Validate and Tune Models Using Cross-Validation

Business Scenario
Welcome back!
Today it's another day of you as a Junior Data Scientist at HealthVision Analytics.
The company has developed a machine learning model to classify breast cancer cases. Before deployment, management wants the model validated and optimized to ensure reliable performance.
Your task is to perform Cross Validation and Hyperparameter Tuning using GridSearchCV and RandomizedSearchCV to evaluate the model and identify the best configuration for deployment.

Pre-Lab Preparation
Topic : Model Optimization
1) Cross-Validation Techniques
2) Hyperparameter Tuning (GridSearchCV, RandomizedSearchCV)
3) Bias-Variance Tradeoff
git pull origin branchNameTask 1: Validate Model Performance Using Cross Validation

Git Pull
Before deploying the disease classification model, management wants proof that it performs reliably on different patient datasets, not just the training data. This can be shown by testing the model on multiple data samples (e.g., using cross-validation or independent test sets) and verifying that performance metrics such as accuracy, precision, and recall remain consistent.
This ensures the model generalizes well and can be trusted in real-world clinical use.

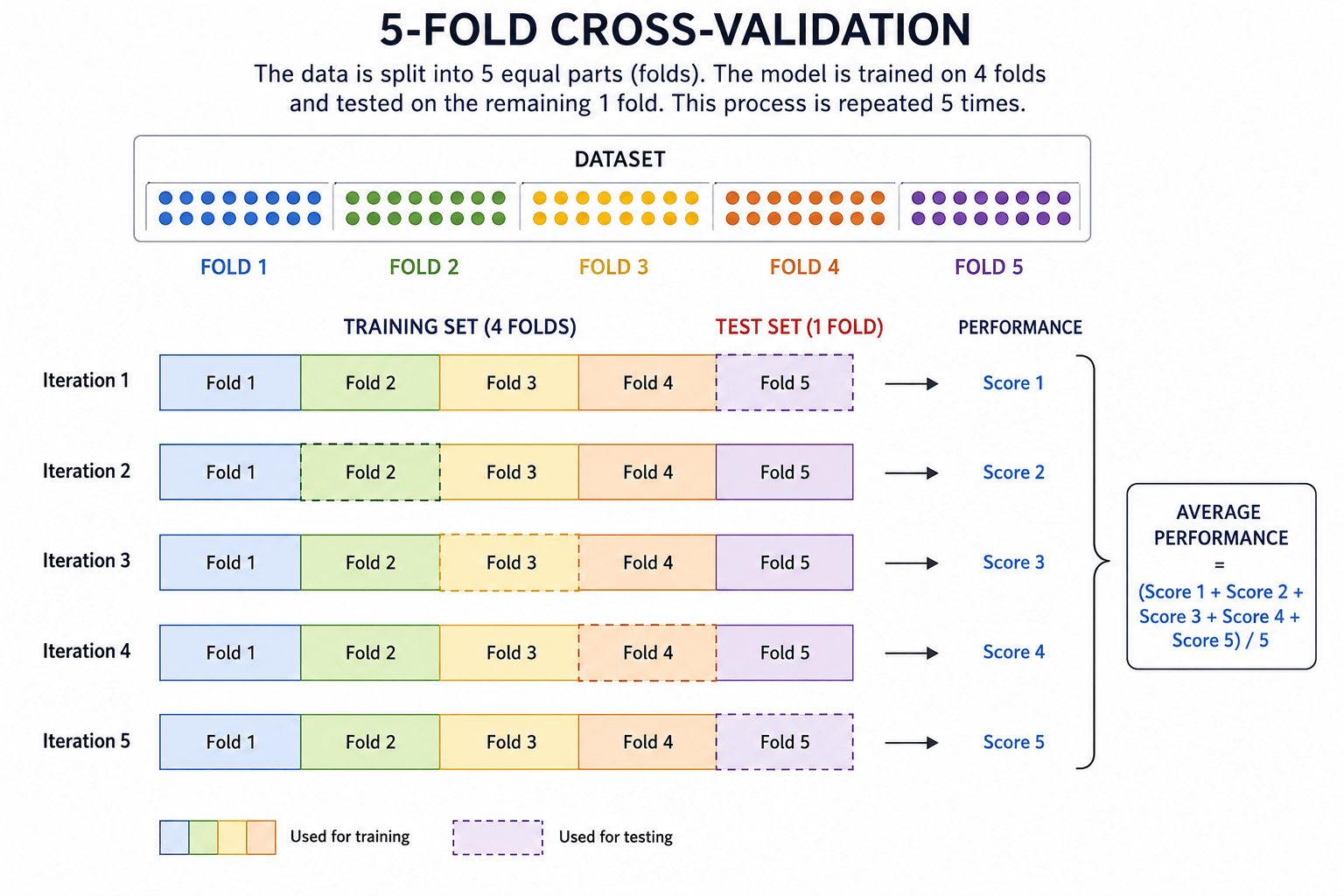
Cross-validation
Cross-validation is a model validation technique that evaluates a model by repeatedly training and testing it on different subsets (folds) of the data.
