External Devices and Disks
The Story So Far
Processes And Scheduling
- OS Roles, history, and interfaces (API, AMI, HAL)
- Dual-mode execution and protection
- Process as fundamental abstraction, unit of execution
- How schedulers work
Threads + Synchronization
- What race conditions are
- How to use locks and semaphores to avoid race conditions
- How locks/semaphores are implemented
- How and why deadlock occurs, how to avoid it with monitors
- How to use synchronization primitives to solve problems (bounded buffer, readers/writers, Pemberley)
Memory
- Early virtual memory mechanisms (static relocation, dynamic relocation, overlays)
- Address-space layouts
- Paging!
- Page tables and page faults
- Swapping
- Page replacement algorithms:
- Heaps
That's a lotta stuff!
Everything we've discussed so far involves just the CPU and main memory.
A computer that can't talk to the outside world is pretty useless!


Examples: your computer needs to
- send information to the monitor so that the monitor can display images.
- Read input from the mouse and keyboard so that the user can send it commands
- Communicate over the network to talk to the cloud. If your computer is a server, it needs to communicate over the network so that it can provide cloud services.
- Even old systems needed to communicate: the IBM 7094 required input and output tapes to process.
External Devices!
- Keyboard/Mouse
- Hard Drive
- Network Card
- Monitor
- Microphone
- Printer
- and many more...
What types of external devices do you have on your computer now? (Anything that isn't RAM)
Today's Roadmap
1. How do we deal with external devices?
- How do we get data to/from the device?
- How do we deal with the fact that the device might not be ready yet?
2. A special external device: the disk
- Disk speed (or lack thereof)
- I/O Characteristics of disks
3. How to use disk head scheduling to speed up disk access
4. How to dodge the problem by using SSDs instead
How do we transfer bits between devices and the OS?
What is the architecture of external devices?
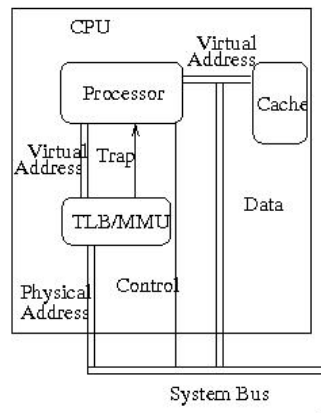
Prior to now in this class, we've been looking at stuff only on the CPU. Things like the TLB/MMU, scheduling, etc. all take place on the CPU.
This image is from an earlier lecture in the class. Note the line labeled "system bus" near the bottom. This is the piece of hardware that the CPU will use to talk to the other components of the system.
Note: The word "bus" simply means "a single wire that all entities connect to and talk/listen on". In a bus-like architecture, everyone can hear you when you talk.
What is the architecture of external devices?
Here, everything from the last slide except the system bus has been condensed into the black box on the left. The system bus, which was at the bottom of that square, now links the CPU to other parts of the system, including some of the external devices we talked about earlier
Let's zoom in on one of these external devices.
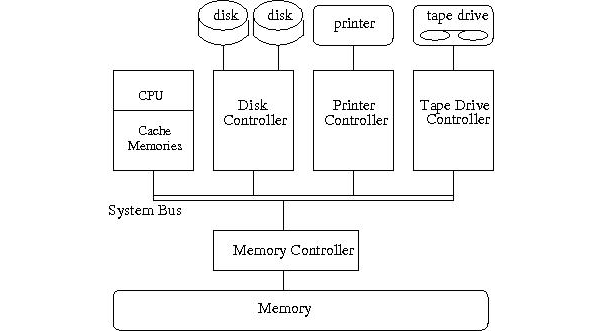
What is the architecture of external devices?
