Voice Recognition with MXNet

Cosmin Catalin Sanda
th
11 December 2018

ABOUT ME
Cosmin Catalin Sanda
Data Scientist and Engineer at AudienceProject
Blogging at https://cosminsanda.com

What is Voice Recognition?
The ability to identify a speaker based on the sound of their voice


- VERIFICATION: is the user who he claims he is.
- IDENTIFICATION: recognize the user.
The problem at hand

- Polly is a text-to-speech service from AWS
- It features 8 voices for its English variant
Who of was used for a given recording ?
Salli
Kimberly
Kendra
Joanna
Ivy
Matthew
Justin
Joey
client = boto3.client("polly")
voices = ["Ivy", "Joanna", "Joey", "Justin",
"Kendra", "Kimberly", "Matthew", "Salli"]
response = client.synthesize_speech(
OutputFormat="mp3",
Text="Polly wants a cracker",
TextType="text",
VoiceId=random.choice(voices)
)
with open("out.mp3", "wb") as out:
with closing(response["AudioStream"]) as stream:
out.write(stream.read())Simplifying the problem


text
text-to-speech
sound
sound
image
image


Joanna




Joanna
Joanna
Kimberly
Kimberly
Kimberly
CONVOLUTIONAL NEURAL NETWORKS
| 34 | 13 | 54 | 45 | 45 | 34 |
| 34 | 34 | 34 | 54 | 43 | 34 |
| 34 | 56 | 34 | 54 | 45 | 23 |
| 34 | 43 | 34 | 44 | 45 | 56 |
| 34 | 54 | 45 | 46 | 34 | 6 |
| 34 | 54 | 56 | 65 | 56 | 56 |
| 20 | 13 | 54 | 45 | 45 | 34 |
| 34 | 34 | 34 | 54 | 43 | 34 |
| 34 | 56 | 34 | 54 | 45 | 23 |
| 34 | 43 | 34 | 44 | 45 | 56 |
| 34 | 54 | 45 | 46 | 34 | 6 |
| 34 | 54 | 56 | 65 | 56 | 56 |
| 20 | 13 | 54 | 45 | 45 | 34 |
| 34 | 34 | 34 | 54 | 43 | 34 |
| 34 | 56 | 34 | 54 | 45 | 23 |
| 34 | 43 | 34 | 44 | 45 | 56 |
| 34 | 54 | 45 | 46 | 34 | 6 |
| 34 | 54 | 56 | 65 | 56 | 56 |
| 34 | 13 | 54 |
| 34 | 34 | 34 |
| 34 | 56 | 34 |
| 34 | 13 | 54 |
| 34 | 34 | 34 |
| 34 | 56 | 34 |
| 34 | 13 | 54 |
| 34 | 34 | 34 |
| 34 | 56 | 34 |
Original
image
Numerical
representation
Filtered
output
simplification
INFRASTRUCTURE

