Simulation-based inference
Boomers Quantified Uncertainty. We Simulate It
[Video Credit: N-body simulation Francisco Villaescusa-Navarro]
IAIFI Fellow
Carolina Cuesta-Lazaro

IAIFI Summer School
Why should I care?
Decision making
Decision making in science
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Is the current Standard Model ruled out by data?
Mass density
Vacuum Energy Density
CMB
Supernovae

Observation
Ground truth
Prediction
Uncertainty
Is it safe to drive there?
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference

Better data needs better models
Interpretable Simulators

Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Uncertainties are everywhere

Noise in features
+ correlations
Noise in finite data realization
Uncertain parameters
Limited model architecture
Imperfect optimization

Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Ensembling / Bayesian NNs
Forward Model
Observable
Dark matter
Dark energy
Inflation
Predict
Infer
Parameters
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Inverse mapping

Fault line stress
Plate velocity
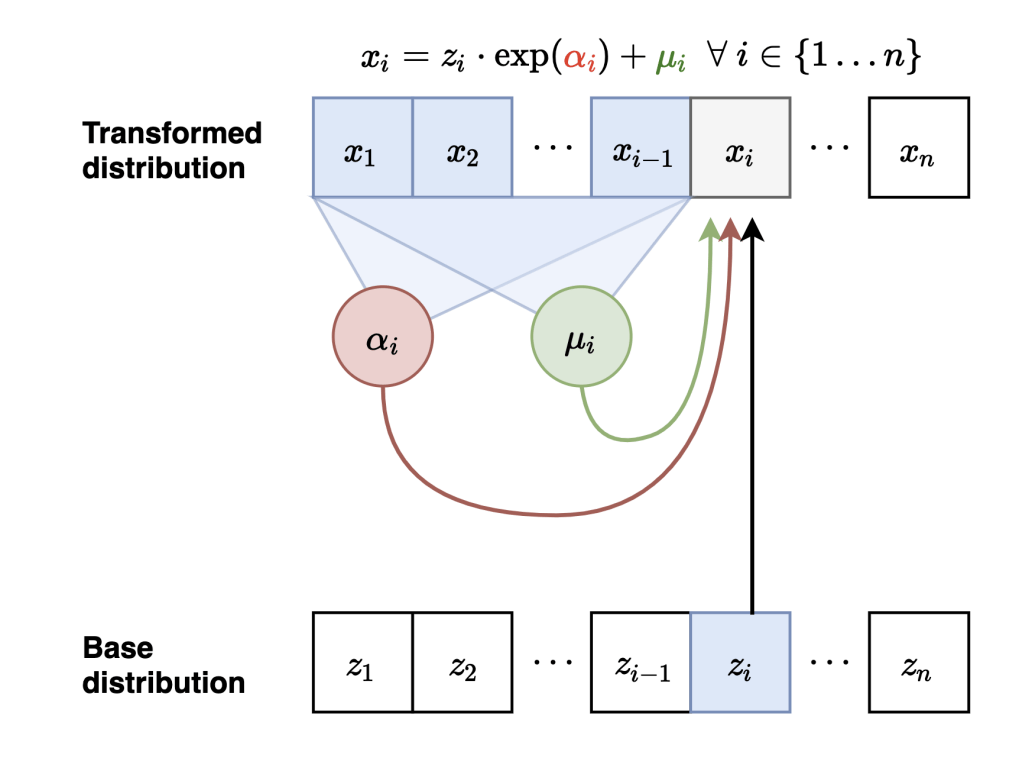
Variational
Posterior
Likelihood
Posterior
Prior
Evidence
Markov Chain Monte Carlo MCMC
Hamiltonian Monte Carlo HMC
Variational Inference VI
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
If can evaluate posterior (up to normalization), but not sample
Intractable
Unknown likelihoods
Amortized inference
Scaling high-dimensional
Marginalization nuisance
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Image Credit: Chi Feng mcmc demo

Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
["Polychord: nested sampling for cosmology" Handley et al]
["Fluctuation without dissipation: Microcanonical Langevin Monte Carlo" Robnik and Seljak]

