Introduction Capsule Networks
1
Alexander Isenko
28.11.2017
In-House presentation @ iteratec
2
Alexander Isenko
28.11.2017
Motivation
Motivation

3
Alexander Isenko
28.11.2017
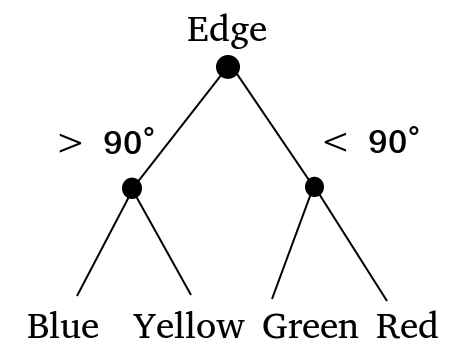
Default Graphics
Graphics
Instantiation Parameters
Rendering
Image
4
Alexander Isenko
28.11.2017
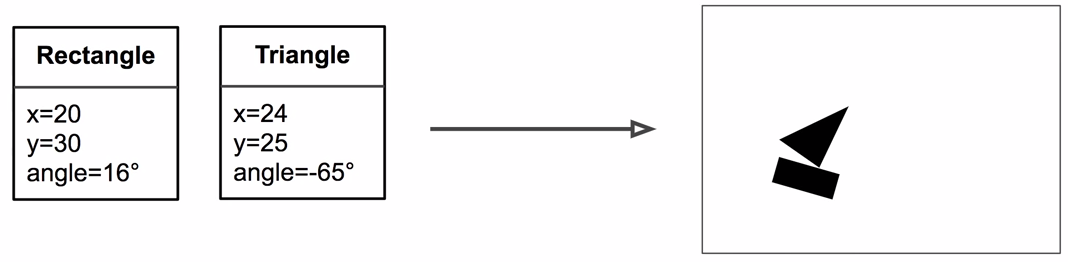
Inverse Graphics
Graphics
Instantiation Parameters
Inverse Rendering
Image
5
Alexander Isenko
28.11.2017
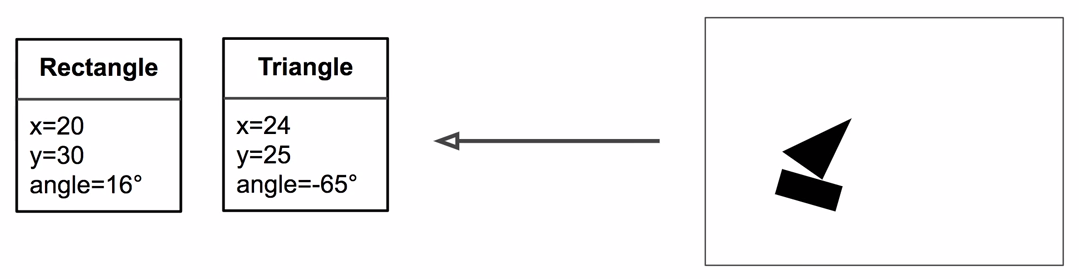
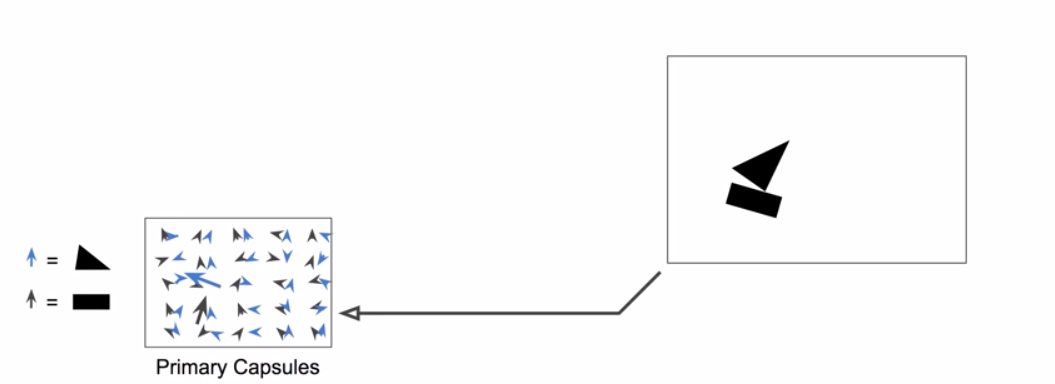
Capsule Activations
Capsules
Capsule Activations
Image
Activation vector:
Length = estimated probability of presence
