PHC7065 CRITICAL SKILLS IN DATA MANIPULATION FOR POPULATION SCIENCE

Big Data
Hui Hu Ph.D.
Department of Epidemiology
College of Public Health and Health Professions & College of Medicine
April 8, 2019
Introduction to Big Data
HDFS and MapReduce
Spark
Introduction to Big Data
Explosion of Data
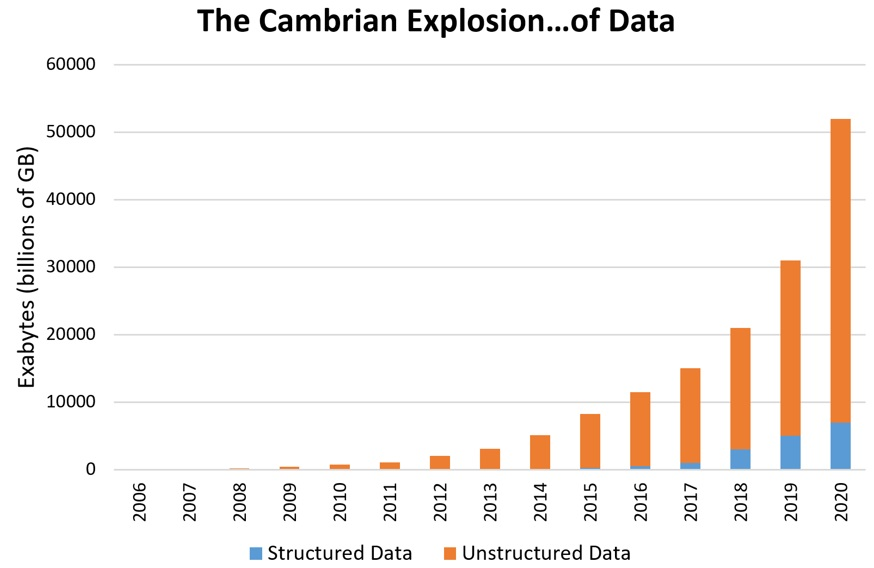
Explosion of Data (continued)
- The increase in amount of data we are generating opens up huge possibilities
- But it comes with problems too:
- where do we have to store all this data?
- and process it too?
Which one(s) of them do you consider as big data?
- Order details for a store
- All orders across hundreds of stores
- A person's stock portfolio
- All stock transactions for the NYSE
What is big data?
- How will you define big data?
- It's a very subjective term, and there is not one definition for big data
- Most people would certainly consider a dataset of several TB to be big data
- A reasonable definition:
Data that are too big to be processed on a single machine

Big data is a loosely defined term used to describe data sets so large and complex that they become awkward to work with using standard statistical software
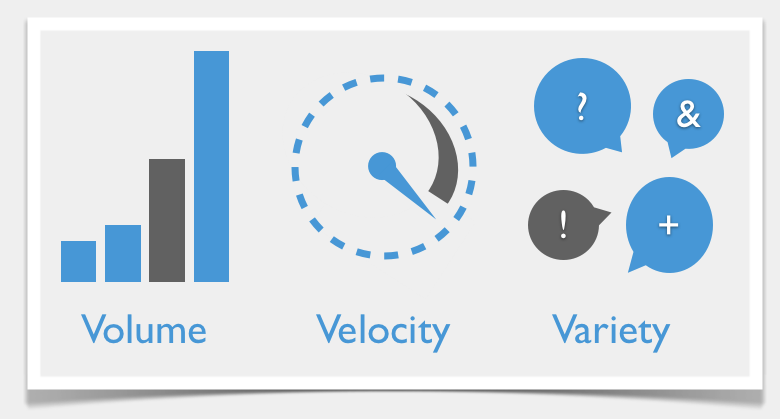
Challenges with Big Data
- Not just about the size
- Data is created fast
- Data from different sources in various formats
Volume
- Store the data
- which one(s) of the following data do you think worth storing?
transactions, logs, business, user, sensor, medical, social
- Read and process the data efficiently
Variety
- For a long time people stored data in relational databases
- The problem is that to store data in such databases, the data need to be able to fit in pre-defined tables
- Many data we are dealing nowadays are unstructured or semi-structured data
- We want to store the data in its original format so we are not throwing any information away
- e.g. transcribe a call center conversation into text
- we have what people said to customer services representatives
- but if we had the actual recording, later we may able to develop algorithms to interpret the tone of voice
Velocity
- We need to be able to store the data even it's coming in at a rate of TB per day
- if we can't store as it arrives, we have to discard some of the data
- Many recommendation systems were developed based on a variety of data stored which arrives with a high velocity
- Amazon will recommend products to you
- Netflix will recommend movies you might be interested in
Hadoop
- In around 2003, google published papers about their internally used distributed file systems and their processing framework, MapReduce.
