Questions
Are final project presentations a part of the grade?
Do we have to make all our assets (sound, images) ourselves for the project?
Can we work alone for the final project?
Yes, it's 10% of the final project grade.
No. Please take assets from places online (unless you want artistic control over them) and credit them appropriately.
Yes.
When making physics, is it better to make physics in a separate class or in the object being simulated?
Usually in the object being simulated.
How long does it take to make a simple physics engine?
A simple physics engine is almost always wrong. The question then becomes how wrong you want to let it be.
Are hurtboxes perfectly shaped to characters in newer games?
No, because perfect forming makes it hard to calculate collisions quickly. Most games still use variants on ellipsoids, cylinders, and boxes.

Machine Learning, Artificial Intelligence, and Image Generation
What this class is not
Golly gee willikers check out what machine learning can do!


Artificial Intelligence is dangerous and should be countered with nuclear airstrikes.
What this class is not
How to use <API> to accomplish <machine learning task> in your application for <startup company> which is valued at <number> <money units>.
What this class is not
Going to teach you how to actually do any machine learning.
(x_train, _), (x_test, _) = fashion_mnist.load_data()
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
print (x_train.shape)
print (x_test.shape)

Even in well-designed libraries for machine learning, the code itself looks nothing like the concepts behind it. It's annoying.
What this class is
A very high level overview of some of the concepts used in machine learning, specifically in the image generation arena.
How people think about the problems and their respective solutions.
Me talking way too fast about ideas I think are cool.
Don't be afraid to ask me to slow down or re-explain something!
What is Machine Learning?
What is Machine Learning?
Machine learning (ML) is a field of inquiry devoted to understanding and building methods that 'learn', that is, methods that leverage data to improve performance on some set of tasks
Wikipedia


Classic Programming
Completely specify what the computer should do.
Write code that tells the computer what operations to carry out.
def my_function(x):
return 2 * x + 1Machine Learning
Partially specify what the computer should do.
Write code that tells the computer mostly what it should do, but leave a few values ambiguous.
def my_function(x):
return a * x + bUse examples to teach the computer what the parameters should be.
Machine learning is not some magical way to make computers do things they couldn't before!
The computer is still executing a function! Instead of specifying what the function is 100%, we're going to feed the computer examples and adjust the function based on those examples!
Common Machine Learning Tasks

Example: Semantic Segmentation
What type of data is a grayscale (black & white) image?