The performance scores from each run are then averaged to provide a more reliable estimate of how well the model will perform on unseen data.
Import the required libraries
1
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifierload_breast_cancer: Loads a built-in breast cancer dataset.cross_val_score: Performs cross-validation and returns evaluation scores.RandomForestClassifier: A machine learning classification algorithm based on multiple decision trees.
Load the dataset
2
data = load_breast_cancer()This loads the breast cancer dataset into the variable data.
The dataset contains:
- Features (measurements of cell nuclei)
- Target labels (malignant or benign cancer)
Separate features and target
3
X = data.data
y = data.targetCreate the Random Forest model
4
model = RandomForestClassifier(random_state=42)This creates a Random Forest classifier.
- A Random Forest builds many decision trees.
- Each tree makes a prediction.
- The final prediction is based on majority voting.
random_state=42 ensures the results are reproducible every time you run the code.
Perform 5-fold cross-validation
5
scores = cross_val_score(model, X, y, cv=5)Print individual cross-validation scores and average accuracy
6
print("Cross Validation Scores:", scores)
print("Average Accuracy:", scores.mean())
Task 2: Tune GridSearchCV
Management aims to determine the most effective Random Forest configuration to achieve the highest possible classification accuracy. This involves testing different hyperparameter settings and comparing their performance to identify the model that provides the most reliable and accurate predictions, ultimately supporting better data-driven decision-making.
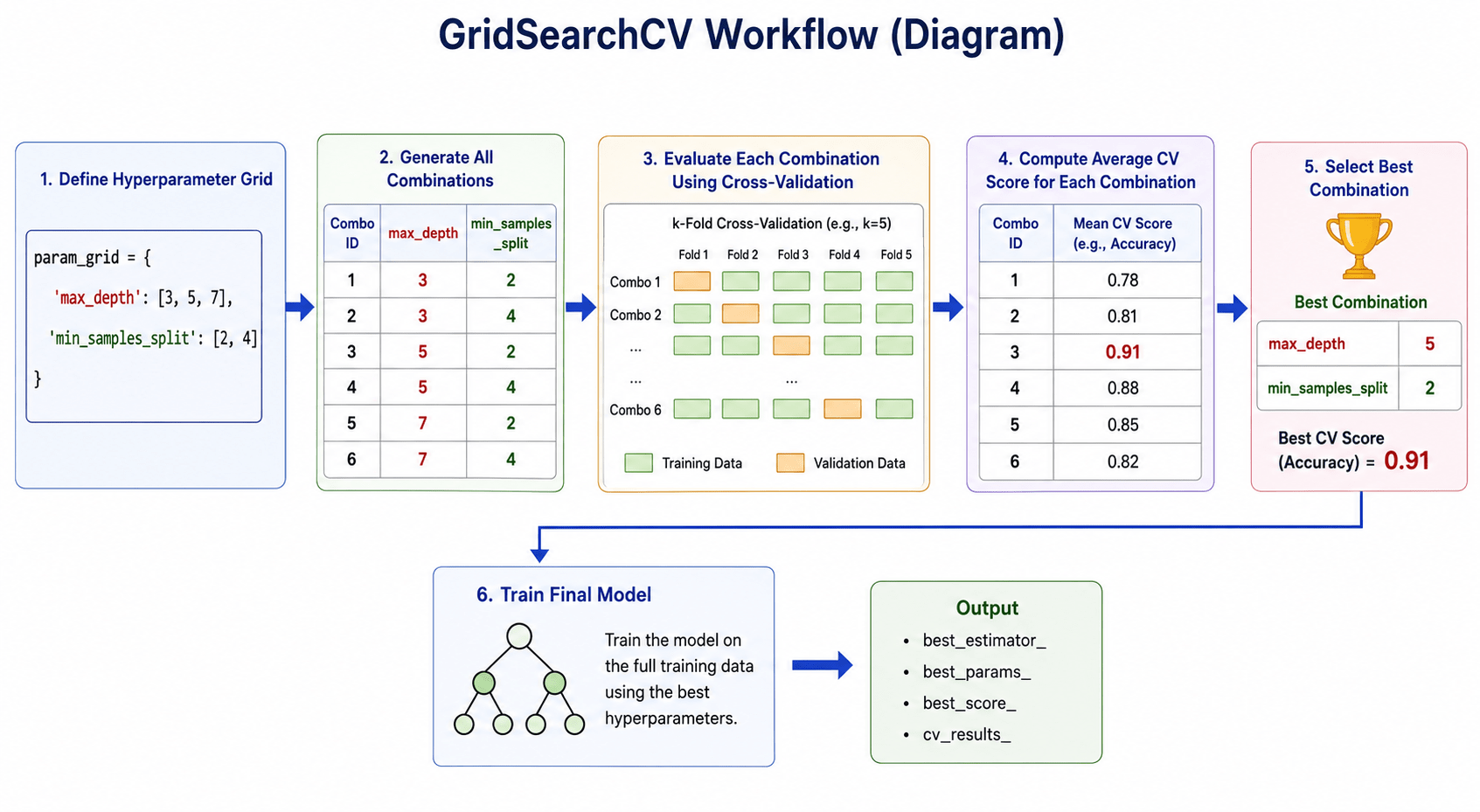
GridSearchCV is a hyperparameter tuning technique that tests every possible combination of specified parameter values using cross-validation and selects the combination that gives the best model performance.
GridSearchCV
Import the required classes
1
- RandomForestClassifier: Creates a Random Forest model for classification tasks.
- GridSearchCV: Automatically tests multiple combinations of hyperparameters and finds the best-performing one using cross-validation.
