Speech Recognition
An introduction
Benjamin Akera
What is Speech
- Speech is a continuous signal ( No explicit word boundaries)
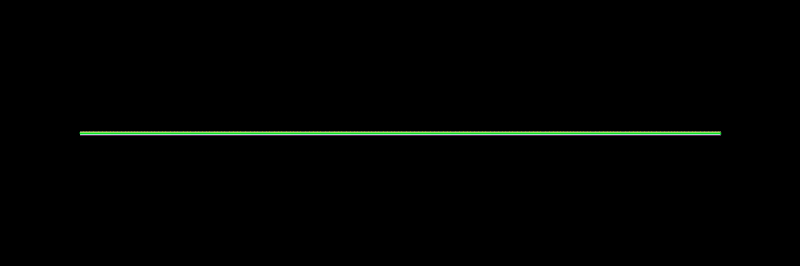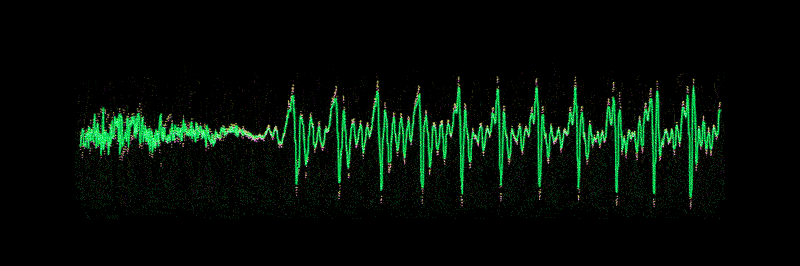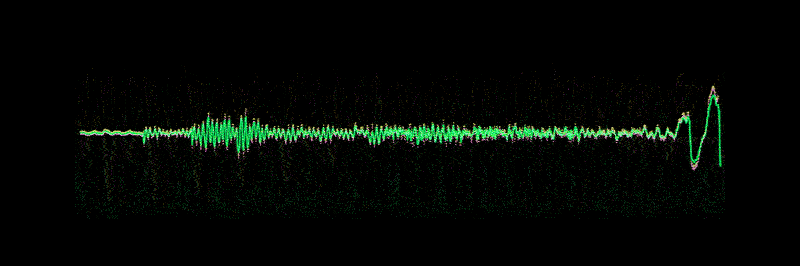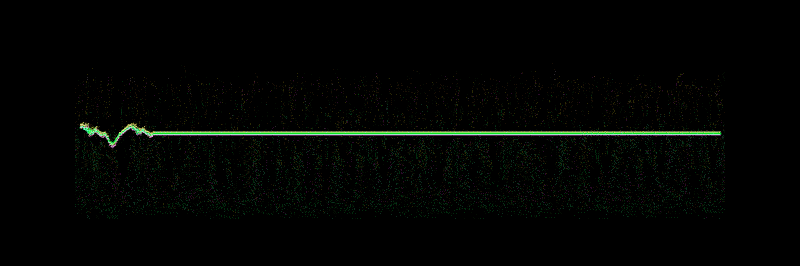
- Speech usually conveys a linguistic message that can be reduced to a transcript
- Can also be used for paralingustics: Speaker Identity, Speaker mood, speaker health condition, speaker accent etc

- Can be decomposed into elementary units of sound (phonemes) that distinguish one word from another in a particular language

Main Speech Tasks
- Speaker compression
- Speaker recognition (strong progress over the last 10 yrs but still poor compared to bio-metrics)
- Text to Speech Synthesis (can still gain in naturalness but new progress with Deep Learning
- Speech Para-linguistics (early days): Gender detection,age, deception, emotion etc
- Keyword spotting
Speech Recognition
Given speech audio, generate a transcript

Speech Recognizer
H
e
l
l
o
w
o
r
l
d
Important goal of AI: Historically hard for machines, easy for people
Traditional ASR pipeline
Traditional systems break the problem into several key components:
Audio Wave
Feature representation
Decoder
HMM/WFST)
Acoustic Model
Language model
Gales & Young, 2008
Jurafsky & Martin, 2000
Traditional ASR pipeline
Usually represent words as a sequence of "phonemes"
Phenomes are the distinct units of sound that distinguish words
- They are quite approximate but standardized
- Some labelled corpora available (eg TIMIT)
Challenges of Traditional ASR
- Highly tweak-able but hard to get working well
- Additional need for a pronunciation dictionary and language model
- Historically, each part of the system has its own set of challenges.
