CS 105C: Lecture 10
Last Time...
Smart Pointers for Fun and Profit
Multiple noncommunicating managers is an awful idea everywhere
std::unique_ptr: the manager that disallows other managers
std::shared_ptr: the manager that talks to other managers
Both classes allow us to manage the lifetimes of objects using RAII
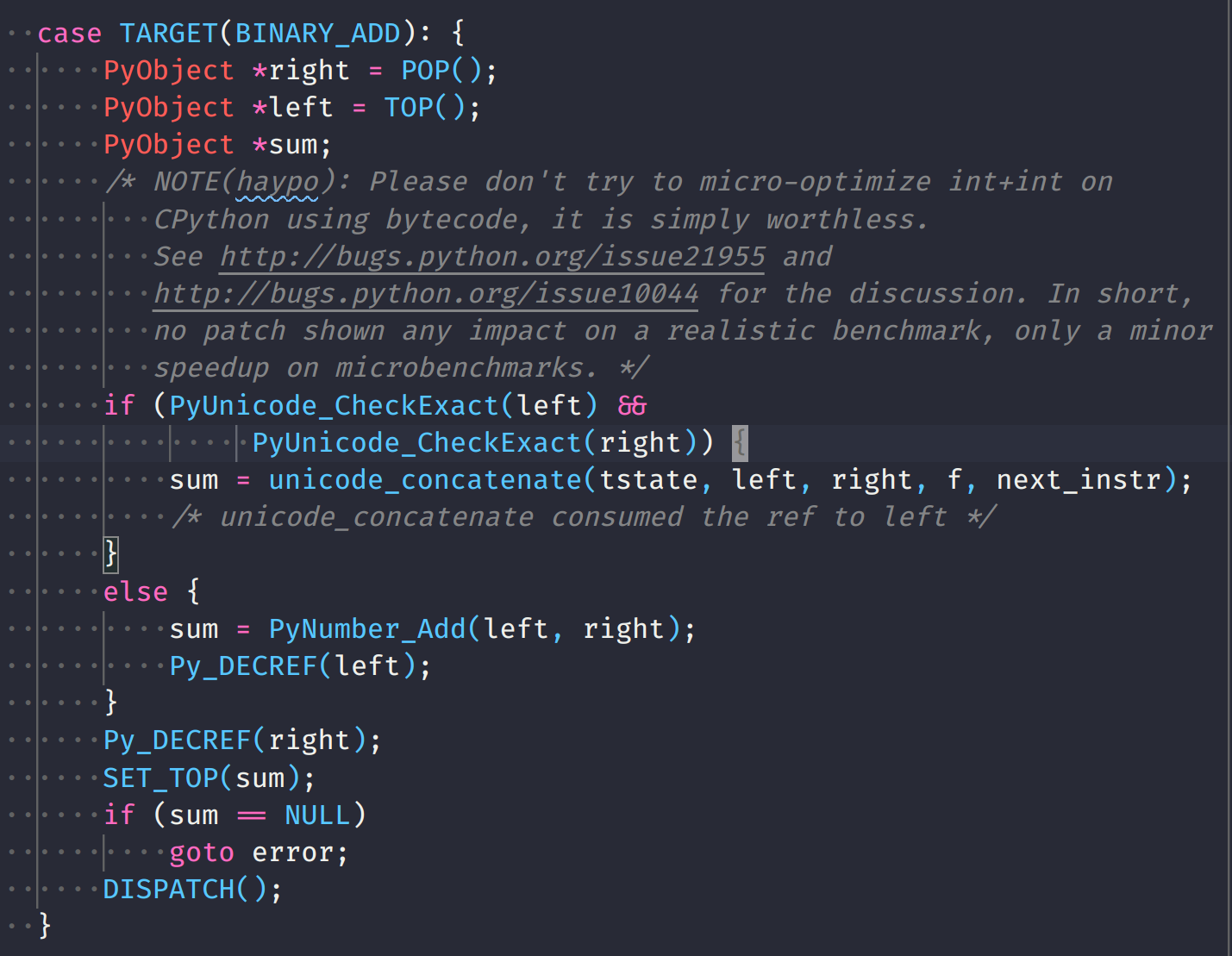
unique_ptr {
T* ptr;
...
unique_ptr(const unique_ptr& other) = delete;
unique_ptr& operator=(const unique_ptr& other) = delete;data
control block
1
unique_ptr works by blocking copies
shared_ptr works by reference counting
We can forward a forwarding reference with the original value category it had by using std::forward
template<typename T>
T make_T(T&& arg){
T(arg); // Calls copy constructor ONLY
T(std::forward<T>(arg)); // Calls move OR copy constructor
}T&& in a type-deduced context forms a forwarding pointer, which is a reference to the category it was initialized with.
int main(){
int x = 3;
auto&& rvalue_reference = 3;
auto&& lvalue_reference = x;
}CS 105C: Lecture 10
Zero-cost abstractions

Summary
Okay, for real though
Even abstractions as basic as function calls and loops can add signficant amounts of overhead!
