DevOps
CI / CD
Cédric BRASSEUR
(Mis à jour le 07/03/2026)
Cédric BRASSEUR
- Ancien étudiant de l'Exia.cesi
- 4 ans consultant chez Amaris, placé chez Euro Information Dev
- Auto-entrepreneur depuis début 2020 (Création de sites web, applications mobiles & formateur)
Et vous ?
- Nom, prénom
- Etudes réalisées
- Utilisation de git & / ou CI/CD en entreprise ?
- Autres infos appréciées
Plan du cours
-
Introduction CI/CD en entreprise
Historique, objectifs
Le mouvement DevOps
-
Les gestionnaires de code source
Centralisé / Décentralisé
Prise en main de git
Les revues de code
-
Intégration en continue
Définition & étapes (build, lint, tests)
Les différents outils
Mise en place d'intégration continue avec github actions
-
Vérifier en continue
Les tests, leur utilité, l'implémentation et leur automatisation
L'analyse sécurité : audit et analyses automatisés
-
Déployer en continue
Objectifs et outils
- Introduction sur Docker et son utilisation
- Schéma récapitulatif CI / CD

CI/CD
Objectifs de la formation
- Comprendre l'intérêt d'un gestionnaire de code source et le mettre en application en équipe
- Appréhender l'intégration continue
- Tester de manière automatiser son application (sécurité, qualité et robustesse)
- Le déploiement continue

Introduction au déploiement continu au sein d'un SI
Les enjeux et le contexte pour une entreprise
Aujourd'hui, l'informatique a une place importante dans les entreprises et il est important de pouvoir accélérer tous les processus menant à la mise en production d'une évolution ou d'une nouveauté pour l'entreprise.
Les besoins changent en fonction du temps… Vos applications doivent suivre !

Objectifs
- Accélérer les processus répétitifs
- Eviter d'avoir plusieurs équipes cloisonnées
- Faciliter les développements en nombre
- Disponibilité immédiate
- Service en continu
- Adapté aux cycles agiles (client intégré)
- Vérification automatisée de ce qui est déployé
- Maintenir l'application efficacement…
Continous Integration
- Planification
- Spécifications
- Code
- Build
- Tests
Développements, vérification des tests unitaires, vérification syntaxique (ESLint),...
- Versionner pour release
- Build production
- Déploiement
- Surveillance
- Alertes
- Maintenance
Déploiement rapide et le plus automatisé possible, retours clients, gestion des bugs, demande d'évolutions...
CI / CD
Continous Deployment
Principe d'intégration continue
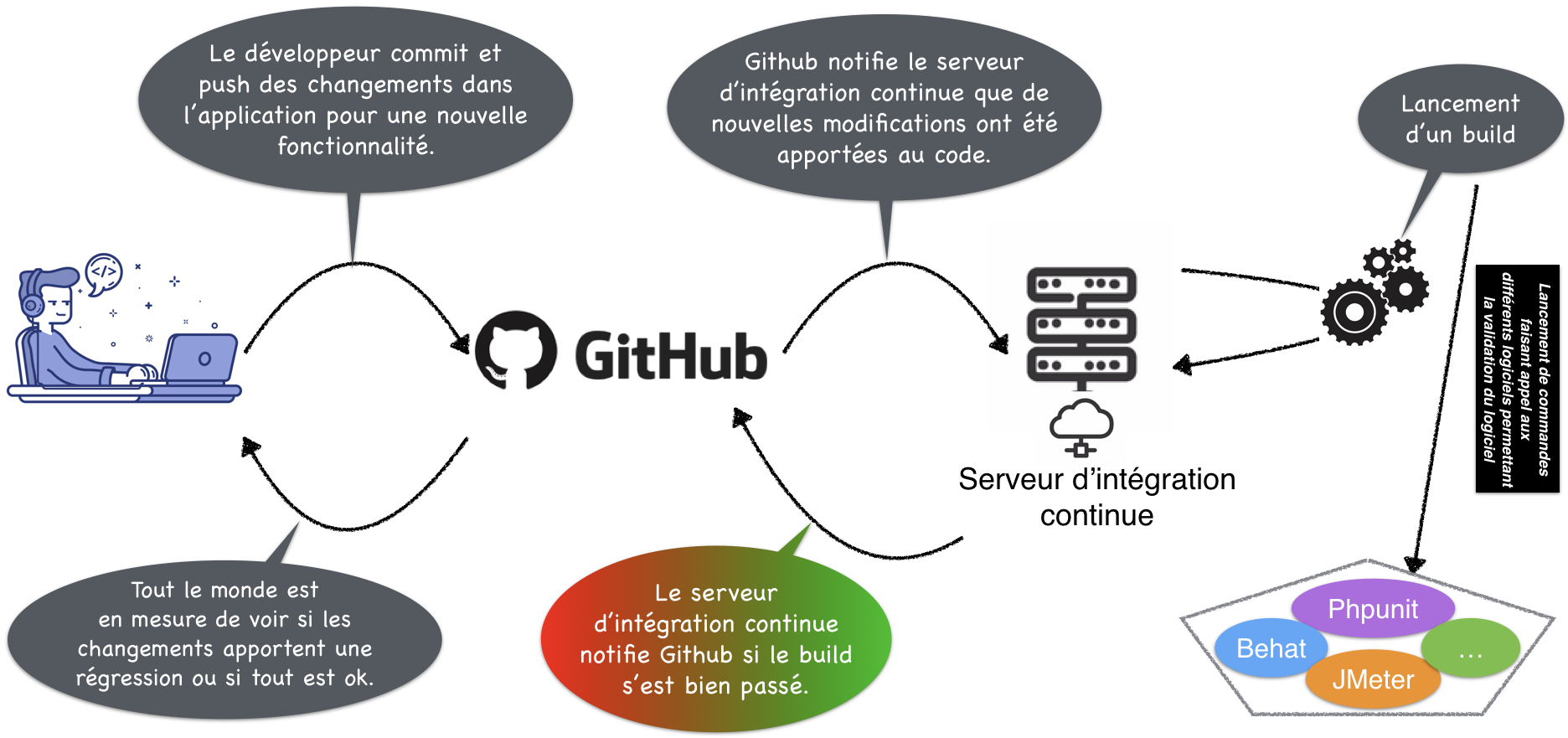
L'intégration continue a pour objectif de faciliter la tâche aux développeurs pour gérer leur code source et réaliser les tâches tout en rajoutant une couche de sureté avec différents tests automatisés.
Vérifier en continue
Problématique : Est-ce que la modification apportée dans le code est valide par rapport au besoin et dans le contexte déjà existant ?
- Tests unitaires
- Tests d'intégration
- Tests d'acceptation
- Tests d'interface
- Tests de qualité
- Tests de sécurité
- Tests de performances / montée en charges
Déployer en continue
C'est l'heure de délivrer nos développements aux clients.
Le travail de vérification effectué en amont et l'utilisation d'outils appropriés permettent d'avoir un système de déploiement automatisé (Un seul clic devrait suffit pour délivrer sur l'environnement de production).



Rappel: Les différents environnements
Pour la plupart des projets, il est important de cloisonner les environnements. D'une part pour ne pas mélanger des données de tests et des données de production, mais également pour pouvoir y faire tourner des versions différentes. Dans le but de pouvoir les tester en contexte avant chaque mise en production.
Voici les environnements minimums couramment utilisés :
- Dev : Environnement de développement
- Pré-production / recette : Environnement avec des données similaires à la production
- Production : Environnement dans lequel tourne votre application en live et sur lequel interagissent vos utilisateurs
Cycle en V
Le déploiement est différent dans un cycle en V, il n'a pas de raison d'être effectué régulièrement.
Il n'est effectué qu'une fois en phase finale, ce qui rend le processus très lourd pour la moindre modification.
Agile
Ici, le client est investit lors de la phase de développement et les remontées sont interceptées sprint par sprint pour fournir une nouvelle version rapidement.
C'est pourquoi nous allons voir le déploiement continue.
Le déploiement par rapport au contexte du projet
Nous allons voir quelques exemples d'outils durant la formation, mais il faudra que vous vous adaptiez par rapport au contexte du projet que vous voulez déployer en continu.
On choisit en fonction de :
- L'équipe qui compose votre projet
- La méthodologie de projet employée
- Le tarif des outils
- La technologie employée
- La base de données (Exemple Render ne faisait que du Postgresql jusqu'en 2023)
- Les besoins du clients et de votre applicatif (cloud computing par exemple)
Choisir par rapport au contexte et aux technologies utilisées
Acteurs du déploiement dans un projet agile
Il va de soit que pour déployer en continue efficacement, il faut que la méthodologie de projet soit adaptée.
L'équipe doit l'être également !
(Tout en devant gérer la résistance au changements)
L'équipe se compose de :
- Product owner : Responsable de l'application
- Scrum master : Animateur de la gestion agile du projet
- Tech lead : Gère les devs techniques et revues
- Développeurs : Produit, test et corrige le code
- Testeur : Valide les développements
- DBA : Gère la partie base de données et montée de version
- Administrateur système & réseau
Le mouvement DevOps
Les principes DevOps
DevOps est un mouvement qui a été instauré afin de mieux répondre aux besoins d'agilités et d'évolutivité des projets.
Concrètement, c'est faire sauter la barrière entre les équipes de développement et les équipes opérationnelles et réduire le "Time To Market"
- C : Culture (Se concentrer sur les gens et leur formation)
- A : Automation (Intégration et déploiement continue)
- L : Lean (Petits scripts, se concentrer sur la value de production)
- M : Mesure (Tout mesurer et voir les progrés)
- S : Sharing (Partager, collaborer, communiquer)
Principes CALMS
Retour au rapport avec l'agilité plus en détails
Le mouvement DevOps a essentiellement été mis en place pour répondre aux besoins des méthodologies agiles.
Le client étant impliqué dans les sprints, souvent à la fin lors de la sprint review, il aime avoir un visu sur l'avancement du projet.