There are four pieces of hardware associated with an I/O device:
- A bus that allows the device to communicate with the CPU
- A device port that has several kinds registers:
- Status: can be read by the CPU to know what state the device is in
- Control: written to by CPU to request I/O from the device
- Data: Used to hold contents of I/O
- A controller that can read/write commands and data on the bus, and translates commands into actions for the device
- The actual device
Port
Communication
Port
In order to access the external device, the system must take the following actions:
- The OS makes a request to the device on the system bus.
- The OS places the information in the device's registers for the controller to interpret.
- The OS waits...
- The controller places information about the result somewhere for the OS to access.
External devices may take a while to respond. For instance, access to a tape drive may take several seconds. Access to asynchronous devices (e.g. keyboards) might take a very long time. Think about what happens if you're waiting for a keyboard input, but your user is on vacation in Hawaii. You might be stuck waiting for weeks! So we need some way to handle this waiting without degrading performance.
Method 1: Polling

The OS will repeatedly check until the status register of the I/O device until it is idle.
Side Note: Polling is not necessarily busy waiting!
int read(){
Device* device = determine_device();
device->issue_read();
while(!device->status_is_ready()){
// wait
}
return <result of device read>
}int read(){
Device* device = determine_device();
device->issue_read();
if(!device->status_is_ready()){
thread_current()->read_sema.down();
}
return <result of device read>
}
void timer_interrupt(){
< Check sleep timers >
// Check device once! If not ready, wait to next interrupt to check again
for(device in busy_device_list){
if (device.status_is_ready()){
device->waiting_thread->read_sema.up();
}
}
}Example of a busy wait
Example of polling without busy waiting
Note: do not try to use this code for Pintos. It doesn't actually work, and Pintos handles this level of complexity for you.
Polling is simple!
Don't knock simplicity!
It is much better to write a system that you can successfully implement rather than waste $50 million on a system that you discover is too complex to use.
Simplicity is fast development. Simplicity is fewer bugs. Simplicity is elegance.
But simplicity can also mean a lack of performance or features. What can we do if we don't want to pay the cost of repeatedly checking the status register?
Interrupts
Instead of having the CPU check, the device notifies the CPU (by sending a message on the bus) when the I/O operation is complete.

This is slightly more complicated: the external device and system need to both have support for interrupts. When the device is finished, it triggers an interrupt on the CPU just like a timer interrupt. The CPU will respond using the standard mechanisms (push registers, jump to interrupt vector, index by interrupt number, etc.)
We no longer have to keep checking the device!
Yay! Now how do we read 4KB?
- Start I/O operation #1
- Get interrupt
- Read 4 bytes
- Start next I/O operation
- Get interrupt
- Read 4 bytes
- Start next I/O operation
- Get interrupt
- Read 4 bytes
- Start next I/O operation
- Get interrupt
- Read 4 bytes
- Start next I/O operation
- Get interrupt
- Read 4 bytes
Repeat above list 200 times
Seems suboptimal: lots and lots of interrupts. Each read requires control unit transfer, waiting at the CPU, etc. etc.
Can we do better?
Direct Memory Access (DMA)
Direct memory access is a hardware-mediated protocol (i.e. the hardware needs to support it) which allows the device to write directly into main memory.
Instead of data-in/data-out registers, we have an address register and a DMA controller. The CPU tells the device the destination of the transfer.
The DMA controller reads/writes main memory directly over the system bus, and notifies the CPU when the entire transfer is complete, instead of a single word.
Can lead to bus or memory contention when heavily used, but still has better performance than interrupting the CPU.