The price of sampling
Higher Effective Sample Size (ESS) = less correlated samples
Number of Simulator Calls
Known likelihood
Differentiable simulators
The simulator samples the likelihood
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference

z: All possible trajectories

Maximize the likelihood of the training samples
Model
Training Samples
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Neural Likelihood Estimation NLE

NLE
No implicit prior
Not amortized
Goodness-of-fit
Scaling with dimensionality of x
Implicit marginalization
Neural Posterior Estimation NPE
Loss Approximate variational posterior, q, to true posterior, p

Image Credit: "Bayesian inference; How we are able to chase the Posterior" Ritchie Vink
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
KL Divergence
Need samples from true posterior
Run simulator
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Minimize KL
Amortized Inference!
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Run simulator
Neural Posterior Estimation NPE
Neural Compression
High-Dimensional
Low-Dimensional
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
s is sufficient iif
Neural Compression: MI
Maximise
Mutual Information
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Need true posterior!
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
NLE
No implicit prior
Not amortized
Goodness-of-fit
Scaling with dimensionality of x
NPE
Amortized
Scales well to high dimensional x
Goodness-of-fit
Fixed prior
Implicit marginalization
Implicit marginalization
Do we actually need Density Estimation?
Just use binary classifiers!
Binary cross-entropy
Sample from simulator
Mix-up
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Likelihood-to-evidence ratio
Likelihood-to-evidence ratio
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Classifier logits
Classifier logits
log(Likelihood-to-evidence ratio)
NLE
No implicit prior
Not amortized
Goodness-of-fit
Scaling with dimensionality of x
NPE
NRE
Amortized
Scales well to high dimensional x
Goodness-of-fit
Fixed prior
Implicit marginalization
No need variational distribution
No implicit prior
Implicit marginalization
Approximately normalised
Not amortized
Implicit marginalization
Density Estimation 101
Maximize the likelihood of the training samples
Model
Training Samples

Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Trained Model
Evaluate probabilities


Low Probability
High Probability

Generate Novel Samples
Simulator
Simulator
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Normalizing flows
[Image Credit: "Understanding Deep Learning" Simon J.D. Prince]
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Bijective
Sample
Evaluate probabilities
Probability mass conserved locally
Image Credit: "Understanding Deep Learning" Simon J.D. Prince
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Masked Autoregressive Flows
Neural Network
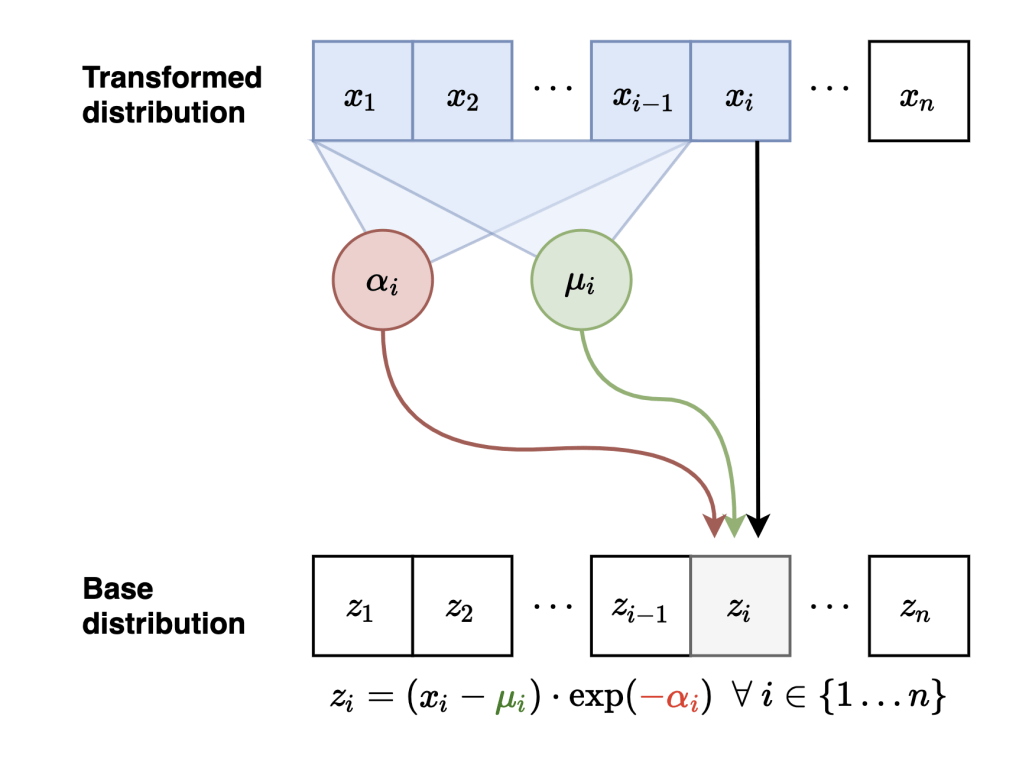
Sample
Evaluate probabilities
Continuity equation
[Image Credit: "Understanding Deep Learning" Simon J.D. Prince]
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Continuous time Normalizing flows
Need to solve this expensive integral at each step during training to maximise likelihood!
Very slow -> Difficult to scale to high dims
Can we avoid it?
Restricted trajectories: flow matching / diffusion
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Flow matching
Regress the velocity field directly!