Imaginez, sans DevOps et CI / CD, comment montrer quelque chose de nouveau au client toutes les 2 semaines ?
On souhaite réduire les risques lors des déploiement mais aussi automatiser le déploiement au maximum.
Dev
Ops
Deployer sur les serveurs
Marche à suivre de déploiement
Sans DevOps
Barrière de communication
Dev
Ops
Déploiement automatisé sur les serveurs
Dossier de déploiement
Avec DevOps
Git (Gestionnaire de code source)
Docker, kubernetes, ...
Développements, tests, ...
Environnements communs
La roadmap du bon DevOps
Nous n'aurons évidemment pas la possibilité de voir tous les éléments de la roadmap du bon DevOps, mais je vous invite à vous y referrer pour progresser, elle est complète et très intéressante sur les notions associées au DevOps.
Les gestionnaires de code source
Utilisation d'un gestionnaire
de code source
Un gestionnaire de code source est utilisé afin de pouvoir gérer le code source en :
- Gardant l'historique de modifications des fichiers du projet,
- Permettant à plusieurs développeurs de modifier le même fichier en même temps,
- Fusionnant de manière automatisée (quand c'est possible) les modifications effectuées par les membres de l'équipe de projet,
- Créant des versions de votre code source. Exemple, vous pouvez avoir une version de sources en développement (version non stable) différente de celle qui est en production (version stable).
Systématique pour chaque projet !
Les intérêts d'un gestionnaire de code source
Un gestionnaire de code source à de multiples intérêts :
- Identifier une modification (par qui, pourquoi, où, quand), provoquant un bug et pouvoir revenir en arrière facilement
- Permettre la gestion de modifications simultanées de fichiers par plusieurs personnes sans jamais les bloquer,
- Retrouver aisément une ancienne modification pour par exemple la redéployer à la place d'une version cassée,
- Réaliser des revues de code intégré au gestionnaire.


Centralisé
Un serveur conserve les anciennes versions des fichiers et les développeurs s’y connectent pour prendre connaissance des fichiers qui ont été modifiés par d’autres personnes et pour y envoyer leurs modifications.
(CVS, SVN, TFS, Subversion...)
Il n’y a pas de serveur, chacun possède l’historique de l’évolution de chacun des fichiers. Les développeurs se transmettent directement entre eux les modifications.
(Git, mercurial, bazaar,...)
Gestionnaires de code source
Décentralisé
Git : Gestionnaire de code source Open Source
Git est un gestionnaire de code source Open Source très utilisé dans le monde de l'informatique, quelque soit le domaine.
Il a pour objectif de répondre au besoin de versionning des sources et de la gestion des modifications réalisées sur celui-ci tout en gardant l'historique de tout ce qui est effectué et par qui.
Attention de ne pas confondre Git avec GitHub ou avec GitLab que l'on va utiliser durant la formation.



Git : Pourquoi choisir git ?
Entièrement gratuit (dans sa version de base)
L'utilisation massive de git a ses raisons...
Open source
Extrêmement rapide
Scalable
Gère les branches et le merging
Afin de comprendre git, il faut assimiler les différentes aires de travail et leurs utilités respectives
Git : Les différentes aires de travail
Répertoire local
(Workspace)
"Staging area"
Espace intermédiaire
Répertoire distant
(Serveur / Cloud)
Add + Commit
Push
Clone / Pull
Git : Gestionnaire de code source Open Source
Git fonctionne de manière assez linéaire car il lie concrètement des versions créées à un moment T par rapport à une référence effectuée à un moment Y.
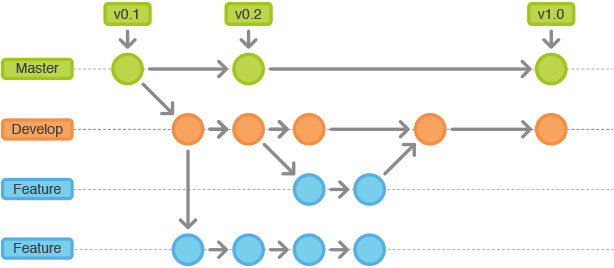
Main
- Commit régulièrement
- Commit les choses qui ont du sens ensemble
- Ne pas faire de trop petits commits
- Ni de trop gros !
- Toujours avoir un message cohérent (Voir slide suivante sur le format normalisé)
Commit : Les 5 règles d'or (bonnes pratiques)
Nous allons essentiellement avoir des commits simple pour la formation, gardez bien en tête les bonnes pratiques suivantes pour l'utilisation réelle de git sur un projet
Pour plus d'informations & aller plus loin : https://github.com/angular/angular/blob/main/contributing-docs/commit-message-guidelines.md
Commit : Le format des messages
Afin de rendre les messages de commit utiles et faire refléter le contenu qu'ils apporte (ou supprime / modifie) du projet, il existe différentes normes pour les messages de commit.
Voici quelques règles que j'applique sur mes commits :
- Toujours utiliser un gitmoji pour identifier visuellement le commit (voir gitmoji.dev) WIN + ; sur windows & CTRL + CMD + Espace sur Mac
- Démarrer son message par un mot clé (action) : build, ci, docs, feat, fix, perf/refactor, test....
- Être le plus explicite possible dans la modification réalisée, pas le ou les fichiers modifiés (git le fait pour nous ça)
- TOUJOURS METTRE UN MESSAGE ! TOUJOURS !
Git ignore
Vous pouvez maîtriser quels fichiers / dossiers seront pris en compte par votre gestionnaire de code source grâce à un fichier .gitignore à la racine de votre projet git.
Voici un exemple de contenu de fichier .gitignore
Il est donc possible et nécessaire de retirer de son gestionnaire de code sources les éléments qui ne doivent pas être publiés !
Exemple, dépendances, fichier environnement, médias,...
.env
/node_modules/
/uploads/Workshop commun
Nous allons installer git :
Normalement, ça s'adapte à votre OS directement :
Ensuite, nous allons vérifier que l'installation s'est bien passée en utilisant la commande
Si tout est bien installé, votre terminal devrait vous donner la version. Pour ce qui est du terminal, je conseillerai à tous d'installer VSCode, il est très utile et je vais l'utiliser tout au long de la formation.
Du coup, vous pouvez directement ouvrir un terminal dans VSCode pour exécuter cette commande.
git --version
Workshop commun
Maintenant que git est installé, on va créer un dossier "formation" quelque part en local.
Ouvrez ce dossier dans VSCode, puis ouvrez un terminal (CTRL+ù ou affichage ==> terminal).
Premièrement, nous devons configurer git à l'aide des deux commandes suivantes
Nous allons initialiser notre projet git en effectuant un
(Assurez vous bien d'être dans le bon dossier)
Ensuite nous allons créer un fichier, par exemple README.md et on va créer une version avec ce fichier.
git config --global user.name "VotreNom"
git config --global user.email "votre@email.com"git initgit add README.md
git commit -m "Message explicatif sur le commit, souvent en anglais"Workshop commun
Nous pouvons accéder au statut d'un repository git avec la commande
git log --oneline --stat --graphgit statusAfin de pouvoir se repérer ce qu'il en est de notre historique de commit, nous pouvons utiliser la commande
A noter que les paramètres sont optionnelles et apportent plus ou moins de précisions dans le rendu de la commande.
Nous allons voir également durant la formation un certain nombre de paramètres pour chaque commande git. Ils ne sont pas tous listés dans ce support. Donc n'hésitez pas à prendre des notes ! Même si j'ai tenté de vous mâcher un peu le travail ICI, l'intégralité des commandes git n'est pas couvrable.
Permet de savoir
les différences entre votre local et votre staging area
Création de snapshot
Vous allez faire un exercice simple d'utilisation de git sans utiliser github pour l'instant.
Envoyer le fichier Exercice1.md
Nous ferons un corrigé ensemble par la suite.
Exercice - Git
GIT
Exploiter les logs et tag une version
Vous allez faire un exercice simple d'utilisation de git sans utiliser github pour l'instant.
Envoyer le fichier Exercice2.md
Nous ferons un corrigé ensemble par la suite.
Exercice - Git
GIT
La branche est une fonctionnalité de git permettant d'avoir un espace de travail séparé et isolé de la version de code source principale (branche main / master).
Lorsque l'on travail sur une nouvelle feature, on veut pouvoir travailler de manière isolée. Ceci permettant de garder la branche principale dans un état le plus stable possible.
Extrêmement rapide car c'est un simple pointeur vers un commit. (Sous forme de micro fichier)
Les branches Git
main
feature
Ce sont donc directement des références vers des commit qui sont utilisées pour pouvoir connaître le contenu d'une branche. Et notre code principal se trouve "toujours" sur la branche main (ou master).
Les branches Git
main
feature
HEAD
HEAD
Permet de savoir
sur quelle branche on est placé dans le workspace local
(C'est aussi un micro-fichier)
Quelques règles de nommages peuvent être mises en place pour le nommage et la gestion de vos différentes branches :
- Démarrer par un mot clé : feature, bugfix, ci, log, tests,...
- Spécifier la fonctionnalité : feature/login-form
- Supprimer ses branches lorsqu'elles sont mergées (voir commande git branch --merged ou git branch --no-merged)
- Ne pas merger de branche dans la branche main tant que la fonctionnalité n'est pas dans un état stable
- Une branche par fonctionnalité
- Attention à votre historique de commits !
Les branches Git
Git utilise deux moyens différents pour fusionner le contenu de deux branches : Le fast-forward et le 3-way merge.
- Fast-forward merge est utilisé si les branches n'ont pas changé de commit par rapport à la base de création de la branche.
- 3-way merge est utilisé si au contraire les branches ont divergés.
Il nous est possible de réaliser des fusions de branches de plusieurs façons.
Les merges de branches
Les merges de branches
Fast forward merges
Permet de simplement déplacer le pointeur de commit de la branche main vers le commit voulu de la branche bugfix.