What would a function look like to determine if a given pixel is part of the stroke or part of the background?
def is_background(image, i, j):
if image[i][j] > 5:
return True
else:
return Falsedef semantic_category(image, i, j):
# Do some analysis work
#
#
if is_car(analysis_result):
return 1
elif is_bus(analysis_result):
return 2
# etc. etc.def semantic_segments(image):
for i in range(len(image)):
for j in range(len(image)):
semantic_category(image, i, j)
What is Artificial Intelligence?
How do we adjust the parameters?
def my_function(x):
return a * x + bThese parameters don't set themselves!
First, we need a list of examples:
- 2, 5
- 7, 15
- -3, -5
- 0, 1
- 100, 201
def my_function(x):
return a * x + bLet's start by guessing values for a, b. Maybe we'll say they start at a = 0 and b = 5.
| Example Input | Example Output | Our Output |
|---|---|---|
| 2 | 5 | 5 |
| 5 | 11 | 5 |
| 100 | 201 | 5 |
| -3 | -5 | 5 |
Well....that's not very good.
def my_function(x):
return a * x + bWhat if we tried a = 0, b = 100?
| Example Input | Example Output | Our Output |
|---|---|---|
| 2 | 5 | 100 |
| 5 | 11 | 100 |
| 100 | 201 | 100 |
| -3 | -5 | 100 |
Well....that's not very good either.
| Example Input | Example Output | Our Output |
|---|---|---|
| 2 | 5 | 5 |
| 5 | 11 | 5 |
| 100 | 201 | 5 |
| -3 | -5 | 5 |
| Example Input | Example Output | Our Output |
|---|---|---|
| 2 | 5 | 100 |
| 5 | 11 | 100 |
| 100 | 201 | 100 |
| -3 | -5 | 100 |
Which is worse?
a = 0, b = 100?
a = 0, b = 5?
Quantifying Error
We need some way to assign a number to the intuitive idea of "how bad the error is."
One common idea: take the square of the difference between the output and the target value (least squares)
def mse(true_out, our_out):
loss = 0
for i in range(len(true_out)):
loss += (true_out - our_out) ** 2These are known as loss functions. If you go into ML, you'll hear about a lot of these things:
- MSE Loss
- MAE Loss
- Cross-Entropy Loss
- etc. etc. etc.
def my_function(x):
return a * x + bPartially Complete Function
| Example Input | Example Output | Our Output |
|---|---|---|
| 2 | 5 | 5 |
| 5 | 11 | 5 |
| 100 | 201 | 5 |
| -3 | -5 | 5 |
List of Examples
Loss Function
The Descent
def my_function(x):
return a * x + bWe tried a = 0, b = 5. These were our results.
| Example Input | Example Output | Our Output |
|---|---|---|
| 2 | 5 | 5 |
| 5 | 11 | 5 |
| 100 | 201 | 5 |
| -3 | -5 | 5 |
If we increased a, would the results be better or worse?
MSE Loss = 38552
def my_function(x):
return a * x + ba = 0.1, b = 5
| Example Input | Example Output | Our Output |
|---|---|---|
| 2 | 5 | 5.2 |
| 5 | 11 | 5.5 |
| 100 | 201 | 55 |
| -3 | -5 | 4.7 |
Loss is 30% lower!
MSE Loss = 21440.38
We could just keep trying this!
- Try changing a or b a small amount, see how the loss changes.
- If the loss decreases, keep the change.
- If the loss increases, revert the change.
- Keep going until you can't decrease the loss anymore.
But real models don't have 2 parameters, they have 3 million.
To actually try this for 3 million parameters (and then actually have to change things) is too slow.
Instead, rely on another observation: for our given examples, we can compute the loss exactly based off of a and b.
For given examples, the loss is a function of a and b!
def compute_loss(inputs, outputs, a, b):
loss = 0
for i in range(len(inputs)):
our_output = a * inputs[i] + b
true_output = outputs[i]
loss += (our_output - true_output) ** 2
return lossIf I change a and b a little bit, does the loss change a little or a lot?
Key Insight: Loss is differentiable
In 1D: derivative tells us how much the Function changes locally


In 2D+: derivative tells us how much the Function changes locally and which direction it changes the fastest
To decrease loss, we can follow the gradient!
Example: We tried a = 0, b = 5.
The (negative) gradient of the function at these values is (39320, 384), so we would increase both a and b.
Keep doing this, and eventually we'll arrive at the correct values for a and b.
Machine Learning, Overall Setup
Machine learning is such a young field that all these steps are areas of active research.
Ingredients
- A parameterized function
- Examples of correct input and output
- A loss function which defines how bad an incorrect output is
- A way to compute gradients of the loss
- Update rules for parameter (training)
def my_function(x):
return a * x + b
But what about....
YEah, I know.
There's a million reasons why this shouldn't work.
But it does.
What is Machine Learning good at?
If you have a function you want to compute, and you don't know how to write code for it, but you can get lots of examples.
Early examples:
- Image labeling
- Defect detection
- Replacing existing (complex) sensors with simple ones
Unknown function, but have Many input and output examples
What is Machine Learning not good at?
If you don't know what your output should be, machine learning will not help you figure that out.

