EDA - Automobile Data

Encoding Categorical Data

Learning Outcome
4
Identify real-world applications and the "Dummy Variable Trap" in Auto EDA
3
Explain how One-Hot Encoding and Label Encoding transform text into numbers
2
Differentiate between Nominal (no order) and Ordinal (ranked) categories
1
Define Categorical Data and explain its importance in car datasets
Lets recall....
Handling Missing Data:
Missing values in Price and HP were identified and filled
Outlier Detection:
Extreme values were detected and properly handled
EDA Progress So Far:
The dataset is now clean and ready for processing
Key Concept:
Machines can only understand numerical data, not text
Transition to Next Step:
Convert categories like BMW and Ford into numbers

Imagine a mechanic who understands only numbers, not words....
You need to tell them the car’s fuel type is Petrol
But you cannot use the word, only numeric codes
You must assign codes to fuel types
Without making one fuel type seem “greater” or “better”

1001+1010

If Petrol = 1 and Diesel = 2
The mechanic may think Diesel > Petrol mathematically

We need a coding method that represents categories without creating false mathematical relationships

Humans understand “Hatchback” as a car type
Machines see it as invalid (NaN) until converted to numbers
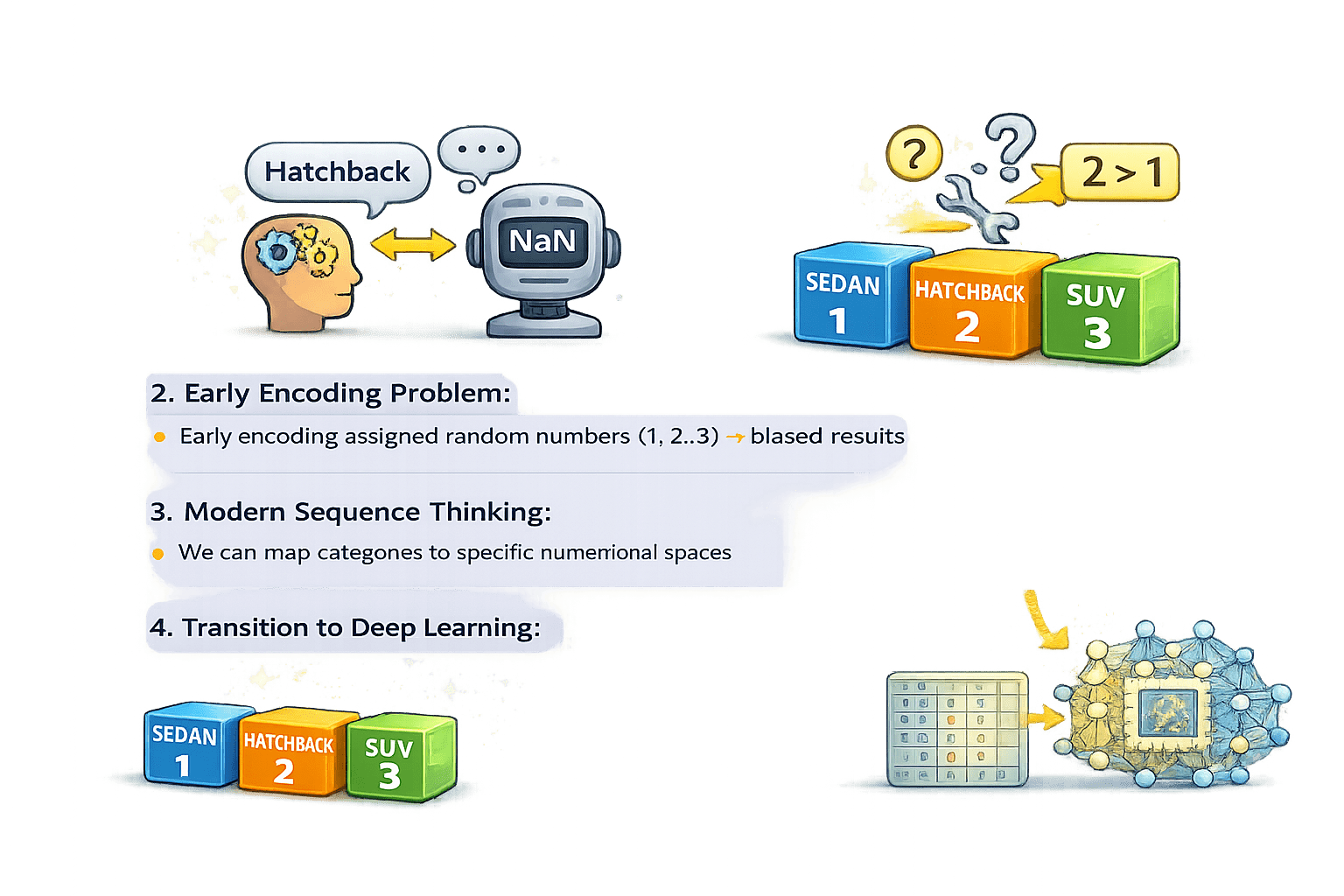
Categories were assigned random numbers (1, 2, 3)
This created bias and incorrect relationships
Categories are mapped to meaningful numerical representations
Each category gets its own defined numerical space
Early Encoding Problem:
Modern Encoding Approach:
This transformation from labels to logic enables machines to understand, learn, and make accurate predictions from real-world data
lets understand it in detail...
Categorical Data Types