- eg. Choosing feature representation
Deep Learning in ASR
Where to apply deep learning to make ASR better?
- Good start: Improve acoustic model
- Introduction of pre-training/DBN

Dahl et al. 2011
Sound Data
Sound is transmitted as waves. How do we turn waves into numbers?
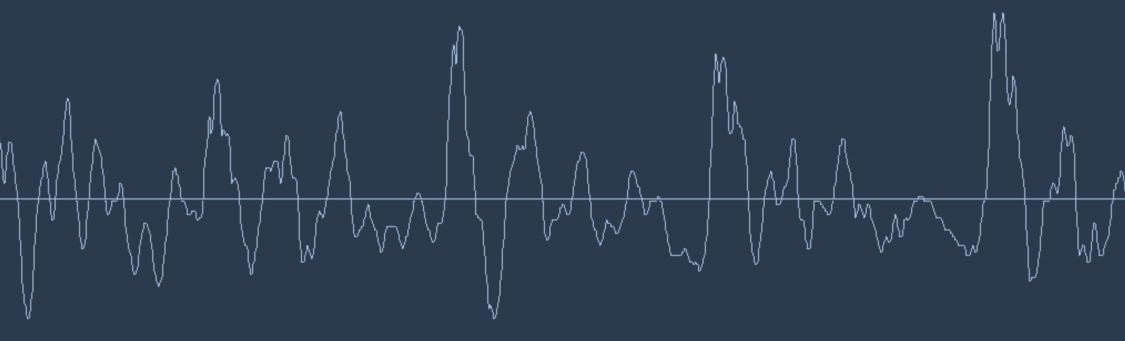
A wave form of "Hello"
Sound waves are one-dimensional.
At every moment in time, they have a single value based on the height of the wave.