- A group tried to reimplement these in open source, and they developed hadoop, which later becomes the core part of today's big data processing platforms
- Hadoop:
- store data: HDFS (Hadoop distributed file system)
- process data: MapReduce
- Data are split and stored in a collection of machines (a cluster), and then the data are processed in where they are stored rather than retrieving the data to a central server

Hadoop Ecosystem
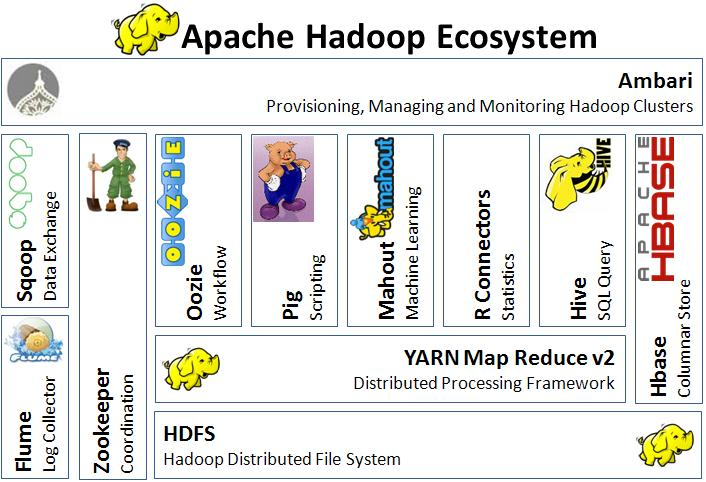
- Some softwares are intended to make it easier to load data into the Hadoop cluster
- Many are designed to make Hadoop easier to use
HDFS and MapReduce
HDFS
- Data are stored in HDFS: Hadoop distributed file system
dat.txt (150 MB)
64 MB
64 MB
22 MB
blk_1
blk_2
blk_3

blk_1
blk_2
blk_3
Datanodes
Namenode
Is there a problem?
blk_1
blk_2
blk_3
- Network failure
- Disk failure on datanodes
- Disk failure on the namenode
Data Redundancy
blk_1
blk_2
blk_3
Hadoop replicates each block three times
blk_1
blk_1
blk_2
blk_2
blk_3
blk_3
What if there is a problem with the namenode?
blk_1
blk_2
blk_3
- If a network failure: data inaccessible
- If a disk failure: data lost forever (no way to know which block belongs to which file)
blk_1
blk_1
blk_2
blk_2
blk_3
blk_3
NFS
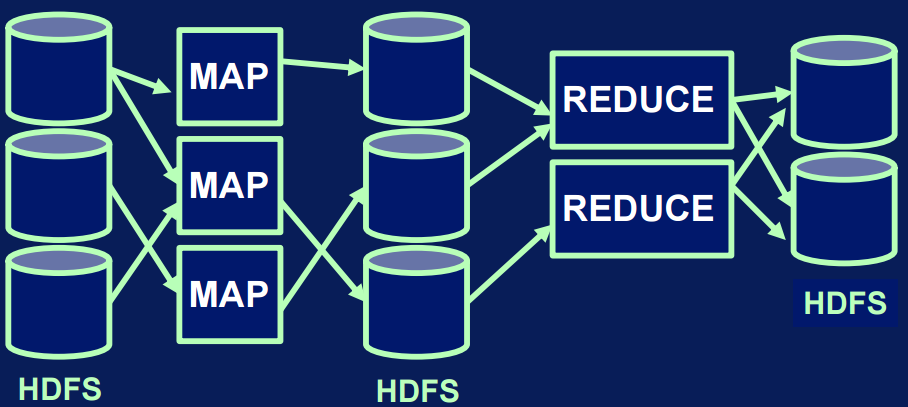
MapReduce
Designed to process data in parallel
Example
- National hospital inpatient cost
- want to calculate the cost per city for the year
| 2017-01-01 | Miami | 2300.24 |
| 2017-01-01 | Gainesville | 3600.23 |
| 2017-01-02 | Jacksonville | 1900.34 |
| 2017-01-02 | Miami | 8900.45 |
- Key-value pairs (Hashtable)
- What are the problems if you have 1 TB data?
- You may run out of memory, and computers will need a long time to read and process the data.