Ordinal Data (Ranks)
Has a clear order or ranking
Values follow a meaningful sequence
Examples:
Engine-Size: Small < Medium < Large
Nominal Data (Labels)
No inherent ranking or order
Categories are just names
Examples:
Body-Style: Sedan, Convertible, Wagon
Label Encoding
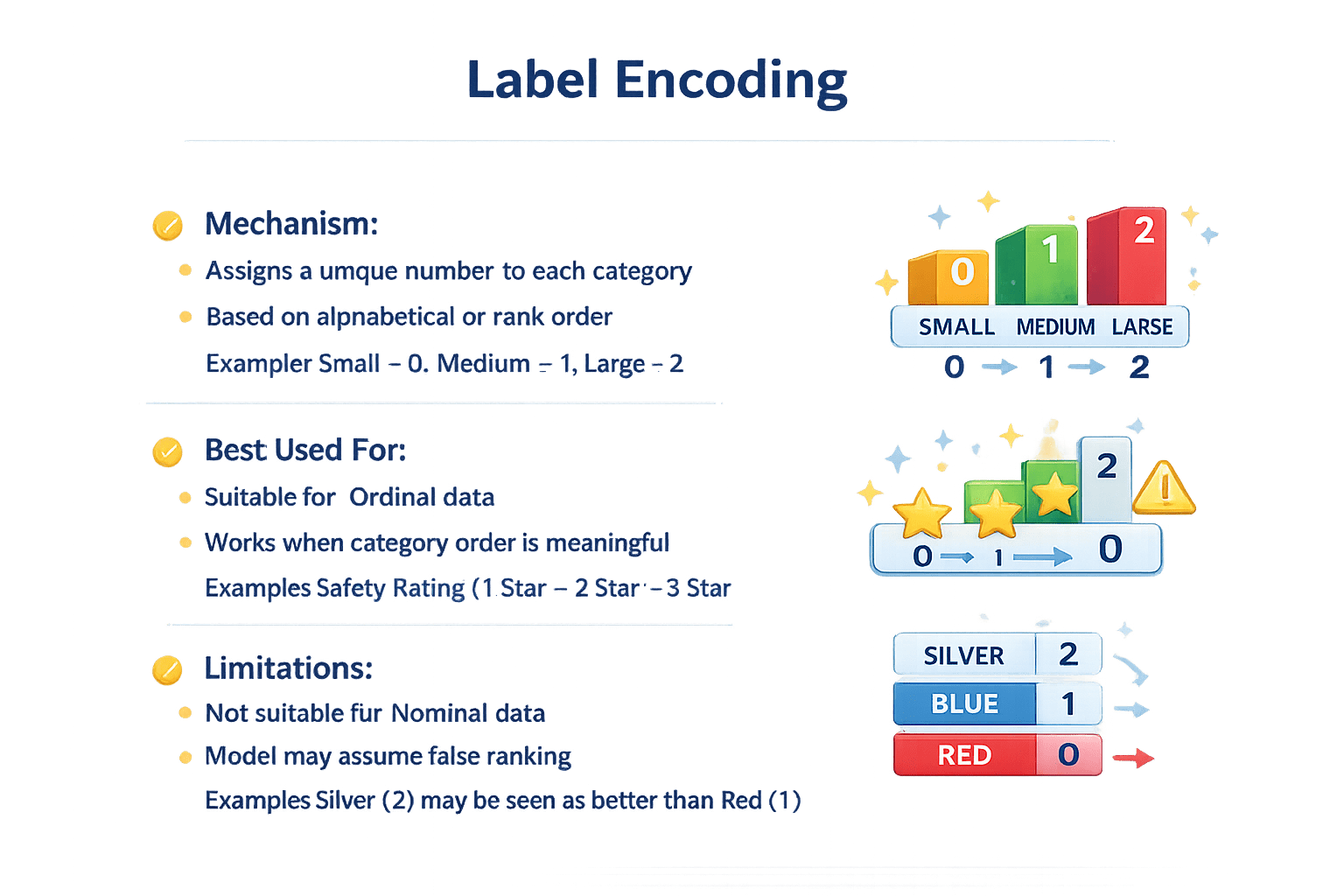
Mechanism
Assigns a unique number to each category
Based on alphabetical or rank order
Example: Small = 0, Medium = 1, Large = 2
Best Used For
Suitable for Ordinal data
Works when category order is meaningful
Example: Safety Rating (1 Star < 2 Star < 3 Star)
Limitations
Not suitable for Nominal data
Model may assume false ranking