If you know what your output should be, but you can't generate more than a few hundred examples, most ML algorithms will not help you.
Neural Networks
def my_function(x):
return a * x + bThis is a very simple function!
No matter how we fiddle with the parameters, it will only ever output a line.
Useless for trying to learn complex functions like language translation or image segmentation.
def my_function(x):
return a * cos(x) + b * sin(x) +
c * exp(x) + d * x**2 +
e * x**3 + f * sqrt(x) +
# and so on and so forthNeed a function that's capable of capturing more behaviors, but can still be adjusted by changing the parameters (so that we can still train the machine learning model).
Neural Networks
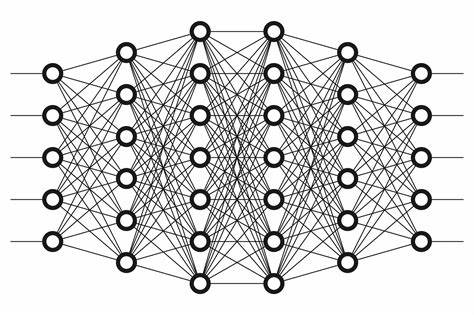
def my_function(x):
return a * cos(x) + b * sin(x) +
c * exp(x) + d * x**2 +
e * x**3 + f * sqrt(x) +
# and so on and so forthNeural Networks
Each layer will apply a simple transformation to the input data, with learned parameters. For example:
Linear
ReLU
MaxPool
Neural Networks
Linear
ReLU
MaxPool
C
A
B
D
E
Q
where \(w_1 \dots w_5\) can be adjusted by gradient descent.
Linear
ReLU
MaxPool
Important idea: we're going to transform the data by doing multiplications, additions, ReLU, and taking the maximum among a few numbers.
Special Callout: Image processing
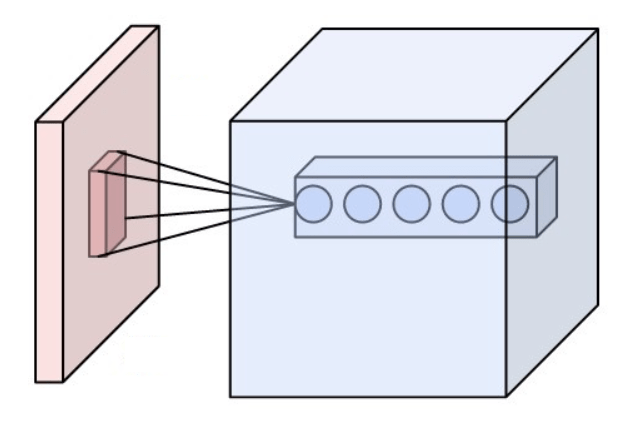
Special Callout: Image Processing
In early layers of an image processing network, we want to gather local information (e.g. colors, edges, brightness) but we don't want to overwhelm the network with too many parameters.
Solution: create neural network layers that operate on small 3x3 windows with learned weights, but the same weights for all areas in the image.
This, combined with clever usage of nonlinear layers and pooling, leads to the convolutional neural network.

VGGNet: A Convolutional Neural Network
It turns out that neural networks have been proven to be able to approximate any function as closely as you want.

...but you may need infinitely many neurons.

CHECKPOINT!

Machine Learning
Basics
Neural Networks
You are here
② Diffusion models
① Neural Radiance Fields
def my_function(x):
return a * x + bPartially Complete Function
| Example Input | Example Output | Our Output |
|---|---|---|
| 2 | 5 | 5 |
| 5 | 11 | 5 |
| 100 | 201 | 5 |
| -3 | -5 | 5 |
List of Examples
Loss Function
Partially Complete Function
| Example Input | Example Output | Our Output |
|---|---|---|
| 2 | 5 | 5 |
| 5 | 11 | 5 |
| 100 | 201 | 5 |
| -3 | -5 | 5 |
List of Examples
Loss Function
Partially Complete Function
List of Examples
Loss Function

DOG

CAT
This is how most commercial image classifiers are trained!
Latent Space encoding example
Text

Raytracing
① Neural Radiance Fields
A method to generate images by simulating the transport of light
A method to generate images by simulating the transport of light
-
Fire light at object
-
Color light appropriately when light hits an object
-
Color pixel if colored light hits eye (or camera)
In practice, this is computationally infeasible.
For every million photons released by the light source, about one will enter the camera.
Reverse Raytracing
In practice, we find the photons that enter the camera and find out what color they would have had.

Done properly with the right rules for bouncing light, raytracing can be gorgeous.
-
Fire light at object
-
Color light appropriately when light hits an object
-
Color pixel if colored light hits eye (or camera)
Implicit Geometry
① Neural Radiance Fields
In order for raytracing to work, we need to know what objects are already in the scene
If we want to use raytracing to generate views of an existing scene, we need to fully digitize the scene before doing so, with full colors and textures---impractical!
Suppose we are raytracing a scene with a purple sphere in it.
Geometry hidden, you tell me color based off of input ray
The color that a particular ray creates is dependent only on the position and direction of the ray!
What is \(f\)?
What is \(f\)?
What is \(f\)?
We don't know....but we can learn it!
What is \(f\)?
We don't know....but we can learn it!
Note: \(f\) is tied to the specific scene. If we want to raytrace a different scene, we will need a different \(f\) (i.e. different weights in our neural net).
| Function to learn | Input ray -> ray color |
| Loss Function | Image similarity |
| Examples | ??? |
Take multiple pictures of the same scene
These photos are the result of raytracing the scene so they form a set of correct examples.