Ceci n'est possible que si la branche de départ n'a pas été modifiée depuis.
main
bugfix
Fast-Forward : On se place sur la branche main puis on déplace le pointeur de main sur le commit de bugfix.
git merge bugfixLes merges de branches
3-way merges
Utilise 3 commit pour réaliser un commit de merge permettant de prendre en compte toutes les modifications qui ont été faites sur les deux branches en simultané.
main
bugfix
3-way Merge : 3 commits sont utilisés pour réaliser un commit de merge.
git merge bugfixmain
Merge commit !
M1
B1
B2
M2
M3
MRGC
Les merges de branches
Squash merging
Le squash merge permet de rendre l'historique plus propre dans le cas où il peut être intéressant de regrouper les commits d'une branche afin d'en faire un seul commit.
main
bugfix
git merge --squash bugfixmain
B1
B2
B1 + B2
La branche peut ensuite être supprimée !
Les merges de branches
Rebase
La dernière possibilité est le rebase, cette commande git réecrit l'historique de vos commit. Attention lors de son utilisation.
L'intérêt est de changer le commit de base d'une branche afin de pouvoir avoir un ligne directe dans sont historique git.
git switch bugfix
git rebase mainNous allons voir un exemple, le schéma est très linéaire on démarre de deux branches qui divergent pour finir avec une seule ligne car on modifie le commit de départ avant création de la branche.
main
Workshop commun
Nous allons maintenant effectuer le même principe en rajoutant une notion de branche et de fusion de ces branches par la suite.
Nous allons commencer par créer une branche ajouterTexte et nous placer dessus
Réalisez une modification dans le texte du README.md, faites le git add, puis le git commit.
Effectuez un
Vous remarquez que votre branche ajouterTexte est en avance par rapport à votre branche main. On va donc tout simplement se placer sur main, merger notre branche puis la supprimer.
git branch ajouterTexte
git checkout ajouterTextegit log --graph --onelinegit checkout main
git merge ajouterTexte
git branch -D ajouterTexteWorkshop commun
Comment gérer un conflit ?
(Utiliser un 3-way merge)
Nous avons vu un cas simple sans conflit, maintenant nous allons voir comment ça se passe s'il y'a conflit entre les branches que l'on veut fusionner.
On créer une branche conflit. On fait une modification sur README.md, on add, on commit sur la branche conflit.
On git checkout main et on fait une autre modification sur ce même fichier on add et on commit sur main.
Maintenant si on fait un on voit qu'un conflit est détecté par git. En ouvrant le fichier en conflit il propose directement les deux options.
Vous pouvez alors modifier le fichier, sauvegarder et utiliser la commande
git rebase conflitgit rebase --continueLes branches et les merges
Vous allez faire un exercice simple d'utilisation de git sans utiliser github pour l'instant.
Envoyer le fichier Exercice3.md
(Question 11 optionnelle)
Nous ferons un corrigé ensemble par la suite.
Exercice - Git
GIT
Revenir en arrière sur un merge
La commande git reset
Plus les conflits sont nombreux, plus ils sont difficiles à gérer et il arrive souvent que des erreurs de merge provoquent des "catastrophe". Mais ceci est assez aisément inversable.
Répertoire local
(Workspace)
"Staging area"
Espace intermédiaire
Répertoire distant
(Serveur / Cloud)
git reset --hard HEAD~1git reset --mixed HEAD~1git reset --soft HEAD~1Soyez prudent avec cette commande...
Sauvegarder son workspace local
La commande git stash
Afin de ne pas être gêné par les développements locaux, il est possible de sauvegarder vos dévs dans un espace particulier, la stash.
Création stash
Réappliquer une stash
Liste des stash
git stash push -m "Stash informations"git stash listgit stash popSupprimer une stash
git stash drop 0Exercice complémentaire git
Si on a le temps, vous pouvez pratiquer ce que l'on a vu avec les jeux éducatifs sur git suivant :
- Oh my git (à privilégier)
- Learning branch (pour compléter)
Jusqu'ici, nous n'avons travaillé qu'en local et avec notre staging area, maintenant nous allons faire en sorte que notre répertoire git soit lié à un répertoire distant que l'on pourra partager avec nos collaborateurs.
Le répertoire distant : Github
Répertoire distant
(Serveur / Cloud)
Nous allons faire un petit tour d'horizon de Github et des fonctionnalités proposées.
Workshop commun
Utilisation de GitHub pour la création du repository (dépôt distant) :
- Créer un compte puis un repository sur https://github.com/
- Vous pouvez générer les clés ssh et les paramétrer sur votre PC (Agent ssh) et sur Github pour gérer votre accès (Envoyer liens doc)
- Récupérer le repository en local avec (le . a la fin permet de cloner dans le dossier courant) par exemple :
git clone git@github.com:cbrasseur/Formations.git .Je vous laisse un peu de temps pour revoir tout ça de votre côté.
Et ça vous permettra de prendre le temps de me poser des questions.
(Pensez à prendre le lien de votre repo sur la commande ci-dessus)
Une bonne pratique et un moyen efficace d'intégrer une revue de code dans votre processus d'intégration continue est d'utiliser les Merge / Pull requests (c'est la même chose, ça dépend juste de l'outil utilisé pour le nom)
Ces dernières permettent de forcer l'attente d'une validation par un ayant droit avant de fusionner quoi que ce soit sur la branche principale.
Voyons rapidement un exemple ensemble sur github.
Petite aparté sur les fork...
Merge / Pull Requests
Toujours réaliser une revue de code à cette étape !
Github propose la possibilité de reporter un bug ou une demande d'amélioration de votre projet grâce aux issues git.
Ces issues peuvent être directement liés aux pull request afin de clotûrer ces issues.
Nous allons faire un exemple ensemble afin de voir comment pourrait être utilisée cette fonctionnalité.
Les issues git
Créer une issue git
Push un bugfix
Associer la fermeture de l'issue lors de la pull request
Github propose également la possibilité d'ajouter des milestones. Ceci étant une fonctionnalité permettant de regrouper des issues afin de planifier par exemple les travaux restants pour une montée de version.
Il permet de planifier, suivre l'avancement en fonction des issues qui sont fermées, etc...
Les Milestones git
Voyons un exemple...
Une autre fonctionnalité concerne les tags git, permettant de pointer une version par rapport à un commit.
A cette étape, github génère les sources de notre projet.
Il nous est également possible de générer une realase version de notre projet.
Les Tags & Releases git
Voyons un exemple...
Et voici un lien contenant les normes pour la gestion des versions
Collaborer et utiliser un répertoire distant
Vous allez faire un exercice simple d'utilisation de git, cette fois-ci, nous allons avoir besoin d'un répertoire distant avec GitHub.
Envoyer le fichier Exercice4.md
Nous ferons un corrigé ensemble par la suite.
Exercice - Git
GIT
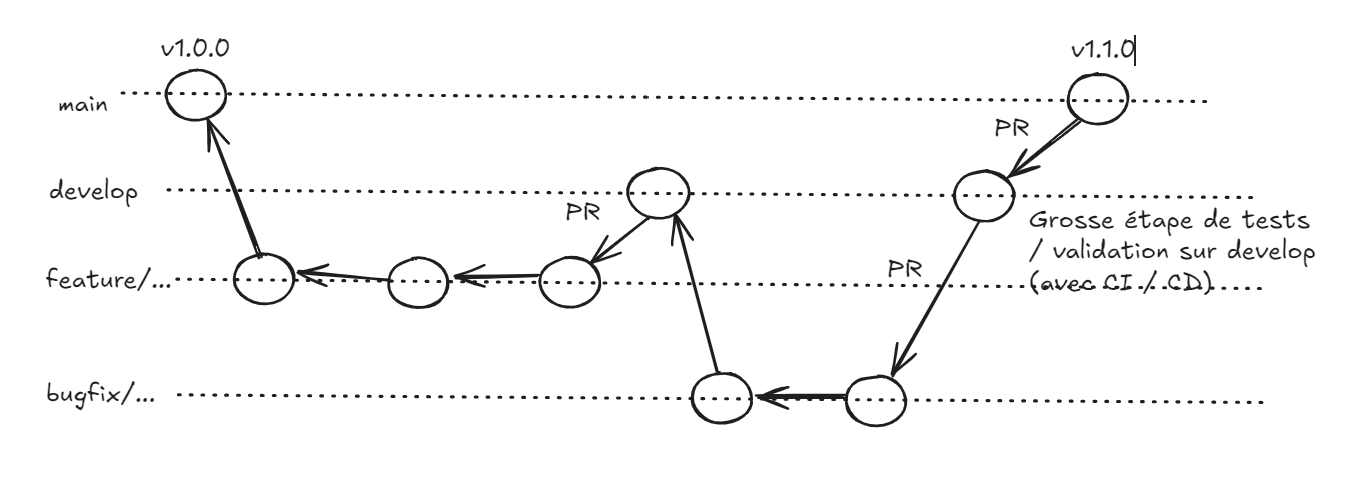
Workflow - Git
Ajout de l'utilisation de la branche develop pour ne JAMAIS développer directement sur main.
On passe toujours par des PR (avec revue de code) entre les branches et develop, puis lorsque c'est testé et validé sur develop, on passe sur main également via une PR (avec revue de code).
Je dois initialiser develop
dès le début idéalement
Workflow plus complet d'utilisation de git (develop)
Faisons ensemble un workflow plus complet d'utilisation de git.
Nous allons ajouter la notion de branche develop à notre utilisation de git.
Exercice 5 - Git
Petite démo + Faire l'exercice 5
Outils graphiques
Il existe des outils graphiques pour représenter sous forme d'arbres vos projets git.
Par exemple, sourceTree est un des outils les plus utilisés pour utiliser git graphiquement.
Ce type de gestion peut permettre à des développeurs non expérimentés de travailler avec git plus facilement.

