Apply Advanced Classification Models

Business Scenario
Welcome back!
Today is your fourth day as a Junior Data Scientist on the Telecom Customer Intelligence Project.
In the previous lab, you developed and optimized a Decision Tree model. Although Logistic Regression and the Pruned Decision Tree performed well, management wants to benchmark additional classification algorithms before selecting the final deployment model.
Your task is to implement Support Vector Machine (SVM) and Naive Bayes, compare their performance, and recommend the most suitable model.

Pre-Lab Preparation
Topic : Classification Models
1) SVM
2) Naive Bayes
3) Model Evaluation Metrics (Accuracy, Precision, Recall, F1-score, Confusion Matrix, ROC-AUC)
git pull origin branchName
Git Pull
Task 1: Apply Support Vector Machine (SVM)
Management wants to evaluate whether Support Vector Machine (SVM) can better distinguish between churn and non-churn customers, providing an alternative to the existing classification models.
Support Vector Machine (SVM)

Support Vector Machine (SVM) is a supervised machine learning algorithm that identifies the optimal decision boundary (hyperplane) to separate different classes while maximizing the margin between them. It is effective for both linear and non-linear classification problems.
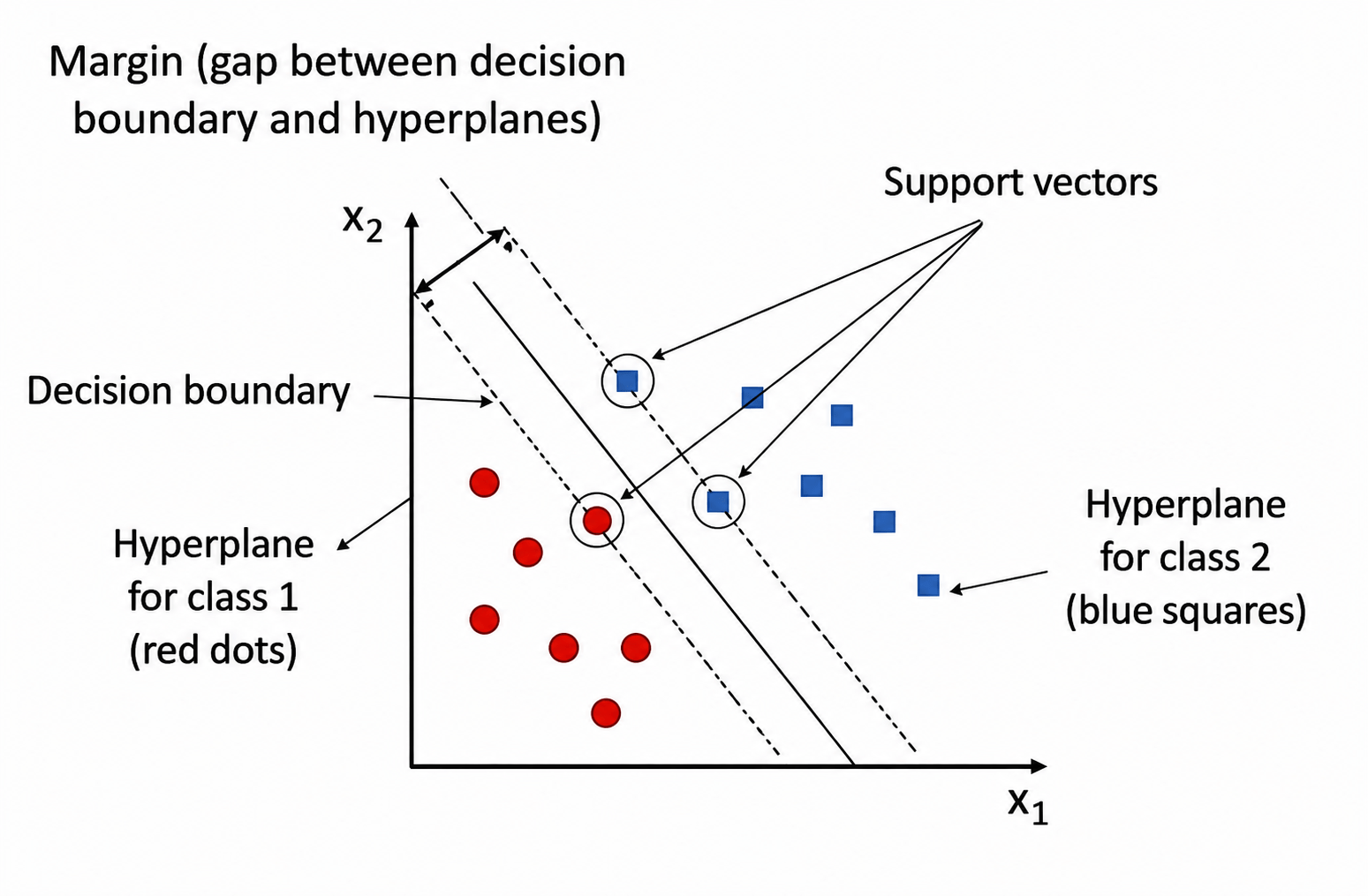
- Hyperplane: A decision boundary separating different classes in feature space and is represented by the equation wx + b = 0 in linear classification.
- Support Vectors: The closest data points to the hyperplane, crucial for determining the hyperplane and margin in SVM.
- Margin: The distance between the hyperplane and the support vectors. SVM aims to maximize this margin for better classification performance.
- Kernel: A function that maps data to a higher-dimensional space enabling SVM to handle non-linearly separable data.
- Hard Margin: A maximum-margin hyperplane that perfectly separates the data without misclassifications.