Orientation = estimated pose parameteres
1
Alexander Isenko
28.11.2017
Capsule Activations
Capsules
Capsule Activations
Image
Convolutional Layers
+ Reshape
+ Squash
6
Alexander Isenko
28.11.2017
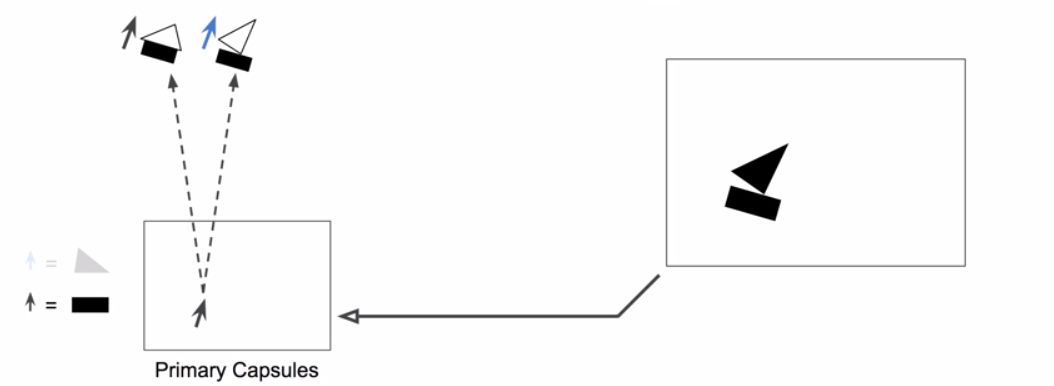
Transformation Matrix
Capsules
7
Alexander Isenko
28.11.2017
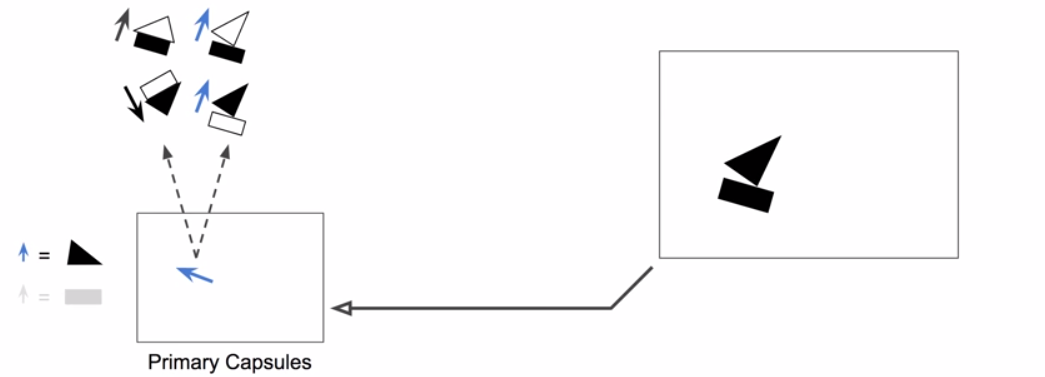
Routing by Agreement
Capsules
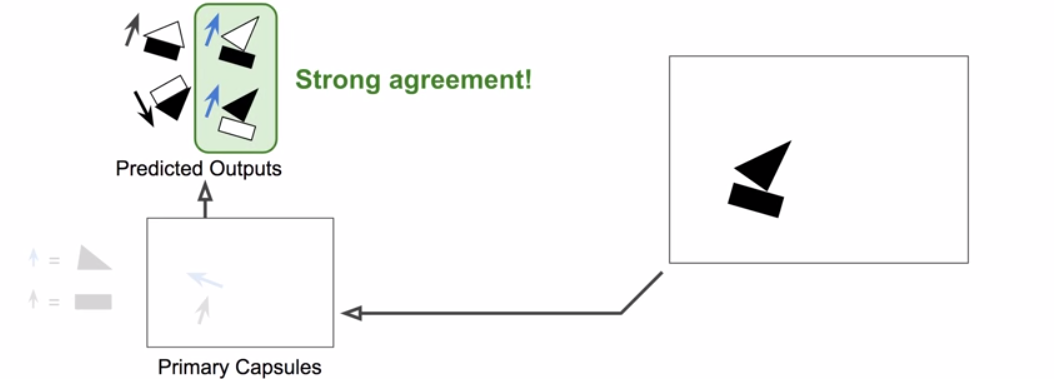
8
Alexander Isenko
28.11.2017
Routing by Agreement
Capsules
Final output of #1 round
Routing coefficient
Prediction vector
Routing weights
Routing weights
9
Alexander Isenko
28.11.2017
Crowded Scenes
Capsules
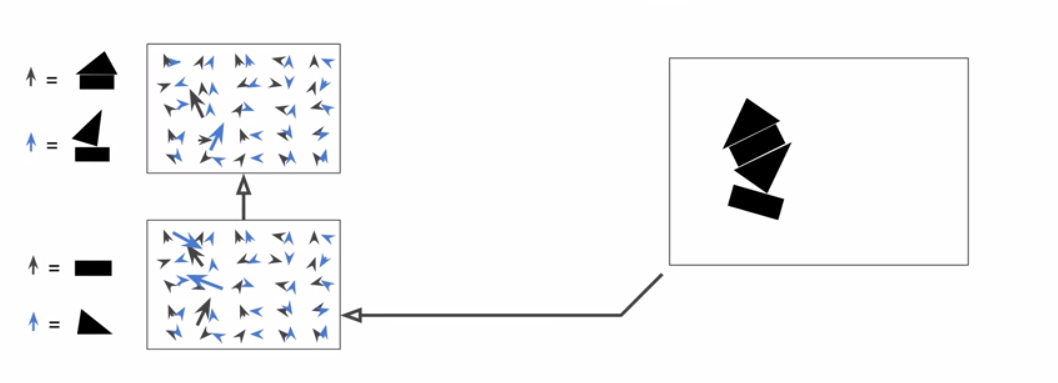