Supporte gitflow graphiquement

Bonnes pratiques Git
-
Toujours add/commit/push quotidiennement,
-
Toujours récupérer les sources à jour avant de relancer un nouveau développement,
-
Créer une branche pour chaque nouvelle fonctionnalité / bug,
-
Appeler la branche principale main,
-
Bien séparer les développements réalisés par commit et par branche et les documenter (-m) + gitmoji
- Utiliser les Merge Request / Pull Request pour mettre du code sur main (et en profiter pour forcer la revue de code !)
- Nous avons abordés beaucoup de sujets git et vous avez en main les éléments nécessaires à la compréhension et l'utilisation de git. Mais dans ce programme nous ne couvrons pas deux aspects majeurs (mais optionnels) de git :
- Réécriture d'historique git (history rewritting)
- Gitflow : Un workflow adapté pour une meilleure utilisation de git, plus commune aux utilisateurs et provoquant logiquement moins de soucis de fusion de branches.
Plus d'informations & schéma sur https://danielkummer.github.io/git-flow-cheatsheet/index.fr_FR.html
Git : Ce qu'il reste à voir...
Evaluation - Etape 1
Cette évaluation sera faite en groupe de 2 ou 3 (Idéalement votre groupe de projet), vous allez devoir développer un jeu au tour par tour.
L'objectif est surtout de mettre en place git, les pull requests, les revues de code et avoir un repo git bien entretenu entre les membres de l'équipe de travail.
Bon courage !

Envoyer Git_eval.md
Git & Projet Cube
Votre objectif maintenant est de mettre en place git, si ce n'est pas déjà fait, sur votre projet Cube pour toute votre équipe.
Créez le repository sur GitHub, partagez vous les droits d'accès, faites quelques tests de git sur des commentaires pour vérifier que ça fonctionne comme il faut.
Cette étape ne prend pas énormément de temps mais il faut qu'elle soit faite pour tout le monde donc prenez le temps nécessaire pour faire ça correctement.
Prévenez-moi en cas de difficultés ou pour toute question !
Intégrer en continue
Intégration continue
L'intégration continue a pour objectif de faciliter la tâche aux développeurs pour gérer leur code source et réaliser les tâches tout en rajoutant une couche de sureté avec différents tests automatisés lors des merge (push, ...).
Pour notre CI, on va mettre en place un serveur qui va avoir pour objectif d'ajouter des étapes supplémentaires à notre validation de merge :
- Vérifications des tests automatisés (inclus la sécurité et qualité)
- Réalisation de revue de code manuelle
- Vérification syntaxique du code
- Gestion du build automatisé (générer les dépendances par ligne de commande, par exemple npm ci)
Intégration continue
Si on prend le cycle agile, par sprint l'idée est de pouvoir intégrer du code à notre gestionnaire de code source et réaliser des versions contrôlées de notre applicatif.
Lors de l'opération de merge (ou pull request) on va utiliser les informations mises en évidence dans github pour réaliser une revue de code avant de valider le merge ou le rebase sur la branche principale.
On pourra donc livrer régulièrement des nouvelles versions vérifiées par le "product owner" ou le "tech lead".
Intégration continue
Grâce à un fichier .yml contenant les scripts et configurations à exécuter, on peut intégrer en continu les nouvelles sources. Même en cas d'update des dépendances.
L'intégration continue nous permet la gestion du build automatisé et donc mettre à jour les dépendances de la branche principale après un merge / pull request.
Elle permet également la vérification syntaxique (eslint par exemple), fiabilité, qualité et sécurité de votre application.
Si une erreur est détectée, le déploiement n'est pas possible !
- Nous allons faire un petit tour d'horizon des éléments
- Mais je vous propose de garder la Cheat_Sheet, elle vous sera utile !
GitHub Actions - YML
Ce que vous devez savoir, c'est qu'aujourd'hui de nombreux templates .yml existent pour toutes sortes de technos. Mais il faut très souvent l'adapter à son contexte.
Cheat Sheet

GitHub Actions
GitHub Actions - YML
Un petit exemple simple de CI...
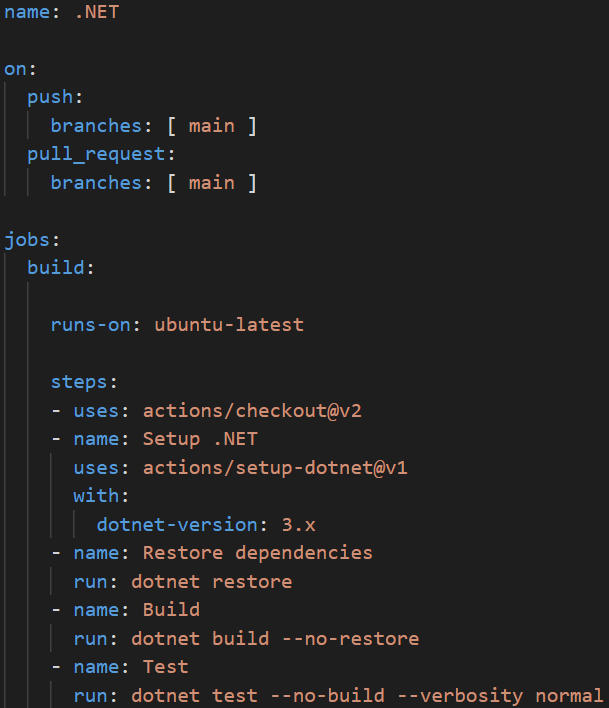
Attention,
l'indentation est normée et provoque des erreurs si non respecté
Attention,
l'indentation est normée et provoque des erreurs si non respectée
Attention,
l'indentation est normée et provoque des erreurs si non respecté
on
Défini l'action déclencheur de la CI
Attention,
l'indentation est normée et provoque des erreurs si non respecté
jobs
Défini la plateforme d'exécution et les étapes de la CI
Démonstration rapide ESLint
Nous allons voir rapidement comment utiliser GitHub et une CI simple pour analyser du code pour l'instant syntaxiquement, plus tard également en y intégrant des tests automatisés.
Sans rentrer trop dans les détails pour l'instant, c'est de la configuration et du travail de mettre en placer un "linter" efficace.
Prenons l'exemple Sample_Node sur GitHub.
Les différents outils
Pour notre intégration continue, il faut également choisir les outils que l'on souhaite utiliser. Il en existe beaucoup trop pour les lister, mais en voici quelques-uns.
- GitLab-CI
- GitHub-Actions
- Buddy
- Jenkins
- Bamboo
- Circle-CI
- Azure DevOps
- Drone
- ...
Workshop CI
L'objectif final de ces tests est qu'ils soient intégrés à notre CI pour qu'ils soient passés automatiquement et nécessairement au vert pour pouvoir merger vers une branche principale.
Workshop guidé (envoyer WS_CI_GitHub_Node.docx)
Avec GitHub et Jest sur un test unitaire extrêmement simple. On en profitera pour linter correctement en même temps.
On va mettre en place la CI complète avec GitHub et les GitHub Actions.
Démonstration plus complète d'une CI
Nous allons voir rapidement comment utiliser GitHub et une CI un peu plus complète.
On va créer un workflow plus complet ensemble. On va avoir un l'installation des dépendances, un linter, des tests unitaires, un scan de dépendances.
Prenons l'exemple SampleCIPython sur GitHub.
Workshop complet CI
L'objectif final de ces tests est qu'ils soient intégrés à notre CI pour qu'ils soient passés automatiquement et nécessairement au vert pour pouvoir merger vers une branche principale.
Nos développements (et plus tard, nos éléments de conteneurisation avec Docker) sont testés et vérifiés avant chaque déploiement.
Workshop guidé (Workshop_CI_Python_Guide.md)
Versionner sa base de données
Une des problématique qui se pose avec l'intégration et le déploiement continue, est la gestion des montées de version de vos bases de données.
Comment s'assurer que votre base de données est toujours dans la bonne version par rapport à la merge request en cours d'acceptation ?


Versionner sa base de données
Comment fonctionne un outil de gestion de versionning de base de données ?
C'est souvent un projet "console"(où de tests unitaires par exemple), qui va avoir en dépendance l'outil de versionning lui permettant de :
- Créer des tables, index, contraintes, procédures stockées, triggers,...
- Modifier des éléments
- Générer des scripts qui seront exécutés à chaque fois
- Gérer les données,
- ...
Ceci permettant de mettre à jour la base de données et d'exécuter les scripts en fonction de ce qui passe dans la merge request.
Schéma récapitulatif d'une CI
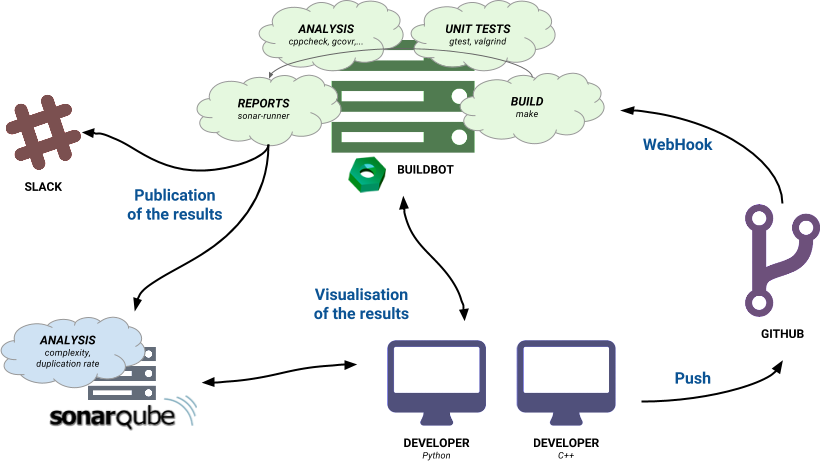
SonarCloud
Démo SonarCloud
SonarCloud
Intégrer l'analyse Sonar avec votre repo de code
sur les livres
Workshop CI
Réalisez une CI complète (sans linter) sur votre projet de combat "The Greatest Warrior".
Je vous demande de réaliser le démarrage de la CI via une pull request et d'y intégrer une revue de code avec un collègue dans github (au moment de créer la pull request, ajoutez un reviewer).