- Soft Margin: Allows some misclassifications by introducing slack variables, balancing margin maximization and misclassification penalties when data is not perfectly separable.
- C: A regularization term balancing margin maximization and misclassification penalties. A higher C value forces stricter penalty for misclassifications.
- Hinge Loss: A loss function penalizing misclassified points or margin violations and is combined with regularization in SVM.
- Dual Problem: Involves solving for Lagrange multipliers associated with support vectors, facilitating the kernel trick and efficient computation.
Click to download previous file : ML Lab 9.ipynb
Import the SVM classifier
1
from sklearn.svm import LinearSVCCreate object of linearsvc
2
svc = LinearSVC(random_state=1,C=0.09)Train the model
3
svc.fit(X_train, y_train)Make predictions
4
y_pred_svc = svc.predict(X_test)from sklearn.metrics import (accuracy_score, precision_score, recall_score,
f1_score, confusion_matrix, roc_auc_score, classification_report)
# Accuracy
print("Accuracy:", accuracy_score(y_test, y_pred_svc))
# Precision
print("Precision:", precision_score(y_test, y_pred_svc))
# Recall
print("Recall:", recall_score(y_test, y_pred_svc))
# F1-Score
print("F1-Score:", f1_score(y_test, y_pred_svc))
# Confusion Matrix
print("Confusion Matrix:\n", confusion_matrix(y_test, y_pred_svc))
# ROC-AUC Score
print("ROC-AUC Score:", roc_auc_score(y_test, y_pred_svc))
# Classification Report
print("Classification Report:\n")
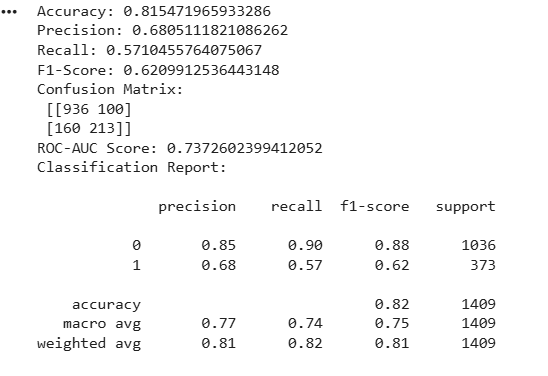
print(classification_report(y_test, y_pred_svc))Evaluate the Model
5
Create non-linear svc model
6
from sklearn.svm import SVC
poly_svc = SVC(kernel="poly", probability=True, random_state=42)Train and predict the Model
7
poly_svc.fit(X_train, y_train)
y_pred_poly_svc = poly_svc.predict(X_test)Evaluate Model Performance
8
print("Accuracy:", accuracy_score(y_test, y_pred_poly_svc))
print("Precision:", precision_score(y_test, y_pred_poly_svc))
print("Recall:", recall_score(y_test, y_pred_poly_svc))
print("F1-Score:", f1_score(y_test, y_pred_poly_svc))
