The C++ Standard Library
Fun fact: some people get really mad if you don't use the version they prefer!
Back in the days before the C++ Standard existed...

Alexander Stepanov wrote a library for C++ based on templates.
This was the original Standard Template Library (STL).
At the November 1993 meeting, it was presented to the standard committee for standardization--this eventually became the C++ Standard Library. The Standard Library has since expanded massively over the STL, which is still developed.
Like many other things in the programmingverse, an inordinate number of bytes have been wasted arguing over whether "STL" or "C++ Standard Library" is the correct term for this library software.
I will prefer "standard library" in these slides, but I often use "STL" when speaking casually.
A Standard Library Breakdown
Very Roughly, the Standard Library can be broken down into the following areas:
- Utilities (e.g. <utility>, <tuple>, <chrono>)
- Platform-specific numeric info
- Error handling (<cassert>, <stdexcept>)
- Strings
- Contiguous Containers
- Associative Containers
- Container Adapters
- Numeric Algorithms (<random>, <numeric>)
- I/O Utilities
- Atomics/Threads
- Algorithms/Iterators
Of these, we have seen a surprising number in lecture already!
Additionally, some of these are fairly niche headers which we'd need to teach another class first to discuss properly.
Today, we will focus on the following
- Utilities (e.g. <utility>, <tuple>, <chrono>)
- Platform-specific numeric info
- Error handling (<cassert>, <stdexcept>)
- Strings
- Contiguous Containers
- Associative Containers
- Container Adapters
- Numeric Algorithms (<random>, <numeric>)
- I/O Utilities
- Atomics/Threads
- Algorithms/Iterators
Goal
Do a thorough API overview of every single class/function in each header
Get a general overview of what the classes/methods can do for us, and situations in which you might want to use them.
C++ STL Utilities
<chrono> and <tuple>
<chrono>
<chrono>
Contains basic functions and classes for calculating time, such as:
- std::duration
- std::system_clock
- std::steady_clock
- std::high_resolution_clock
As well as some convenience utilities, like
- std::chrono::nanoseconds
- std::chrono::milliseconds
- (Other unit typedefs)
int main()
{
auto start = std::chrono::steady_clock::now();
std::cout << "f(42) = " << fibonacci(42) << '\n';
auto end = std::chrono::steady_clock::now();
std::chrono::duration<double> elapsed_seconds = end-start;
auto elapsed_nanoseconds = std::chrono::duration_cast<std::chrono::nanoseconds>(elapsed_seconds);
}How hard is time??
You just use clock() and measure the results, right?
12. Time always progresses monotonically forward.
25. One minute on the system clock has exactly the same duration as one minute on any other clock.
26. Ok, but the duration of one minute on the system clock will be pretty close to the duration of one minute on most other clocks.
27. Fine, but the duration of one minute on the system clock would never be more than an hour.
28. You can’t be serious.
Time is HARD!
There's a challenge that some of the old UNIX programmers used to throw around: take two datetimes (date + time + timezone info) and determine which one occurred earlier.
This challenge is nearly impossible to do correctly on first try.
The Standard Library contains lots of functionality that seems trivial to implement yourself.
Unless you know exactly what you're doing, just use the standard library features.
It's so much easier than discovering that your clock ran backwards for 20 seconds after midnight of Feb. 29 and now your server is corrupted.
<tuple>
A tuple is a set of values
You can think of it as a generalization of pair
auto data = std::make_tuple(age, name, height)Tuples are everywhere in other languages!
Functional languages and Python abuse the hell out of these structures.
Why doesn't C++ use them as much? Two reasons:
- Classes came much earlier as a way of aggregating data, so C++ programmers got used to using those instead.
