Optimisation des développements
Cédric BRASSEUR
Mis à jour le 03/11/2025

Cédric BRASSEUR
- Ancien étudiant de l'Exia.cesi
- 4 ans consultant chez Amaris, placé chez Euro Information Dev
- Auto-entrepreneur depuis début 2020 (Création de sites web, applications mobiles & formateur)
Et vous ?
- Nom, prénom
- Etudes réalisées
- Connaissances en dév
- Autres infos appréciées
Plan du cours
-
Mise en oeuvre de la stratégie de développement
-
Introduction au développement qualitatif en entreprise
-
Choix de la méthodologie de gestion de projet et de la méthodologie de développement
-
Revues de code (Intégré à la PR)
-
Sous-traitance / Consulting
-
-
Mise en oeuvre d'un outil d'audit de qualité de code
-
Intégration de SonarCloud dans la CI
-
Les différents indicateurs de qualité
-
Les autres outils de qualité (pour le web par exemple)
-
Exercice de développement qualitatif
-
-
Axes d'améliorations du code source
-
Design Patterns
-
Tests
-
-
Gestion de la dette technique

Opti
Dev
Objectifs de la formation
-
Développer en tenant compte des priorités de l'entreprise sur la dette technique
-
Mettre en oeuvre les outils de qualité
-
Comprendre la qualité logicielle et la dette technique

Mise en oeuvre d'une stratégie de développement
Introduction optimisation
Les entreprises se soucient de plus en plus de la qualité du code sur leurs projets.
Cette optimisation passe par de nombreux aspects et le niveau d'exigence dépend de nombreux facteurs :
- Les attentes du client en termes de qualité
- Les forces et faiblesses des équipes de travail
- L'expérience et les formations des développeurs de l'équipe
- Les contraintes des projet (projet interne, projet externe, projet pour un client exigent,...)
- Les méthodologies employées (gestion de projet, dév, tests,...)
- Les outils utilisés
C'est quoi un code optimisé ?
Chaque développeur a son propre point de vue sur ce qu'est un code propre. La plupart du temps, on a plus une liste de choses que l'on ne veut pas voir plutôt qu'une recette miracle.
Attention :
- Le Clean Code est très subjectif
- Vous serez en constante évolution au cours de votre carrière, au départ c'est un frein à votre productivité car vous devez faire des efforts supplémentaires.
Quand doit-on coder propre ?
Dans l'idéal, il faudrait toujours coder le plus proprement possible, quelque soit le développement en cours. Mais dans la réalité d'une entreprise, on ne peut pas travailler uniquement la qualité.
Mise en garde :
- Vous allez sûrement avoir une phase ou vous allez vouloir faire de la sur-qualité "inutile"
- La deadline est un facteur qui impacte la propreté du code (on reviendra sur ça, mais c'est un fait en entreprise)
Ce qui est attendu de vous ?
Savoir être
Savoir faire
Savoir penser
Savoir structurer




Savoir être
Le savoir être englobe plusieurs softskills, élever le niveau, savoir communiquer, savoir tirer profit de l'expérience des autres et apporter son expérience aux autres, et ça ne concerne pas que vous...

Savoir être
Ethique et attitude de codeur responsable :
- Zéro mythos : Faire ce qu'on dit, dire ce que l'on fait
- Agilité en entreprise, appliquer ou faire appliquer les principes agiles
- Communication, feedback en continue
- Savoir dire non (même au big boss)
- Vous êtes une startup
Développeurs heureux, code fabuleux !

Savoir être
Se regarder dans le miroir avant de critiquer les autres ! Souvent, c'est par manque de connaissance, ou parce que le contexte ne permettait pas de réaliser du clean code qu'on livre du code sale.
Donc soyez indulgent avec les autres, mais ne le soyez pas avec vous-même.



Si ça ne vous est pas encore arrivé, ça vous arrivera un jour !
Don't blame !
Blame, but efficiently
Savoir être
Agilité et feedback en continue
- TDD et BDD : feedback sur les intentions de test.
- Pull Requests et Code Review : feedback sur les livraisons de code.
- Intégration et Déploiement continu : feedback sur l’intégration et fiabilité de la chaîne de déploiement.
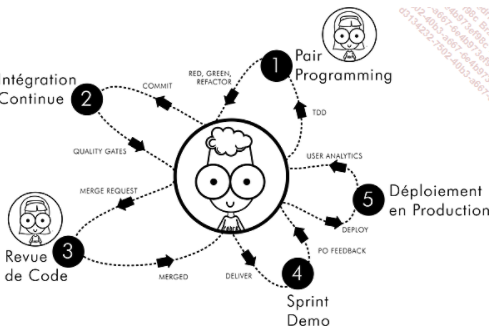
Savoir être
Rappels sur les méthodes agiles
- Releases périodiques et fréquentes (toutes les 2 semaines max)
- Intégrer le client dans le cycle
- Utilisation d'une préproduction
- Pull request et revue de code obligatoire
- Intégration et déploiement continu (et si possible livraison continue)
- Daily meeting (scrum meeting)
- Démo et réunion de rétrospective
- Afficher les dashboards nécessaire au monitoring d'un projet
Pourquoi la qualité
&
Pourquoi l'agilité ?
Les entraves au clean code
Vu comme ça, c'est beau, mais il y a des entraves au clean code.
- Les fondements et normes des entreprises qui n'évoluent pas toujours au bon rythme.
- La méthodologie a un impact important sur le clean code.
Mise en garde :
- Vous allez sûrement avoir une phase ou vous allez vouloir faire de la sur-qualité inutilement
- La deadline est un facteur qui impacte la propreté du code (on reviendra sur ça, mais c'est un fait en entreprise)
Les entraves au clean code
Le nombre de développeurs dans le monde a une courbe de croissance extrêmement élevée au fil des années.
Environ un facteur double tous les 5 ans.
Ceci engendre que :
- Tous les 5 ans, la moitié des développeurs est inexpérimentée
- On doit tous apprendre aux moins expérimentés à développer proprement selon ses connaissances
- On doit s'attendre à ce que tout ce que l'on délivre soit clean. C'est ce qu'un client attend d'un programme, on doit donc avoir la même attente de nos devs
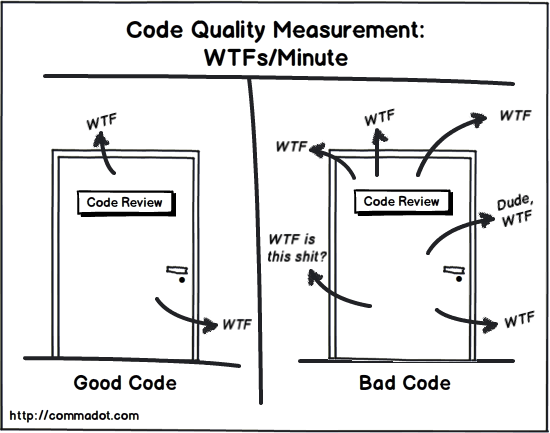
Comment juger le Clean Code ?
Un des pionnier du Clean Code (Robert C. Martin) propose une façon simple d'analyser si du code est propre ou non. Il suffit de compter le nombre de "WTF" / minute lors d'une revue de code.
Savoir faire
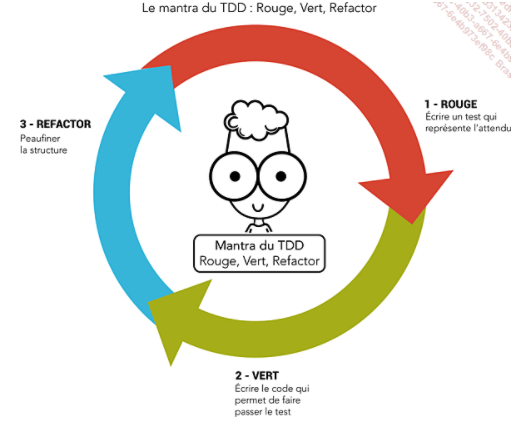
L'utilisation de tests est primordiale ! Une technique que l'on va approfondir plus tard durant la formation : le TDD.
Et dans une future formation, le BDD également !
On test en mode agile, dans le but d'avoir un test en continu et présent dans notre intégration continue.
Savoir structurer
Plusieurs principes sont clés pour ce savoir :
- Gestion dette technique
- Le DDD (Domain Driven Design)
- Architecture propre et S0LID