print("Confusion Matrix:\n", confusion_matrix(y_test, y_pred_poly_svc))
print("ROC-AUC Score:", roc_auc_score(y_test, poly_svc.predict_proba(X_test)[:, 1]))
print("\nClassification Report:\n", classification_report(y_test, y_pred_poly_svc))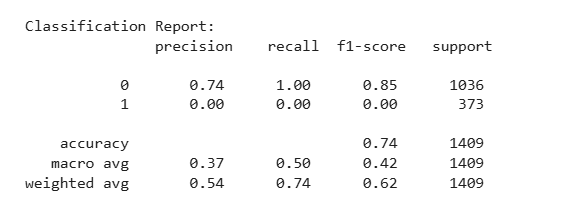
Task 2: Apply Naive Bayes
Management also wants to evaluate whether a probability-based classifier can effectively predict customer churn.
Naive Bayes
Naive Bayes is a probabilistic classification algorithm based on Bayes Theorem. It assumes that features are conditionally independent given the target class, making it simple, fast, and effective for many classification tasks.
Import the classifier
1
from sklearn.naive_bayes import GaussianNBCreate the model
2
nb_model = GaussianNB()Train and predict the model
3
nb_model.fit(X_train, y_train)
y_pred_nb = nb_model.predict(X_test)Evaluate the model
4
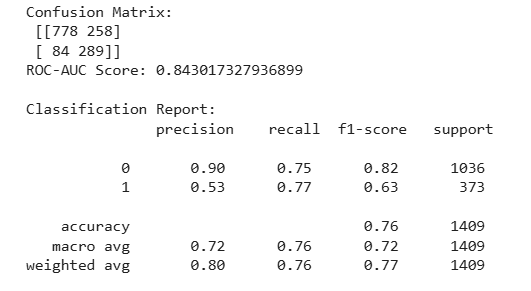
print("Accuracy:", accuracy_score(y_test, y_pred_nb))
print("Precision:", precision_score(y_test, y_pred_nb))
print("Recall:", recall_score(y_test, y_pred_nb))
print("F1-Score:", f1_score(y_test, y_pred_nb))
print("Confusion Matrix:\n", confusion_matrix(y_test, y_pred_nb))
print("ROC-AUC Score:", roc_auc_score(y_test, nb_model.predict_proba(X_test)[:, 1]))
print("\nClassification Report:\n", classification_report(y_test, y_pred_nb))
Great job!
In this lab, you learned the importance of benchmarking multiple classification algorithms before selecting a deployment model. You successfully implemented Support Vector Machine (SVM) and Naive Bayes, trained both models, and evaluated their performance using metrics such as Accuracy, Precision, Recall, F1-Score, Confusion Matrix, ROC-AUC Score, and Classification Report.
You are now ready to explore Validate and Tune Models Using Cross-Validation in the next lab.
Checkpoint
Git Push
git push origin branchNameNext-Lab Preparation
Topic : Model Optimization
1) Cross-Validation Techniques
2) Hyperparameter Tuning (GridSearchCV, RandomizedSearchCV)
3) Bias-Variance Tradeoff