- The pre-C++17 interface for tuples was atrocious to use.
std::tuple<int, string, double> tup = get_data();Let's say I have the following variable...
std::tuple<int, string, double> tup = get_data();How do I access the i-th element of the tuple?
string name = tup[1];string name = std::get<1>(tup);
How do I destructure the tuple?
int age;
string name;
double height;
std::tie(age, name, height) = tup;
string name = tup.at(1);Fortunately, C++17 makes life a lot better
You can use the so-called "structured binding" to deconstruct a tuple in-place as follows:
auto [age, name, height] = tup;You can even use this in other contexts, which is awesome!
std::map <char, int> charFrequency;
/* Populate map with frequencies */
for (auto [c, freq] : charFrequency){
assert(charFrequency[c] == freq);
}Where do I use tuples?
Anytime you have a compound return value and you don't want to write a class specifically for it!
Example: suppose in Project 1, you wanted to create a list of all collisions in the world. Each element of the list should contain the colliding object along with the colliding point, like so:
collisions = [(Box 1, Ball, point1), (Box1, Box2, point2) .... ]
collisions = [(Box 1, Ball, point1), (Box1, Box2, point2) .... ]
You could write a class for this, but if you're just going to break it back apart again, that's just a class name cluttering up your namespace.
Instead, use a tuple to temporarily group these objects together!
std::vector<std::tuple<GameObject, GameObject, Point>> collisions; // Please just use autoNote: if you find yourself writing lots of functions taking in tuples, maybe consider writing a class. Tuples in C++ are most effective when they're temporary structures, not core data representations.
I/O Library
<iostream> and <fstream>
There are two things file-based I/O libraries need to do
Modify individual files (file access)
- Reading files
- Writing to files
- Appending to files
Modifying relationships between files (filesystem access)
- Search in directory
- Move file
- Delete file
Up until C++17, there was no standard way to access the filesystem in C++!
If you need a way to access the filesystem in pre-C++17, use a library like TinyDir.
Reading and Writing Files
The fundamental C++ abstraction for I/O is the stream.
Note: <iostream>, <fstream>
Three steps to any file operation:
- Open stream over a file
- Write/Read file
- Close stream
Reading and Writing Files
The fundamental C++ abstraction for I/O is the stream.
Note: <iostream>, <fstream>
Three steps to any file operation:
- Open stream over a file
- Write/Read file
- Close stream
Reading and Writing Files
Opening A File
Reading/Writing File
Closing A File
We can open a file using the stream constructors.
using std::istream;
using std::ostream;
using std::fstream;
int main(){
istream f1("file1.txt");
ostream f2("file2.txt");
fstream f3("file3.txt",
fstream::out | fstream::append);
}We can read/write files using the bitshift operators
std::ostream f("test.csv");
// Print a table as CSV format
for(const auto& row : table){
for(double val : row){
f << val << ',';
}
f << '\n';
}
???
RAII takes care of this for us!
How does << work?
It may seem like magic that the shift operators just work with streams, but it's not!
These operators are user-defined.
std::ostream &operator<<(std::ostream &os, const Stack &stack) {
os << "Stack( " << std::hex;
if (!stack.empty()) {
os << stack.front();
for (std::size_t i = 1, e = stack.size(); i < e; ++i)
os << "; " << stack[i];
}
os << std::dec << " )";
return os;
}Define your own input/output operators, and let the standard library do the rest!
Containers
There are three general categories of containers in the C++ Standard Library
Sequential Containers
- vector
- deque
- list
- forward_list
- array
- string
Associative Containers
- map
- set
- multimap
- multiset
- unordered_map
- unordered_set
- unordered_multimap
- unordered_multiset
Container Adapters
- stack
- queue
- priority_queue
What's the fundamental difference between the sequential and associative containers?
Sequential Containers
- vector
- deque
- list
- forward_list
- array
- string
Associative Containers
- map
- set
- multimap
- multiset
In sequential containers, it is meaningful to talk about an element occurring "before" another element.
The Sequential Containers
vector, array, string
You should already have an idea of how these work!