Vérifier en continue (Tests automatisés)
Importance des tests
L'objectif premier de réaliser des tests sur son application est de limité d'envoyer des erreurs en production.
On va donc tester les développements réalisés à chaque changement et surtout avant chaque mise en production, ce qui rend l'application plus robuste mais ne la rend pas infaillible.
- L'utilisation d'une CI/CD force la réalisation de tests et surtout de s'assurer qu'ils passent,
- L'identification des problèmes est donc réalisée bien plus tôt et plus simplement car tout est cloisonné,
- Plus de productivité (si industrialisé) et rendement.
Les outils et s'adapter au contexte
Pour choisir quels outils utilisés pour réaliser nos tests, il faut une fois de plus se référer à la technologie et le contexte du projet.
Quelques exemples... (Mais il y'en a trop)
- Mobile : Graddle
- .Net : NUnit,
- Java : JUnit,
- Web : PHPUnit, Jasmine (js)
Je vous invite à chercher ceux qui peuvent correspondre à vos technologies habituelles ou d'entreprise.
Différents types de tests
Il existe de nombreux tests différents, en voici les principaux et ceux que l'on va voir ensemble
- Tests unitaires
- Tests d'intégration
- Tests d'acceptation
- Tests de sécurité (aussi mais on l'a déjà vu)
Autres types de tests : Tests de montée en charge, tests d'exploitabilité, vérification de disponibilité immédiate…
Les tests unitaires
Un test unitaire est utilisé afin de pouvoir vérifier atomiquement que chaque élément de notre code. On va donc vérifier que le code produit bien le résultat attendu.
A savoir :
- Systématique pour chaque projet !
- Réfléchir efficacement à ce qui doit être testé, inutile de tester si 1 + 1 = 2.
- Test Driven Development (TDD): Méthodologie récente visant à démarrer ses développements par des tests unitaires
Exercice
Réalisez une CI sur Github
Votre objectif est de mettre en place une TDD afin de pouvoir mettre en place une CI (GitHub Actions recommandé) sur un projet super simple permettant d'afficher le résultats de calculs :
- Addition : Une méthode pour ajouter deux nombres en paramètre et retourner le résultat,
- Soustraction : De même que pour l'addition, mais pour une soustraction
- Multiplication : De même...
- Division : ... (Attention quand même au type de retour !)
Réalisez le projet en TDD afin de vous assurer des tests unitaires (TDD optionnelle)
Une CI qui va lancer votre build, vos tests ainsi que votre linter !
Donnez-moi un accès (en lecture au moins) au repo github pour que je puisse regarder votre travail
Workshop / Démo
L'idée ici, va être simple, on veut gérer un menu simple
Les tests à effectuer sont les suivants :
- Add : Ajouter un nouvel élément dans le menu
- Update : Modifier un élément existant dans le menu
- Remove : Supprimer un élément existant dans le menu
- GetList : Récupérer la liste des éléments en IEnumerable
Le but est d'abord de réaliser les tests, puis développer notre menu.
Le code corrigé est fait en TDD avec NUnit, nous pourrons prendre le temps de le refaire en TDD ensemble pour appréhender la méthodologie.
Les tests d'intégration
Un test d'intégration permet de vérifier qu'il n'y a aucune régression sur l'existant suite aux modifications effectuées. (En termes de dépendances entre les éléments de votre appli)
A savoir :
- Systématique pour chaque projet !
- Plus complexe à mettre en œuvre car il doit vérifier les dépendances entre les éléments (Si une classe en utilise une autre par exemple ou un framework)
- Injection de dépendance (Inversion of Control)
Injection de dépendances
Concept issu de la POO permettant de limiter les conséquences des interactions entre les éléments de votre projet.
Il en existe 3 types :
- Par interface : On utilise une interface pour forcer le respect d'un contrat
- Par mutateur : Une propriété interne a notre classe reçoit en paramètre l'objet de dépendance
- Par constructeur : On passe l'objet de dépendance directement au constructeur de notre objet.
La pratique la plus répandue aujourd'hui est de coupler l'injection par interface et l'injection par constructeur.
Les tests d'acceptation
Les tests d'acception permettent de vérifier que les scénarios utilisateurs définis à l'expression de besoin respectent bien les étapes et le résultat attendu.
A savoir :
- Systématique pour chaque projet ! (Au moins de manière implicite par les développeurs)
- Peuvent être définis dès la phase de spécification.
- Une méthodologie récente propose même des outils pour passer ces tests de manière automatisée ou en forçant les développeurs à les passer avant de pouvoir partager leurs développements.
Behavior Driven Development
-
Outils manuels (souvent utilisé lorsque des équipes de recette sont définies pour le projet) : QCHP, Cucumber, il en existe surement énormément, mais ils font tous à peu près la même chose. On décrit un scénario avec des étapes et un résultat attendu, le recetteur doit respecter les étapes et faire un retour quant au résultat attendu directement sur l'outil.
Tant qu'un scénario bloque, il n'est pas possible de passer de l'environnement de recette (ou pré-prod) à l'environnement de production.
- Behavior Data Driven : Ici, on parle de tests d'acceptation automatisés qui sont bien plus complexes à mettre en œuvre. On peut réaliser ça avec NUnit et Gherkin par exemple, ou Jest et GitLab...
Tests d'acceptation - suite
Les tests d'interface
Les tests d'interface vérifient que les développements sont cohérents et fonctionnent sur toutes les plateformes cibles (par exemple, dans le web on vérifie chaque navigateur)
A savoir :
- Systématique pour chaque projet ! (Au moins de manière implicite par le développeur)
- S'informer sur les plateformes cibles potentielles est important ici
- Il est aussi possible de les automatiser (Selenium) en passant paramétrant notre test avec les plateformes cibles et les vérifications sur ces plateformes.
Les tests de performances
Les tests de performances font exactement ce que leur nom indique, on parle aussi de tests de charge, tests d'usine,...
A savoir :
- PAS systématique pour chaque projet, utilisé en cas de besoin de performances.
- On test si des fonctionnalités ont des temps de réponses suffisant ou si le réseau est de bonne qualité, on réalise des simulations d'utilisation massive pour s'assurer d'un service continue...
Conclusion sur les tests
Les tests sont une part importante des développements dans un projet et également une part importante de sa réussite.
L'estimation moyenne du pourcentage de temps (selon moi, j'ai cherché mais je n'ai pas trouvé d'étude) pris pour réaliser les tests sur un projet est compris entre 30% et 50% du temps !
D'où l'intérêt de la TDD, plus d'aller retour entre les développements et les tests, les tests sont effectués au départ et les développements s'adaptent pour y répondre !
Vous avez beaucoup de travail à réaliser sur les tests pour votre projet Cube. Je vais vous laisser 2 heures pour travailler sur les tests du projet Cube et me poser des questions.
Ajoutez des tests unitaires à votre projet de jeu.
Vous devriez trouver une 10aine de tests à réaliser, si besoin, vous pouvez me demander mais je préfèrerai que vous cherchiez.
Lorsque vos dix tests passent en local, votre objectif est de rajouter une CI complète sur votre projet avec GitHub Actions.
Pensez à l'étape de linting (analyse syntaxique)
N'oubliez pas la notation se fera en partie sur cet exercice
Exercice fil rouge
Corrigé exercice fil rouge
Nous allons prendre le temps de parcourir le corrigé ensemble et je vais vous envoyer le projet et vous laisser un peu de temps pour le regarder, les différents tests etc...
Vous pouvez en profiter pour modifier le comportement du jeu, mais faites le en TDD !
CI pour votre projet Cube
En fonction du temps qu'il nous reste, je vais vous laisser vous regrouper et réfléchir à votre CI du projet Cube.
Vous pouvez commencer à documenter votre CI en expliquant chaque étape rapidement (son utilité et où ça se trouve dans votre script de CI). Cette documentation vous sera utile car elle sera demandée dans le dossier de déploiement / d'exploitation.
Si vous n'avez pas encore mis en place de tests unitaires sur votre projet, c'est le moment ! Faites un test quelconque, intégrez le test à votre CI.
Il vous faut trouver la commande qui exécute les tests selon vos technologies et votre environnement.
Le déploiement en continue (Docker & autres outils)
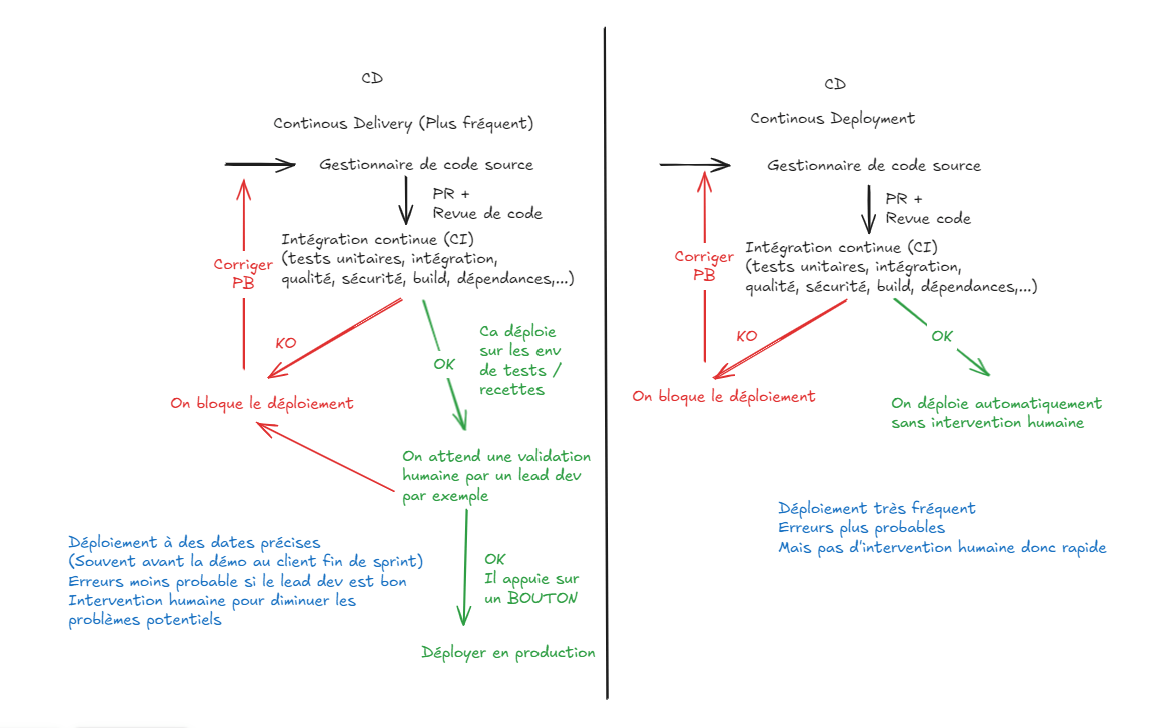
Le déploiement est la suite logique de l'intégration continue.
