Filesystem Fundamentals
In-Class Activity
Direct Allocation
File header points to each data block directly (that's it!)

Advantages? Disadvantages?
Indexed Allocation
- OS keeps a special block of disk pointers called the index block.
- The array is initially empty.
- When a block needs to be allocated to the file, the OS allocates that block, then fills in the appropriate parts of the index block.

Indexed Allocation: Access
CPU
How many disk reads to access the first block?
(We always start with the block# of the file header)
Indexed Allocation: Access
CPU
How many disk reads to access the first block?
(We always start with the block# of the file header)
- Read header
H
Indexed Allocation: Access
CPU
How many disk reads to access the first block?
(We always start with the block# of the file header)
- Read header
- Find address of index block
-
Read index block
H
IB
Indexed Allocation: Access
CPU
How many disk reads to access the first block?
(We always start with the block# of the file header)
- Read header
- Find address of index block
- Read index block
- Find address of first block from index block
-
Read first block
H
1
What if I want to read the second block from here? (sequential access)
Indexed Allocation: Access
CPU
How many disk reads to access the first block?
(We always start with the block# of the file header)
- Read header
- Find address of index block
- Read index block
- Find address of first block from index block
-
Read first block, replacing the header
1
What if I want to read the second block from here? (sequential access)
IB
Indexed Allocation: Access
CPU
How many disk reads to access the first block?
(We always start with the block# of the file header)
- Read header
- Find address of index block
- Read index block
- Find address of first block from index block
- Read first block, replacing the header
- Find address of second block in index block
-
Read second block
2
IB
Indexed Allocation: Access
CPU
How many disk reads to access the first block?
(We always start with the block# of the file header)
- Read header
- Find address of index block
- Read index block
- Find address of first block from index block
- Read first block, replacing the header
- Find address of second block in index block
-
Read second block
2
IB
Indexed Allocation: Access
CPU
How many disk reads to access the third block?
(We always start with the block# of the file header)
Random Access
Indexed Allocation: Access
CPU
How many disk reads to access the third block?
(We always start with the block# of the file header)
Random Access
- Read header
H
Indexed Allocation: Access
CPU
How many disk reads to access the third block?
(We always start with the block# of the file header)
Random Access
- Read header
- Find address of index block
-
Read index block
H
IB
Indexed Allocation: Access
CPU
How many disk reads to access the third block?
(We always start with the block# of the file header)
Random Access
- Read header
- Find address of index block
- Read index block
- Find address of third block in IB
-
Read third block
3
IB
Indexed Allocation: Assessment
How fast is sequential access? How about random access?
How bad is fragmentation?
What if we want to grow the file?
Does this support small files? How about large files?
Indexed Allocation: Extensions