Example: Silver (2) may be seen as better than Red (1)
One-Hot Encoding (OHE)
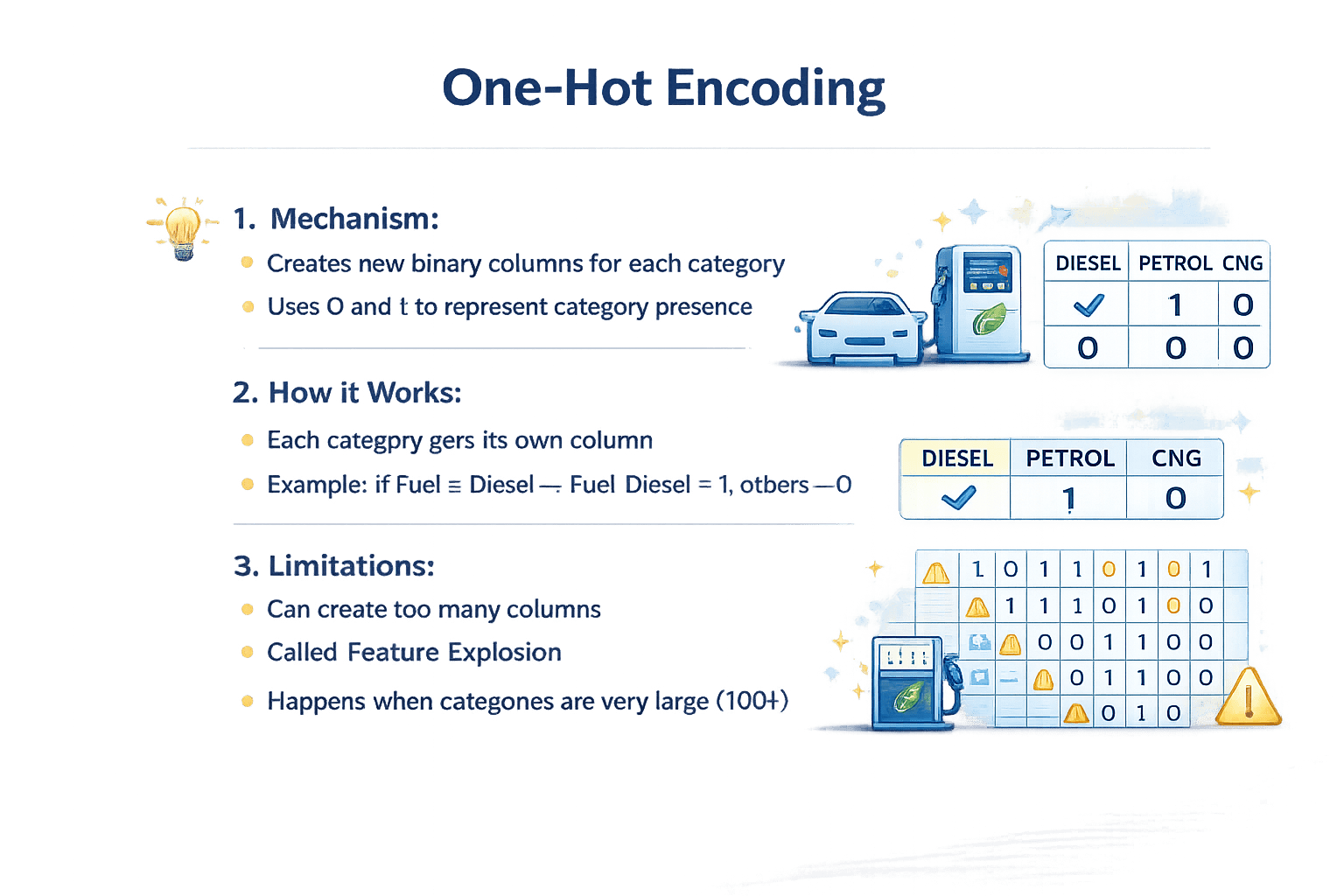
Mechanism
Creates new binary columns for each category
Uses 0 and 1 to represent category presence
Best Used For
Each category gets its own column
Example: If Fuel = Diesel → Fuel_Diesel = 1, others = 0
Limitations
Can create too many columns
Called Feature Explosion
Happens when categories are very large (100+)
The "Dummy Variable Trap"
Logic Behind It
Remaining columns already contain full information
Example: If Is_Manual = 0, it means Automatic = 1
No need to store both columns
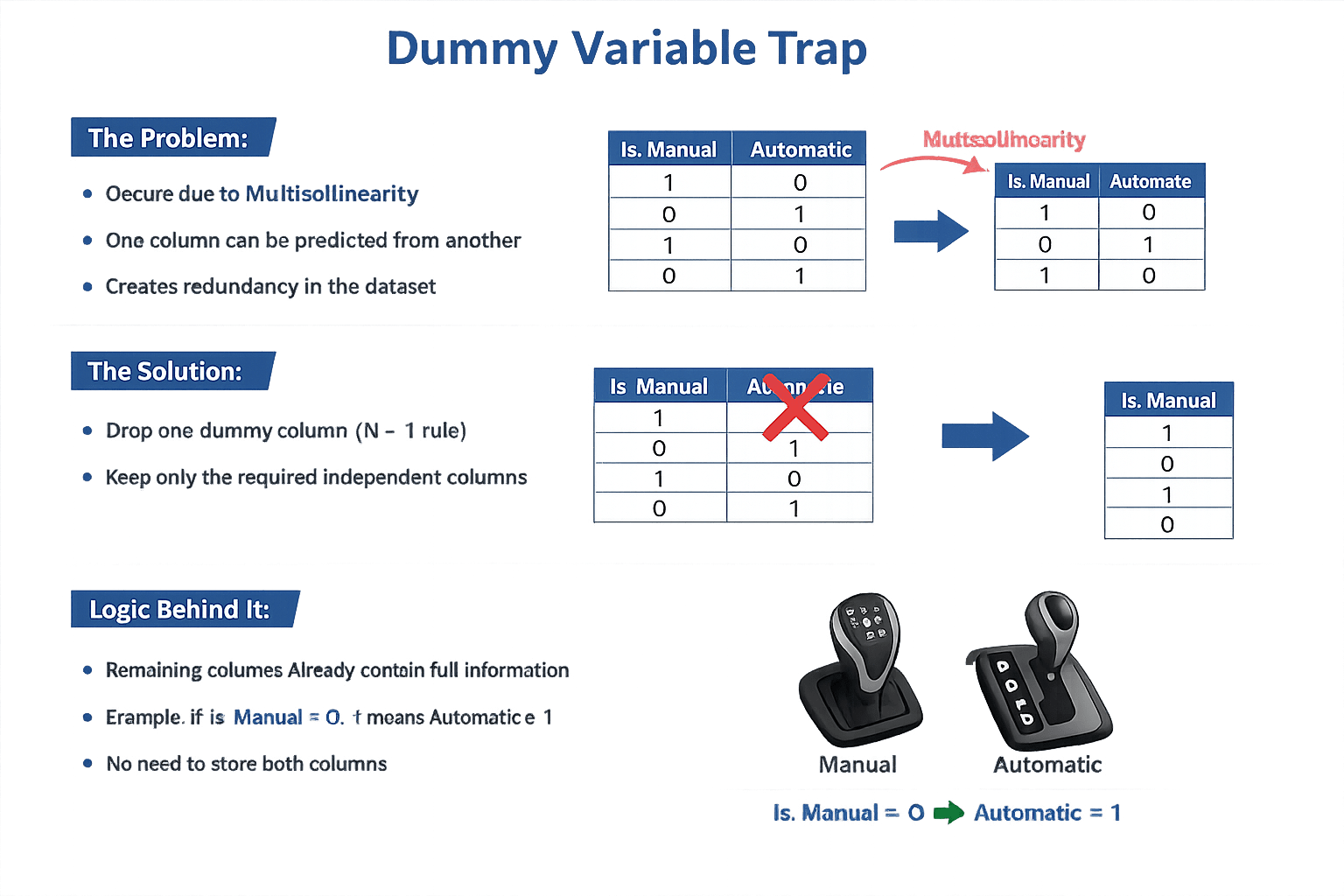
The Solution
Drop one dummy column (N − 1 rule)
Keep only the required independent columns
The Problem
Occurs due to Multicollinearity
One column can be predicted from another
Creates redundancy in the dataset
Feature Preservation
Maintains the true meaning of car categories
Ensures important information is not lost
Faster Computation
Reduces processing time
Improves efficiency for Neural Networks
Improves Accuracy
Enhances price prediction performance
Helps the model learn correct relationships
Better Training Alignment
Ensures features are properly structured
Helps the model train more effectively
Impact on Model Performance
Summary
4
Context is Key: Wrong encoding leads to biased machine "assumptions"
3
One-Hot Encoding = For Unordered Data (Make, Color)
2
Label Encoding = For Ordered Data (Safety, Size)
1
Clean $\rightarrow$ Handle Outliers $\rightarrow$ Encode
Quiz
What is the primary reason for dropping one column during One-Hot Encoding ($N-1$)?
A. To increase data size
B. To eliminate the need for cleaning
C. To prevent the Dummy Variable Trap (Multicollinearity)
D. To improve label readability

Quiz-Answer
What is the primary reason for dropping one column during One-Hot Encoding ($N-1$)?
A. To increase data size
B. To eliminate the need for cleaning
C. To prevent the Dummy Variable Trap (Multicollinearity)
D. To improve label readability