So much so that we have optimization techniques (inlining and unrolling) to deal with the overheads of these abstractions!
So what the heck does it mean when we say that C++ offers zero-cost abstractions?
What you don’t use, you don’t pay for. And further: What you do use, you couldn’t hand code any better.

-- Bjarne Stroustrup
In practice, something we strive for more than something we accomplish.
"What you don't use, you don't pay for"
Python: Heterogeneous Objects
a = [1, "1", 1.0]Python has heterogeneous collections: you can add objects of different types into e.g. a list.
How convenient!
Python: Heterogeneous Objects
a = [1, "1", 1.0]Since we can put any object into a list, we can put different-sized objects into a list.
How do we store them?
Option 1: Store objects inline
a = [1, "1", 1.0]Advantages
- Saves space!
- Data remains local
Disadvantages
- Indexing is now O(N)
Implications: simple for loops are now \(O(N^2)\)!
Option 2: Store Objects as Pointers
a = [1, "1", 1.0]Advantages
- Indexing is O(1)
- Store as much data as you want
Disadvantages
- Accessing an element of the list costs two pointer lookups (and probably a cache miss or page fault)
There Is No Fundamental Way Around The Storage Problem
Any container storing heterogeneous elements must either pay an \( O(N) \) indexing cost or store elements indirectly.
Heterogeneous lists have a high runtime cost.
What if I don't want to use this functionality?
a = [1, 2, 3]Can I just place the elements in-line like I would for a homogeneous array?
What if I don't want to use this functionality?
a = [1, 2, 3, "4"]Can I just place the elements in-line like I would for a homogeneous array?
No.
As long as we can add elements of a different type, we have to be able to deal with it.
If we want to have a heterogeneous collection, we must pay the runtime cost even if we don't use it that way.
a = [1, 1, 1]Even homogeneous collections are stored in Python indirectly!
This has very real runtime implications for Python!
Let's add 1 to a bunch of numbers to test it out...
#include<vector>
#include<iostream>
int main(){
std::vector<int> a(100'000'000, 1);
for(auto& x : a){
x++;
}
}def main():
x = [1] * 100_000_000
list(map(lambda z: z+1, x))
if __name__ == "__main__":
main()
Test: Perform x+=1 on 100,000,000 ints in C++
Test: Perform x+=1 on 100,000,000 ints in Python


Test: Perform x+=1 on 100,000,000 ints in C++, optimized
Actually, the add operation in python isn't great either...
More Examples
Garbage Collection
int* read_unknown_data(const std::string& filename){
std::istream inf(filename);
int num_elements;
inf >> num_elements;
int* data = new int[num_elements]; // Ugh, when can I delete this?
}Recall: Stack allocation/deallocation is lightning fast, but size of object needs to be known at compile-time.
Unknown-size objects have to be allocated on the heap and cleaned up later.
Garbage Collection
class Program{
public int[] readInput(String fname)
Scanner scanner = new Scanner(new File(fname));
int[] vals = new int[scanner.nextInt()]; // Java will take care of it!
for(int i = 0; i < vals.length){
vals[i++] = scanner.nextInt();
}
return vals;
}
Garbage collection makes this fun and easy, at the cost of a little extra time to run the GC algorithm!
But there's a small cost for every single value we use, and that can add up.
Garbage Collection
Can I tell the garbage collector to only worry about certain data in my heap?
No.
Garbage Collection
If I'm working in a garbage collected language, I have to pay the GC cost even if I know ahead of time exactly when all my memory can be deallocated!
I can manually force garbage collection to occur, but I can't tell the language "trust me, drop that memory now" without violating gc safety requirements.
Green Threads
A lightweight threading system which relies on the language runtime to schedule threads instead of the OS. Found in:
- Java (pre-v1.1)
- PyPy/Stackless Python
- Erlang/Elixir
- Go (goroutines)
- Julia (tasks)
- Haskell
- Ruby (pre-v1.9)
- Rust (pre-v1.0)
Green Threads
func f(from string) {
for i := 0; i < 3; i++ {
fmt.Println(from, ":", i)
}
}
func main() {
go f("goroutine")
go func(msg string) {
fmt.Println(msg)
}("going")
}goroutine : 0
going
goroutine : 1
goroutine : 2example from https://gobyexample.com/goroutines
Threads managed by Go, not by the OS!