Savoir penser
Encore un savoir assez abstrait, un peu comme le savoir être. Nous aborderons plus en détail ce savoir en conclusion de la formation, sûrement même après l'évaluation !
Un avant goût de ce que l'on verra :
- Veille technologique
- Intéressez-vous à ce que disent les développeurs expérimentés (Martin Flower, Robert C. Martin, ...)
- Pragmatisme et concentration
- Think first act last
Mettons nous dans le bon état d'esprit...
Exercice solo :
Le but de cet exercice n'est pas de réaliser du code complexe, il est de réaliser l'exercice en essayant d'avoir le code le plus "Clean" possible selon votre expérience personnelle actuelle.
Vous pouvez réaliser un développement sur ce que vous voulez, l'exercice doit durer 45min / 1 heure maximum
Je vous propose de réaliser un mini rogue like si vous n'avez pas d'idée. Pas besoin d'interface particulière, le jeu peut être de simples affichages dans la console.
Envoyer roguelike.md
Revue de code avec le voisin !
Exercice duo :
Le but de cet exercice est de prendre 20 minutes pour faire une revue de code réalisé par son voisin.
On ne critique pas le code du voisin, on propose des améliorations et son point de vue.
Car le voisin va également faire une revue de votre code de 20 minutes également.
Mettez sur un fichier les différentes remarques que vous vous faites entre vous !
Axes d'améliorations de la qualité du code
Introduction - Savoir faire
On l'a dit précédemment mais le clean code est assez subjectif, dans cette partie je vais vous proposer une vision des choses que j'applique et complétée par celle qui est proposée par Robert C. Martin.
- Ne pas laisser de surprise dans son code
- Coder lentement mais efficacement !
- Il est très rare qu'un développeur puisse développer dès la première itération du clean code. L'objectif premier étant de faire fonctionner nos développements, il est nécessaire de repasser sur ces développements pour les rendre propres
==> Refactoring
Conseils et exemples
Les commentaires
Quel est votre avis sur les commentaires dans le code ?
Quand faut-il en mettre ? Quel pourcentage par rapport au code ?
?
?
?
Les commentaires
Ne jamais tout commenter
Un exemple de code commenté intégralement, regardez bien :
Deux remarques à faire !
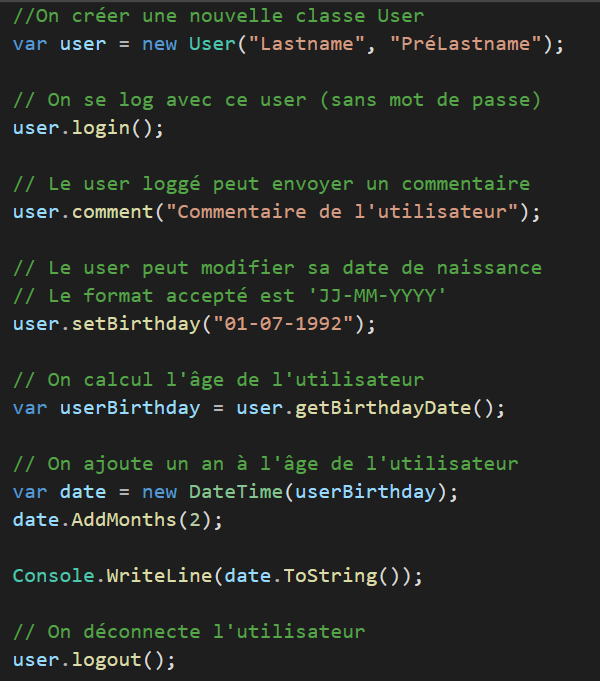
Les commentaires
Maintenance des commentaires ?
Dans la réalité des choses, les commentaires ne sont pas maintenus, il arrive même qu'ils n'aient plus rien à voir avec la ligne en dessous, suite à un refactoring ou autre raison.
Le conseil qui est donné par Robert C. Martin est de ne pas commenter son code, si un commentaire est nécessaire autant le factoriser et le rendre plus clair !
"Un commentaire est un échec dans la clarification de votre code"
Il faut nuancer un peu quand même, certains commentaires ont leurs places dans votre code. Et parfois nous n'avons pas le temps ou pas les connaissances pour rendre le code plus clair, donc le commentaire reste intéressant.
Les commentaires
Les commentaires utiles
Le commentaire informatif : Celui qui donne une information sur un format d'entrée accepté par une méthode par exemple.
Les commentaires sur des conditions : Ici on ne commente pas, on créer une méthode dont le nom explique la condition.
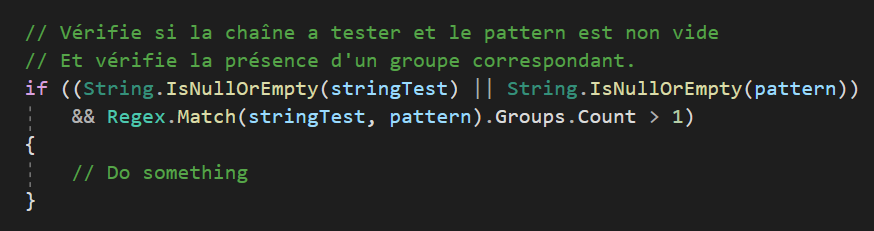


Les commentaires
Les commentaires utiles
Le commentaire clarifiant : Dans le cas de suite d'opérations arithmétiques par exemple pour un test.
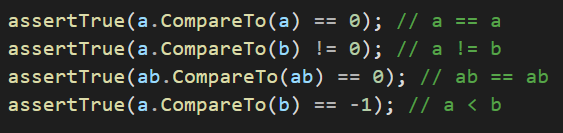
Le commentaire utile : Dans le cas de la réalisation d'une opération non compréhensible par le contexte
Les commentaires
Les commentaires obligatoires
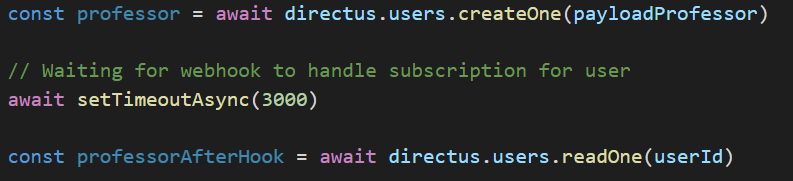
Le commentaire copyrights : Il est fréquent que le copyright d'entreprise soit nécessaire sur vos développements
Le commentaire pour la documentation automatisée : Si le besoin d'avoir une doc est présent, faites le... Mais excepté pour la doc, on est vraiment dans le commentaire complètement inutile.