Let’s zoom in on one tiny part of the sound wave and take a look:
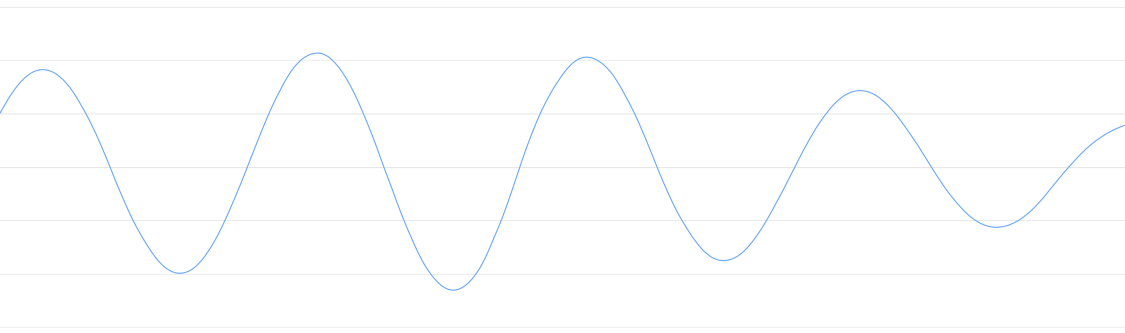
To turn this sound wave into numbers, we just record of the height of the wave at equally-spaced points:
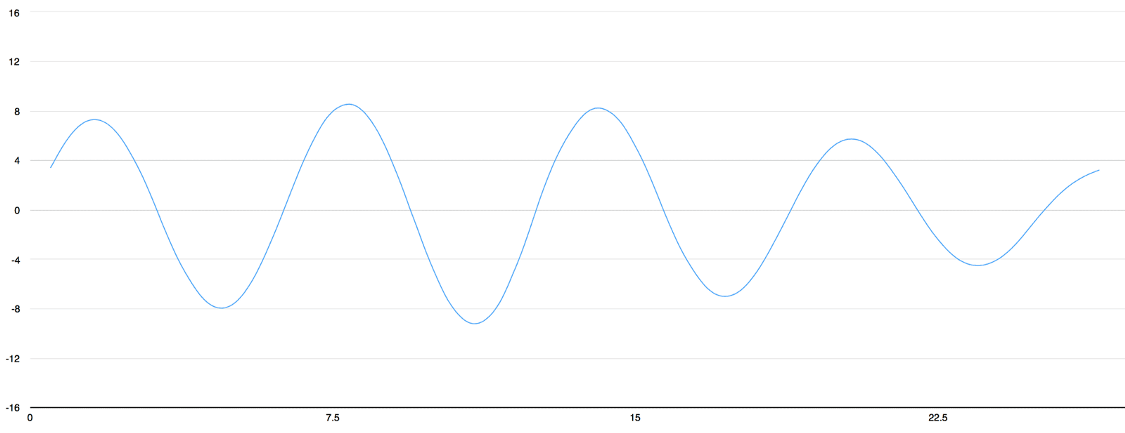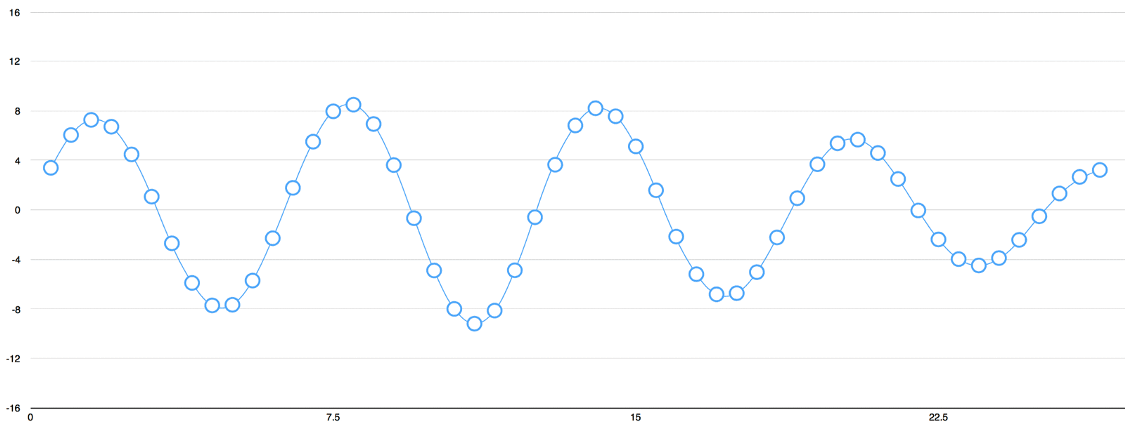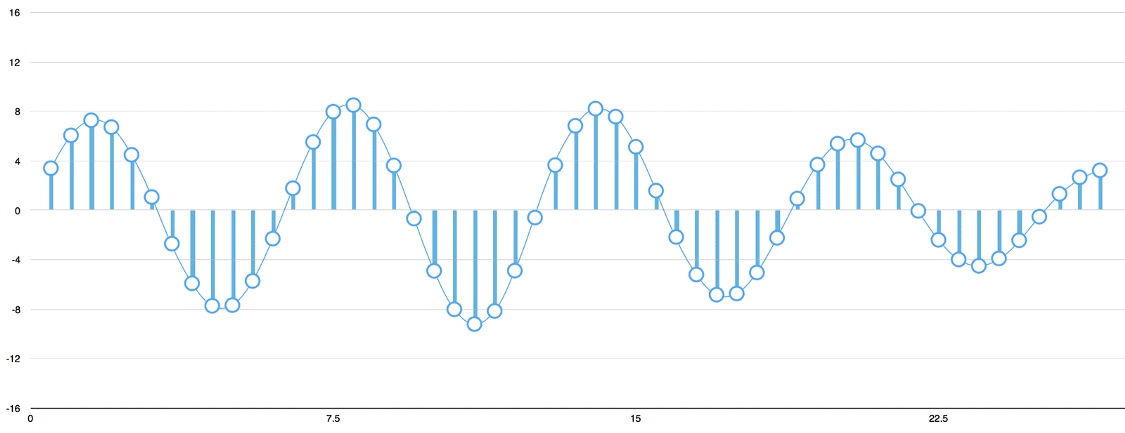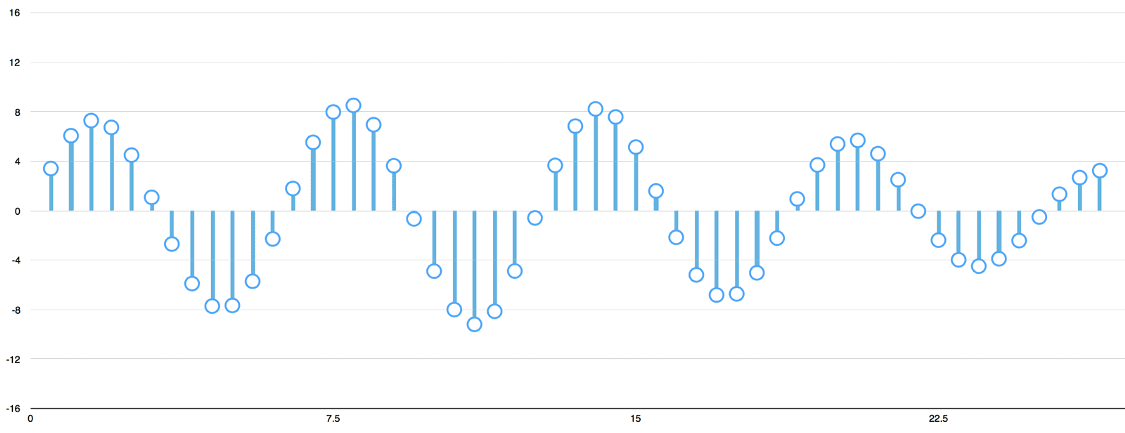
This is called Sampling
Pre-processing
Two ways to start:
- Minimally pre-process (e.g simple spectogram)
- Train model from raw audio wave
- We will use this
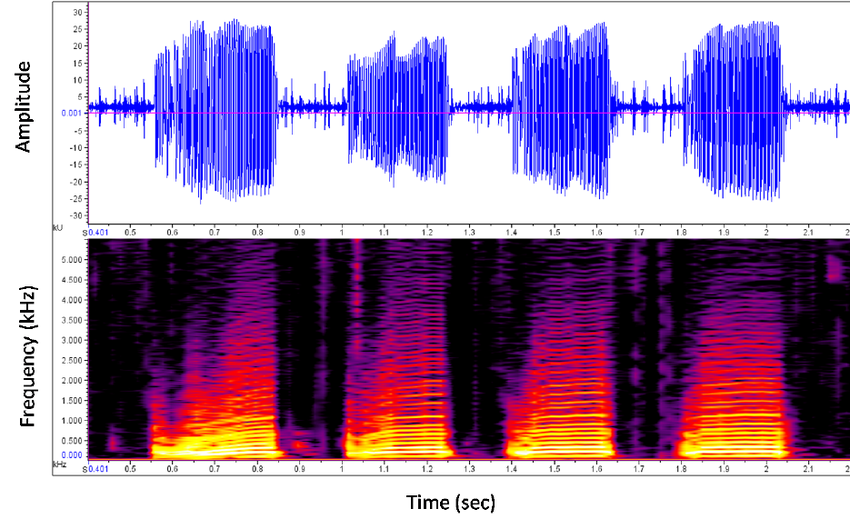
A spectrogram is a visual representation of the spectrum of frequencies of a signal as it varies with time
Fourier Transform
Breaks apart the complex sound wave into the simple sound waves that make it up. Once we have those individual sound waves, we add up how much energy is contained in each one.