Can I tell my programming language that I don't want to use green threads?
Green Threads
Yes.
Can I remove the code dealing with threads from the language runtime to reduce the complexity/binary size of the language?
No.
Just don't use green threads.
A warning about performance
Use your intuition to ask questions, not answer them
--John Osterhout, inventor of Tcl
Software engineers are full of horror stories of someone who spent weeks optimizing the {memory access, program logic, parallelization} only to realize that they didn't actually make the program run any faster!
Use your intuition to ask questions, not answer them
--John Osterhout, inventor of Tcl
We can look at some code and say "it looks like this should be slower"...
...but we must back this up with measurements showing it to be the case!
C++ Zero-Cost Abstractions
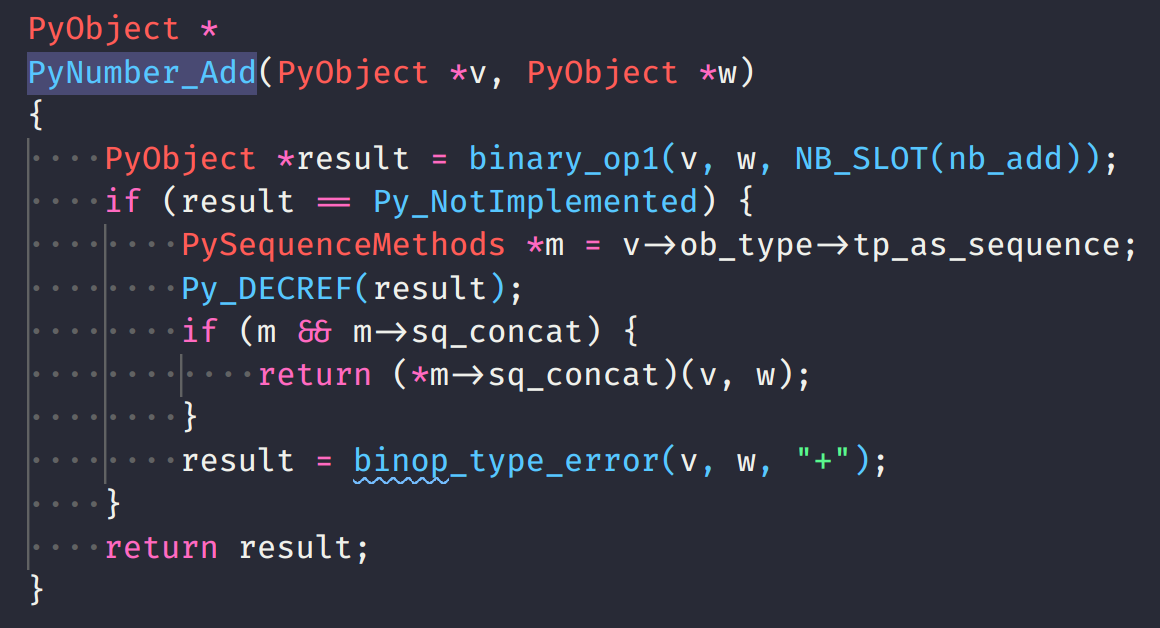
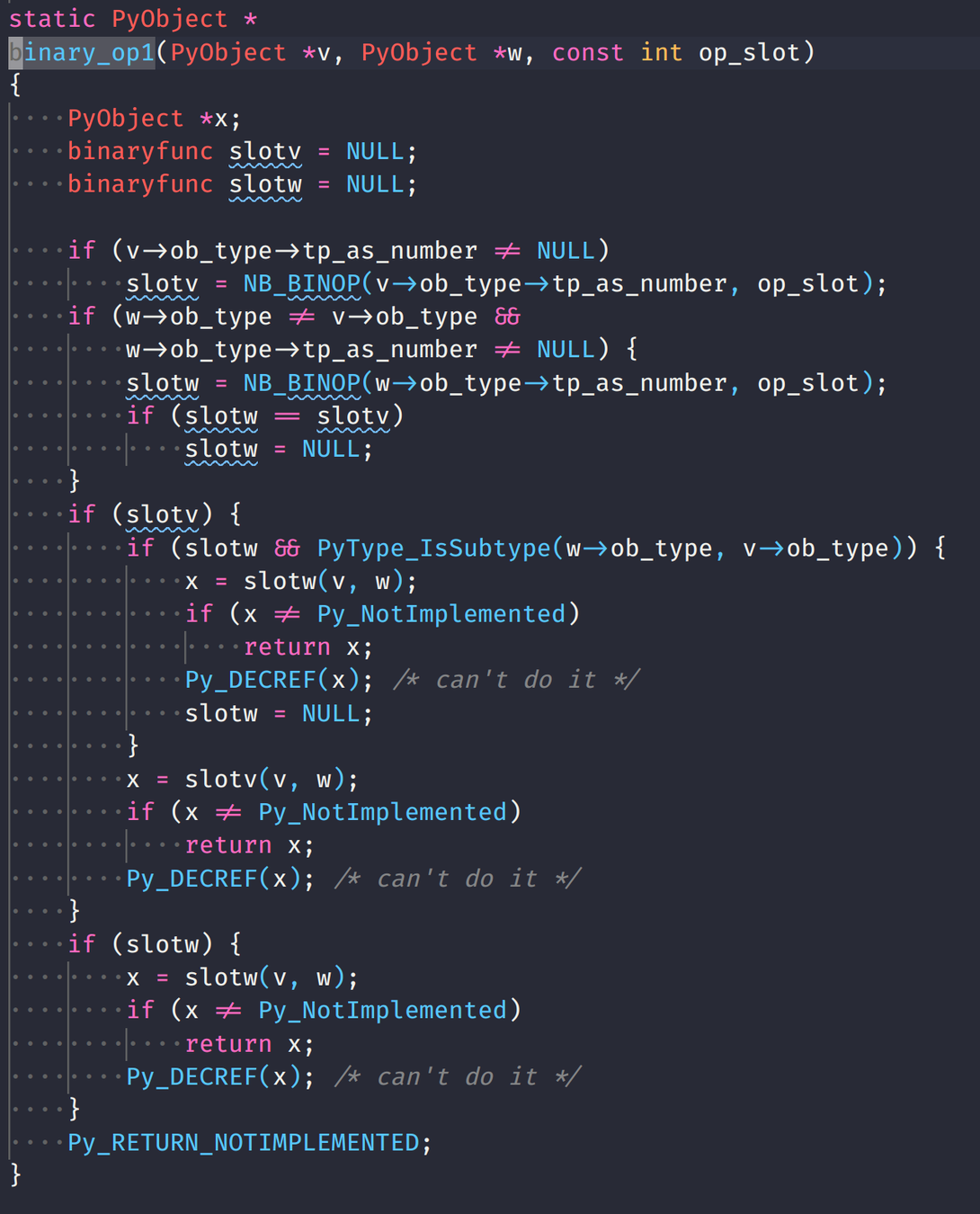
std::unique_ptr
Runtime cost
Compile time cost
Code Complexity Cost