Les commentaires
Les mauvais commentaires
Quelques exemples de mauvais commentaires :
- Les commentaires manquant de clarté
- Les commentaires redondants
- Les commentaires pour la documentation (Si elle n'est pas obligatoire selon le contexte ça n'a pas de sens)
- Les commentaires de versionning et de signature "Fait par BRASSECE", git sait très bien nous dire ça
- Les commentaires d'accolades fermantes
Les standards de développements
Bien nommer ses variables
Aujourd'hui, il est possible de nommer les variables comme on le souhaite, profitons-en pour les nommer correctement !
En C# la convention est d'utiliser le PascalCase pour quasiment tout, les classes, les propriétés, les méthodes,...
Dans d'autres langages on va plus utiliser le camelCase.
Chaque variable doit représenter ce qu'elle va contenir : parfois on va même mettre le type de la donnée dans le nom de la variable (mais souvent l'IDE sait vous donner l'information, donc elle serait redondante dans ce cas)
Anecdote Fortran
Les standards de développements
Bien nommer ses variables
J'espère que ça vous semble logique de bien nommer vos variables, mais si ça semble annodin c'est nécessaire et mérite de la réflexion.
- Choisir des noms exprimant vos intentions dans le code
- Eviter la désinformation
- Penser ses noms pour des recherches dans le projet
- Eviter les codifications
- Choisir des noms en rapport au contexte / domaine
- Choisir un mot par concept et le garder cohérent (exemple : fetch / retrieve / get,...)
- Eviter les noms qui se ressemblent trop (surtout s'ils sont longs)
Les standards de développements
Bien nommer ses fonctions / méthodes
Les méthodes sont des actions, lorsque l'on verra le principe du découplage, nous verrons que chaque méthode devrait en principe faire qu'une seule chose.
Une méthode représente une action, elle doit donc avoir un contexte verbeux et il faut choisir un nom révélateur.
Exemples :
- InsertClient(),
- GetAllClients() ,
- GetCarById(),
- ...
Les standards de développements
Une fonction doit faire une seule chose et doit la faire bien
Selon Robert C. Martin, les fonctions devraient réaliser qu'une et uniquement une seule chose. Il faudrait donc extraire chaque "chose" pour en faire une fonction. Il en décrit copieusement les avantages et la clarté de code qui en découle. La difficulté réside dans le fait de savoir quand est-ce que l'on fait une seule chose.
Je n'en suis pas encore à ce niveau d'abstraction, mais le Clean Code est un chemin à suivre toute sa vie, ma vision et mes attentes évolueront au fil des années d'expériences.
Les standards de développements
Les arguments d'une fonction
Personnellement, j'essaye de limiter au maximum le nombre d'arguments dans mes fonctions (3 max)
A savoir aussi sur les arguments :
- Le problème des arguments est qu'ils mélangent souvent plusieurs niveaux d'abstraction,
- Les arguments sont même encore plus pénibles du point de vue des tests. Imaginez la difficulté que représente l’écriture de tous les cas de test qui permettent de vérifier que les différentes combinaisons des arguments fonctionnent...
- Passer une valeur booléenne à une fonction est véritablement une pratique épouvantable !
Faites des classes !
Les standards de développements
Les instructions avec accolades
Une instruction avec accolade (if, foreach,...) devrait dans l'idéal ne jamais être utilisé avec des accolades, ceci forçant cette instruction à faire une seule chose.
Vous l'aurez compris, la plupart du temps, on va développer une fonction et appeler cette fonction en passant à la ligne avec une tabulation.
Les standards de développements
Attention à l'instruction switch !
Un switch ne peut par définition pas réaliser qu'une seule chose. Ils sont donc déconseillé (pas interdit).
Déconseillé car :
- En général, si vous avez un switch, vous en aurez d'autres qui vont suivre dans d'autres parties de vos développements.
- En termes de déploiement, le switch nécessite de déployer toutes les fonctions / classes / méthodes de tous les switchs en cas de modification
- Difficile de retrouver toutes les occurrences (if ?)
- Violation du SRP et Open/Close Principle
- Difficile à tester efficacement
- Rupture avec le polymorphisme
Un switch devrait être cloisonné, placé derrière une factory method / abstract factory et nous verrons ça quand nous parlerons de Design Patterns.
Les standards de développements
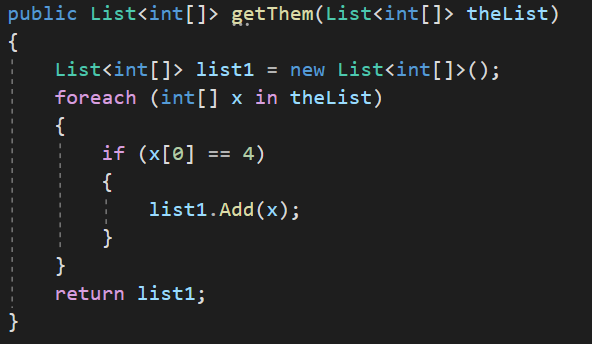
Un exemple de code et de simplification
Ce bout de code est pas simple à comprendre, vous ne trouvez pas ? Et pourtant...
Comment l'améliorer ? Le rendre compréhensible ?
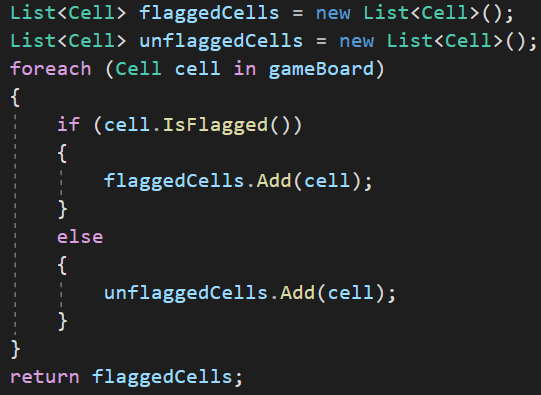
Les standards de développements
Deux étapes pour améliorer le code précédent
- On renomme correctement les variables, les méthodes et les arguments
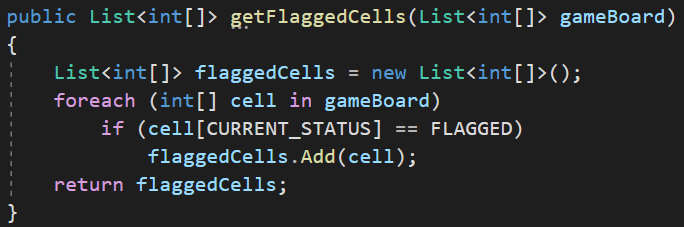
On comprend déjà beaucoup plus de quoi on parle et quel est l'objectif de ce bout de code
Les standards de développements
Deux étapes pour améliorer le code précédent
- On créer une classe Cell pour clarifier ce int[] et l'utilisation de constantes
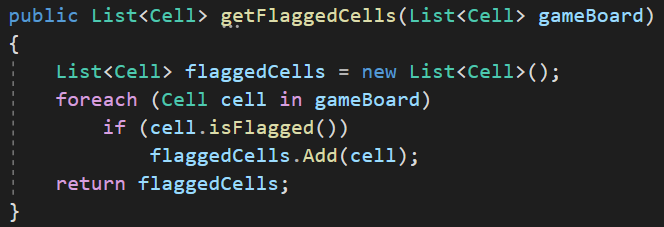
Il n'y a pas vraiment plus de ligne de code et aucun besoin de commentaire pour comprendre ce que cette méthode fait.
DRY Principle
Ne vous répétez pas
Un code propre est un code qui ne contient pas de répétition. Lorsqu'une répétition se trouve dans votre code il vous faut factoriser en créant une fonction et remplacer les doublons par un appel à cette fonction.
En tant que développeurs, nous avons souvent tendance à utiliser le copier coller, il faut être vigilant...
C'est très simple à mettre en place mais pas toujours à identifier il faut donc être attentif ou utiliser un outil d'analyse de code tel que SonarQube pour détecter ça.
L'avantage principal : Une erreur dans le code dupliqué n'est pas à corriger à plusieurs endroits, elle n'est à corriger que dans la fonction factorisée.
La mise en forme
Introduction et importance
En début de formation nous avons parlé du nombre de WTF pour évaluer le Clean Code. La mise en forme de votre code est très importante pour la compréhension du code et donc la qualité de celui ci.
Soyons clairs, le formatage du code est extrêmement important, la fonction que vous développez aujourd'hui va évoluer et doit être maintenable, pensez à celui qui passera derrière vous.
Nous allons voir comment mettre en forme sur deux axes :
- La mise en forme verticale : lecture et compréhension du code ligne par ligne.
- La mise en forme horizontale : largeur de ligne et indentation.
La mise en forme
La mise en forme verticale
- Bien nommer le fichier : On doit savoir au premier coup d'œil de quoi on parle
- Voir son code comme un "journal" : On le rend lisible de haut en bas, en intégrant les concepts détaillés en bas de fichier
- Un journal pas trop long ! Il n'y a pas de vraie règle absolue, mais disons que plus ils sont courts mieux c'est. 200 lignes semblent d'après moi un maximum à éviter de dépasser
- Espacement vertical des concepts : Bien séparer les concepts avec un saut de ligne
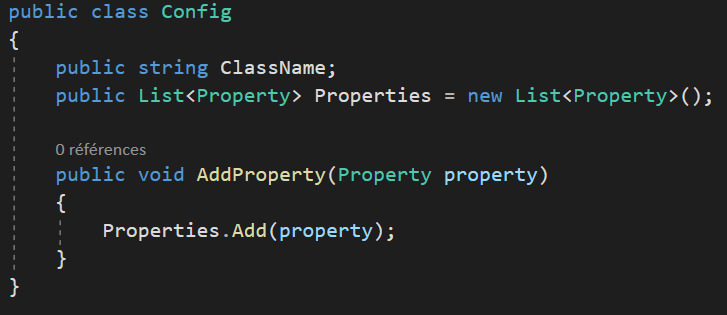
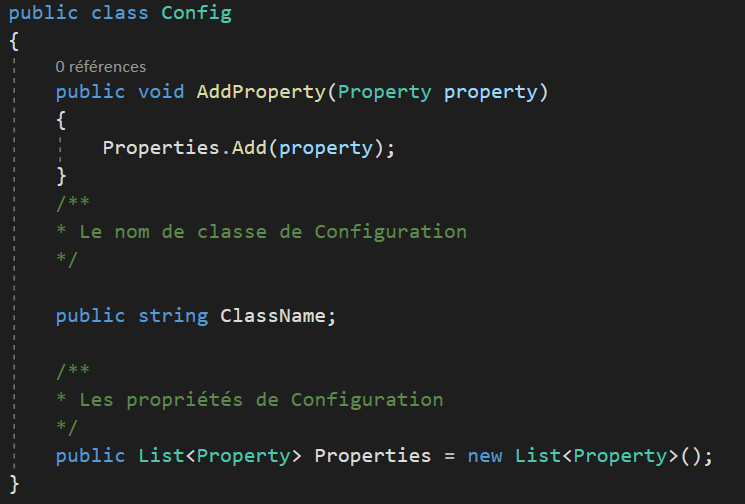
- Organiser son code proprement : Associer les propriétés, puis constructeur, puis associer les méthodes en liens et dont les concepts se suivent en allant du plus haut niveau vers le plus bas.
La mise en forme
Exemple : La mise en forme verticale
La mise en forme
La mise en forme horizontale
- La taille d'une ligne de code ne doit pas dépasser (dans l'idéal) 120 caractères pour pouvoir être affiché sur un écran sans avoir à scroller vers la droite.
- Le nombre de tabulation en début de ligne défini un ensemble d'instructions communes effectuée dans la même portée.
- Mauvaise pratique : Aligner les initialisation de variables, ça n'apporte pas une meilleure lisibilité
- La tabulation (en début de ligne) permet de simplifier grandement la compréhension
- Eviter les "tout en une ligne", autant faire le saut de ligne et la tab.
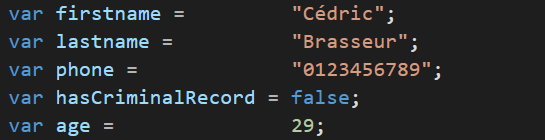
La mise en forme
Exemple : La mise en forme horizontale
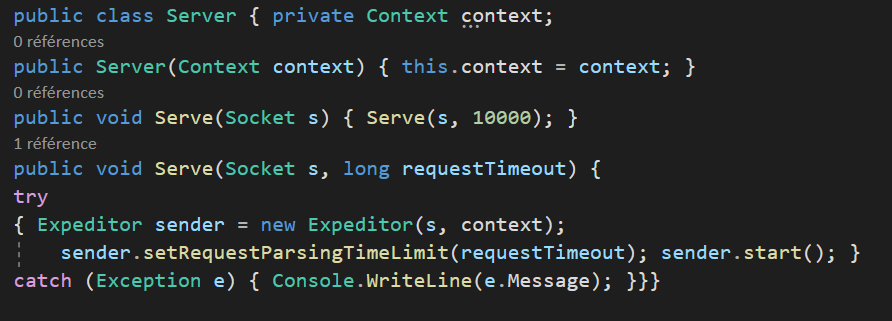
La mise en forme
Exemple : La mise en forme horizontale
Pour définir les normes : Appliquez des règles d'équipe
La mise en forme
Outil d'analyse automatisé et Linter
Un linter va analyser syntaxiquement votre code selon certaines règles (Exemple Resharper, ESLint,...) que vous mettez en place au fur et à mesure avec votre équipe de développement.
Durant la phase d'intégration continue il est fréquent d'utiliser un outil d'analyse de la qualité de votre projet. Exemple SonarQube, qui calcul des métriques de qualité de code souvent très utiles.
Nous allons voir comment mettre en place cet outil, avec SonarCloud, en ligne, simple à associer à un repo github.
Le gestionnaire de code source
Outil de versionning
Nous n'allons pas voir comment fonctionne un gestionnaire de code source (même si durant les exercices je peux vous aider à prendre en main git, si besoin).
Je tiens juste à rappeler les avantages en termes de Clean Code :
- Premièrement, le gestionnaire de code source va nous permettre d'éviter un certain nombre de commentaires inutiles (comme vu précédemment)
- Il va permettre de mettre en place une revue de code efficace sur les changements qui ont été réalisés pour la fonctionnalité
- Il permet de retrouver le code précédent en cas de besoin
- Et bien d'autres avantages également...
Systématique !
L'intégration continue
La CI pour le bien de tous
L'intégration continue a pour objectif de faciliter la tâche aux développeurs pour gérer leur code source et réaliser les tâches tout en rajoutant une couche de sureté avec différents tests automatisés lors des merge (ou commit d'ailleurs).
Pour notre CI, on va mettre en place des étapes supplémentaires à notre validation de merge (déploiement impossible si rouge) :
- Vérifications des tests automatisés (inclus la sécurité et qualité)
- Réalisation de revue de code manuelle
- Vérification syntaxique du code (Linter)
- Gestion du build automatisé (générer les dépendances par ligne de commande, par exemple npm ci)
Systématique !
Importance des tests
L'objectif premier de réaliser des tests sur son application est de limité d'envoyer des erreurs en production.
On va donc tester les développements réalisés à chaque changement et surtout avant chaque mise en production, ce qui rend l'application plus robuste mais ne la rend pas infaillible.
- L'utilisation d'une CI/CD force la réalisation de tests et surtout de s'assurer qu'ils passent,
- L'identification des problèmes est donc réalisée bien plus tôt et plus simplement car tout est cloisonné,
- Plus de productivité (si industrialisé) et rendement.
Les différents types de tests
Il existe de nombreux types de tests, nous allons essentiellement travailler les tests unitaires lors de cette formation. Et les tests d'acceptation dans la prochaine (BDD)
-
Tests unitaires : On test atomiquement toutes les portions de notre code ! L'objectif des tests unitaires est de couvrir le plus de code possible 100% est la valeur que l'on tend à atteindre pour la perfection. (Mais difficile en pratique)
- Autres tests : Acceptation, interface, charge, performance, sécurité, exploitabilité, vérification de disponibilité immédiate,
La revue de code
Rendu obligatoire dans le process de déploiement continu !
Quelques règles pour la revue de code :
- Une revue de code ce n'est pas juste vérifier l'indentation, s'il y'a un ; à la fin etc... Notre Linter s'occupe de ça bien mieux.
- La revue de code doit prendre au minimum la moitié du temps qu'à pris le développement de la fonctionnalité.
- La revue de code est obligatoire (je me répète, mais c'est important)
- La revue de code est un moyen de prendre de l'expérience d'autrui et donner son expérience
- La revue de code fait parti du savoir faire.
Conseil en vrac - Clean Code
Autres conseils selon mon point de vue
- Il se cache souvent une classe derrière une méthode ayant plusieurs tabulations de profondeur de code, cette méthode doit sûrement définir des variables sur lesquelles elle travail ==> propriétés + méthodes.
- No side effects : Effets de paire, chaque new a besoin d'un free, chaque open a besoin d'être closed
- Garbage collection : On est mauvais pour faire ça et on a même inventé le moyen de nous éviter ce problème car le garbage collector fait ça pour nous. Mais quel est le problème potentiel ? Side effects.
- Open closed principle : Votre code doit être ouvert aux évolutions mais fermé aux modification (utilisation d'abstractions)
- TODO qui sont commits deviennent des non-dos. Donc soit vous faites le TODO avant de commit, soit vous retirez le TODO.
Conseil en vrac - Clean Code
Les principes SOLID
-
S – Single Responsibility Principle (SRP)
Une classe ne doit avoir qu’une seule responsabilité ou raison de changer. -
O – Open/Closed Principle (OCP)
Le code doit être ouvert à l’extension, mais fermé à la modification. -
L – Liskov Substitution Principle (LSP)
Une classe fille doit pouvoir remplacer sa classe mère sans altérer le comportement du programme. -
I – Interface Segregation Principle (ISP)
Il vaut mieux avoir plusieurs petites interfaces spécifiques qu’une grosse interface générale. -
D – Dependency Inversion Principle (DIP)
Les modules de haut niveau ne doivent pas dépendre des modules de bas niveau, mais tous deux doivent dépendre d’abstractions.
Exercice
Le but de l'exercice est simple : Refaire de zéro le roguelike en appliquant les conseils vu durant la formation
Mais en respectant au maximum tous les principes vu dans cette partie. Prenez bien le temps, cet exercice peut prendre plusieurs heures si vous appliquez tous les conseils donnés.
Réalisez quelques tests unitaires (4/5 suffiront pour l'exercice) et mettez en place une CI avec Github Actions
Si vous pensez avoir du code suffisamment Clean alors que les autres sont encore en train de développer. Vous pouvez soit me demander une revue de code, soit ajouter de nouvelles fonctionnalités.
Exercice
Revue de code sur les développements réalisés
Faites une revue de code entre vous prenez bien le temps de vous faire des retours sur ce qui a été vu en cours.
Mise en oeuvre d'un outil d'audit de qualité
Mise en place de SonarCloud en CI
Sonar
Les métriques analysées
Les smells applicatifs
Dans la couche applicative, on retrouve des smells qui impactent une solution sur plusieurs modules, classes et méthodes en étant associés à plusieurs emplacements dans l’application. Quelques exemples marquants :
- Chirurgie Shotgun (Shotgun Surgery) : une modification nécessitant d’être répliquée sur plusieurs classes en même temps.
- Complexité pour la complexité (Contrieved Complexity) : utilisation inutile, voire forcée, de design patterns compliqués quand ce n’est pas nécessaire.
Sonar
Les métriques analysées
Les smells de classe
Les classes smells regroupent tous les anti-patterns inhérents à une classe. Pour en énumérer quelques-uns :
- Feature Envy : une classe qui fait une utilisation abusive des méthodes d’une autre classe.
- Large class : une classe qui contient beaucoup trop de lignes de code, plus d’une centaine.
- Inappropriate intimacy : une classe qui accède aux détails d’implémentation d’une autre classe.
- Orphan variable or constant class : une classe qui a une collection de constantes dont elle ne fait pas usage et, par conséquent, dont elle ne devrait pas être maîtresse.
Sonar
Les métriques analysées
Les smells de méthode
- Utilisation de trop de paramètres : nous pouvons nous retrouver dans une situation où une méthode évolue avec le temps pour arriver au point où elle accepte beaucoup trop de paramètres en entrée.
- Méthode trop longue : elle contient beaucoup trop de lignes. En général, une méthode avec plus de 20 lignes pourra être considérée comme trop longue. Le premier réflexe serait de découper ce type de méthode en plusieurs sous-méthodes. Toutefois, une telle pratique pourrait cacher un problème de design qui, pour être résolu, nécessiterait un refactoring plus important, tel que la création d’autres classes.
Sonar
Allons voir la doc de SonarCloud
Sonar
SonarLint
Installation & présentation de SonarLint
Exercice
Exercice SonarCloud
Mettez en place l'intégration continue avec SonarCloud sur votre projet (ou sinon, réalisez une analyse sur votre poste avec SonarQube) regardez et corrigez un maximum des code smells / bugs qui vous sont remontés.
Prenez le temps de bien faire cet exercice, le but est vraiment de ne plus avoir de smells à cette version de votre code
Présentation de Lighthouse
Et les 4 axes qui sont analysés
Performances
Analyse des performances du site, temps de chargement, taille des images, premier affichage de la page d'accueil etc...
Accessibilité
Analyse de l'accessibilité à votre site, ça passe par les variances de couleurs, la taille des caractères, la police choisie, etc...
Les 4 axes analysés
Performances
Bonne pratiques
Un peu comme ce que propose Sonar sur votre site web, ici ça analyse le code source disponible et fait des retours dessus
SEO
"Search Engine Optimization", des retours directs sur votre ranking dans les recherches google.
A savoir : Les autres axes améliorent aussi votre SEO
Exemple & utilisation
Gestion de la dette technique
Gestion de la dette technique
Une fois de plus l'utilisation d'un outil d'analyse qualité est de mise ici : SonarQube
La dette technique correspond au temps nécessaire pour rendre votre projet plus propre et répondant aux critères que l'on a évoqués jusqu'ici durant la formation.
Gestion de la dette technique
On décide de réécrire un projet lorsque la dette technique dépasse la durée de réécriture d'un projet. Donc il faut avoir au préalable planifié la réécriture et voir si la dette technique dépasse cette durée, on réécrit tout !