Linked Index Blocks
Multilevel Index Blocks
For very large files,do multilevel index blocks or linked index blocks provide better random access?
Filesystem Mad Libs
First, calculate how many pointers can be stored in a block if you have 4-byte pointers and 4KB blocks. Call this number N. Also answer what kind of data a disk-pointer is. A floating point? A string?
Next, choose an allocation scheme for each of the following block ranges:
- For the first 10 blocks of a file, use __________ allocation
- For blocks from 10 to \(10+N\), use ________ allocation.
- For blocks beyond the \(10+N\)th, use _________ allocation.
Finally, analyze your new filesystem! Answer some of the following questions:
- How many accesses do we need to access small files sequentially? Randomly?
- How many accesses do we need to access large files sequentially? Randomly?
- Is there a maximum file size? If so, what is it?
- What is the minimum number of blocks we need to corrupt in order to break the file? [1]
- Is fragmentation an issue in this filesystem? Only at certain file sizes? Not at all?
- Can you easily grow files? Only at certain filesizes? Not at all?
- How hard do you think it would be to implement this system?
[1] Remember that we can corrupt any file layout by breaking its header block. We want to ask about whether we can corrupt the file by breaking any non-header block.
Berkeley Mad Libs
Next, choose an allocation scheme for each of the following file sizes:
- For the first \(10\) blocks, use direct allocation
- For the next \(N\) blocks after that, use multilevel indexed allocation.
- For the next \(N^2\) blocks after that, use multilevel indexed allocation (double indirect).
- If there are still blocks left, use multilevel indexed allocation (triple indirect)
Results in the Berkeley Fast File System (FFS)
Note: the folks at Berkeley write a mean UNIX system, but their idea of mad libs is apparently pretty boring.
This filesystem was invented at UC Berkeley in the early 80s for the Berkeley Software Distribution.
It was usable on MacOS (formerly OSX) as late as 2012 (!!)
Survives in modern FreeBSD as UFS2, its design inspired many other filesystems including the ext family used by Linux
- Small file access?
- Sequential large file access?
- Random large file access?
- Max file size?
- Fragmentation an issue in this filesystem?
- File growth?
- File corruption? [1]
- How hard do you think it would be to implement this system?
Example: Fast File System
- Developed for the Berkeley Software Distribution UNIX (BSD) in the early 80s
- Was possible to use with OSX (MacOS) systems until 2012 (!!)
-
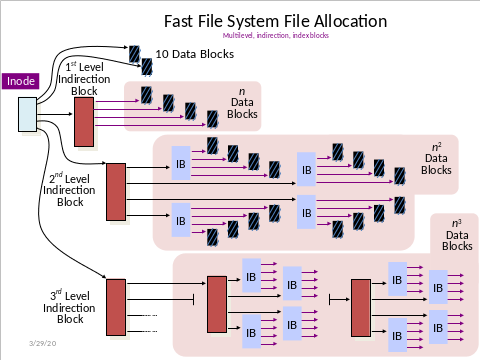
Each inode (file header in UNIX terminology) contains 13 pointers
- First 10 pointers point directly to data blocks
- 11th pointer points to an index block of 1024 pointers (one indirection)
- 12th pointer points to a block of pointers to index blocks blocks (two indirections)
-
13th pointer points to a block of pointers to blocks of pointers to index blocks (three indirections)
- Advantages: simple to implement, supports incremental file growth, supports small files
- Disadvantages: random access to large files is inefficient, many seeks.
Multileveled Indexed Files: Key Ideas
| Pointer Type | # Ref Blocks | Total Size At Level |
|---|---|---|
| Direct | 10 * 1 = 10 | 40 KB |
| Single Indirect | 1 * 512 = 512 | 2 MB |
| Double Indirect | 512 * 512 = 2^18 | 1 GB |
| Triple Indirect | 512*512*512 = 2^24 | 512 GB |
| Total | ~513 GB |
FFS: assuming 4KB blocks, 8-byte pointers = 512 pointers/block
- Tree-like structure
- Efficient for finding blocks
- Efficient in sequential reads
- Once indirect block is read, can read 100s of data blocks
- Fixed Structure
- Relatively straightforward to implement
- Asymmetric
- Efficiently support both large and small files
- Most files can be stored using only direct blocks, but allows very large files using indirect blocks.
Answers to other questions about FFS
-
Small file access?
Fast! (Direct-allocated access)
-
Sequential large file access?
Fast! Need to read one new index block every \(N\) accesses and two new index blocks every \(N^2\) accesses.
-
Random large file access?
Not great--need to read three index blocks per random access--but not horrific like linked.
-
Max file size?
Calculated on previous slide: 512 GB at 64-bit pointers with 4KB blocks. Roughly 1 TB for 32-bit pointers at the same block size.
-
Fragmentation an issue in this filesystem?
Nope!
-
File growth?
Easy! New allocation always takes place in 1-block units, so just grab a single block and goooooooo.
-
File corruption?
Corrupting index blocks will break most files, but there are relatively few index blocks (1/1024 at most) so randomly getting an index block corrupted would be very unlucky.
-
How hard do you think it would be to implement this system?
Pretty simple! It might even make a good choice for Pintos (HINT HINT)
fclones is a duplicate file detector
General workflow:
- Read file from disk
- Hash file contents with hash functions
- Store hash of file, compare against other files
- If hashes match, actually compare the file byte-by-byte just to make sure
Expensive

Does this sound familiar?
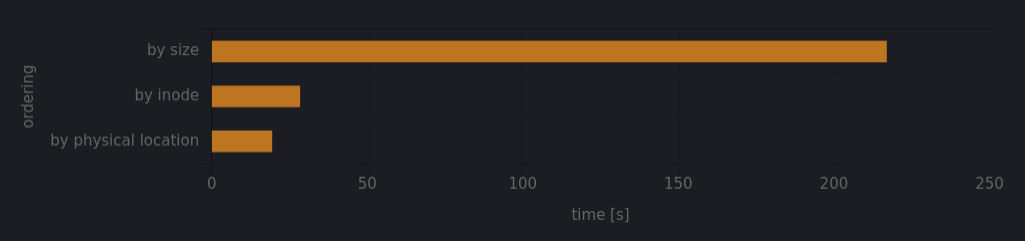
Idea: Sort the file accesses to speed up I/O
Problem 1: As we just learned, this only works perfectly if the file layout is contiguous!
Problem 2: fclones is a userspace program--it has to rely on the OS to tell it where files are. Maybe the OS it's running on won't be so nice!
Since fclones uses read() calls to get data, we should order read() calls by the location of data on the disk.
Idea: Use inode order as a proxy for file block order!
Why does this work?
Hint: Programmers are lazy...
Results