L'objectif est de mettre en production de manière automatisée (ou la plus automatisée possible), monitorer et alerter en continue.
Méthodes agiles VS cycle en V
Différents outils peuvent être utilisés :
CI/CD : déploiement et outils




Objectifs du déploiement
Comme expliqué, l'objectif premier est de livrer en production de manière automatisée après que notre CI valide ce qui doit être déployé. On doit également pouvoir monitorer (logger en continue) et alerter en continue.
Objectifs :
- Déployer sur un environnement de production en un clic (si possible)
- Monitorer en continue, c'est à dire logger en continue tout ce qui se passe en production et de manière la plus exhaustive possible !
- Alerter en continue, en cas de panne, d'incident, de tentative de brute force, etc... Un système d'alerte doit être mis en place (mail, alarme bruyante...)
Manuel VS Automatisé
- Eviter les erreurs qui arrivent systématiquement lors d'un déploiement manuel,
- Le déploiement manuel force à avoir des acteurs à chaque étape du déploiement, des vérifications, un timing a respecter,...,
- Tester son cycle de déploiement manuel est complexe et coûteux,
- Le déploiement manuel nécessite une documentation claire soumise à interprétation,
- Si un acteur d'une étape du déploiement manuel est indisponible, c'est la panique
- Notre objectif : Livrer rapidement et proprement au client !
- Zero Down Time deployment : Le déploiement est réalisé de manière à ne jamais avoir d'interruption de service en production.
- Feature flipping : Possibilité d'activer / désactiver des fonctionnalités de l'application (en cas de bug par exemple)
- Fréquence de déploiements : Beaucoup de décisions sur son déploiement dépendent de la fréquence de déploiement. Mon ancienne entreprise faisait 1 déploiement tous les 2 mois (semi-automatisé, avec des étapes de validations...). Facebook en fait 2 par jour ! (Full-automatisé avec une bonne CI/CD, en ZDT,...)
CI/CD : déploiement et concepts associés
Workshop guidé
Petit exemple de mise en place d'un déploiement continue simple et automatisé avec GitHub Pages.
Voir exemple hello_world.
A vous de faire de même ! Vous devez effectuer la même chose (en js, ou sinon faite une simple page html, sans test tant pi, nous l'avons déjà travaillé !)
Vous pouvez repartir du repo github de la CI en Node.js effectuée précédemment. Ajouter un fichier index.html avec du html dedans et il suffit d'ajouter la partie github pages dans votre fichier .yml afin d'intégrer le déploiement continu.
https://www.youtube.com/watch?v=hNRxn5sKOdE
Quelques exemples
Exemple de monitoring en continue sur un projet en production (Gallus, sur render).
Exemple de CI que j'utilise aujourd'hui. Exemple avec gallus-app et GitHub Actions. (Celle-ci est propre et réutilisable pour d'autres projet Vue)
Un petit Exemple avec heroku.
Un exemple plus complet
Nous allons voir un exemple complet avec Azure DevOps.
Démo avec Azure DevOps
CI/CD
Docker : La virtualisation allégée
Docker est un outil de conteneurisation, adapté à toutes les plateformes, il va permettre d'utiliser la virtualisation afin de créer des conteneurs utilisant des images.
Il nous faut l'installer, ça va prendre un certain temps. Soit Docker Desktop (Windows, Mac) soit Docker via apt-get (Unix). Un outil en ligne existe : play-with-docker
A savoir, WSL a été intégré à Windows et Docker peut utiliser le WSL de Windows (pratique, mais gourmand !!).
L'utilité première est de pouvoir avoir un environnement défini et commun ainsi que pouvoir paramétrer ces environnements de manière sécurisée. On peut facilement simuler l'utilisation d'une machine Ubuntu, avoir un environnement Node, créer un serveur minecraft...
Docker : La virtualisation allégée
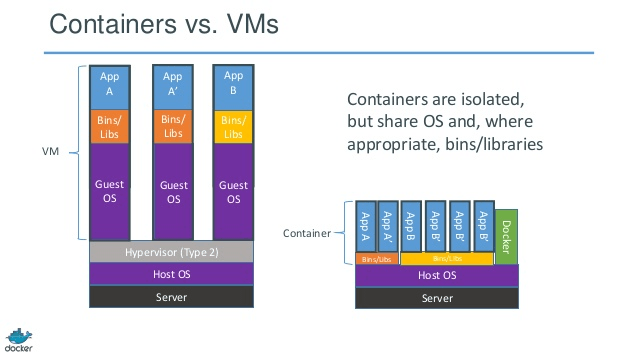
Les commandes Docker
Lister les conteneurs :
docker ps -a
Lister les images :
docker image ls
Builder un container :
docker build -t image-name
Démarrer un conteneur :
docker run -p 8080:2368 ghost
Démarrer un conteneur avec un volume :
docker run -v localFolder:containerFolder containerName
Supprimer un conteneur :
docker rm -f containerName (ou containerId)
Supprimer une image :
docker rmi imageName (ou imageId)
Démarrer une invite de commande dans le conteneur :
docker exec -it containerName bash
Docker : Cheat Sheet
Voici une feuille de triche contenant toutes les commandes docker, que ce soit pour du docker simple, du docker-compose ou du dockerfile :
https://dockerlabs.collabnix.com/docker/cheatsheet/
Docker : Petite démo
On va faire un exercice ensemble sur Docker pour nous familiariser avec l'outil.
Exemple en workshop guidé avec MySQL.
Utilisation des commandes :
Démarrer un conteneur Mysql
- docker run --name some-mysql -e MYSQL_ROOT_PASSWORD=root -d mysql
Lister les conteneurs
- docker ps -a
Entrer en ligne de commande sur le conteneur (containerId est trouvable via la commande précédente)
- docker exec -it containerId mysql -p
Stopper un conteneur
- docker stop some-mysql
Supprimer un conteneur
- docker rm -f containerIdDocker : Première utilisation
Démarrez par suivre les 6 tutos de docker dans "Learning Center".
Ensuite, faites le tuto par rapport à la technologie de votre choix.
Puis faire l'exercice en ligne de commande suivant.
Envoyer le fichier d'exercice démarrer un conteneur avec docker
Run-a-container.md
ET
Docker : Première utilisation
Exercice avec ports et mise en place de volume ainsi que copie de fichiers via lignes de commande
Work-with-containers.md
Docker : Dockerfile
Créer sa propre image en utilisant un Dockerfile.
Ce fichier va permettre d'utiliser une ou plusieurs image pour créer votre propre conteneur.
- FROM (nom d'image à utiliser en tant que référence. Exemple : from debian / from nodejs,...)
- WORKDIR ./app (espace de travail dans le conteneur sera /app)
- COPY . ./app (pour copier les sources locales dans le dossier .app)
- RUN uneCommande (sur le serveur directement)
- CMD UneEtapeDeBuild (npm ci, npm install...)
Builder un conteneur : docker build -t <tag> .
Démarrer un conteneur : docker run <tag>
Premier exercice docker (JS)
Réalisons ensemble notre premier container pour lancer un script javascript (supposons que c'est une application simple en js)
- Premièrement, il faut créer un nouveau dossier, disons simple-js-docker
- Ensuite, on créer un fichier js : app.js
- Contenant un simple console.log("...")
- Pour lancer ce script sur notre machine, on peut utiliser node, avec node app.js par exemple
Comment réaliser la même chose depuis Docker ?
Ceci se fait en plusieurs étapes, très simples :
- D'abord il nous faut utiliser une image de départ qui permettra de définir l'image de base du conteneur (Ici FROM node:alpine)
- Ensuite on copie le fichier app.js (COPY . /app)
- On définit l'espace de travail (WORKDIR /app)
- Puis on execute le script via Node (CMD node app.js)
- Et c'est tout ! (il ne reste qu'à build, puis run l'image)
Les commandes à lancer : docker build -t nom-image .
& docker run nom-image
Exemple de mise en place
Getting started with Docker :
On va clone git@github.com:docker/getting-started.git
Ensuite, on va ouvrir le dossier app avec VSCode.
On va créer un fichier Dockerfile :
# syntax=docker/dockerfile:1
FROM node:12-alpine
RUN apk add --no-cache python2 g++ make
WORKDIR /app
COPY . .
RUN yarn install --production
CMD ["node", "src/index.js"]
EXPOSE 3000 (< Exposition port 3000 dans le conteneur, pour le -p 3000:3000)
Puis build le container docker build -t getting-started . (Pensez à être dans le dossier app & n'oubliez pas le . dans la commande)
Et on finit par run le container docker run -p 3000:3000 getting-started Puis on va sur localhost:3000/
Regardez les tests unitaires du projet
Premier exercice docker
(Python & Dockerfile)
Envoyer le fichier Workshop_Docker_Counter_simple.md
Docker : Docker compose
Docker compose nous permet d'avoir une CI dans Docker. On commence à savoir ce qu'est une CI, alors prenons directement un exemple.