Afin d'éviter ça, on vérifie régulièrement la dette technique et on investi du temps durant les sprints pour diminuer la dette technique au fur et à mesure de l'évolution du projet
Les principes SOLID
Un peu plus en détails & exercices
Les principes SOLID
Les principes SOLID
-
S – Single Responsibility Principle (SRP)
Une classe ne doit avoir qu’une seule responsabilité. -
O – Open/Closed Principle (OCP)
Le code doit être ouvert à l’extension, mais fermé à la modification. -
L – Liskov Substitution Principle (LSP)
Une classe fille doit pouvoir remplacer sa classe mère sans altérer le comportement du programme. -
I – Interface Segregation Principle (ISP)
Il vaut mieux avoir plusieurs petites interfaces spécifiques qu’une grosse interface générale. -
D – Dependency Inversion Principle (DIP)
Les modules de haut niveau ne doivent pas dépendre des modules de bas niveau, mais tous deux doivent dépendre d’abstractions.
Les principes SOLID
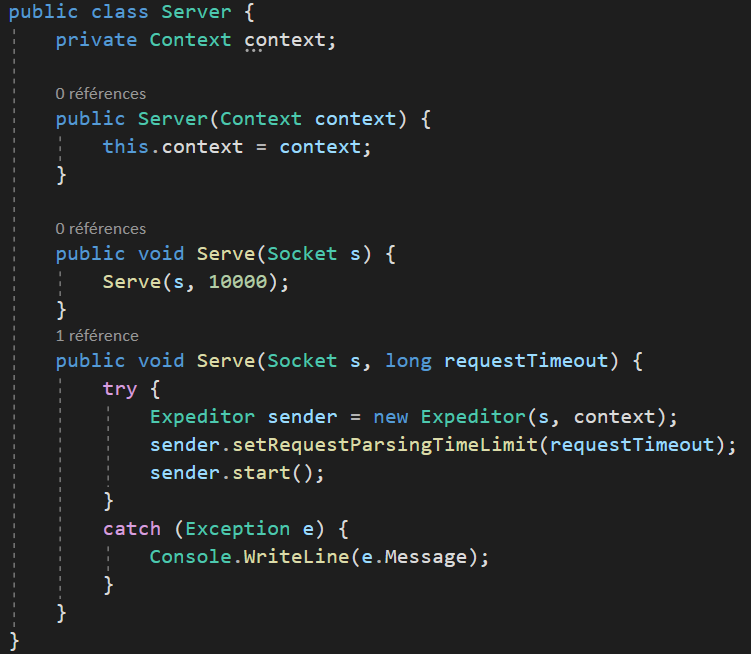
Single Responsibility Principle
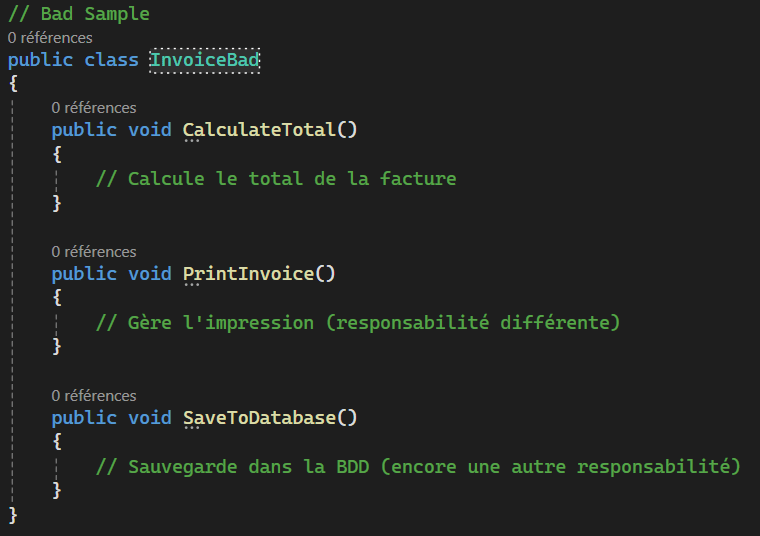
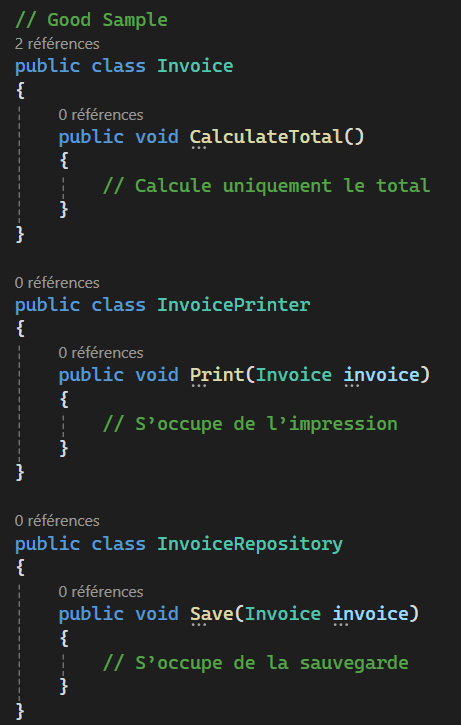
Les principes SOLID
Open/Close Principle
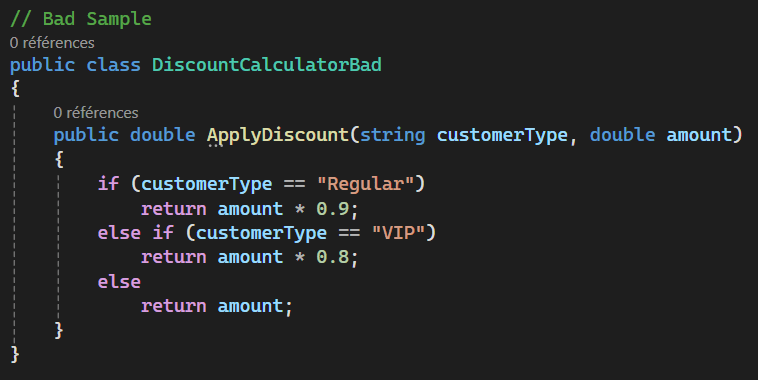
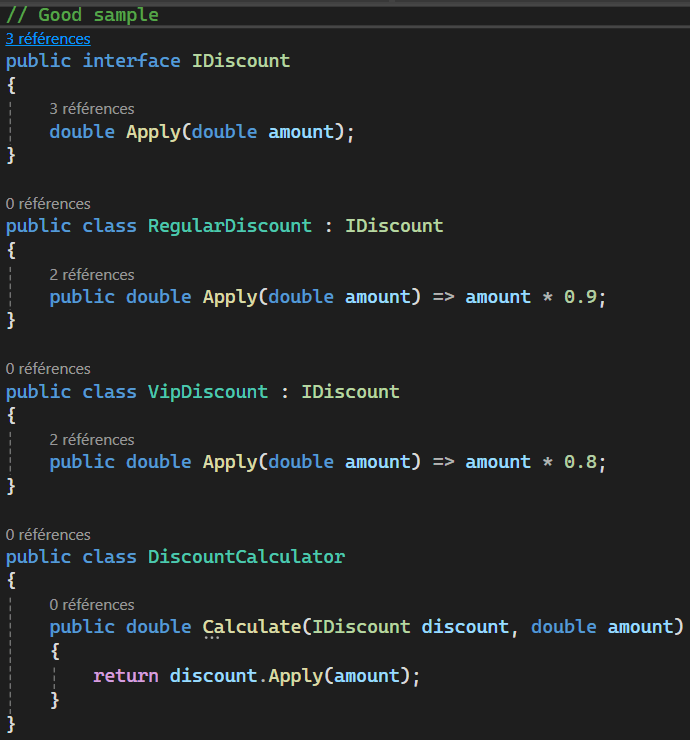
Les principes SOLID
Liskov Substitution Principle

