Reinforcement Learning:
Classical Foundations and the LLM era
Flatiron Institute
Carol(ina) Cuesta-Lazaro



TD-GAMMON
1992

2013
DQN
2016
AlphaGo
AlphaGo
ChatGPT
(RLHF)
2022
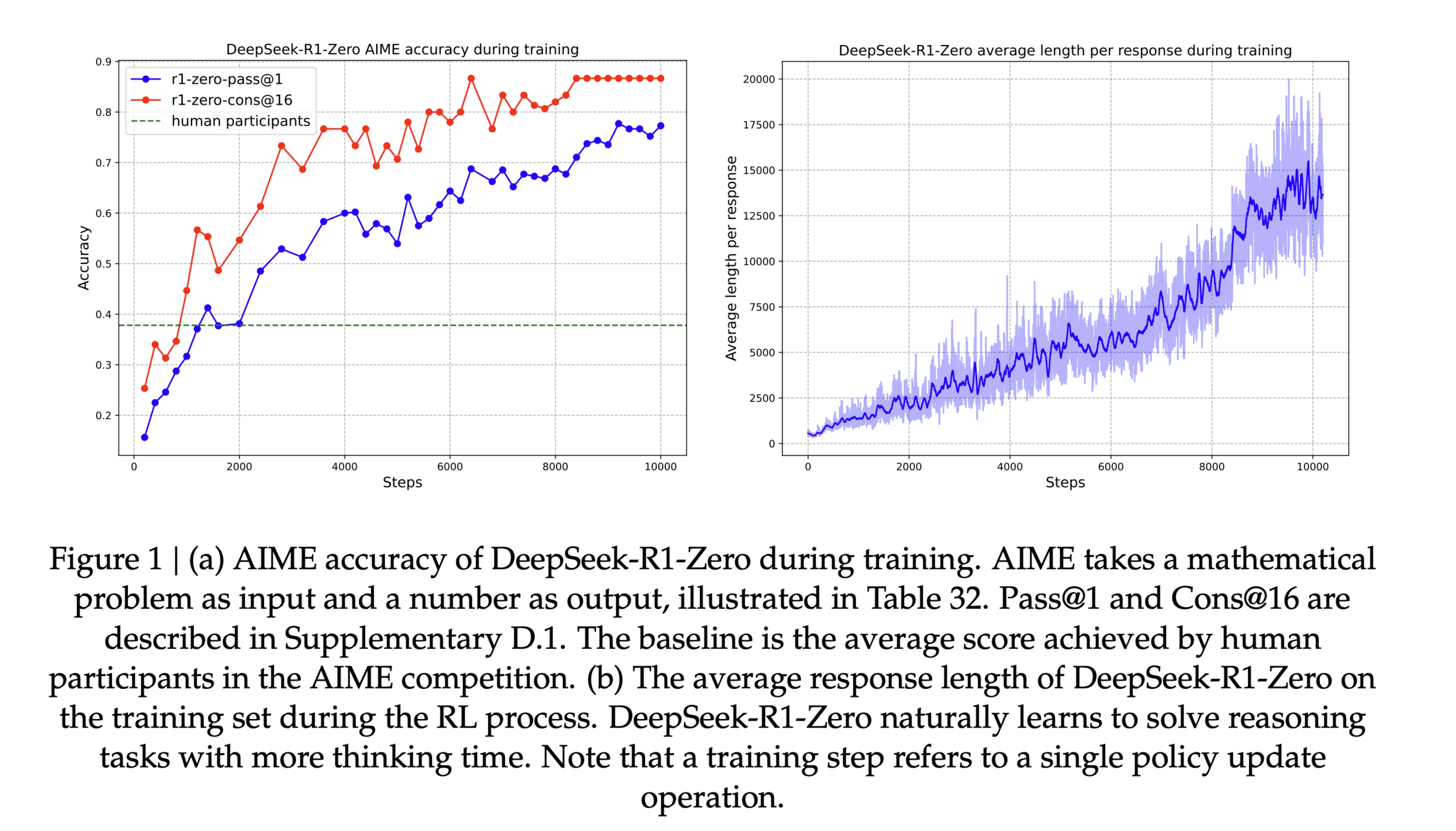
Reasoning (RLVR)
2025
Hide And Seek
2019

Agent

Environment
State

Action
s_t
s_{t+1}
a_t \sim \Pi_\theta(s_t)
Reward
R_t
Policy
RL vs Supervised Learning
- In RL the data distribution is changing
- Reward signal is evaluative, not instructive
- Very stochastic outcomes
- Trade off between exploration and exploitation
The agent generates its own training data by acting
Should I do what's worked before, or try something new?