[Image Credit: "An Introduction to flow matchig" Tor Fjelde et al]
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
["Flow Matching for Generative Modeling" Lipman et al]
["Stochastic Interpolants: A Unifying framework for Flows and Diffusions" Albergo et al]
Conditional Flow matching
Assume a conditional vector field (known at training time)
The loss that we can compute
The gradients of the losses are the same!
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
["Flow Matching for Generative Modeling" Lipman et al]
["Stochastic Interpolants: A Unifying framework for Flows and Diffusions" Albergo et al]
Intractable
Flow Matching
Continuity equation
[Image Credit: "Understanding Deep Learning" Simon J.D. Prince]
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Sample
Evaluate probabilities
Diffusion models
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
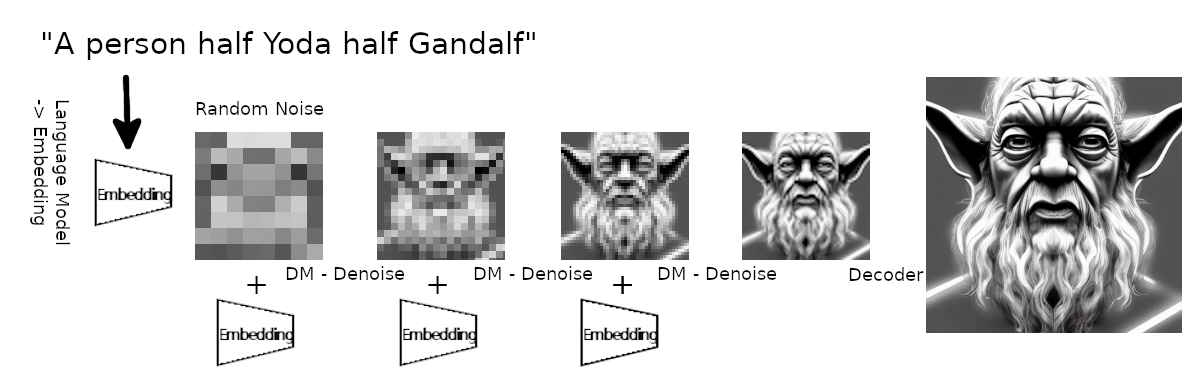
Reverse diffusion: Denoise previous step
Forward diffusion: Add Gaussian noise (fixed)

["A point cloud approach to generative modeling for galaxy surveys at the field level"
Cuesta-Lazaro and Mishra-Sharma
arXiv:2311.17141]