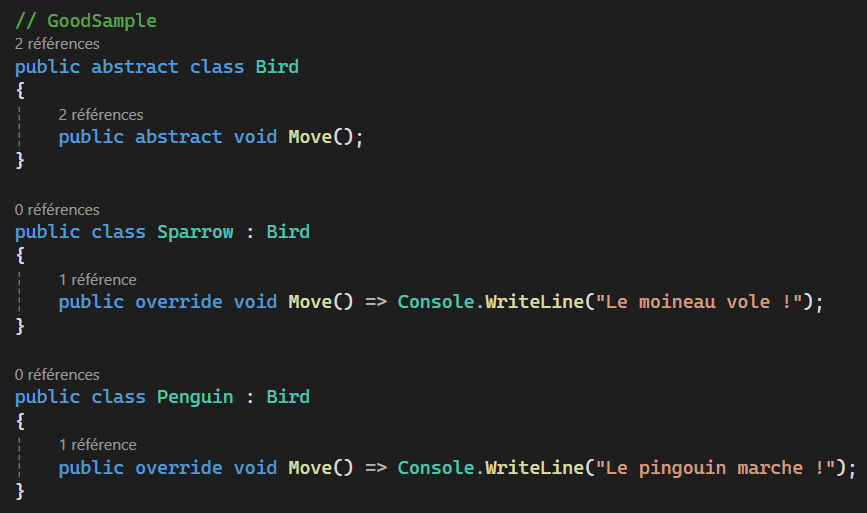
Les principes SOLID
Interface Segregation Principle
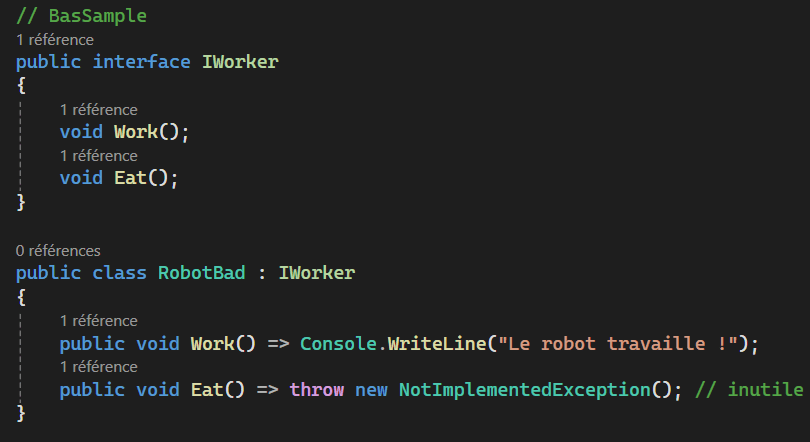
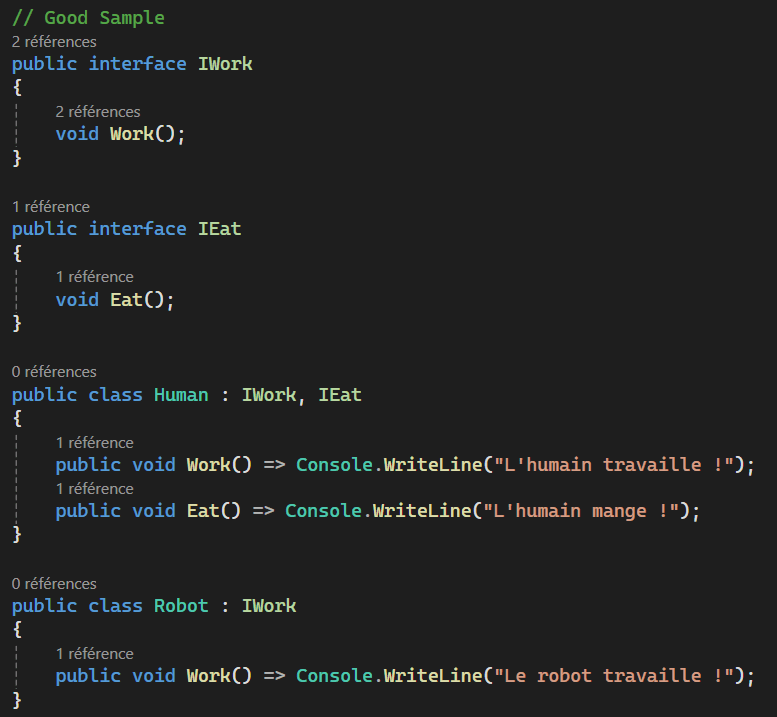
Les principes SOLID
Dependency Inversion Principle
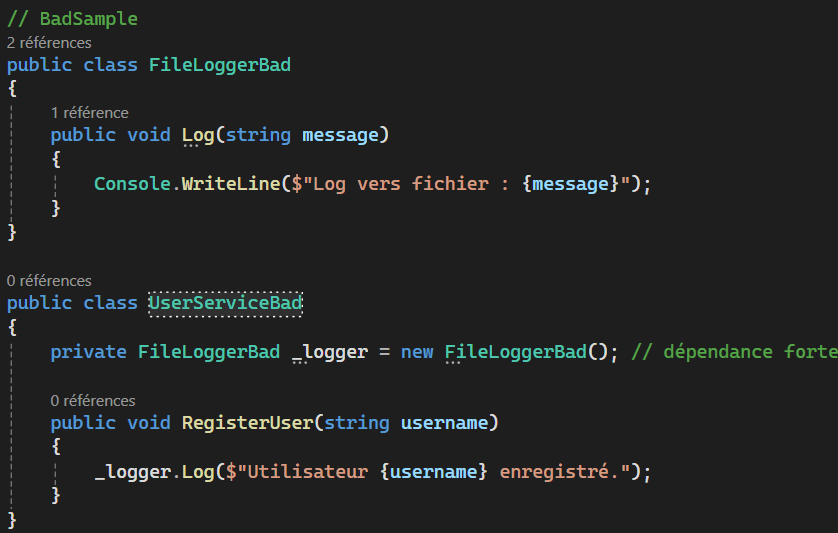
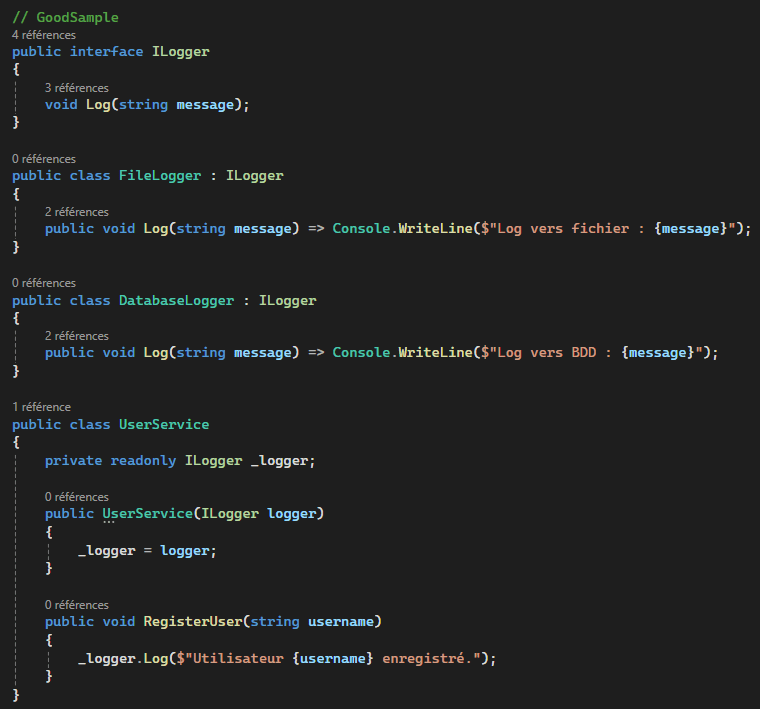
Les principes SOLID
Exercices
Envoyer Exercices_SOLID_C#.md
Les Design Patterns
Kesako ?
- Solutions architecturales à des problèmes objets
- Réutilisable à des problèmes de dévs récurrents
- Peu d’algorithmique quand on isole, plus des schémas orientés-objet (UML!!)
-
Façons d’organiser le code pour augmenter
- Flexibilité du code
- Maintenabilité du code
- Extensibilité du code
- Configurabilité du code
- (Diminuer) Duplication de code
- Le plus souvent basé sur des interfaces et abstractions