Tells you how good, not what was right
- Delayed Feedback
The consequence of an action may only show up many steps later
The Learning Problem
\frac{\partial R}{\partial \theta} = \frac{\partial R}{\partial s_T} \cdot \frac{\partial s_T}{\partial a_{T-1}} \cdot \frac{\partial a_{T-1}}{\partial s_{T-1}} \cdots \frac{\partial a_0}{\partial \theta}
State
s_{t-1}
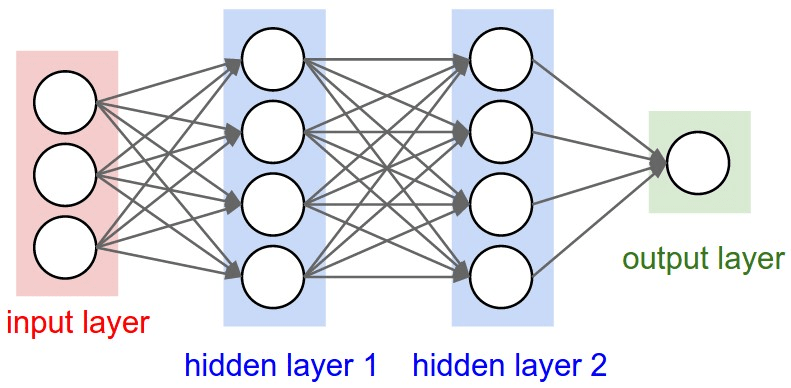
Policy Network