No: no template is instantiated so there's no extra stuff to compile
No: unique_ptr (in its simplest form) just wraps new and delete
std::unique_ptr
Do we have to pay a cost for unique_ptr if we don't use it?
No.
std::unique_ptr
Could we write it better ourselves?
If we use handwritten allocation instead of letting unique_ptr allocate stuff for us, do we lose any performance?
Does it use more memory?
#include<memory>
#include<iostream>
int main(){
int* databuf = new int[10000];
int* rp = databuf;
std::unique_ptr<int> up(databuf);
std::cout << "Size of unique ptr = " << sizeof(up) << '\n';
std::cout << "Size of raw ptr = " << sizeof(rp) << '\n';
}❯ ./a.out
Size of unique ptr = 8
Size of raw ptr = 8Apparently not.
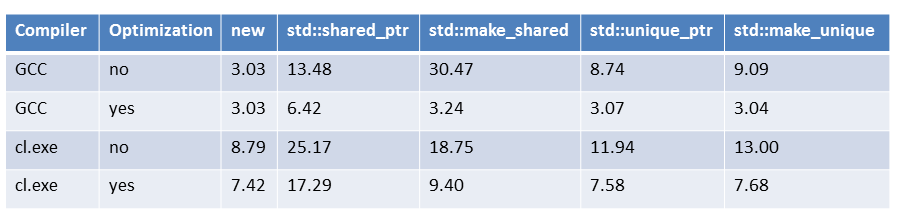
Allocate + Deallocate 100,000,000 ints using smart pointers and raw pointers
Conclusion: not really enough to matter.
Less than a 0.1% difference in a program that spends all of its time doing allocation!