Siddharth Mishra-Sharma
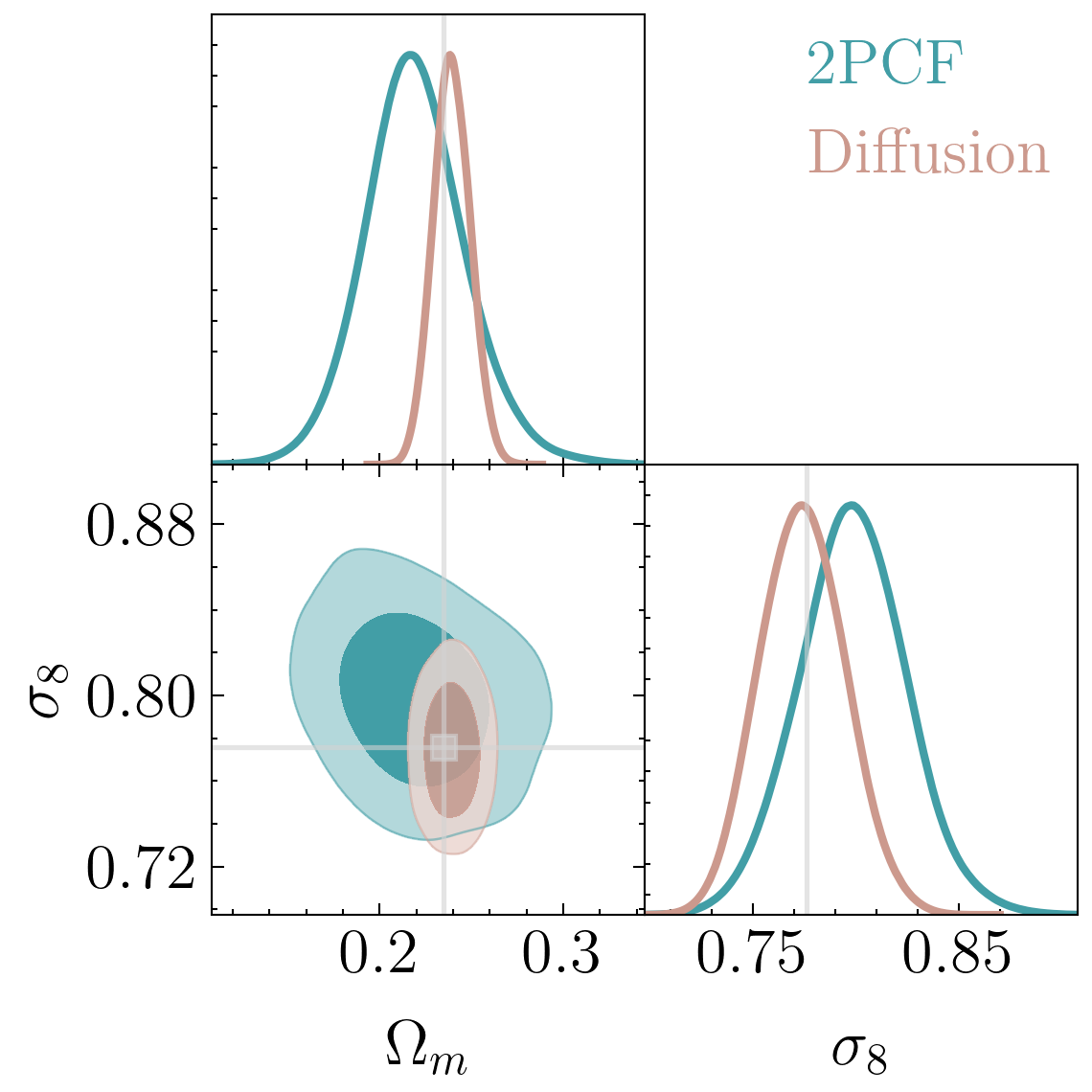
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Galaxies as point clouds
NLE
No implicit prior
Not amortized
Goodness-of-fit
Scaling with dimensionality of x
NPE
NRE
Amortized
Scales well to high dimensional x
Goodness-of-fit
Fixed prior
Implicit marginalization
No need variational distribution
No implicit prior
Implicit marginalization
Approximately normalised
Not amortized
Implicit marginalization
How good is your posterior?
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Test log likelihood
["Benchmarking simulation-based inference"
Lueckmann et al
arXiv:2101.04653]
Posterior predictive checks