Environment
Reward
s_{t}
Not Differentiable!
a_t \sim \Pi_\theta(s_{t-1})
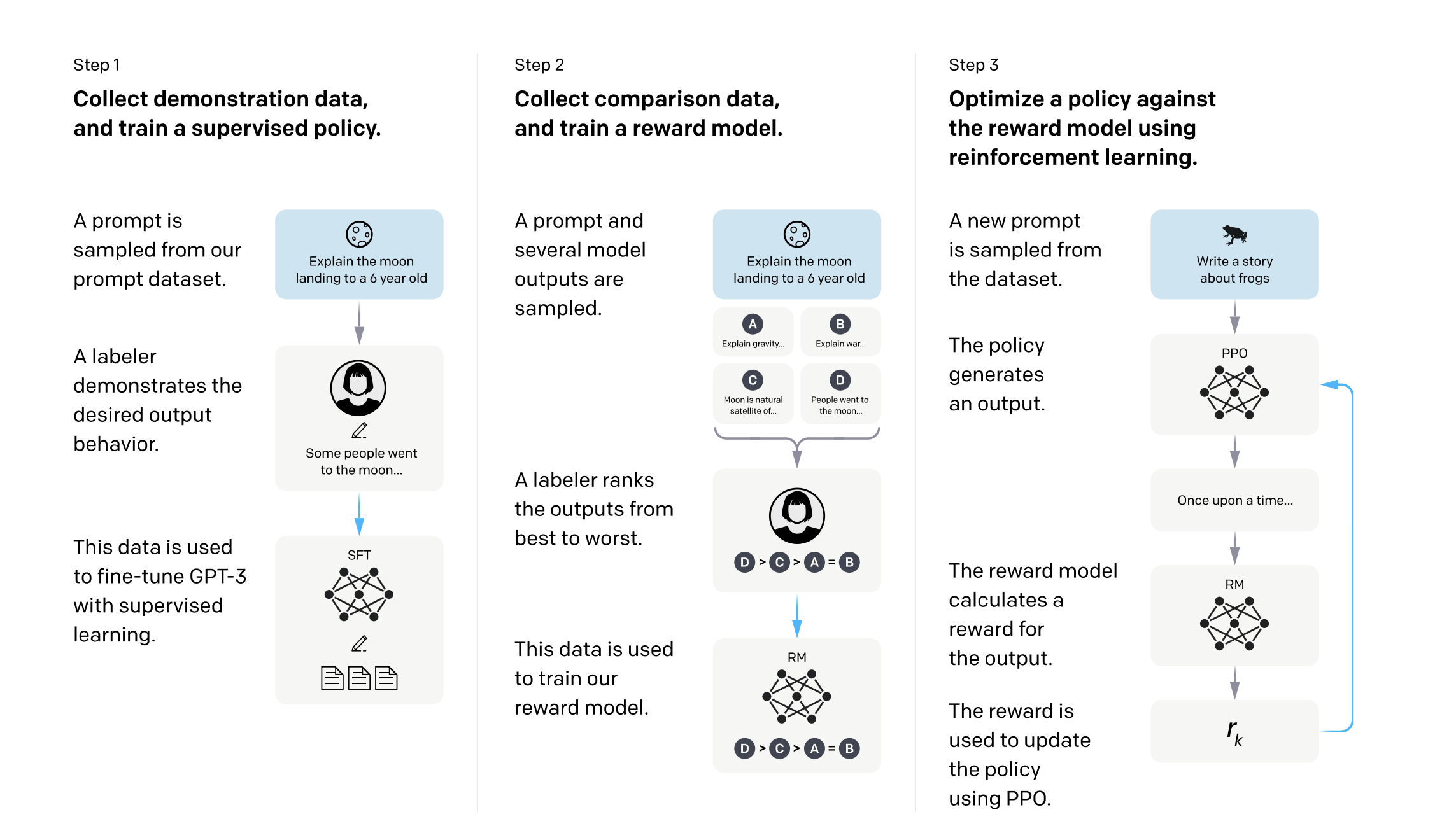
Reinforcement Learning from Human Feedback (RLHF)
Reinforcement Learning from Verifiable Rewards (RLVR)