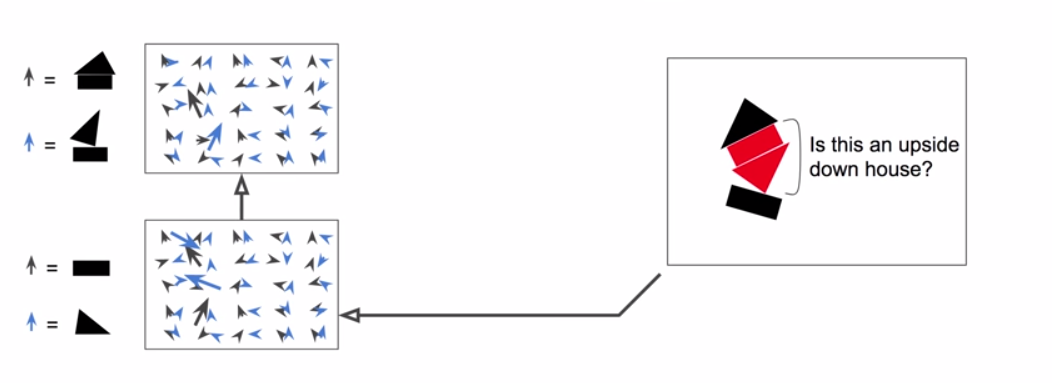
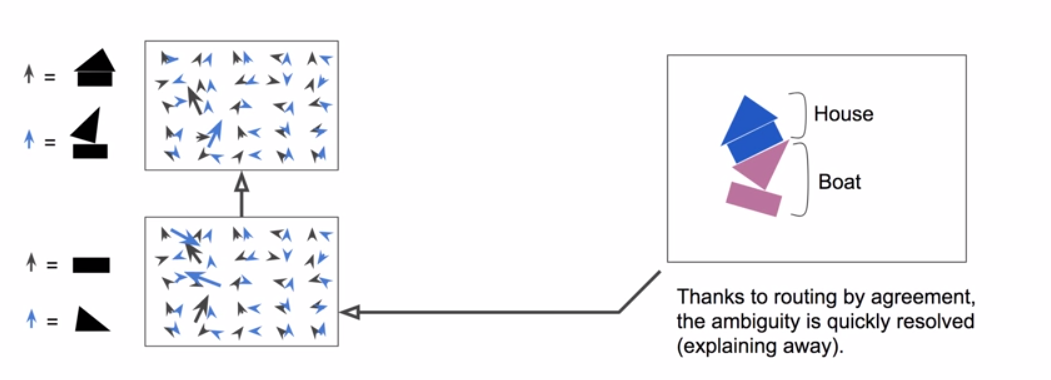
10
Alexander Isenko
28.11.2017
MNIST Classifier
Example
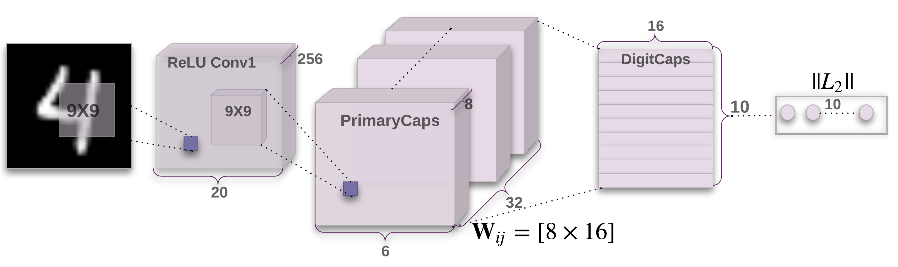
11
Alexander Isenko
28.11.2017
MNIST Latent Variables
Example
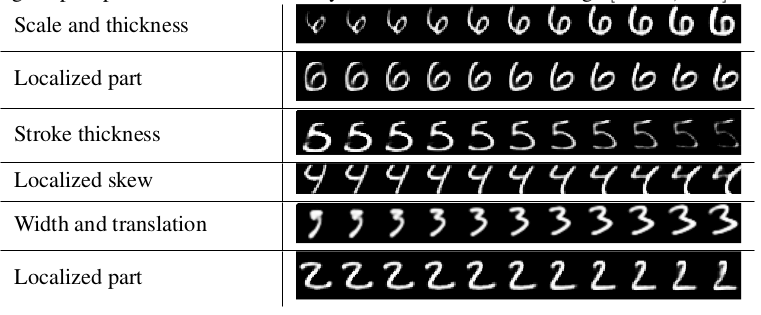
12
Alexander Isenko
28.11.2017
Takeaway
Pros
- Routing by agreement is an innovative concept
- allows for better classification of crowded scenes
- does not throw away information in comp. to MaxPooling
- Activation of the capsules is the vector length
- Learning the transformation matrices
- scale, rotation
- not translation, that's via low level capsules (CNN)
-
Activation vectors are interpretable
- creation of hierarchy
- Parse tree for "every fixation" point
- Requires less data
13
Alexander Isenko
28.11.2017
Takeaway
Pros
Routing
Capsule
output
Routing coefficient
Capsule activation
Transformation Matrix
Prediction vector
14
Alexander Isenko
28.11.2017
Takeaway
- CIFAR10 was not state of the art
- Does it scale? Imagenet?
- Slow training (routing agreement)
- Can't see two close objects next to each other
Cons
15
Alexander Isenko
28.11.2017
Sources
- Link to the original paper
-
Excellent youtube talk where I copied most of the slides
- Implementation links are provided in the description
- A nice blog post