Observed
Re-simulated posterior samples
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Classifier 2 Sample Test (C2ST)

Real or Fake?
Benchmarking SBI
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
["Benchmarking simulation-based inference"
Lueckmann et al
arXiv:2101.04653]

Classifier 2 Sample Test (C2ST)
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
["A Trust Crisis In Simulation-Based Inference? Your Posterior Approximations Can Be Unfaithful" Hermans et al
arXiv:2110.06581]

Much better than overconfident!
Coverage: assessing uncertainties
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
["A Trust Crisis In Simulation-Based Inference? Your Posterior Approximations Can Be Unfaithful" Hermans et al
arXiv:2110.06581]
Credible region (CR)
Not unique
High Posterior Density region (HPD)
Smallest "volume"

True value in CR with
probability

Empirical Coverage Probability (ECP)
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference

["Investigating the Impact of Model Misspecification in Neural Simulation-based Inference" Cannon et al arXiv:2209.01845 ]
Underconfident
Overconfident
Expected Coverage Probability (ECP)
Hard to find in high dimensions!

U
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference

Underconfident
Overconfident
["Sampling-Based Accuracy Testing of Posterior Estimators for General Inference" Lemos et al arXiv:2302.03026]
["Investigating the Impact of Model Misspecification in Neural Simulation-based Inference" Cannon et al arXiv:2209.01845 ]
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Calibrated doesn't mean informative!
Always look at information gain too
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
["A Trust Crisis In Simulation-Based Inference? Your Posterior Approximations Can Be Unfaithful" Hermans et al
arXiv:2110.06581]

["Calibrating Neural Simulation-Based Inference with Differentiable Coverage Probability" Falkiewicz et al
arXiv:2310.13402]
["A Trust Crisis In Simulation-Based Inference? Your Posterior Approximations Can Be Unfaithful" Hermans et al
arXiv:2110.06581]
Sequential SBI
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
["Benchmarking simulation-based inference"
Lueckmann et al
arXiv:2101.04653]

[Image credit: https://www.mackelab.org/delfi/]Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Sequential SBI
Sequential Neural Likelihood Estimation
["Sequential Neural Likelihood: Fast Likelihood-free Inference with Autoregressive Flows" Papamakarios et al
arXiv:1805.07226]
Proposal (different from prior)
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
SNLE
["Fast -free Inference of Simulation Models with Bayesian Conditional Density Estimation" Papamakarios et al
arXiv:1605.06376]
["Flexible statistical inference for mechanistic models of neural dynamics." Lueckmann et al
arXiv:1711.01861]
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
Sequential can't be amortized!
Sequential Neural Posterior Estimation
SNPE
Proposal (different from prior)
Real life scaling: Gravitational lensing
["A Strong Gravitational Lens Is Worth a Thousand Dark Matter Halos: Inference on Small-Scale Structure Using Sequential Methods" Wagner-Carena et al arXiv:2404.14487]
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference


Current SBI limitations
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference

["All-in-one simulation-based inference" Gloeckler et al arXiv:2404.09636]
Model all conditionals at once!
All-in-one: The Simformer
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference

["All-in-one simulation-based inference" Gloeckler et al arXiv:2404.09636]

Score based diffusion model with sampled conditional masks
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference










Model mispecification
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference

["Investigating the Impact of Model Misspecification in Neural Simulation-based Inference" Cannon et al arXiv:2209.01845]
More misspecified
SBI Resources
Carolina Cuesta-Lazaro IAIFI/MIT - Simulation-Based Inference
"The frontier of simulation-based inference" Kyle Cranmer, Johann Brehmer, and Gilles Louppe
Github repos
Review

cuestalz@mit.edu

Book
"Probabilistic Machine Learning: Advanced Topics" Kevin P. Murphey