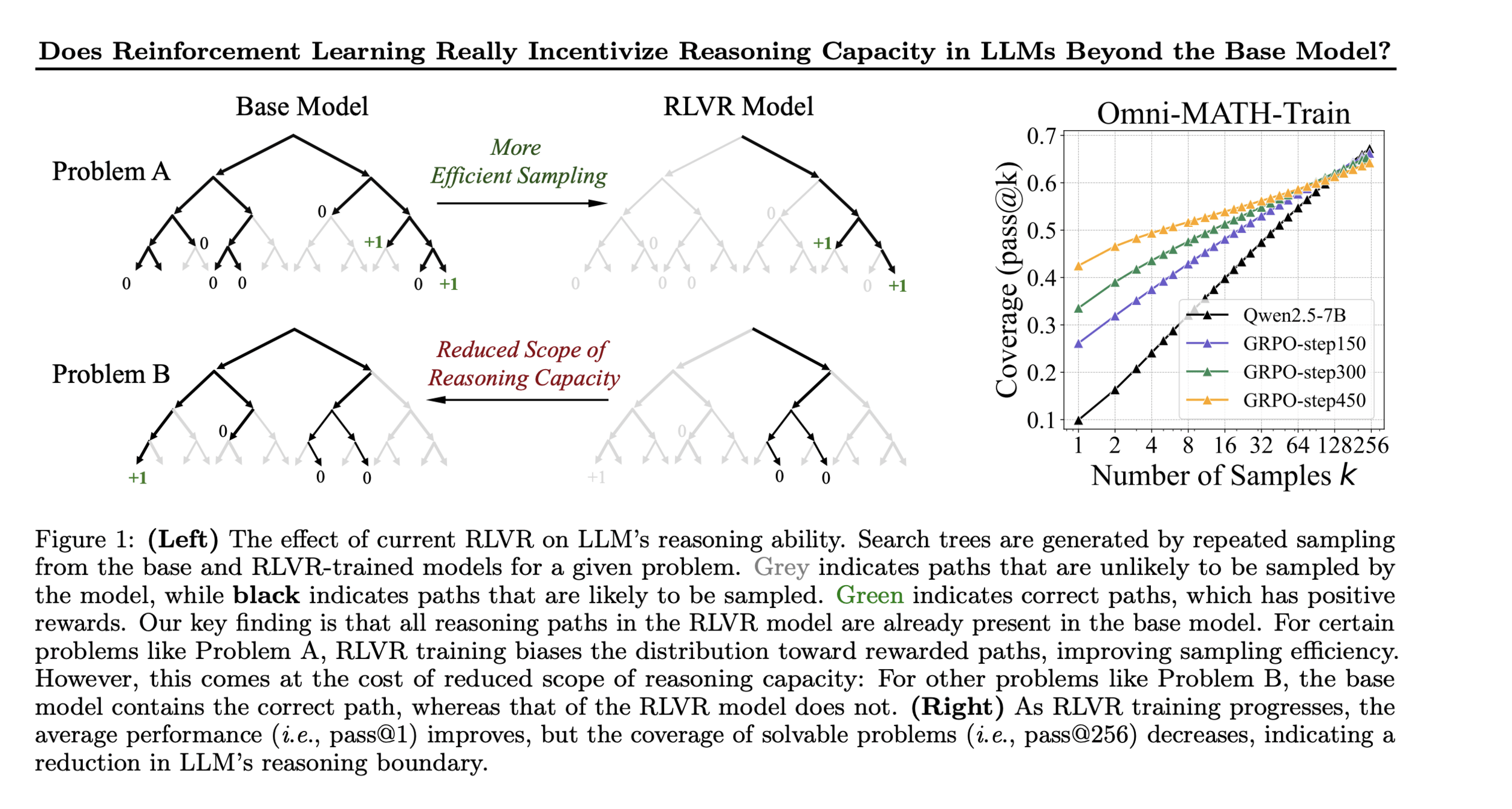
https://arxiv.org/pdf/2504.13837
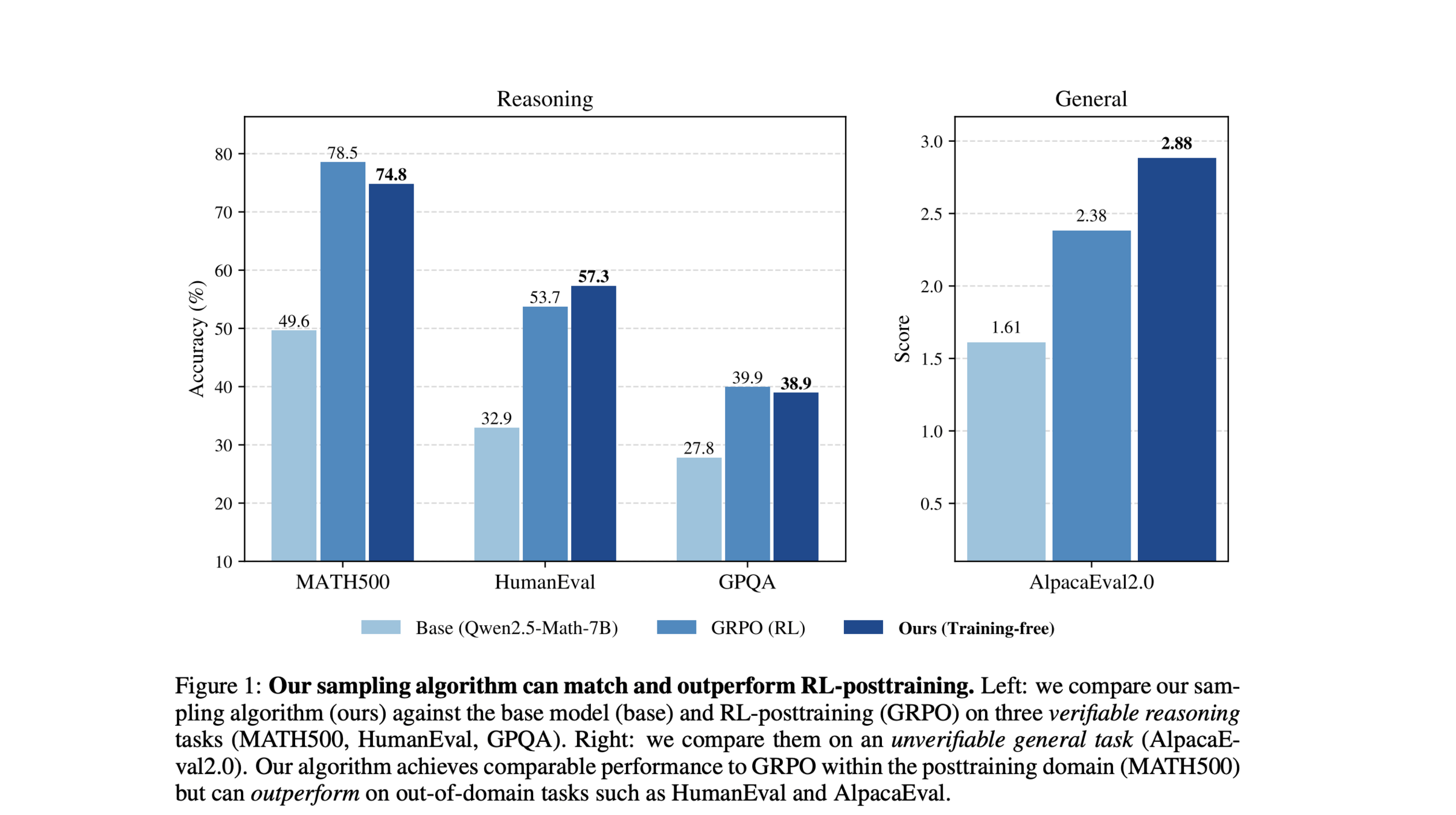
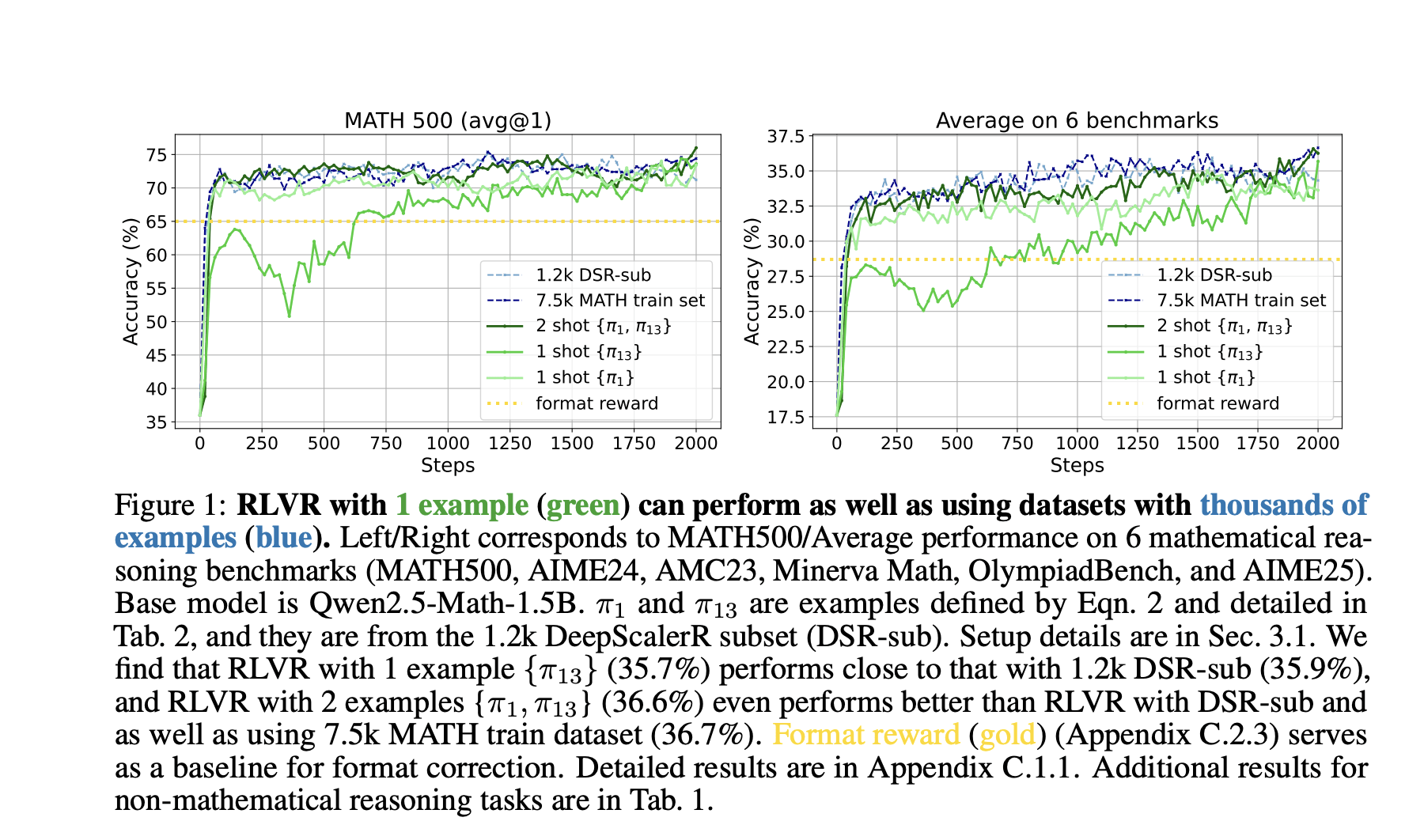
Are models learning something new via RL?