One note: the standard stipulates that all operations on a vector should be O(1) except for insert, assign, and erase, which can be O(n).
dequeue
A Double-Ended Queue.
Very similar to a vector except that you get an O(1) push_front() and pop_front().
Vectors store their data internally as one contiguous piece of memory, reallocating if needed to get a larger memory piece.
dequeues often store their data internally as several smaller chunks, meaning less reallocation at the cost of increased traversal cost.
If you only ever need to access your data from the ends, consider a dequeue. Otherwise, vector should be more than good enough.
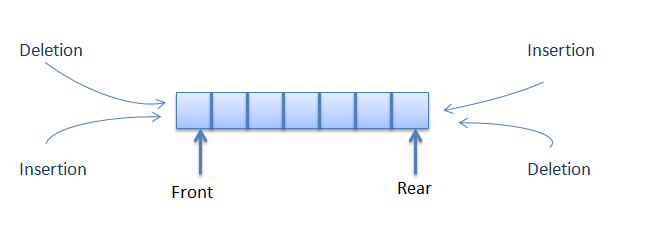
list, forward_list
Implementation of linked list (double and single, respectively) in C++.
Essentially the same interface as the vector/dequeue!
- push_front()/pop_front()
- push_back()/pop_back()
- insert()
- emplace()
- erase()
- swap()
- etc...
The only difference is how these methods are implemented. The list classes guarantee that insert is O(1) anywhere, instead of just at both ends (dequeue) or the back (vector).
Q: Which sequential container should I use?
A: Use vector.
Q: But what if I...
A: Use vector.
Q: But I really need...
A: Use vector.
Q: But my program requires...
A: That's lovely, use vector.
Q: HONESTLY NOW 😠
A: Alright, alright.
There are certain applications where dequeue and lists do offer a speed advantage...but in general, people are very bad at predicting when this is the case!
Suppose I need to read in a list of numbers (which is unsorted during input), and store them in sorted order. I don't know how long the list is in advance.
What data structure would be best suited for this task?
- Growable Array
- Linked List
- Binary Tree
- Associative Array
The answer is "Binary Tree."
...but how different are the Linked List and Vector?
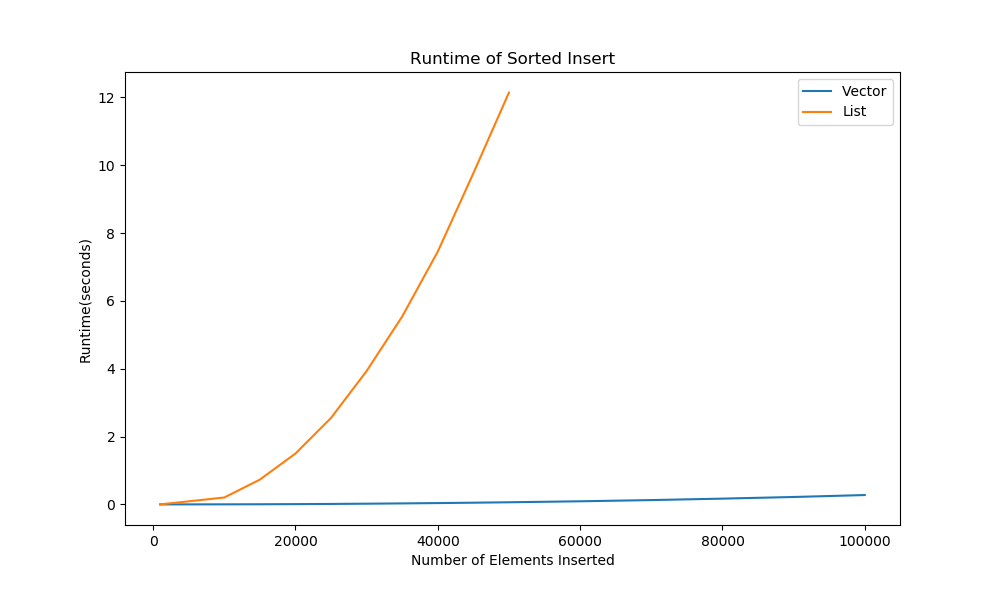
Max vector time (100k elements) is 0.26s, a tree-based approach is under 0.01s
If instead of inserting in sorted order, we just always insert at the midpoint, the linked list winds up doing better than the vector...