1. Vérifier que vous possédez docker compose (Inclus avec Docker Desktop, mais à installer manuellement sur Unix)
docker-compose --version
2. Clonez ce repo :
git clone https://github.com/nigelpoulton/counter-app .
3. Utilisez la commande :
docker-compose up
4. Rendez-vous directement sur :
http://localhost:5000/
5. Magique n'est-ce pas ? Rien à faire à part une commande pour démarrer un projet !
Docker : Docker compose
- build: On dit à Docker d'utiliser le Dockerfile présent à la racine comme image.
- command: python app.py On run l'app python.
- ports: On dirige vers le port souhaité et l'app écoute sur ce port.
- networks: On expose le network sur lequel on attache les services du conteneur.
- volumes: On dit à Docker de monter le counter-vol (source:) vers le container (target:)
Docker : Docker compose
Quelques commandes utiles :
- docker-compose up : Démarre un conteneur en utilisant les infos dans le fichier docker-compose.yml
- docker-compose build : Build un conteneur sans le lancer, permet de pré-charger tout ce qui est nécessaire au démarrage du conteneur
- docker-compose restart : Redémarre un conteneur
- docker-compose down : Stop et supprime un conteneur
- docker-compose stop : Stop un conteneur
- docker-compose rm : Supprimer un conteneur (il doit d'abord être stoppé)
- docker-compose ps : Voir les statuts du / des conteneurs
- docker-compose top : liste les processus
Workshop
Sur ce workshop, je vous demande d'utiliser docker-compose pour mettre en place un conteneur avec :
- une base de données MySQL
- le système de fichiers Wordpress
Vous devez créer le fichier docker-compose.yml permettant de mettre en place un environnement :
- Déclarez le premier service DB et son image
- Définissez le volume pour faire persister vos données
- Définissez la politique de redémarrage du conteneur
- Définissez les variables d'environnement
- Décrivez votre second service : Wordpress
- Essayez de créer un volume afin de faire persister les données
C'est pas si facile, mais on corrigera ensemble après ne vous inquiétez pas si vous avez du mal.
Docker : CI avec Docker et Github Actions
Documentation et mise en place d'une CI / CD avec Docker
Suivez la documentation présente ici pour mettre en place un déploiement avec Docker
CI/CD avec docker-compose (& github actions)
Full documentation avec les différentes étapes plus avancées
Workshop Docker
Envoyer le workshop WS_CD_Docker_Minecraft.docx
Nous ne ferons pas ce workshop car il est très gourmand en ressources et pose souvent problème, mais on peut regarder rapidement ce qu'il faut mettre en place et je vous donnerai accès au repo de mon corrigé.
Workshop Render
Suivre le workshop guidé Deploy_with_render.md
Docker : Docker c'est vaste !!
- Docker Swarm : Permet d'orchestrer les conteneurs afin de pouvoir les coupler facilement et donc réaliser des sous ensembles plus petits.
Ces conteneurs sont donc plus facilement réutilisables dans un autre projet.
- Docker Networking : Permet d'améliorer la qualité des échanges réseaux nécessaires à une infrastructure contenant plusieurs conteneurs devant communiquer les uns avec les autres (vraiment dans les grandes lignes, car ça englobe aussi le paramétrage, la sécurité des échanges etc...)
- Docker overlay Networking: Pour être plus outillé sur la partie sécurité avec docker.
Schéma récapitulatif d'une CI / CD
Voir schéma sur draw.io
Rappelez-moi de vous envoyer le schéma en fin de formation !
Conclusion déploiement en continue
Nous mettons en place un déploiement continue lorsque de nombreux déploiement sont à prévoir.
Cette mise en place de CI / CD a un coût, mais il faut aussi savoir que déployer manuellement a également un coût et est source d'erreur. Aujourd'hui, toute application tend à viser le déploiement continue et automatisé.
Les objectifs finaux à retenir sont surtout le monitoring, l'alerte en continue et le paramétrage des données constantes des environnements.
Je vais vous envoyer une succession de TP qui vont nous permettre de tout revoir et tout mettre en place avec du PHP et MySQL.
- Création d'un dockerfile qui permet de faire un echo en PHP.
- Ajout d'une base de données mysql avec docker compose avec un script sql de création de base / table intégré dans un entrypoint
- Mise en place d'un docker compose complet qui permet d'avoir un lien entre le Dockerfile php et la base de données.
- Créer un environnement de tests et un environnement de production
- Réellement séparer ses environnements
- Créer un script d'initialisation des environnements
- Exploiter Github Actions pour ajouter une CI à tout ça et lier les branches develop à l'env de test et main à l'env de prod
Succession de TP
Réalisez un déploiement continu, trouvez un outil adapté à votre projet, essayez de le déployer en continu.
Je ne vais pas cacher que certains auront plus de facilité que d'autres, je saurai en aider certains. Pour d'autres, j'essayerai en tous cas.
A minima, je souhaite avoir la marche à suivre (Les outils, les éléments à remplir etc...) pour réaliser une CD sur votre projet. Expliquer les avantages de ce déploiement continu.
Facilité pour PHP, JS, .Net.
Bon courage !!
N'oubliez pas la notation se fera en partie sur cet exercice
Exercice fil rouge
Je vous propose de m'envoyer vos documents que vous utiliserez pour votre soutenance, je vous fait un retour dessus.
Durant ce temps, je vous propose de vous focaliser sur votre projet Cube, c'est la dernière ligne droite pour vous alors prenez le temps de bien faire les choses.
De retour sur votre projet Cube
Les commandes
UNIX
Envoyer Linux-Commands-Cheatsheet-FR.pdf
Cheat sheet - Unix
Gameshell
Un premier exercice vous permettra de travailler les commandes Unix sous forme de jeu.
Envoyer gameshell_Docker.md
Exercice - Unix
Unix
The Unix game
Un second exercice vous permettra de travailler les commandes Unix sous forme de jeu.
Accessible via ce lien :
Exercice - Unix
Unix
Ensemble de commandes à trouver
Voici un fichier contenant un ensemble de commandes que vous devez trouver !
Un peu moins guidé et plus complexe que les deux exercices précédents
Envoyer Exercices_Shell.md
Exercice - Unix
Unix
Le rôle d'un administrateur système
Sysadmin & DevOps
Le sysadmin a un rôle critique dans le bon déroulement d'une approche DevOps pour un projet :
-
Réalise et configure l'infrastructure
-
Automatisation du processus de déploiement
-
Monitorer et logger
-
Sécurité
-
Collaboration
Réaliser et configurer l'infrastructure
Cette première étape est primordiale pour le bon fonctionnement d'un projet à moindre coût.
-
Définir les besoins en infra
-
Choisir un outil de provisionnement : Terraform, CloudFormation, Ansible,...
-
Ecrire l'infrastructure as code
-
Tester et valider l'infra
-
Configurer
-
Amélioration continue
Automatiser les processus
L'automatisation des processus est également une grande étape pour le bon fonctionnement DevOps
-
Choisir un outil de déploiement : Jenkins, GitLab CI/CD, AWS CodeDeploy, Azure DevOps...
- Ecrire les scripts de déploiement
Tuto
Jenkins
https://medium.com/@gustavo.guss/quick-tutorial-of-jenkins-b99d5f5889f2
Ansible
https://docs.ansible.com/ansible/latest/getting_started/index.html
https://www.redhat.com/en/interactive-labs/ansible?extIdCarryOver=true&sc_cid=701f2000001OH7YAAW
Exercices et ressources supplémentaires
https://github.com/bregman-arie/devops-exercises/blob/master/topics/ansible/README.md
Monitorer et logger
Nous l'avons déjà vu, mais pour faire du DevOps, il est nécessaire de monitorer et logger le plus de choses possibles afin de suivre la vie du projet
-
Choisir un outil de monitoring et de logs : Prometheus, ELK stack, Grafana,...
-
Configurer l'outil
Tuto
Grafana
Tester et valider
Nous l'avons déjà vu, mais pour faire du DevOps, il est nécessaire de tester l'infrastructure du projet afin de s'assurer de son bon fonctionnement
-
Choisir un outil : Test Kitchen, Serverspec, Packer...
-
Ecrire les tests
Documentation
Serverspec
Sécurité
Nous en avons aussi brièvement parlé, mais la sécurité est un aspect primordial pour une application aujourd'hui. DevOps contient cette partie.
-
Les tests à réaliser : Scanneur de sécurité, système de détection d'intrusion, scanneur de vulnérabilité,...
-
Sécuriser l'infrastructure : Suivre les bonnes pratiques telles que le renforcement des serveurs (fermé le maximum de choses), chiffrer les données, utiliser des firewalls, mise en place du Secure By Design...
-
Implémenter des tests de sécurité : Identification des vulnérablités, problèmes de configurations, etc... Par exemple, SonarQube et Checkmarx sont des outils qui peuvent effectuer en partie ces tests de manière automatisée.
-
Intégrer l'outil dans le process de déploiement : Mise en place de l'outil dans une CI afin de lancer des tests de sécurité.
-
Monitorer la sécurité en continue
Démo
Mise en place d'une analyse sécurité et qualité avec SonarCloud
Ensemble d'exercices DevOps
Exercices DevOps
Le lien suivant contient de nombreux labs permettant de travailler vos compétences de DevOps, une partie gratuite déjà bien fournie vous permettra d'apprendre !
Exercices DevOps
Le lien suivant contient de nombreux exercices sur tout ce que nous avons pu aborder durant la formation et bien plus encore...
Je vous conseil de le garder et d'y passer de temps en temps pour appréhender de nouveaux sujets
Intégrer la sécurité dans son cycle de déploiement continue
S-SDLC
Secure-Software Development Life Cycle
Le S-SDLC concerne à la fois les manageurs et les développeurs dans une entreprise. Ce procédé n'est pas encore très répandu dans les entreprises, bien qu'il soit très efficace. Nous allons survoler les différentes étapes de mise en place d'un S-SDLC (méthodes agiles).