Example (continued)
Mappers
Miami
2300.24
NYC
9123.45
Boston
8123.45
LA
3123.45
Reducers
NYC, LA
Miami, Boston
NYC
7123.45
Boston
6123.45
NYC
7123.45
Boston
8123.45
Boston
6123.45
LA
3123.45
Miami
2300.24
NYC
9123.45
Example (continued)
Mappers
Intermediate records (key, value)
Shuffle and sort
Reducers
(key, value)
Results
blk_1
blk_2
blk_3
blk_1
blk_1
blk_2
blk_2
blk_3
blk_3
Job Tracker
Task Trackers
Code a MapReduce Problem
| date | time | store | item | cost | payment |
|---|---|---|---|---|---|
| 2012-01-01 | 12:01 | Orlando | Music | 13.98 | Visa |
How to find total sales per store? (what is the key-value pair)
import sys
def mapper():
for line in sys.stdin:
data = line.strip().split("\t")
if len(data) == 6:
date, time, store, item, cost, payment = data
print "{0}\t{1}".format(store, cost)Store, Cost
Code a MapReduce Problem
def reducer():
salesTotal = 0
oldKey = None
for line in sys.stdin:
data = line.strip().split("\t")
if len(data) != 2:
continue
thisKey, thisSale = data
if oldKey and oldKey != thisKey:
print "{0}\t{1}".format(oldkey, salesTotal)
salesTotal = 0
oldKey = thisKey
salesTotal += float(thisSale)
if oldKey != None:
print "{0}\t{1}".format(oldkey, salesTotal)
| NYC | 12.00 |
| NYC | 13.11 |
| LA | 11.23 |
| LA | 12.34 |
| LA | 11.98 |
Spark
Why Spark?
- Shortcomings of Hadoop MapReduce:
- only for map and reduce based computations
- relies on reading data from HDFS (many machine learning uses iterative algorithms that require several reads of the data, which result in a performance bottleneck due to I/O)
- native support for Java only
- no interactive shell support
- no support for streaming
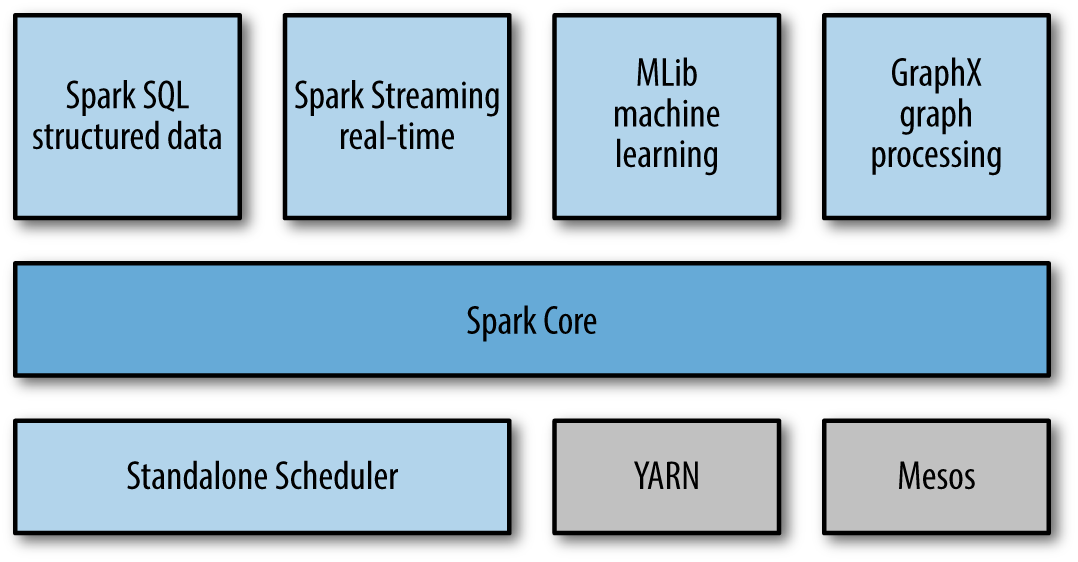
- Advantages of Spark:
- expressive programming model
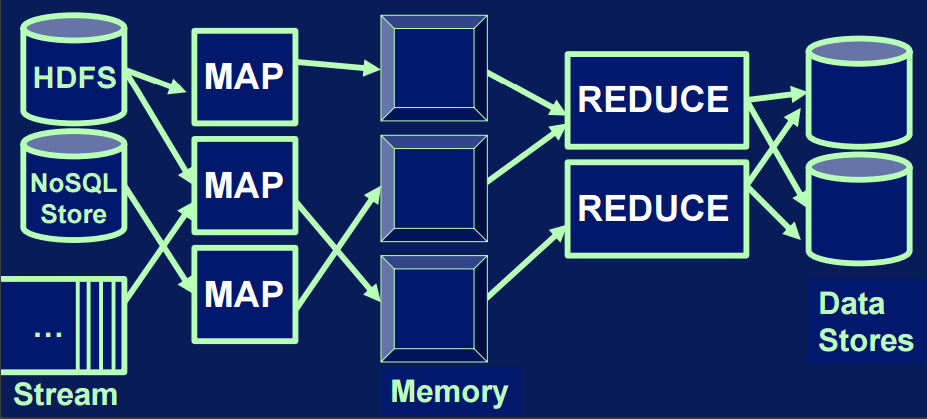
- in-memory processing
- support for diverse workloads
- interactive shell
The Spark Stack
What is in memory processing?