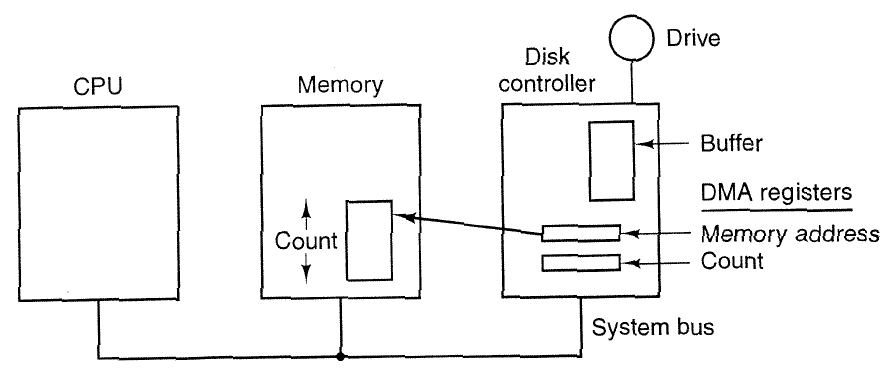
Direct Memory Access (DMA)
Note: there are extra registers and memory on the device, and we need some control mechanisms to allow the device to write directly into main memory now.
How do we read 4KB?
- Issue a DMA read of 4KB to an address in memory.
- Wait.
- Once interrupt is received, make sure status register does not report error. Data is now at the address we specified in step 1.
This seems easier. What really happened was that a lot of the complexity has been moved into hardware. This is both faster and easier, for us as programmers. For the hardware designers, this is more complex.
Which of these methods is best for reading a large file?
What about a microphone?
DMA, if you can pay for the hardware.
DMA, if you can pay for the hardware.
Polling or interrupts. We're getting data regularly anyways, polling might legitimately be best here.
There is no such thing as "best in general." Every time you say something is better than something else, you are (whether you mean to or not) attaching a goal to this statement.
Disks
Disks vs Memory

Image Credits:
Faster, Smaller, More Expensive
Memory (RAM)
- Small, Fast, and Expensive
- Data is lost when power is turned off
Stable Storage (Disk)
- Large, Slow, and Cheap
- Data is retained through power off
How slow is slow?
Light can travel around the Earth's equator 7.5 times in a single second.
Modern CPUs are so stupidly fast that it should be illegal.
A nanosecond is so short that light travels almost exactly one foot per nanosecond.
In that one nanosecond, a typical modern CPU executes 3-5 processor cycles.
Disk access is measured in milliseconds, 1 million times slower than a CPU cycle.
Speed
For a relatively fast hard drive, the average data access has a latency (request made to data available) of 12.0 ms.
| Action | Latency | 1ns = 1s | Conversation Action |
|---|---|---|---|
Values taken from "Numbers Every Programmer Should Know", 2020 edition
1s
4s
1m 40s
138d 21hr+
1ns
4ns
100ns
12ms
L1 Cache Hit
L2 Cache Hit
Cache Miss*
* a.k.a. Main Memory Reference
Disk Seek
Talking Normally
Long Pause
Go upstairs to ask Dr. Norman
Walk to Washington D.C. and back
DISK ACCESS
Other Destinations:
- Canada
- Guatemala
- San Francisco
Why so slow?
Short answer: instead of being controlled by electricity traveling down a copper or silicon trace, data retrieval from a hard drive is controlled by chunks of metal flying around at incredible speeds. It turns out it's very hard to accurately fling metal around at anything near the speed of light.
Anatomy of a Hard Disk Drive
Platter: a thin metal disk that is coated in magnetic material. Magnetic material on the surface stores the data.
Each platter has two surfaces (top and bottom)
Drive Head: Reads by sensing magnetic field, writes by creating magnetic field.
Floats on an "air" cushion created by the spinning disk.
Sector: Smallest unit that the drive can read, usually 512 bytes large.
Drives are mounted on a spindle and spin around it (between 5,000 and 15,000 rpm)
Sectors are organized in circular tracks. Data on the same track can be read without moving the drive head.
{
Cylinder
A set of different surfaces with the same track index
Comb
A set of drive heads.
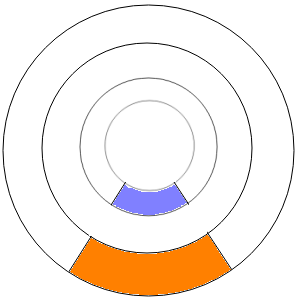
Note: Outer parts of the disk are faster!