Think of GridSearchCV as an automated trial-and-error process for model tuning.
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import RandomForestClassifierCreate a Random Forest model
2
rf = RandomForestClassifier(random_state=42)Define the hyperparameter search space
3
param_grid = {
'n_estimators': [100, 200, 300],
'max_depth': [10, 20, None],
'min_samples_split': [2, 5],
'min_samples_leaf': [1, 2]
}n_estimators: [100, 200, 300] – Number of trees in the forest. More trees usually improve stability but increase training time.max_depth: [10, 20, None] – Maximum tree depth. Deeper trees capture more complex patterns but may overfit.min_samples_split: [2, 5] – Minimum samples required to split a node. Higher values help reduce overfitting.min_samples_leaf: [1, 2] – Minimum samples required in a leaf node. Larger values create more conservative trees.
GridSearchCV tests all combinations of these values to find the best-performing model.
Create the Grid Search object
4
grid_search = GridSearchCV(
estimator=rf,
param_grid=param_grid,
cv=5,
scoring='accuracy'
)estimator=rf– Uses the Random Forest model for tuning.param_grid=param_grid– Tests all combinations of the specified hyperparameter values.cv=5– Performs 5-fold cross-validation, training on 4 folds and testing on 1 fold each time for a more reliable evaluation.scoring='accuracy'– Evaluates models using accuracy, and selects the combination with the highest average accuracy.
Train and search for the best parameters
5
grid_search.fit(X, y)Display the best hyperparameters
6
print("Best Parameters:", grid_search.best_params_)
Display the best accuracy
7
print("Best Accuracy:", grid_search.best_score_)
Task 3: Tune Model Using RandomizedSearchCV
Management is looking for a more efficient hyperparameter tuning strategy that can explore a much larger set of parameter combinations without requiring a proportional increase in computational resources. The goal is to identify high-performing model configurations more quickly by reducing the number of unnecessary training runs, thereby lowering overall computation time and cost while maintaining or improving model performance.