Les design patterns : classification
-
Patterns créateurs (Singleton, factory, abstract factory)
-
Patterns aidant à la gestion de la création d’objet
-
-
Patterns structurants (Façade, proxy, decorator, composite, adapter)
-
On parle de travailler sur la partie externe des classes du pattern. L’extensibilité et l’encapsulation des classes.
-
-
Patterns comportementaux (Strategy, iterator, observer, state)
-
Ici, on travaille sur la partie interne des classes du pattern. La dynamique des classes du pattern. Améliorer la qualité du code, éviter les duplications ou gérer des problématiques connues.
-
Mais d'abord...
Rappel de certaines notions objets importantes
La mise en place de Design Pattern va nécessiter des notions objets simples mais importante pour la compréhension de ces derniers. Nous allons revoir rapidement :
- Héritage
- Interface
- Composition
- Agrégation
- Classe abstraite
Définition
Définir une dépendance entre un objet observé et un ou plusieurs objets observants.
L’objectif étant de pouvoir notifier les objets observants lorsqu’un changement de statut est opéré sur l’objet observé.
Problématique
On a parfois besoin de connaître le changement de statut d’un autre objet. Il est possible d’interroger l’objet en continue pour connaître son statut et le mettre à jour si nécessaire.
Ceci est très gourmand s’il y’a plusieurs abonnés et surtout si on interroge toutes les secondes, alors que le statut change de manière aléatoire ?
Ceci n’est pas efficace.
Pattern Observer
UML : Pattern Observer
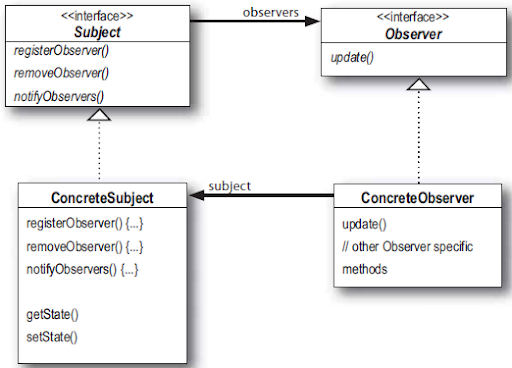
Text
update(ConcreteSuject sub);
Pattern Observer : Avantages
-
Eviter les opérations de PULL massives et simplement effectuer un push / pull lorsque c’est nécessaire.
-
Plus concrètement, améliorer la logique métier
-
Diminuer le coûts de l’observation
-
Supprimer la question de l’intervalle d’interrogation
Exercice
Exercice (Réaliser un pattern Observer)
Reprenez le pattern Observer pour observer la modification d'une température et notifier des objets observants ce changement de température.
Chaque modification de température affiche (dans la console) la nouvelle température pour tous les objets observants.
Pensez bien à avoir plusieurs observants.
Développez le code du pattern en C#
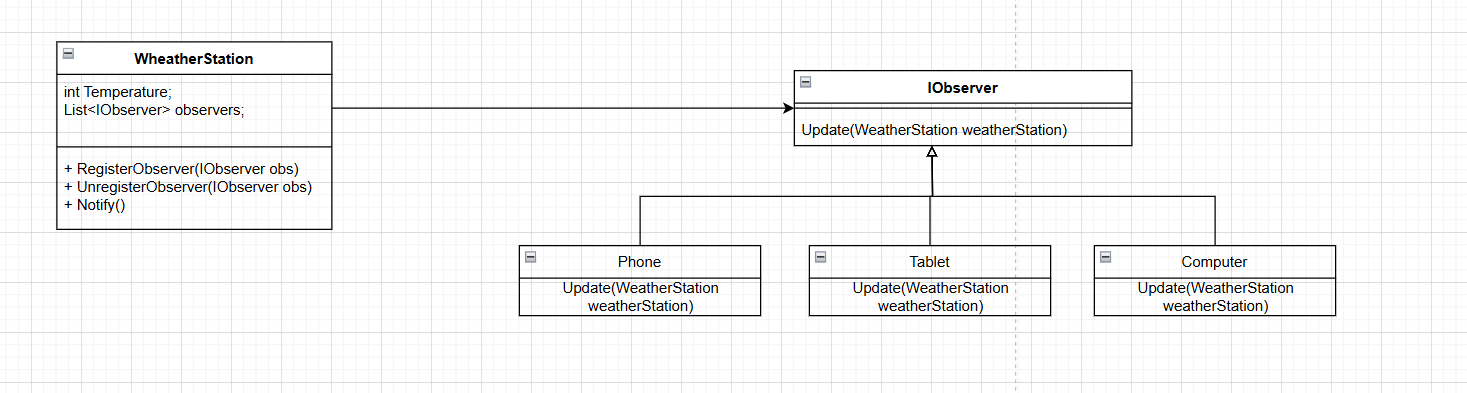
Exercice (UML à réaliser)
Exercice (UML à réaliser)
void SetTemperature (int valeur)
{
Temperature = valeur;
Notify();
}
void Notify ()
{
foreach (IObserver obs in Observers)
obs.Update(Temperature);
}
Définition
Permet de gérer des états sur des objets tout en gardant la flexibilité d’opérer toutes les actions que voulues sur chaque état.
Sans avoir à enchainer les if (x.state === State.closed) {…}.
On change le state d’un objet et c’est ce state s’auto-gère en fonction des opérations qui sont proposées par l’interface State.
Problématique
La gestion d’état sur des objets est gérable avec de simples conditions, mais dans le cas où l’on a beaucoup d’état qui peuvent changer en fonction de différentes opérations, le code devient une succession de condition.
D’une part, c’est incompréhensible à premier abord (surtout sans commentaire, ça peut prendre un certain temps) et d’autre part, lorsque l’on veut ajouter un state ou une opération on se retrouve a devoir modifier tout ça au risque de tout péter.
Pattern State
UML : Pattern State
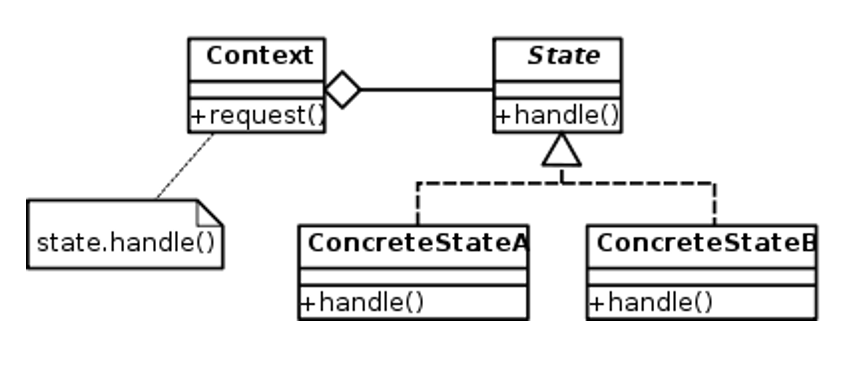
Pattern State : Avantages
- Modularité du code
- Simplicité pour multiplier les opérations de changement de statut (flexibilité)
- Découplage fort
Exercice
Exercice (Réaliser un pattern State)
Réalisez le code permettant d'implémenter un pattern State répondant aux besoins précisés par le diagramme d'états transitions envoyé.
(Débutant, confirmé, expert, indétrônable, en pouvant sauter des niveaux que ce soit positivement ou non. Excepté quand on arrive à indétrônable)
Développez le code du pattern en C# pour implémenter cette problématique d'états.
Exercice
Exercice (Réaliser un pattern State)
Si nous avons assez de temps, je vais vous demander de réaliser un pattern State, l’idée ici est de gérer les statut d’une porte :
- Une interface IGateState + une classe Gate + une classe OpenGateState (IGateState) + une classe ClosedGateState (IGateState)
- Les méthodes à implémenter sont
- Enter, pay, payFailed : Ces méthodes doivent modifier le statut suivant l'action réalisée sur le statut courant.
Réalisez le code C# associé à ce pattern
Attention à la surutilisation des patterns
Petite attention particulière sur la surutilisation : même quand vous aurez l’habitude d’utiliser les design patterns…
Le but des patterns est de répondre à une problématique de code par une conception adaptée ET PAS rendre la conception plus complexe pour mettre des patterns juste parce qu’on veut absolument mettre des patterns partout.
C’est assez effrayant le nombre de développeurs en entreprise qui font ça, de mon expérience, je dirai qu’environ 10% des développeurs que j’ai connu avaient ce syndrome. Travailler avec eux était d’autant plus compliqué que leur syndrome était avancé !
Car ils ajoutent une complexité non négligeable à un projet et ensuite pour faire intervenir une ressource non expérimentée et bien… ça fini souvent avec quelqu'un en pleure avant même d’avoir écrit une ligne de code.
Attention à la surutilisation des patterns
Pour appuyer mes propos, imaginez, nous avons vu une architecture MVC (en 3 couches), y ajouter des patterns n’est déjà pas toujours évident, même si les patterns que l’on a vu s’adaptent bien à l’architecture MVC.
D’autres architectures existent, par exemple SOA, qui est une architecture orientée services. Cette architecture contient, en moyenne pour une utilisation normale, entre 10 et 12 couches. Là, on parle d’une complexité déjà impactante en termes d’architecture…
Ajoutez une surutilisation de patterns et seuls les développeurs séniors seront capables de travailler sur ce projet (mais ça ne donnera envie à personne…)
Evitez absolument la complexité dans vos développements, un pattern n'a d'avantage que s'il est employé correctement
Les tests de performances
Les tests de performances
Il existe plusieurs méthodes pour réaliser des tests de performances, chacune a ses propres objectifs
-
Développer ses propres tests automatisés pour tester les performances de certaines parties de votre application. Ici on parle de vérifier le temps de traitement, ou l'espace mémoire ou la RAM utilisées par une instruction "complexe" du programme
- Utilisation d'outils externes (dans la CI), tels que Grafana ou Datadog pour le monitoring de vos applications / infrastructures
Réaliser ses propres tests de performances (.Net)
Stopwatch & mémoire
Voyons quelques exemples de tests de performances que l'on peut réaliser simplement en .Net
Un exemple concret complet d'optimisation (mémoire)
Voir l'exemple "Strings are evil"
Prenez le temps d'analyser toutes les étapes qui permettent de gagner en espace mémoire de manière drastique en changeant la façon de traiter les chaînes de caractères.
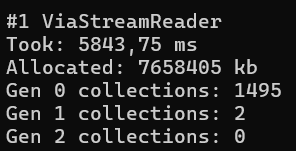
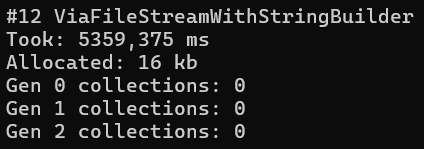
- Quasiment la même durée (même si un poil mieux)
- Espace mémoire nécessaire ~500 000 fois moins élevé
Utilisation d'outils externes pour le monitoring
- Grafana / Prometheus : Outils de monitoring à l'aide de dashboard qui permettent d'analyser les performances et l'utilisation réel du projet qui est réalisé (applicatif essentiellement)