https://arxiv.org/pdf/2510.14901
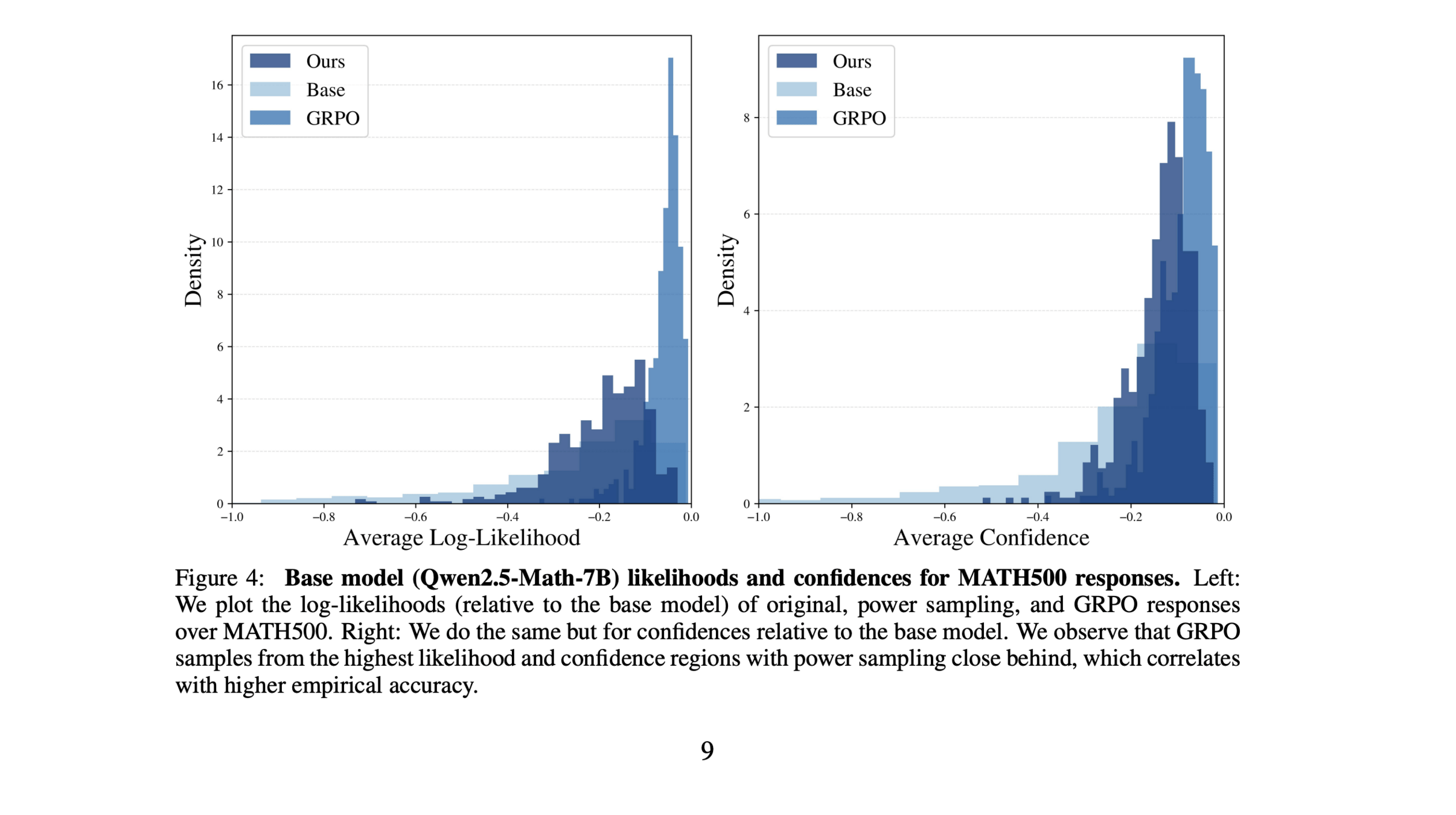
Are high likelihood responses more correct?