The Latent Space
① Diffusion models
Suppose I generated 1024 x 1024 x 3 random numbers in [0,255] and Treated those as an RGB image.
How likely is it that thiS Array is an Image (i.e. it actually looks like something?)
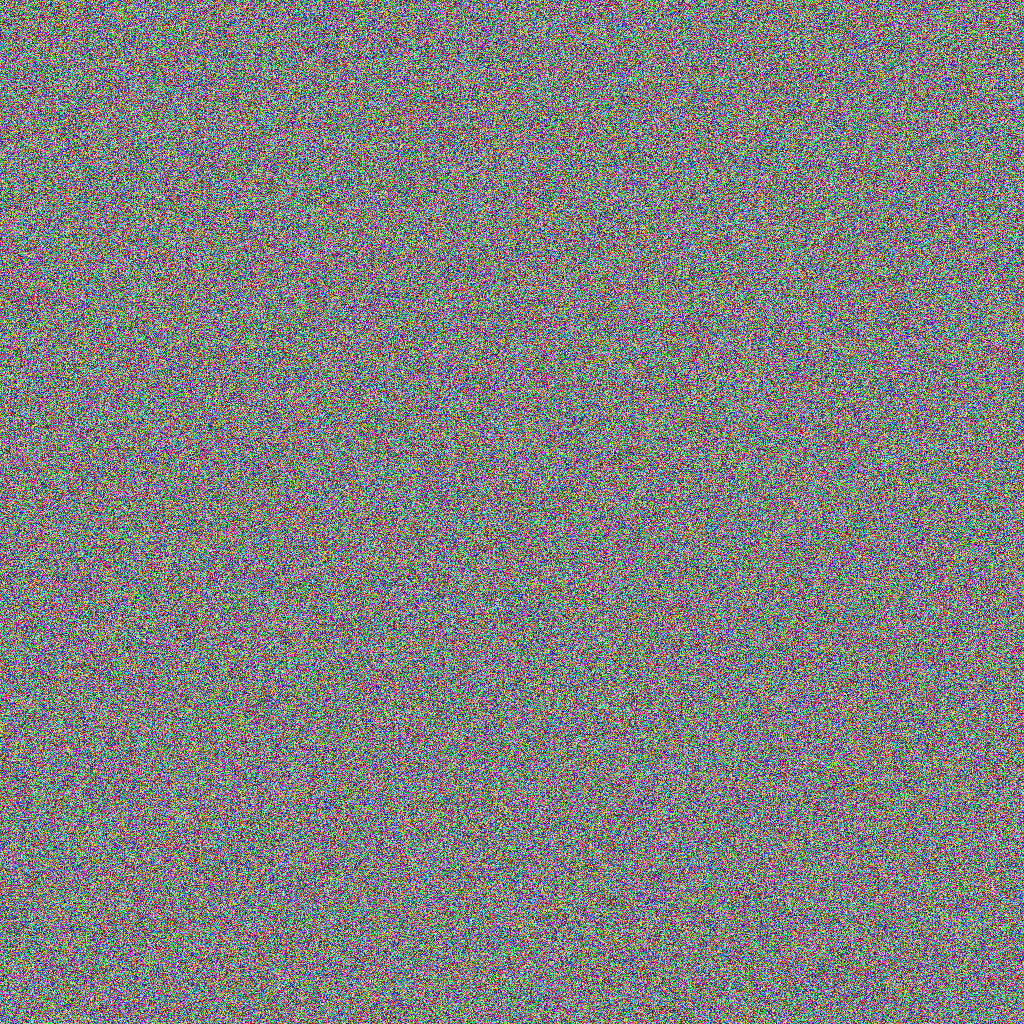