Even though we don't usually exploit this in the operating system.
Why? Because more disk travels past the read head per unit time closer to the edge of the platter!
Look at the diagram: even if the rings were the same thickness (which they aren't because I screwed up), the orange arc would clearly be larger than the blue one.
In fact, if you do some calculus, you find that 2x the distance from the spindle = 2x the area per second
Disk Operations
The CPU presents the disk with the address of a sector:
- Older disks used CHS addresses: specify a cylinder, a drive head, and a sector.
- Pretty much every disk sold since the 1990s uses LBA (logical block addressing): each sector gets a single number between 0 and MAX_SECTOR.
Disk controller moves heads to the appropriate track.
Wait for sector to appear under the drive head.
Read or write the sector as it spins by.
The Major Time Costs of a Disk Drive
-
Seek time: Moving the head to the appropriate track
- Maximum: time to go from innermost to outermost track
- Average: Approximately 1/3 of the maximum (see OSTEP for why! Warning: involves integrals)
- Minimum: track-to-track motion
- Settle time: waiting for the head to settle into a stable state (sometimes incorporated into seek time)
-
Rotation time: Amount of time spent waiting for sector to appear under the drive head (note: may vary!)
- Modern disks rotate 5,000-15,000 RPM = 4ms-12ms per full rotation.
- A good estimate is half that amount (2-6ms)
-
Transfer time: Amount of time to move the bytes from disk into the controller
- Surface transfer time: amount of time to transfer adjacent sectors from the disk once first sector has been read. Smaller time for outer tracks.
- Host transfer time: Time to transfer data between the disk controller and host memory.
Disk I/O time =
seek time + rotation time + transfer time
Remember that these times may change depending on where on the disk the data is stored and what the disk is currently doing!
Specifications for ST8000DM002
| Platters/Heads | 6/12 |
| Capacity | 8 TB |
| Rotation Speed | 7200 RPM |
| Average Seek Time | 8.5 ms |
| Track-to-track seek | 1.0 ms |
| Surface Transfer BW (avg) | 180 MB/s |
| Surface Transfer BW (max) | 220 MB/s |
| Host transfer rate | 600 MB/s |
| Cache size | 256MB |
| Power-at-idle | 7.2 W |
| Power-in-use | 8.8 W |

Suppose we need to service 500 reads of 4KB each, stored in random locations on disk, and done in FIFO order. How long would it take?
Disk I/O time =
seek time + rotation time + transfer time
For each read, need to seek, rotate, and transfer
- Seek time: 8.5 ms (average)
- Rotation time
- On average, 8.3 ms for a full rotation, so estimate half a full rotation: 4.15ms
- Transfer time:
- 180 MB/s transfer = 5.5ms per MB
- 4KB @ 5.5ms/MB = 0.022ms per transfer
Ouch.
Note: reviews claim that this disk tends to become nonfunctional very often. Do not consider this an endorsement.
What if the reads are sequential instead?
| Platters/Heads | 6/12 |
| Capacity | 8 TB |
| Rotation Speed | 7200 RPM |
| Average Seek Time | 8.5 ms |
| Track-to-track seek | 1.0 ms |
| Surface Transfer BW (avg) | 180 MB/s |
| Surface Transfer BW (max) | 220 MB/s |
| Host transfer rate | 600 MB/s |
| Cache size | 256MB |
| Power-at-idle | 7.2 W |
| Power-in-use | 8.8 W |
Suppose we need to service 500 reads of 1MB each, stored in sequential order on the disk. How long would it take?
Disk I/O time =
seek time + rotation time + transfer time
We need to seek/settle/rotate once for all the reads, then transfer data from the disk.
- Seek time: 8.5ms (avg)
- Rotation time: 4.15ms (avg)
- Transfer time: 5.5ms per MB
We just made things 300x faster by doing them in order!