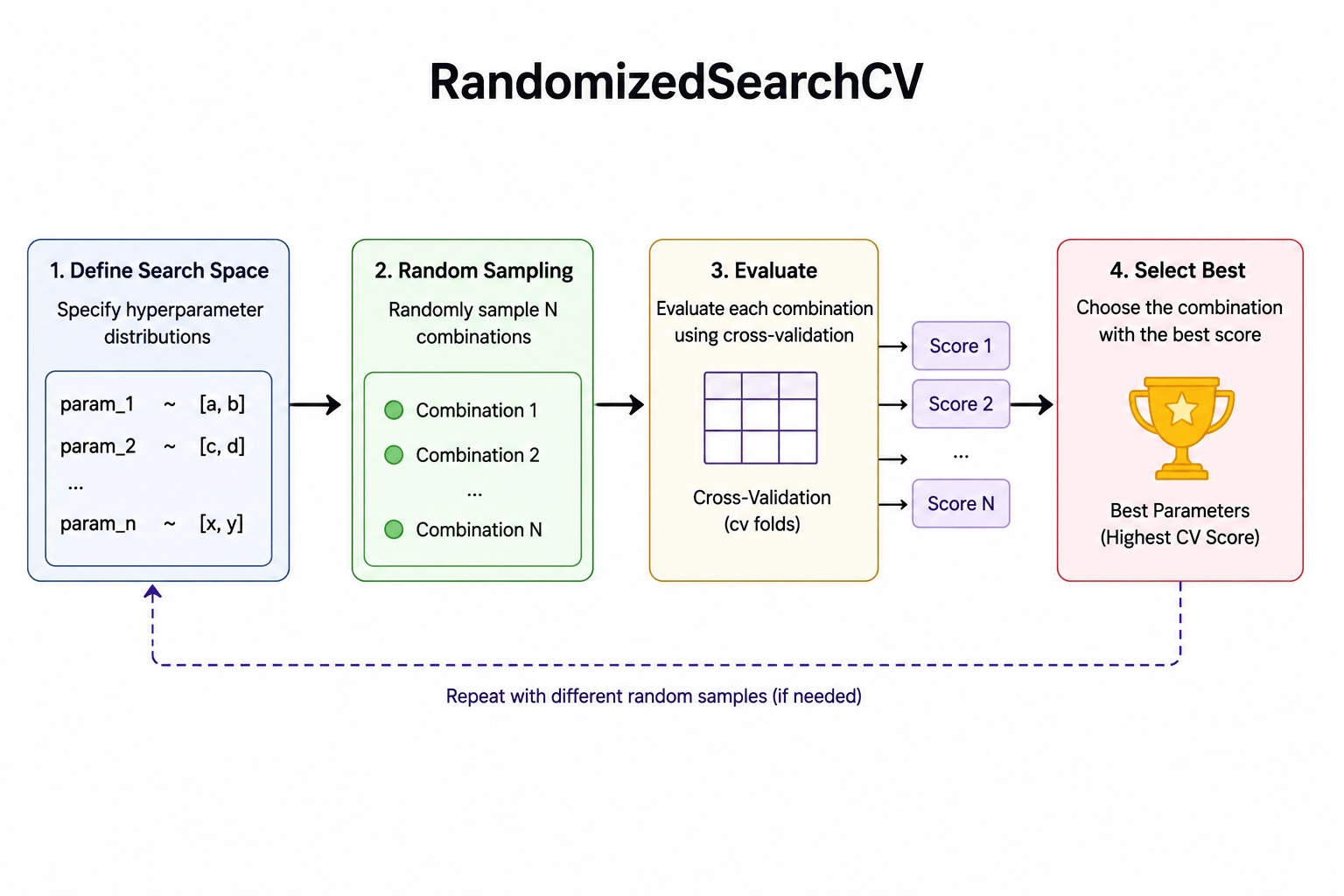
RandomizedSearchCV randomly tests a selected number of hyperparameter combinations instead of trying every possible combination, helping find good-performing settings faster and with lower computational cost.
RandomizedSearchCV
Import RandomizedSearchCV
1
from sklearn.model_selection import RandomizedSearchCVDefine Hyperparameter Search Space
2
param_dist = {
'n_estimators': [50, 100, 200, 300],
'max_depth': [5, 10, 15, 20, None],
'min_samples_split': [2, 5, 10],
'min_samples_leaf': [1, 2, 4]
}Create RandomizedSearchCV Object
3
random_search = RandomizedSearchCV(
estimator=rf,
param_distributions=param_dist,
n_iter=10,
cv=5,
scoring='accuracy',
random_state=42
)Train and Search
4
random_search.fit(X, y)Find Best Parameters and average accuracy
5
print("Best Parameters:", random_search.best_params_)
print("Best Accuracy:", random_search.best_score_)
Great job!
You have successfully completed the lab on Validate and Tune Models Using Cross-Validation. In this lab, you applied Cross Validation to assess model reliability, used GridSearchCV and RandomizedSearchCV to optimize hyperparameters, tuned a Random Forest model, identified the best-performing hyperparameter configuration, and recommended a deployment-ready model based on the evaluation results.
You are now ready to explore advanced ensemble learning techniques and further improve model performance.
Checkpoint
Next-Lab Preparation
Git Push
git push origin branchNameTopic : Ensemble Learning
1) Bagging(Random Forest)