Sentiment Analysis on Amazon Reviews- Natural Language Processing

Embedding Layer in Natural Language Processing


Learning Outcome
5
Implement an Embedding layer using Keras
4
Differentiate between Random and Pre-trained embeddings
3
Describe how embedding lookup works
2
Explain why embeddings are preferred over one-hot encoding
1
Understand what an Embedding Layer is in NLP
Before this topic, we already learned:
After tokenization, how does a model understand meaning?

- Introduction to NLP
- Text preprocessing
- Tokenization
- Converting words into numbers

Imagine two ways to describe a person:

One-hot = Only their name in attendance register
Embedding = Full biography (interests, profession, behavior)
Just knowing a word’s position in vocabulary is not enough.
We want its story and relationships
In NLP, models cannot understand text directly...
This is called an Embedding Layer
Let's understand it in detail....
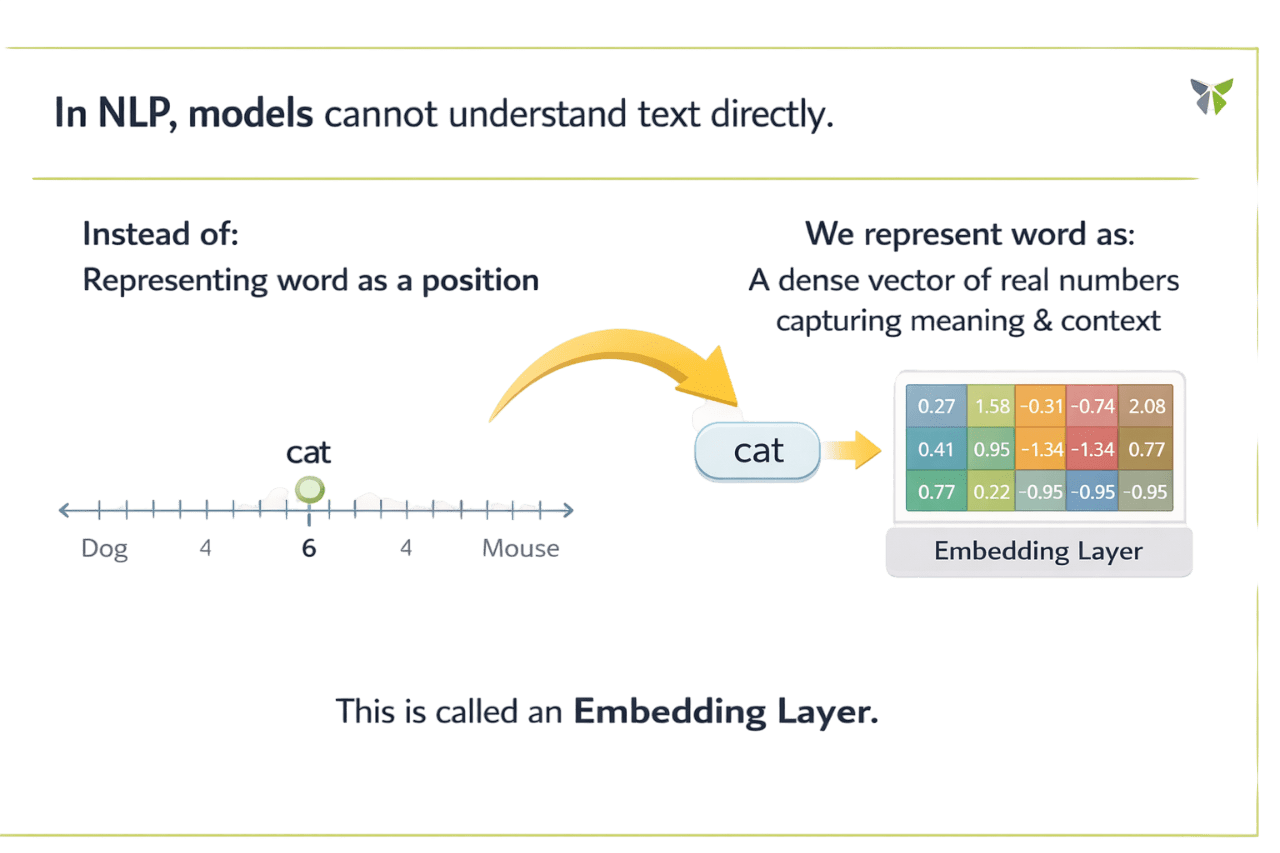
Instead:
Representing word as a position
We represent word as:
A dense vector of real numbers capturing meaning & context
Core Concepts (Slide 6)
Core Concepts (Slide 7)
Core Concepts (.....Slide N-3)
Summary
5
Widely used in NLP models
4
Can be random or pre-trained
3
More efficient than one-hot encoding
2
Captures semantic meaning & relationships
1
Embedding Layer converts words into dense vectors
Quiz
Which statement best explains why embeddings are preferred over one-hot encoding?
A) They increase vocabulary size
B) They create sparse vectors
C) They capture semantic meaning in dense vectors
D) They remove need for tokenization

Quiz-Answer
Which statement best explains why embeddings are preferred over one-hot encoding?
A) They increase vocabulary size
B) They create sparse vectors
C) They capture semantic meaning in dense vectors
D) They remove need for tokenization