Disk Head Scheduling
Disk Head Scheduling
We saw earlier that disk accesses are much faster if they're sequential instead of random. Can we exploit this to make disk access faster?
Suppose we're in a multiprogramming environment that's moderately busy. We can start to form a queue of requests.
The disk now has an option of which I/O to perform first--it can maximize its I/O throughput using disk head scheduling

Disk
FIFO Scheduling
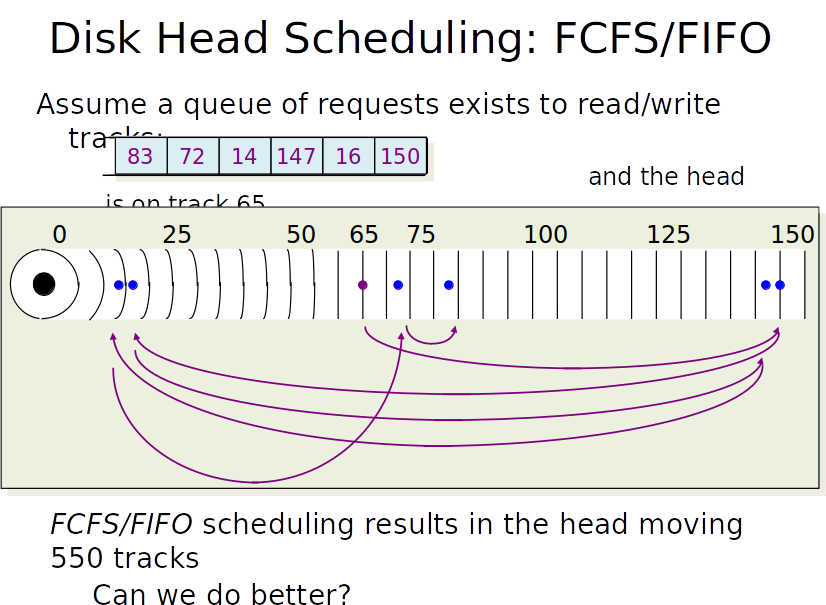
Suppose that the read head starts on track 65 and the following requests are in the read/write queue:
|
|
83 |
|---|
Running these requests in FIFO order has resulted in the disk head moving 550 tracks. Can we do better than this?
What went wrong here?
Our first two moves are clearly dumb.
New idea: let's visit the closest request every time.
Our request queue is [150, 16, 147, 14, 72, 83] and our disk head starts at 65. What are the two requests that we should service first?
SSTF Scheduling
Rearrange our access order to greedily minimize the distance traveled between tracks.
| 150 | 16 | 147 | 14 | 72 | 83 |
|---|
Outstanding Requests:
Access Order:
Running these requests in SSTF order has resulted in the disk head moving 221 tracks. Can we do better?
What could we improve on?
Notice that the jump in red is a particularly bad one. It occurs because SSTF walks us towards the high end of the disk, then "traps" us so that we have no choice but to jump all the way across the disk.
New idea: let's start by going in one direction, then the other. That way, we don't get (too) badly trapped in these large jumps.
Our request queue is [150, 16, 147, 14, 72, 83] and our disk head starts at 65, with the head moving inwards towards lower tracks. What are the two requests that we should service first?
SCAN/Elevator Scheduling
Move the head in one direction until we hit the edge of the disk, then reverse.
Simple optimization: reset when no more requests exist between current request and edge of disk (called LOOK).
| 150 | 16 | 147 | 14 | 72 | 83 |
|---|
Outstanding Requests:
Access Order:
Running these requests in LOOK order has resulted in the disk head moving 187 tracks. Can we do better?
C-SCAN/C-LOOK Scheduling
| 150 | 16 | 147 | 14 | 72 | 83 |
|---|
Outstanding Requests:
Access Order:
| 16 | 14 | R | 150 | 147 | 83 | 72 |
|---|
Takes advantage of a hardware feature that allows the disk head to reset to the outer edge almost-instantly.