Solving Long Horizon Reasoning Problems


Resources
Tutorial: Lunar Lander
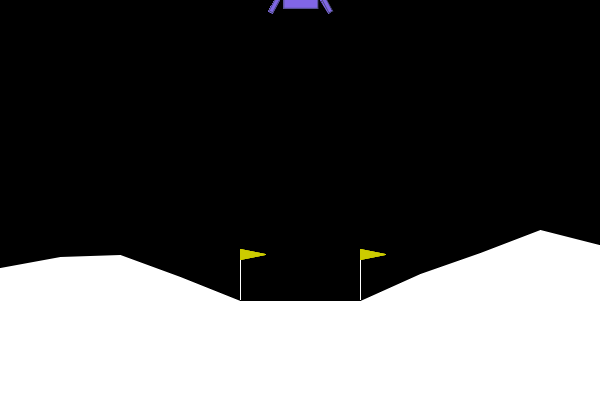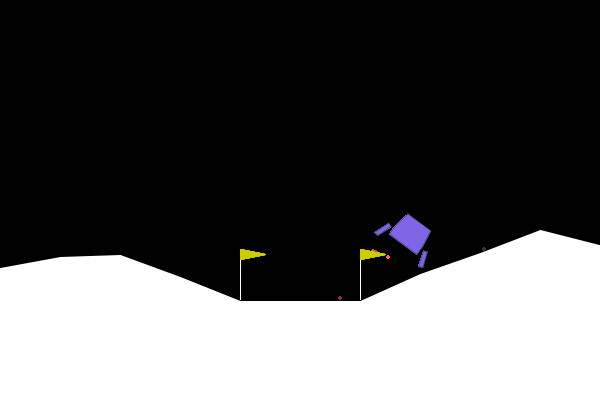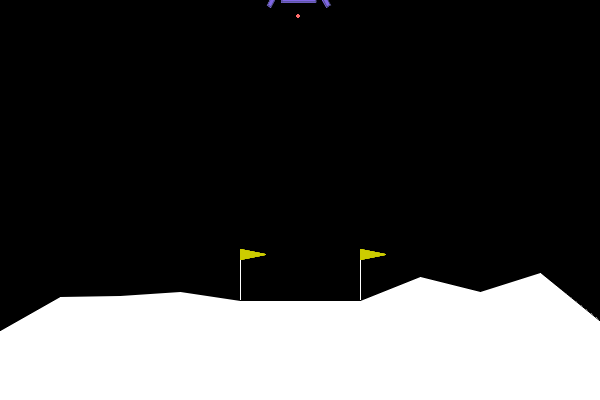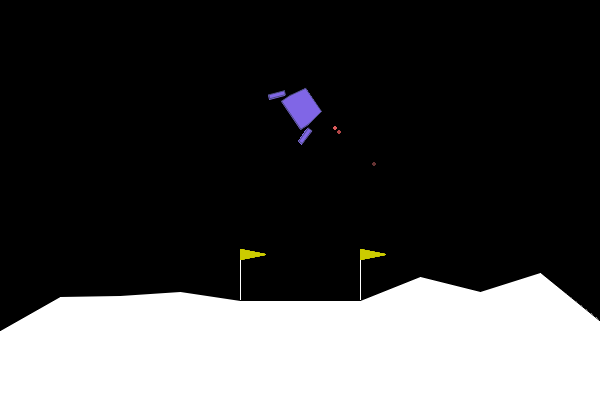
0: Do nothing
1: fire left engine
2: fire main engine
3: fire right engine
Actions
State
(x, y, vx, vy, angle, angular_velocity, left_leg_contact, right_leg_contact)The Reinforce Algorithm
\begin{array}{l}
\text{Initialize } \theta \\
\textbf{repeat:} \\
\quad \text{Sample } \tau_1, \ldots, \tau_N \sim \pi_\theta \\
\quad \hat{g} \leftarrow \frac{1}{N} \sum_i r(\tau_i) \sum_t \nabla_\theta \log \pi_\theta(a_t | s_t) \\
\quad \theta \leftarrow \theta + \alpha \hat{g}
\end{array}