There are way more squares of numbers than images!
All 1024 x 1024 x 3 boxes with values [0,255].
Things that actually look like images.
The space of images is probably not actually a nice small ball within the space of all arrays.
How can we find a representation of the space of images?
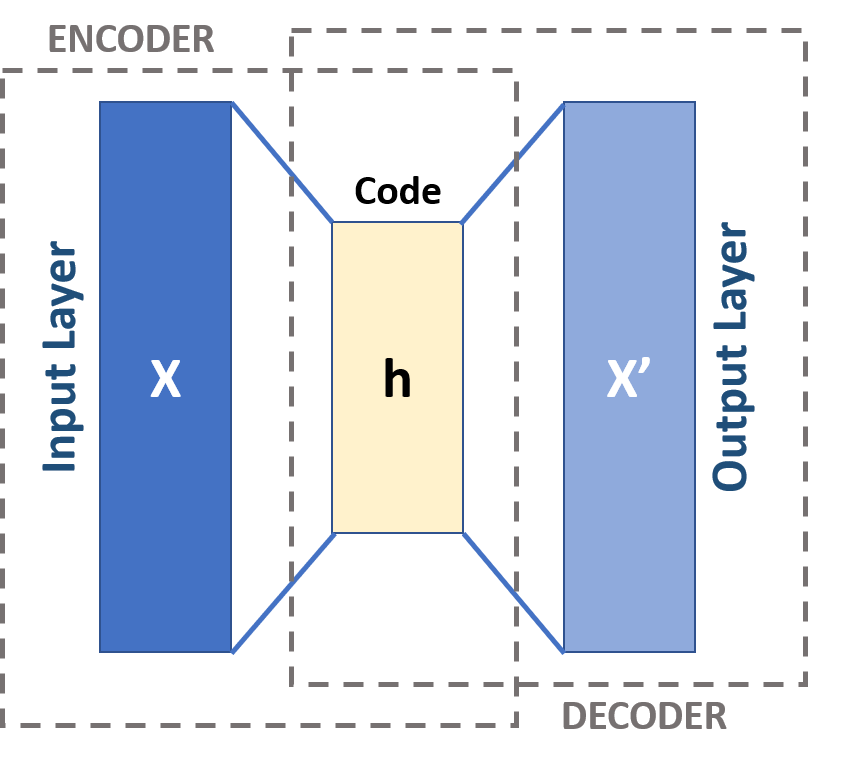
Autoencoder (ENcoder-Decoder)
A neural network which just attempts to replicate its output.
Center layer (bottleneck) is smaller than the input (and also the output).

Why would we want to do this?
In a perfect world, the bottleneck layer forms a perfect representation of all points in the space of images: every image corresponds to some value of the bottleneck, and every value of the bottleneck corresponds to an image.






In practice, for simple autoencoders like this, things aren't perfect. Inserting some random numbers into the central layer and then computing the output won't always give us an image.
But we can already do some cool stuff!

We say the autoencoder has learned the "latent space" of the problem.
Another View of the Latent Space
Latent Spaces are Problem Dependent
If we're trying to generate human faces, our latent space is the space of all human faces.

If we're trying to generate images, our latent space is the space of all images.

If we're trying to do voice generation with text-to-speech, the target voice (and all the sounds it can make) are our latent space.
Swapping Out Halves
Decoder Network
Swapping Out Halves
Swapping Out Halves
Classifier Network
Swapping Out Halves
Swapping Out Halves
Stylization Network
Swapping Out Halves
If the bottleneck layer has condensed information about the domain, we can use another network to extract this information!
http://taskonomy.stanford.edu/
Diffusion Models
① Diffusion models
In practice, simple autoencoders can't quite learn the latent space of complex datasets
But we can generalize this to an encoder-decoder architecture which attempts to capture a similar idea.
A U-Net (encoder-decoder architecture)
Generative Modeling
General idea: turn random noise into meaningful data.

This is a function.
In principle, we can approximate it with a neural network.
But we don't have examples of this function, so we can't train a neural network on examples directly.
Can we somehow generate examples of this function to train a neural network with?
Can we somehow generate examples of this function to train a neural network with?
The noising process is really easy to generate examples of! Just add Noise™.
Take a bunch of images and noise them. Then train a neural network to compute the inverse process (denoising to image)


Training a network to do this in one step is still not feasible!
Image Diffusion
Add noise step-by-step, so that there's a little less information in the image at each step (rather than going from the full image to random noise in a single step)

Now train a neural net to reverse each step of this process!*
*this isn't what actually happens: see references for more information

Source: https://www.calibraint.com/blog/beginners-guide-to-diffusion-models
In principle, we can now take any Gaussian noise (which is the end result of applying the noising process for a very long time)...
..and denoise it into an image of something.
Noising Process
Pause here to complain about excessive math

Diffusion With Text Conditioning
① Diffusion models
We can now go from noise to image, but we have no control over the image that gets generated

?
?
MORE NEURAL NETS
Modern machine learning in a nutshell
monkey eating banana split sundae
Use neural net to predict the correct noise for a given text prompt