Il existe de nombreux outils, mais les plus utilisés sont :
- Datadog : Même principe mais plus orienté infrastructure de votre projet, pour monitorer la RAM, la mémoire etc... de vos infrastructures. Permettant donc de faire des choix infrastructurels adaptés

Tutoriels
Grafana
Datadog
- https://www.youtube.com/watch?v=Js06FTU3nXo
- https://www.youtube.com/watch?v=0p9JJobuVTg&ab_channel=TheDevOpsSchool (un peu ancien, mais j'y ai appris beaucoup de chose à l'époque)
Optimisation algorithmique
Optimisation algorithmique
Déjà, un algorithme, c'est un réponse à une problématique et il doit fonctionner (résoudre le problème), mais il y a plusieurs moyens de résoudre un même problème.
On souhaite trouver le meilleur moyen de répondre à la problématique en termes de ressources (RAM, HDD / SSD) ou de temporalité
Les programme sont de plus en plus gourmand :
- En mémoire non volatile [HDD, SSD ]
- En mémoire volatile [RAM]
- En performance
- Temps d'exécution
- Coût de l'utilisation de la ou des machine(s)
Problématique
Optimisation algorithmique
Exemple de problématique
Lire un fichier csv pour en exploiter les données.
Voici deux des multiples possibilités pour résoudre la problématique :
- Utiliser le Framework (.Net ici) pour résoudre simplement le problème ==> Gourmand en mémoire, mais rapide en développement
- Décomposer le problème et optimiser chaque aspect ==> Très très peu gourmand en mémoire, mais long et complexe en développement
Voir exemple StringsOptimizations
Optimisation algorithmique
Calculer la complexité algorithmique
Afin de définir quel est la réponse (algo) la plus adaptée pour répondre à notre problématique, nous pouvons calculer la complexité algorithmique des différents algorithmes proposés.
On calcul souvent la complexité de deux façons :
- Le pire cas, ou possibilité la plus lourde de l'algorithme, notée O. Ce calcul est systématique
- Le meilleur cas, ou calcul de la complexité la plus faible notée Ω (Oméga). Ce calcul est utilisé que dans certains cas
- Le cas constant, ou le pire et le meilleur des cas sont identiques,
notée Θ (Thêta). Ce calcul est utilisé dans de très rares cas.
Optimisation algorithmique
Calculer la complexité algorithmique
Calcul de la complexité du code, explications (avant de faire un exemple simple ensemble)
- Opération atomique : vaut 1
- Création d'une variable
- Opérations arithmétiques (+, -, *, /, %)
- Affectations (=)
- Comparaisons
- Exemple :
- int x = 2 + 3 : vaut 2 car on affecte une variable et on fait une opération arithmétique. On la notera O(2), réduit à O(1)
- Appel de fonction : 1 + Complexité de la fonction
- Structures conditionnelles (if, else if) : 1 + Complexité de la condition
- Boucles : 1 + Complexité de la condition (utiliser des variables comme "n", "m" pour les valeurs variables)
- Parcourir une liste est équivalent à une boucle
Optimisation algorithmique
Prenons un exemple simple
Nous allons utiliser un exemple de la vie réelle afin de comprendre la complexité algorithmique et son calcul : Réaliser un nombre de pompes avant le jour (n) d'une compétition.
La complexité constante

Ici, la complexité est constante, car pour préparer la compétition, on doit faire 100 pompes (une seule fois)
On parle donc de O(1) en complexité.
Optimisation algorithmique
Prenons un exemple simple
Nous allons utiliser un exemple de la vie réelle afin de comprendre la complexité algorithmique et son calcul : Réaliser un nombre de pompes avant le jour (n) d'une compétition.
La complexité linéaire
Ici, la complexité est linéaire car pour chaque jour avant la compétition, on doit faire 100 pompes. On dépend donc du nombre de jour dans cet algorithme.
On parle donc de O(n) en complexité.