Move the head towards inner edge until head reaches spindle, then reset to outer edge.
Reset immediately once no more requests towards inner edge: C-LOOK.
This requires us to move 118 tracks, plus whatever time it takes to execute the disk head reset (varies by drive model).
Other performance improvements

Disks can be partitioned into logically separate disks. Partitions can be used to pretend that there are more disks in a system than there actually are, but are also useful for performance, since access within a partition has shorter seeks.
In cases where extreme performance is needed (usually only for database servers), we can short-stroke the disk by restricting the partitions to the outer 1/3rd of the disk.
Solid State Drives
Solid State Drives
Solid state drives have no moving parts. This results in:
- Better random-access performance.
- Less power usage
- More resistance to physical damage
They are typically implemented using a technology called NAND flash.
The First Rule of NAND Flash...
NAND Flash can be set, but it can't be unset individually!
unset(1)?
BANNED
set(4)
We have to clear all the cells at once.
The First Rule of NAND Flash...
NAND Flash can be set, but it can't be unset!
This makes it nearly impossible to overwrite data in-place!
53
62
erp
The First Rule of NAND Flash...
NAND Flash can be set, but it can't be unset!

Like an Etch-A-Sketch!
You can set whatever pixels you want by turning the knobs, but the only way to erase them is to reset everything at once (by shaking the unit).
NAND Flash Operations
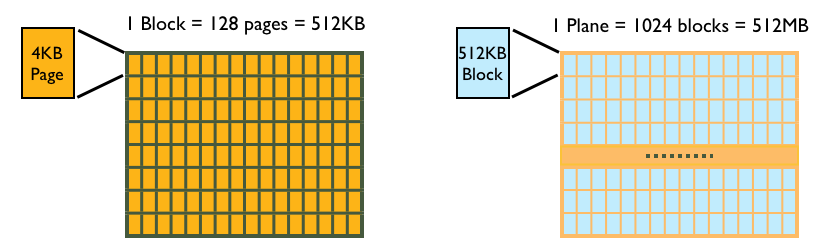
- Reading a page: a few µs
- Writing a page: a few µs
- Erasing a block: several ms (!!)
Pages function similarly to sectors on a hard drive: reads and writes occur in units of minimum one page.
Remapping: Lying to Your Users (Productively)
See primary slide decks for examples of how SSD remapping works.
Generally, use the following ideas:
- Set aside a small area of the SSD which is reserved for storing mappings.
- When the user requests a page write, write it to somewhere else. Use the reserved area to store this remapping (e.g. page 37 written to slot 119).
- Only do a full erase of a page when it's completely written by pages which are no longer used.
NAND Flash Operations
- Writing/Reading a page: 50 µs
- Erasing a block: 3ms
- 128 pages per block
We fix this the same way we fixed disk operations: try to avoid having to perform the slow operations by optimizing data layouts!
Write 1 page, erase 1 block, etc. 128 times
\( 128 \times \left( 50 \times 10^{-3} \text{ms} + 3 \text{ms} \right) \approx 385 \text{ms} \)
or 3.005 ms per page.
Write 1 page, write a second page, etc. 128 times,
then erase
\( 128 \times \left( 50 \times 10^{-3} \text{ms} + \right) + 3 \text{ms} \approx 9.4 \text{ms} \)
or 0.08 ms per page.
By amortizing erase costs, we get a 37.5x speedup!
When a user "erases" a page, lie and say the page is erased, without actually erasing, but mark the page as unusable. Then, at some later time, erase a bunch of unusable pages together.