Resilient Distributed Datasets
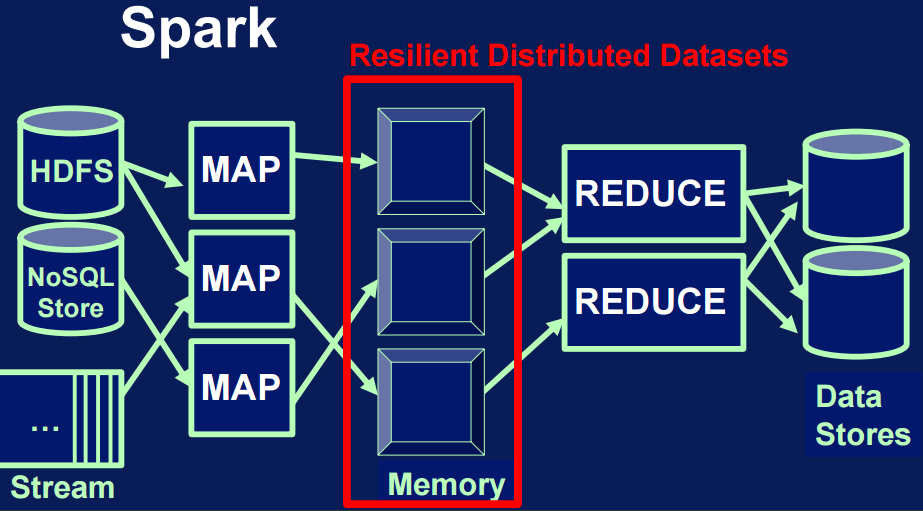
Resilient Distributed Datasets
- Resilient:
- recover from errors: e.g. node failure
- track history of each partition, re-run
- Distributed:
- distributed across the cluster of machines
- divided in partitions, atomic chunks of data
- Dataset:
- data storage created from HDFS, S3, HBase, JSON, text, local hierarchy of folders
- or created transforming another RDD (RDD is immutable)
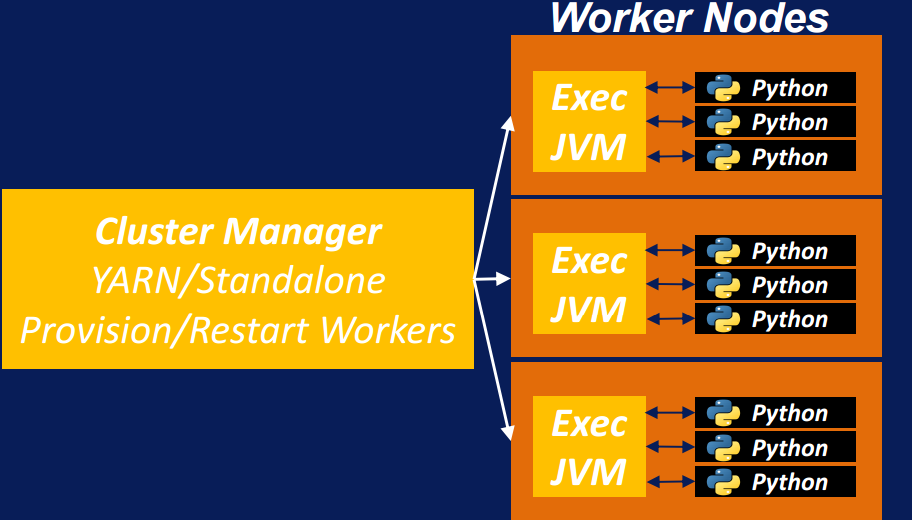