The end result is a score of how important each frequency range is, from low pitch (i.e. bass notes) to high pitch
Spectogram
- Take a small window (e.g 20ms) of waveform
- Compute FFT and take magnitude (ie Power)
- Describes frequency content in local window


Concatenate frames from adjacent windows to form a "spectogram"
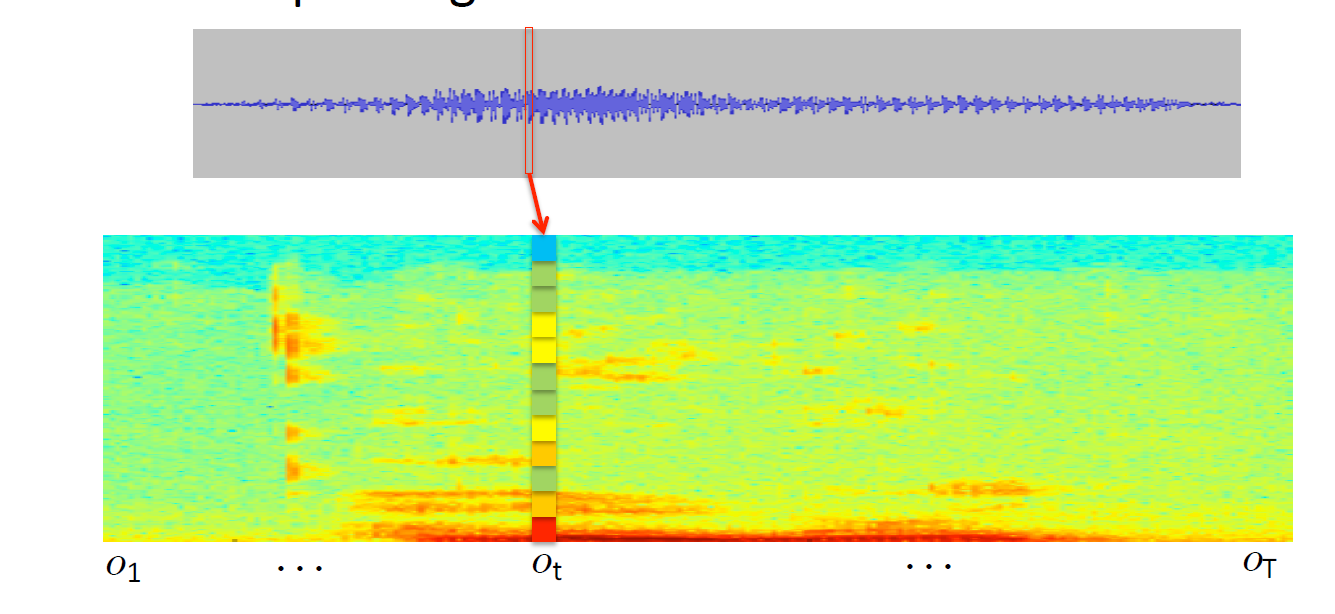
Acoustic models
- Goal: Create a neural network from which we can extract transcription, y.
- Train from labelled pairs (x, y*)

- Main Issue: length(x) != length(y)
- We dont know how symbols in y map to frames of audio
- Traditionally, try to bootstrap alignment (painful)
- Ways to resolve
- Use attention, Sequence 2 Sequence models, etc [Chan et al. 2015, Bahdanu et al.2015)
- Connectionist Temporal Classification (Graves et al 2016)
Applying techniques to Radio Surveillance
Over 300 radio stations are registered in Uganda.