Flash Durability
Flash memory can stop reliably storing data:
- After many erasures
- After a few years without power
- After a nearby cell is read too many times
To improve durability, the SSD's controller will use several tricks:
- Error correcting codes for data
- Mark blocks as defective once they no longer erase correctly
- Wear-level the drive by spreading out writes/erases to different physical pages
- Overprovisioning: SSD comes from factory with more space than is advertised--this space is used to manage bad pages/blocks and as extra space for wear-leveling
SSDs vs Spinning Disk
| Metric | Spinning Disk | NAND Flash |
|---|---|---|
| Capacity/Cost | Excellent | Good |
| Sequential IO/Cost | Good | Good |
| Random IO/Cost | Poor | Good |
| Power Usage | Fair | Good |
| Physical Size | Fair | Excellent |
| Resistance to Physical Damage | Poor | Good |
As we can see, SSDs provide solid all-around performance in all areas while being small--this is why they have essentially taken over the personal electronics arena (most phones, tablets, and laptops come with SSDs these days).
The capacity/cost ratio of hard drives means that they are a mainstay in servers and anything else that needs to store large amounts of data.
Summary

A computer that cannot communicate with the outside world is effectively a potato.
It may be a very powerful potato, but it's still a potato. The ability to communicate with external devices is required if a computer is to be useful.
There are many different external devices that a computer might communicate with:
- Keyboard, mouse, touchscreen
- Monitor, speakers
- Microphone, webcam
- Network Interface Card (NIC)
- Bluetooth adapter
- Hard Drive
These devices all have different properties and access patterns.
The OS, in its role as illusionist and glue, abstracts away many of the details of doing the I/O.
Summary
The OS must be able to deal with the fact that external devices might not immediately be available.
To do this, it uses one of three mechanisms to wait for I/O and do the actual data transfer:
- Polling
- Interrupts
- DMA
An extremely important class of external device is the disk.
Disks function as stable storage for the OS, as well as providing a large, cheap store of space.
Disks are slow.
A single disk read might take tens of millions of CPU cycles. This is because disks are complex mechanical devices that can only move so fast.

Summary
We can speed up disk access over multiple requests by scheduling requests appropriately.
We can also just change our hardware and replace the disk with solid state drives
There are several major scheduling algorithms, including:
- FIFO
- Shortest Seek Time First (SSTF)
- Scan/Elevator/Look
- C-Scan/C-Look
We can also partition a disk to reduce seek time for requests in a partition.
Much faster than disk drives (on average)
But don't have as much storage capacity and have to have extra code in the OS to support certain operations.
Food For Thought
- Polling is less CPU-efficient than other methods because the CPU has to repeatedly check the device, but polling is not busy waiting. Explain how you would set up a system to poll an I/O device without busy-waiting.
- When using DMA, does the CPU provide the device with a physical or virtual address? Why?
- Could there be a situation in which polling is faster than interrupt-based scheduling? What are the primary costs associated with each?
- With non-FIFO disk head scheduling, requests may not be processed in the order that they were issued. Is this something that CPU schedulers (e.g. MLFQS, SJF, etc.) need to be aware of? If so, how does it affect their behavior?
- In main memory, page tables serve to prevent processes from accessing memory that is not theirs. However, disks do not track "ownership" of data. How does the OS prevent a process from accessing a swap page that does not belong to it?
The questions in the following slides are intended to provoke some thought and tie back what you've learned in this section to things you've studied previously in this course, or to really test your knowledge of what you learned in this unit.
- In SSDs, we use remapping to increase the longevity of the drive and accelerate multiple writes. Could we use the same strategy on disk drives? Why or why not?
- Early versions of the iPod (an old-timey music player before smartphones were a thing) came with a spinning disk drive inside. Name some of the downsides of such an approach compared to the modern approach of using flash memory. Given that this was purely a music player, how could we mitigate these disadvantages?
- Would using multiple threads to access a disk speed up disk access (e.g. instead of reading one file with one thread, we read the first 25% of the file with thread 1, the next 25% of the file with thread 2, etc)? Does it depend on the waiting method used (polling/interrupts/DMA)? Does it depend on if the threads are user or kernel threads?