model.fit(states, targets, epochs=10, verbose=0)
def load(self, Model_name):
self.model = load_model(Model_name + ".h5", compile=True)
def save(self, Model_name):
self.model.save(Model_name + ".h5")
# Не входят в класс DQN
print(env.action_space.n)
print(env.observation_space.shape)
3
(240, 320, 3)
Код Agent
class Agent:
def __init__(self, env):
self.env = env
self.state_dim = [240,320,4]
self.action_dim = self.env.action_space.n
self.model = DQN(self.state_dim, self.action_dim)
self.target_model = DQN(self.state_dim, self.action_dim)
self.target_update()
self.buffer = ReplayBuffer()Код Agent
def replay(self):
for _ in range(10):
batch = self.buffer.sample()
states = np.array([each[0] for each in batch], ndmin=3)
actions = np.array([each[1] for each in batch])
rewards = np.array([each[2] for each in batch])
next_states = np.array([each[3] for each in batch], ndmin=3)
done = np.array([each[4] for each in batch])
targets = self.target_model.predict(states)
target_next = self.target_model.predict(next_states)
Код Agent
for i in range(0,32):
terminal = done[i]
if terminal:
targets[i] = rewards[i]
else:
targets[i] = rewards[i] + 0.95 * target_next[i]
self.model.train(states, targets)
Код Agent
def train(self, max_episodes=10, stacked_frames=None):
if os.path.exists("Models/Name_DQN.h5"):
self.model.load("Models/Name_DQN")
print("Модель загружена")
decay_step = 0
for ep in range(max_episodes):
done, total_reward = False, 0
state = self.env.reset()
state, stacked_frames = stack_frames(stacked_frames, state, True)
while not done:
decay_step += 1
action = self.model.get_action(explore_start, explore_stop, decay_rate, decay_step, state, possible_actions)
next_state, reward, done, _ = self.env.step(action)
img_array.append(next_state)
next_state, stacked_frames = stack_frames(stacked_frames, next_state, False)
self.buffer.add(state, action, reward*0.01, next_state, done)
total_reward += reward
state = next_state
if self.buffer.size() >= 32:
self.replay()
self.target_update()
print('Эпизод {}; награда за эпизод={}'.format(ep, total_reward))
if ep % 5 == 0:
self.model.save("Models/Name_DQN")Код Agent
def test(self, Model_name, stacked_frames = stacked_frames):
self.model.load(Model_name)
decay_step = 0
for e in range(2):
done, total_reward = False, 0
state = self.env.reset()
state, stacked_frames = stack_frames(stacked_frames, state, True)
while not done:
decay_step += 1
action = self.model.get_action(explore_start, explore_stop, decay_rate, decay_step, state, possible_actions)
next_state, reward, done, _ = self.env.step(action)
img_array_test.append(next_state)
next_state, stacked_frames = stack_frames(stacked_frames, next_state, False)
total_reward += reward
state = next_state
if done:
print("Эпизод: {}/{}, общая награда: {}".format(e, 10, total_reward))
break
self.env.close()Наконец начинаем тренировку
env = gym.make('VizdoomDefendLine-v0')
agent = Agent(env)
agent.train(max_episodes=10, stacked_frames = stacked_frames)
#Тест
agent.test("Models/Name_DQN", stacked_frames = stacked_frames)Записываем видео
from random import choice
from google.colab.patches import cv2_imshow
import skvideo.io
out_video = np.empty([len(img_array), 240, 320, 3],
dtype = np.uint8)
out_video = out_video.astype(np.uint8)
for i in range(len(img_array)):
frame = img_array[i]
out_video[i] = frame
skvideo.io.vwrite("doom_defend_line.avi", out_video)Результат