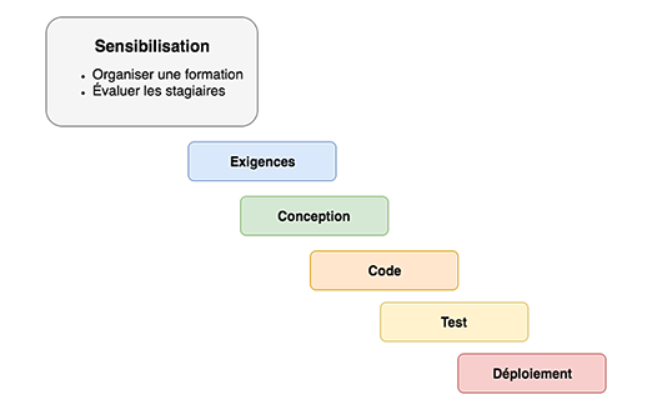
les développeurs
S-SDLC
Seconde étape
Exigences : phase importante où l'on défini les besoins en sécurité de l'organisation ainsi que l'élaboration du plan d'action et l'analyse de coût de la mise en place d'un S-SDLC
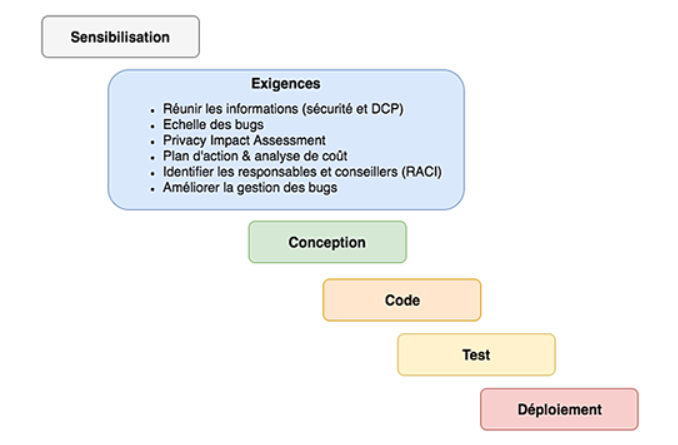
S-SDLC
Troisième étape
Conception : cartographie de l'architecture autour de l'application pour en modéliser les menaces. On va anticiper pour réduire les menaces potentielles.
Mieux vaut prévenir que guérir ! "
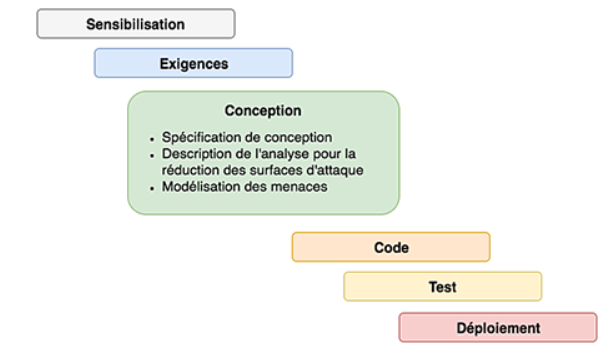
S-SDLC
Quatrième étape
Code : Déterminer les règles de développement à suivre et penser à effectuer une analyse de code statique !
Ces règles devront être respectées par toutes les parties prenantes de votre projet.
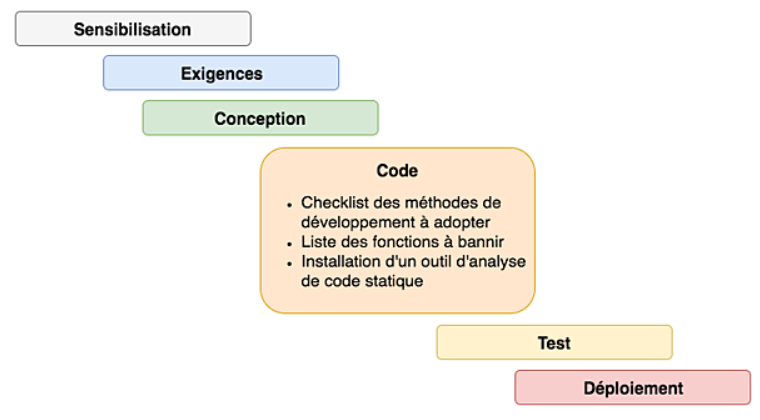
S-SDLC
Cinquième étape
Test : S'assure de la sécurité de manière dynamique avec l'utilisation de scans de vulnérabilités (dynamique), tests de fuzzing, ou tests de pénétrations.
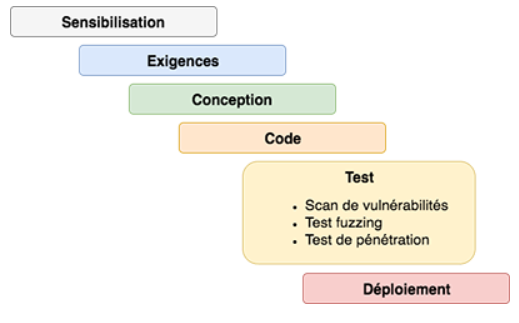
S-SDLC
Sixième et dernière étape
Permet l'analyse des écarts entre les principes définis lors de l'étape 2 et la réalité du code applicatif de notre application.
On réalise également un plan de réponse aux incidents (écarts), puis on réalise une revue finale de sécurité.
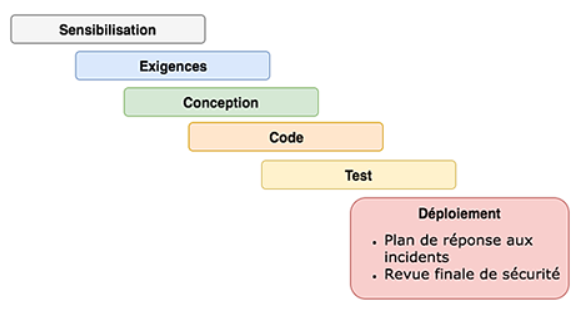
Dossier d'exploitation
Contenu du dossier de déploiement
- Présentation du logiciel
- Le manuel des opérations (configuration des logiciel et du système (inclus CI / CD mise en place) + commitologie git)
- Démarrage et arrêt (Reprise d'activité et PCA)
- Le traitement des informations
- La gestion des accès et de la sécurité
- Sauvegarde et restauration
-
Les opérations de maintenance - Gestion des montées de version de la base de données
-
Préparation du passage de compétences
Normalement, vous avez eu une journée de formation sur le dossier d'exploitation alors ça sera uniquement un rappel. Si ce n'est pas le cas, on va voir ça ensemble.
Dossier d'exploitation
Pour le dossier d'exploitation
- Dossier de déploiement
- Plan de sécurisation
- Plan de tests et recette
Pour la maintenance
- Tierce Maintenance Applicative
- SLA
- (OLA)
Ce qu'il vous faut absolument pour votre projet Cube
Dossier de déploiement (DFS)
Pour le plan de déploiement, il faut :
- Commitologie (façon d'utiliser git et les branches)
- Architecture du projet
- Intégration continue (Workflow et contrôles automatisés effectués)
- Déploiement continue (Outils utilisés et méthode de déploiement)
- Gestion des montées de version de la base de données
Ce qu'il vous faut pour votre projet fil rouge (DFS MNS)
Types et contrats de maintenance
La maintenance, c'est quoi ?
La maintenance vise à vérifier, entretenir l'application ou son infrastructure.
Le rôle du contrat est d’englober le mode et le périmètre d’intervention de l'entreprise ainsi que le niveau de responsabilité qui lui revient.
Il y'a plusieurs types de maintenance :
- préventive : maintenance en continue, via des audits, analyses de code, passage de scanner (SonarQube, Checkmarx,...)
- curative : Correction d'une anomalie (souvent gratuit si en rapport à un souci de dev)
- évolutive : Amélioration en continue de l'app.
TMA / SLA / OLA
Vous allez devoir mettre une Tierce Maintenance Applicative qui respecte le Service Level Agreement et l'Operating Level Agreement.
Oui, là on va s'ennuyer sévère mais c'est important pour rentabiliser un projet sur le long terme.
- TMA : Tierce Maintenance Applicative, confier l'infogérance à une équipe externe.
- SLA : Service Level Agreement, on défini les services à maintenir et les relations entre les parties prenantes.
- OLA : Operating Level Agreement, objectifs en niveau de qualité de service et d'infrastructure
SLA, plus précisément
Ce que doit préciser un SLA :
- Le type de service à fournir,
- Le niveau de performance souhaité des services, en particulier sa fiabilité et sa réactivité,
- Les étapes à suivre pour signaler les problèmes,
- Le temps de réponse et les solutions aux problèmes,
- Le suivi des processus et les rapports de niveau de service,
- Les répercussions pour le fournisseur de services qui ne respecte pas son engagement
On l'évalue selon sa disponibilité, sa fiabilité, la fonctionnalité à réaliser, les temps de réponse, la degré de satisfaction...
Un exemple pour rien oublier...
Une TMA plus en détail :
https://docplayer.fr/1804563-Tierce-maintenance-applicative.html
Exemple de document :
https://docplayer.fr/2426163-Contrat-de-maintenance-applicative.html
Evaluation
Partie théorique
Envoyer fichier deployment_theory.docx
Partie pratique
Worskhop d'une demi-journée de mise en place d'une CI / CD avec les technologies de votre choix.
L'idée est d'avoir une CI / CD complète et un environnement complètement automatisé avec tout ce que l'on a vu.
Envoyer le sujet WS_CI_CD_Full.docx
BON COURAGE !
(après c'est fini)
Evaluation
Tests & CI
Pour PhoneNumber, la classe a un constructeur privé et l'objet s'instancie via la méthode Parse
PhoneNumber phoneNumber = PhoneNumber.Parse("0123456789");
// phoneNumber est un objet instancié de type PhoneNumber si pas d'erreur
// Donc vous pouvez accéder aux propriétés Area, Minor et Major via phoneNumber.Area ou phoneNumber.Minor ou phoneNumber.Major