If your program spends 5% of its time doing allocation, this is a 0.05% difference
No extra cost if unused
Just as fast as handwritten code
std::unique_ptr is a zero-cost abstraction
C++ Zero-Cost Abstractions
std::vector
std::vector
Do we have to pay a cost for vector if we don't use it?
Runtime cost
Compile time cost
Code Complexity Cost
No.
No: no template is instantiated so there's no extra stuff to compile
Minimal: the code for the abstraction has to exist, but we don't have to put it into our program.
What you do use, you couldn’t hand code any better.
Do we need to pay the indirect storage cost like we do in Python?
After all, we can store any type of data in a C++ vector...
std::vector<int>
std::vector<float>
std::vector<Cow>Since any given vector only stores one type of data, we can store all of them in-line in the heap!
std::vector<int> a = {1, 2, 3};Element Access
Element access in a raw array is a simple procedure:
- Find the array address
- Add the appropriate offset
- Load the element from offset
In principle, access in a vector is harder:
- Find operator[] in vector method
- Resolve operator [] overloads
- Access data buffer within class
- Add appropriate offset
- Load element from offset
_Z8access_NRSt6vectorIiSaIiEEi:
.LFB853:
.cfi_startproc
movq (%rdi), %rax
movslq %esi, %rsi
movl (%rax,%rsi,4), %eax
ret
.cfi_endproc_Z8access_NPPii:
.LFB854:
.cfi_startproc
movq (%rdi), %rax
movslq %esi, %rsi
movl (%rax,%rsi,4), %eax
ret
.cfi_endprocVector Copy
How do I make a copy of a vector in C++? (Without using the built-in copy constructor)
template <typename T>
std::vector<T> makeCopy(const std::vector<T>& in){
std::vector<T> out(in.size());
for(int i = 0; i < in.size(); i++){
out[i] = in[i];
}
return out;
}Time for 10 million elements:
97 milliseconds
vector<int> makeCopySTL(const vector<int> &a) {
vector<int> x = a;
return x;
}Time for 10 million elements:
13 milliseconds
How is the copy constructor so much faster??
Most modern processors provide vector units which can load/store multiple addresses at once.
AVX2, per CPU cycle
load/store, per CPU cycle
But there's a catch: the memory block has to be aligned to a multiple of 16! Most memory allocated in a program doesn't have this property!
Memory Alignment
The vector units require that memory is aligned (e.g. the beginning address is a multiple of 16). An actual data buffer may not have this property.
Orange blocks can be copied via aligned vector instructions--red blocks cannot.
Should we give up on using vector instructions because some of the memory is uneligible?
Solution
Copy orange blocks via vector instructions, then clean up red blocks with manual copying!
Determining which blocks can be copied and which cannot at runtime is a little annoying....
_Z11makeCopySTLRKSt6vectorIiSaIiEE:
.LFB853:
.cfi_startproc
;; blah blah blah
.L3:
; Associated code does "patch-up" on red blocks which can't be copied by aligned memmove
movq %rcx, %xmm0
addq %rcx, %rbx
punpcklqdq %xmm0, %xmm0
movq %rbx, 16(%r12)
movups %xmm0, (%r12)
movq 8(%rbp), %rax
movq 0(%rbp), %rsi
movq %rax, %rbx
subq %rsi, %rbx
cmpq %rsi, %rax
je .L6
movq %rcx, %rdi
movq %rbx, %rdx
call memmove@PLT ; Does accelerated memory copies using vector instructions!
movq %rax, %rcxThe vector move constructor does all of this by default!
Reality is much more complicated than presented here--sometimes both your source and destination need to be aligned!
Can you code the vector copy better by hand?
...maybe you could. I probably couldn't.
Summary
Zero-Cost Abstractions
Broadly try to fulfill two goals:
- Do not affect the runtime/complexity of the language if unused
- Are nearly as efficient as handwritten versions of the same code
Some abstractions that don't qualify:
Heterogeneous Collections
Force layout changes in data structure that affect all usages of that collection
Garbage Collection
All data must be collected by the GC, even if we know exactly when it can be safely collected
Green Threads
Can opt not to use them, but implementation must remain in the language runtime
Zero-Cost Abstractions in C++
std::vector
std::unique_ptr
Uses compile-time information to make operations just as fast as handwritten counterparts
Uses no more memory and is essentially no slower than a raw pointer.
Vector copy scheme is faster than naive handwritten code!
Notecards
- Name and EID
- One thing you learned today (can be "nothing")
- One question you have about the material. If you leave this blank, you will be docked points.
If you do not want your question to be put on Piazza, please write the letters NPZ and circle them.