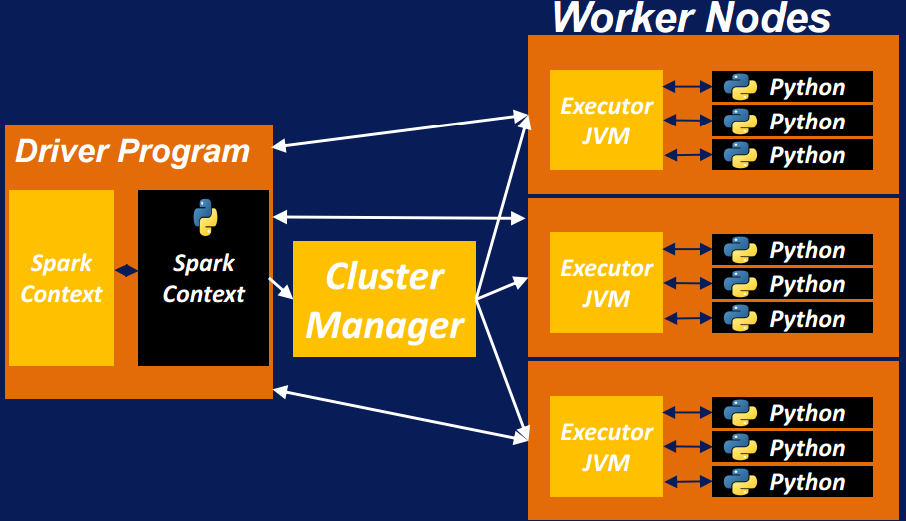
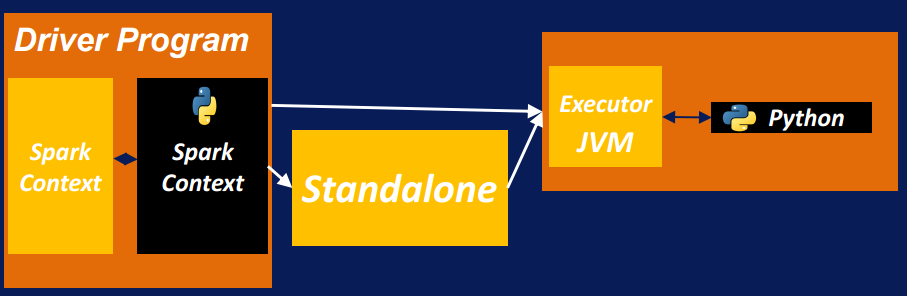
Spark Architecture
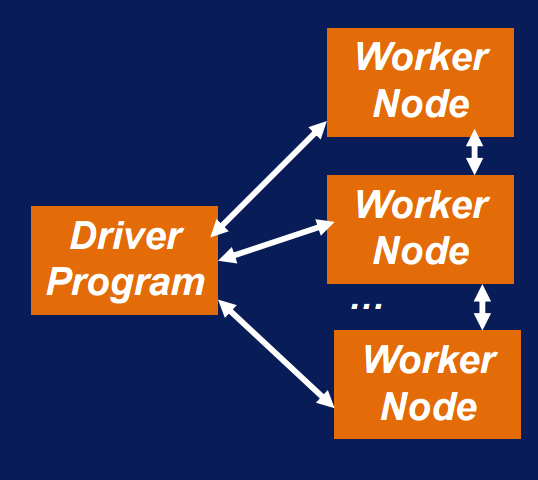
Spark Architecture (continued)
- Driver program:
- where the application starts
- it distributes the RDDs on cluster and make sure the transformation and actions of these RDDs are performed
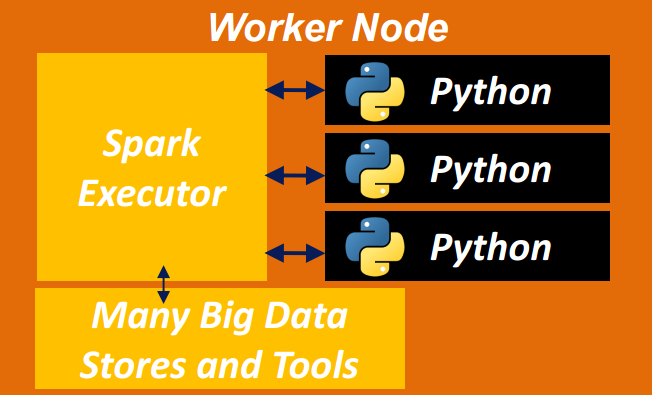
- Worker node:
- runs Java virtual machine (JVM) to call the executor
- executors can execute task related to mapping or reducing or other Spark specific pipelines