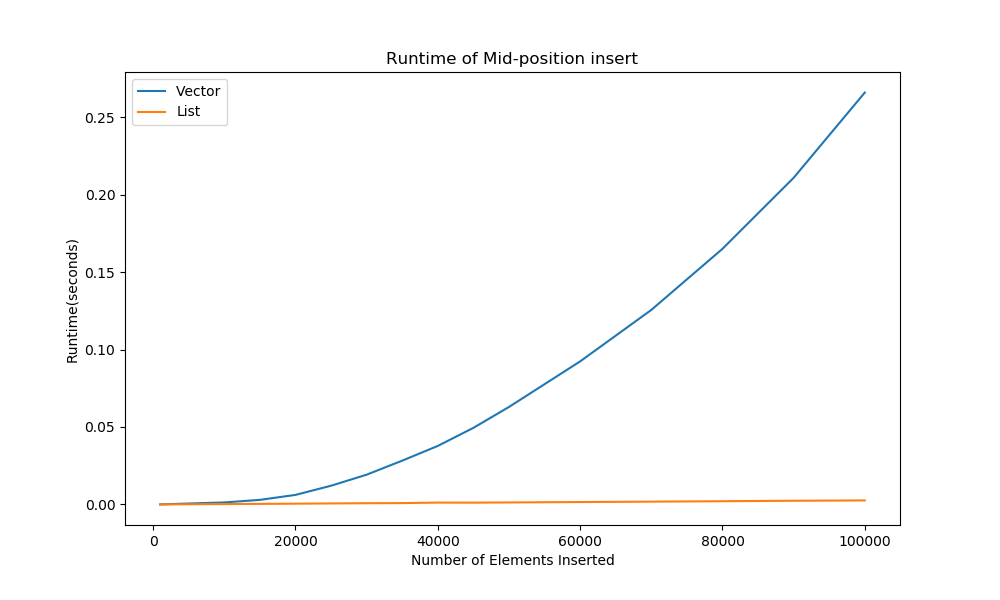
...but this benchmark is pretty meaningless!
C++ offers vectors, dequeues, linked lists, and arrays for sequential containers
but unless you can demonstrate that another container gives better performance in your actual program, you should stick with vector and dequeue.
(we may see some examples of exceptions next week--game companies are infamous for not wanting to use the standard library)
Associative Containers
There are actually only two associative containers: map and set
Use comparison (trees) or hash to identify element?
Allow multiple copies of same element?
| Comparison | Hashing | |
|---|---|---|
| No | map set |
unordered_map unordered_set |
| Yes | multimap multiset |
unordered_multimap unordered_multiset |
A set of decisions around policy balloon this into 8 different associative containers
For the rest of this presentation, we'll look at <map>
The API for <set> is pretty similar.
What's the definition of a map?
template < typename Key,
typename T,
typename Compare = less<Key>,
typename Alloc = allocator<pair<const Key,T> >
> class map;What are all these pieces used for?