(I think GPT might have been sassing me...)
monkey eating banana split sundae
But this isn't used in practice. Probably because it doesn't work well, but who knows?
x1000
Pause here to rant about the state of machine learning publications
monkey eating banana split sundae
Instead, make the prompt an input to the denoising network!
x1000
monkey eating banana split sundae
Okay, but how do we turn text into something that the neural network can understand?
MORE NEURAL NETS
CLIP is a model which is designed to predict which image labels map to which images
This means the text representations it learns should somehow be really well suited for visual tasks.
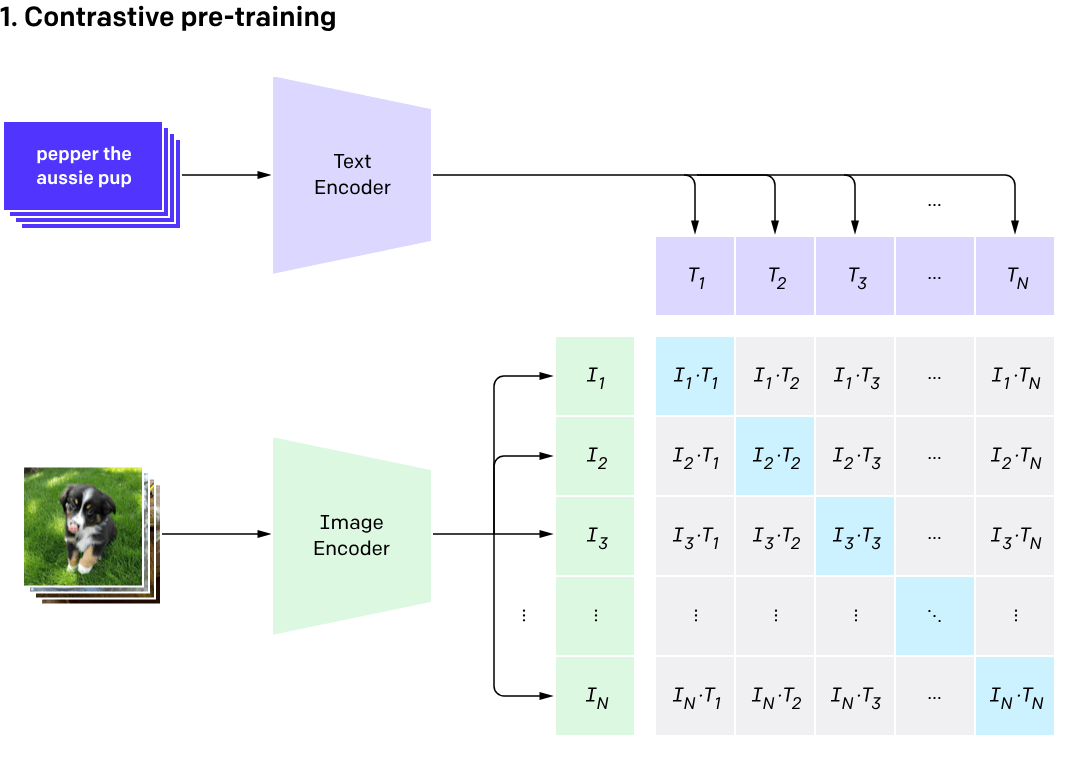
CLIP is a model which is designed to predict which image labels map to which images
CLIP is a model which is designed to predict which image labels map to which images
CLIP is a model which is designed to predict which image labels map to which images
monkey eating banana split sundae
Use CLIP embeddings (latent space vectors) to feed into the denoising network!
This idea forms the core of most Text-to-image generation techniques today, including offerings by Midjourney, OpenAI, etc.
You need slightly more cleverness to deal with the fact that training a neural net over the full image space is too computationally expensive.
See reference Diffusion2 for more details (look for cascade and latent space diffusion)
References and More Information
Machine Learning and Neural Nets
- https://www.tensorflow.org/tutorials/generative/autoencoder
- Introduction to Neural Networks. A detailed overview of neural networks… | by Matthew Stewart, PhD | Towards Data Science
- Machine Learning for Beginners: An Introduction to Neural Networks - victorzhou.com
NERFs
Diffusion
- https://medium.com/@kemalpiro/step-by-step-visual-introduction-to-diffusion-models-235942d2f15c
- https://theaisummer.com/diffusion-models/
- https://github.com/openai/CLIP