Optimisation algorithmique
Prenons un exemple simple
Nous allons utiliser un exemple de la vie réelle afin de comprendre la complexité algorithmique et son calcul : Réaliser un nombre de pompes avant le jour (n) d'une compétition.
La complexité logarithmique
Ici, la complexité est logarithmique car pour chaque jour avant la compétition, on doit faire des pompes tous les n / 2 jours. On dépend donc du nombre de jour dans cet algorithme, mais l'opération est réalisée moins de fois que n.
On parle donc de O(log(n)) en complexité.

Optimisation algorithmique
Prenons un exemple simple
Nous allons utiliser un exemple de la vie réelle afin de comprendre la complexité algorithmique et son calcul : Réaliser un nombre de pompes avant le jour (n) d'une compétition.
Différence entre O(n) et O(log(n))

Optimisation algorithmique
Prenons un exemple simple
Nous allons utiliser un exemple de la vie réelle afin de comprendre la complexité algorithmique et son calcul : Réaliser un nombre de pompes avant le jour (n) d'une compétition.
La complexité polynomiale
Ici, la complexité est polynomiale car le nombre de pompes dépend du nombre de jour dans cet algorithme, plus on avance dans les jours plus on fait de pompes.
On parle donc de O(n²) en complexité.

Optimisation algorithmique
Prenons un exemple simple
Nous allons utiliser un exemple de la vie réelle afin de comprendre la complexité algorithmique et son calcul : Réaliser un nombre de pompes avant le jour (n) d'une compétition.
La complexité cubique (polynomiale)
Si on rajoute des abdos à réaliser par pompe en plus par jour, la complexité est cubique car le nombre de pompes et abdos dépendent du nombre de jour dans cet algorithme, plus on avance dans les jours plus on fait de pompes et d'abdos.
On parle donc de O(n³) en complexité.

Optimisation algorithmique
Prenons un exemple simple
Nous allons utiliser un exemple de la vie réelle afin de comprendre la complexité algorithmique et son calcul : Réaliser un nombre de pompes avant le jour (n) d'une compétition.
La complexité exponentielle
Ici, la complexité est exponentielle car chaque jour on va multiplier le nombre de pompes à réaliser par deux, donc plus n est grand, plus m (nombre de pompes / jour) va devenir grand.
On parle donc de O(2^n) en complexité.

Optimisation algorithmique
Exemple de cas concrets de complexité
Quelques exemples dans le développement :
-
Complexité constante (O(1)): Demander le nom d'un utilisateur et lui dire bonjour dans la console
-
Complexité linéaire (O(n)): Parcourir une liste
-
Complexité logarithmique (O(log(n))): Recherche par dichotomie
-
Complexité polynomiale (O(n^x)): Comparer toutes les combinaisons possibles de paires d'utilisateurs pour vérifier s'ils sont amis
- Complexité exponentielle (O(2^n) : Générer toutes les combinaisons possibles d'une liste d'éléments (produit cartésien de deux listes minimum)
Optimisation algorithmique
Exemple de cas concrets de complexité
Envoyer le projet AlgorithmiqueSample
Optimisation algorithmique
Ordre de grandeur et durée estimée
En fonction du nombre de données à traiter et de la complexité algorithmique, on peut estimer (approximativement, car ça dépend du langage et de la machine de traitement) la durée d'exécution de l'algorithme.
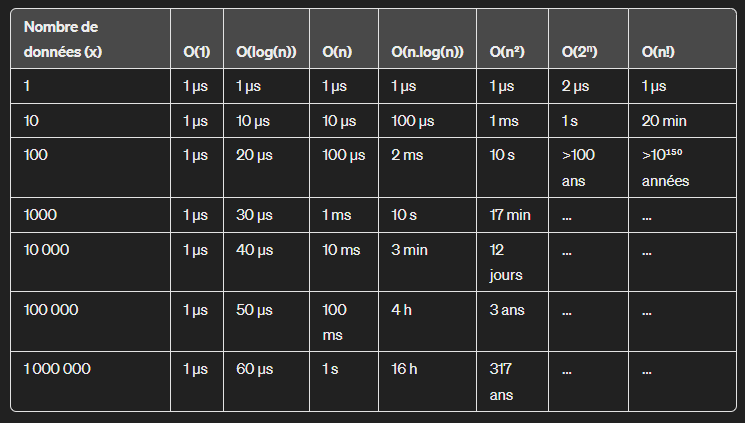
Merci chatGPT ! 😊
Optimisation algorithmique
Exercice calculer la complexité
Je vais vous envoyer 7 bouts de code, vous devez définir la complexité algorithmique de chacun (sans l'aide de GPT 😉)
Expliquez pourquoi vous avez mis cette complexité et pas une autre.
Optimisation algorithmique
Exercice optimisation de code
Je vais vous envoyer deux bouts de code à optimiser, le premier est assez simple, il faut surtout réfléchir à l'algorithme et comment éviter des traitements inutiles.
Le second est plus complexe, il va falloir vous creuser les méninges pour vous en sortir, bon courage !
Optimisation algorithmique
Autres aspects à avoir en tête
Nous ne pourrons pas voir l'intégralité de ce qu'il faut comprendre pour estimer et optimiser la complexité algorithmique dans cette formation, mais voici quelques points à avoir en tête :
- Complexité dans les bases de données
- Technologies les plus rapides pour traiter les algorithmes lourds
- Optimiser des opérations lourdes en décomposant les actions, sans utiliser le Framework (exemple StringOptimizations)
- L'utilisation du développement parallèle pour optimiser (ça a un impact élevé sur le traitement d'un algo...). Vous pouvez voir cette formation pour en apprendre plus :
https://slides.com/cedricbrasseur/parallel-programming/
Utilisation de Grafana
Grafana
- Visualisation de données : Création de tableaux de bord interactifs et personnalisés.
- Monitoring : Suivi des données système, applications et infrastructure.
- Alertes : Mise en place d'alertes par email, webhook,...
- Analyse de performances : Identification de tendances et diagnostic des problèmes.
- Exploitation de données multi sources : Connexion à diverses bases de données (Prometheus, SQL Server, Mongo, etc.).
A quoi ça sert ?
Grafana
Petit schéma

- Utilise un système de production de données
- Les données sont agrégées dans une base de données
- Grafana exploite ces données et vous pouvez en faire des dashboards
Grafana
Petite demo
Je vais vous montrer un peu comment fonctionne Grafana puis vous suivrez un tutoriel pour vous y habituer, le plus difficile au début c'est de s'y retrouver dans toutes les fonctionnalités de Grafana
Grafana
Tutoriel complet à suivre
Voici un tutoriel qui vous permet de tester et mieux comprendre Grafana sans avoir à configurer vous même le data producer et les sources de données :
https://grafana.com/tutorials/grafana-fundamentals/?utm_source=grafana_gettingstarted
Montrer un exemple avec SQL Server (simple table panier, avec exploitation de ces données)
TODO
Grafana
Data source : SQL Server
Utilisation de Datadog
Datadog
- Monitoring : Supervision des applications, infrastructures, réseaux et logs
- Alertes : Notifications basées sur des conditions
- Analyse des performances : Suivi des temps de réponse, goulots d'étranglement et optimisation des ressources.
- Gestion des logs : exploitation des logs pour détecter les erreurs, pannes, etc...
- Dashboard : Mise en place de tableau de bords perso
- Sécurité : Détection et surveillance des menaces en temps réel + alertes automatisées
A quoi ça sert ?
Datadog
Petit schéma
- L'agent se met directement sur vos serveurs de production
- Il récupère des données d'infrastructure, logs, utilisation de votre application
- Et vous créez des dashboards sur Datadaog pour exploiter les données, alertes, etc...

Datadog
Petite demo
Je vais vous montrer un peu comment fonctionne Datadog puis vous suivrez un tutoriel pour vous y habituer, le plus difficile au début c'est de s'y retrouver dans toutes les fonctionnalités de Datadog
Datadog
Tutoriel complet à suivre
Voici plusieurs tutoriels qui vous permet de tester et mieux comprendre Datadog dans un Lab (les tutoriels sont vraiment incroyables)
https://learn.datadoghq.com/bundles/dd-fundamentals
- (Faire 101 Site Reliability Engineer)
- (Faire 101 Developer également)
Evaluation
Pratique