In its 2015 third quarter report, the regulator, UCC
revealed that 292 FM stations were operational
Goal:
To build an iterable Keyword spotting model for Automated Crop Disease and Pest Surveillance in Uganda from radio data
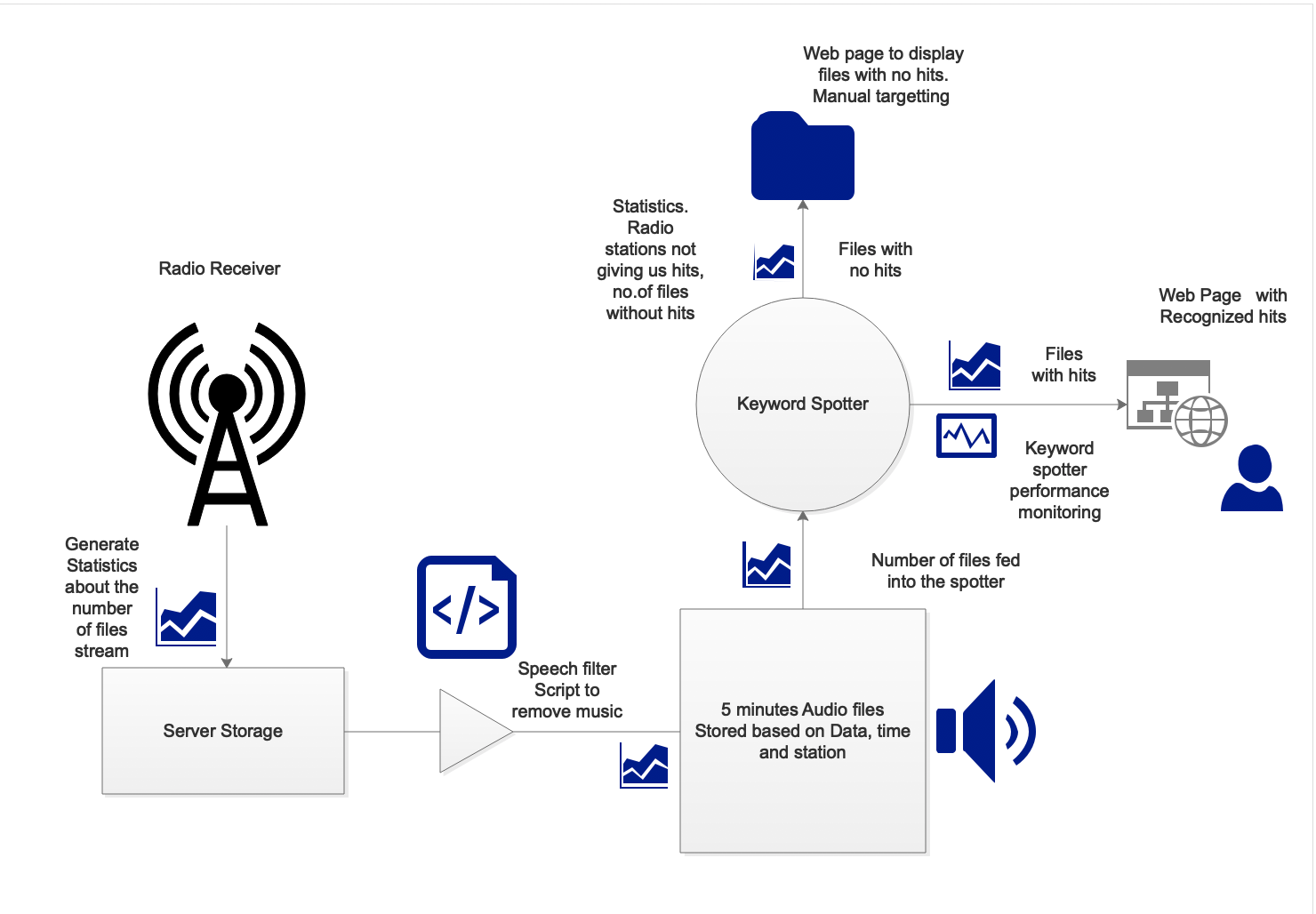
Pipeline
Dataset consists of keywords that occur often in Agricultural talkshows

Next step is to Obtain Audio waveforms of Each Keyword

If you'd like to Donate your voice:
https://rcrops.github.io
Conclusion
- A lot of ways we can use speech technology for local problems
- Data is key to speech, the technology is available
- Reading groups?
Thank you
akeraben@gmail.com