- Key: Type of the map's key
- T: Type of the map's value
- Compare: A function to compare two keys
- Alloc: the function to allocate memory for a map element
map stores the key/value pairs in an ordered data structure, usually a red-black tree
An Example With Maps
Let's say we want to create a map that maps tags to dogs
class NameTag{
string name;
Address addr;
Material m;
};std::map<NameTag, Dog> m;
NameTag t;
Dog d;
m[t] = d;In file included from /usr/include/c++/9/string:48,
from test.cpp:1:
/usr/include/c++/9/bits/stl_function.h: In instantiation of ‘constexpr bool std::less<_Tp>::operator()(const _Tp&, const _Tp&) const [with _Tp = NameTag]’:
/usr/include/c++/9/bits/stl_map.h:497:32: required from ‘std::map<_Key, _Tp, _Compare, _Alloc>::mapped_type& std::map<_Key, _Tp, _Compare, _Alloc>::operator[](const key_type&)
test.cpp:23:8: required from here
/usr/include/c++/9/bits/stl_function.h:386:20: error: no match for ‘operator<’ (operand types are ‘const NameTag’ and ‘const NameTag’)
386 | { return __x < __y; }
| ~~~~^~~~~
In file included from /usr/include/c++/9/bits/stl_algobase.h:64,
from /usr/include/c++/9/bits/char_traits.h:39,
from /usr/include/c++/9/string:40,
from test.cpp:1:
/usr/include/c++/9/bits/stl_pair.h:454:5: note: candidate: ‘template<class _T1, class _T2> constexpr bool std::operator<(const std::pair<_T1, _T2>&, const std::pair<_T1, _T2>&)’
454 | operator<(const pair<_T1, _T2>& __x, const pair<_T1, _T2>& __y)
| ^~~~~~~~...ugh
In file included from /usr/include/c++/9/string:48,
from test.cpp:1:
/usr/include/c++/9/bits/stl_function.h: In instantiation of
‘constexpr bool std::less<_Tp>::operator()(const _Tp&, const _Tp&) const
[with _Tp = NameTag]’:
/usr/include/c++/9/bits/stl_map.h:497:32: required from ‘std::map
error: no match for ‘operator<’ (operand types are ‘const NameTag’
and ‘const NameTag’)
386 | { return __x < __y; }What is this error message telling us?
Translation: I don't know how to implement less<T> for T = NameTag
We need to tell C++ how to compare two NameTags!
There are many ways to do this!
- Define a less-than operator on the class
- Overload std::less<NameTag>
- Create a class which compares NameTags
- Write a lambda function
bool NameTag operator<(const NameTag& other){
// Implementation
}using ntcompare = std::function<bool(const NameTag&, const NameTag&)>;
ntcompare compare_tags = [](const NameTag& a, const NameTag& b){ /* ... */ };
std::map<NameTag, Dog, ntcompare>(compare_tags);Unordred_map uses hashes to store elements
template<
class Key,
class T,
class Hash = std::hash<Key>,
class KeyEqual = std::equal_to<Key>,
class Allocator = std::allocator< std::pair<const Key, T> >
> class unordered_map;- Key, T: Same as before
- Hash: a function for hashing keys
- KeyEqual: a function for checking if one key is the same as another
- Allocator: same as before
Java uses the term "TreeMap" and "HashMap" for the concepts of "map" and "unordered_map", respectively.
Which should I use?
The ordered variants of map and set keep their entries in sorted order.
This means that you can easily iterate over the entries in sorted order.
The unordered variants of map and set have O(1) lookup times.
This makes them well-suited to applications where lookup time is a major bottleneck.
There is no best structure.
Benchmark both and decide! If you can't spare the time to benchmark, then it probably doesn't actually matter that much.
Container Adaptors
Container Adaptors
The containers we've seen so far work by defining their own storage:
- vector: contiguous memory chunk
- dequeue: multiple memory chunks
- (forward) list: one memory chunk per element
- set/map: balanced tree
- unordered set/map: hash table
Container Adaptors don't do this--instead, they wrap an existing class to provide ADT functionality.
template<
class T,
class Container = std::deque<T>
> class stack;
stack<int> s1;
stack<int, std::vector> s2;Reminder: Project 3 Due Wednesday
Read the project guidelines carefully. I will most likely not have time to do regrades for this project.
Guest Lecture Next Week
Prof. Sarah Abraham on the Unreal Engine and Game Tech*
*subject to change