Data PROcessing
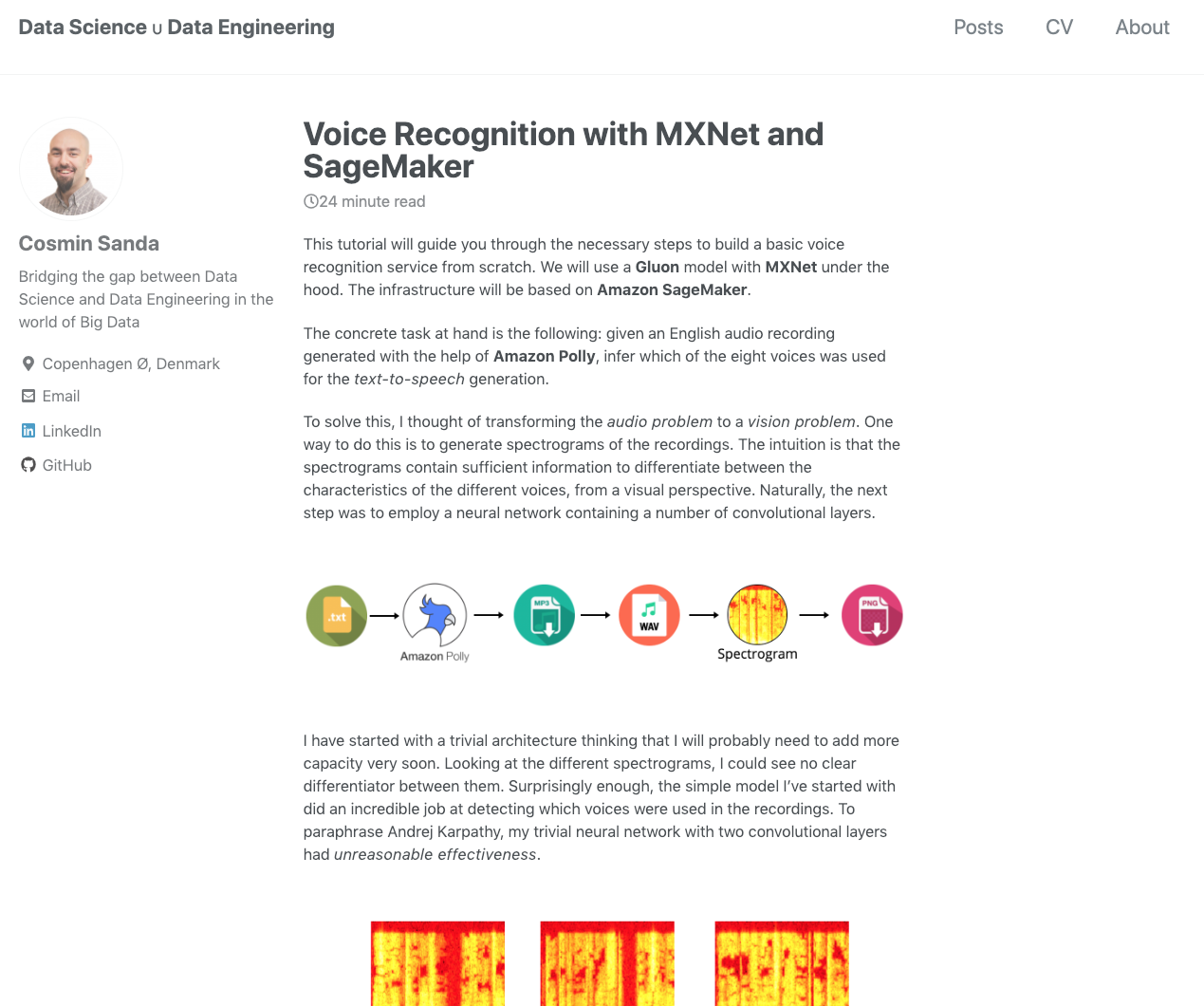
"Quickly" going through the data processing steps, we have the following:
- Download a list of short sentences from a publicly available dataset.
- Use Amazon Polly to get the spoken versions of the sentences in mp3 format.
- Convert the mp3 to wav files.
- Use a window interval of about 3 seconds from each file to generate the spectrogram.
- Convert the spectrogram image to a numerical representation.
- Make sure there are three stratified datasets: training/validation and test.
- Store the training and validation numerical arrays in Python pickles.
- Upload pickles to S3.
- Set the test data aside.
Model
from mxnet.gluon.nn import MaxPool2D, Sequential
from mxnet.gluon.nn import Conv2D, Dense, Dropout
net = Sequential()
with net.name_scope():
net.add(Conv2D(channels=32, kernel_size=(3, 3),
padding=0, activation="relu"))
net.add(Conv2D(channels=32, kernel_size=(3, 3),
padding=0, activation="relu"))
net.add(MaxPool2D(pool_size=(2, 2)))
net.add(Dropout(.25))
net.add(Dense(8))Number of filters. Used to balance
between under/over fitting
Dimension of the convolution window
Rectified Linear Unit (y=max(x,0))
Reduces the spatial size of the input and contributes to reducing overfitting and computation
Regularization layer. A percentage of neurons
do not get activated

NETWORK PARAMETERS INITIALIZATION
import mxnet as mx
from mxnet.initializer import Xavier # [Bengio and Glorot 2010]
ctx = mx.gpu()
net.collect_params().initialize(Xavier(magnitude=2.24), ctx=ctx)LOSS FUNCTION
from mxnet.gluon.loss import SoftmaxCrossEntropyLoss
loss = SoftmaxCrossEntropyLoss()from mxnet.gluon import Trainer
trainer = Trainer(net.collect_params(), optimizer="adam")Optimizer
Relies on predicted probabilities to compute a score in classification problems
A SGD flavoured optimizer
TRAining with AUTOGRAD
epochs= 5
for e in range(epochs):
for i, (data, label) in enumerate(train_data):
data = data.as_in_context(ctx)
label = label.as_in_context(ctx)
with autograd.record():
output = net(data)
loss_result = loss(output, label)
loss_result.backward()
trainer.step(batch_size)How many times I go through
the whole training data
(batch_size, channels, height, width) NDArray
Forward pass
Update weights
PERFORMANCE MEASURMENT
epochs = 5
for e in range(epochs):
moving_loss = 0
for i, (data, label) in enumerate(train_data):
data = data.as_in_context(ctx)
label = label.as_in_context(ctx)
with autograd.record():
output = net(data)
loss_result = loss(output, label)
loss_result.backward()
trainer.step(batch_size)
validation_acc = measure_performance(net, ctx, validation_data)
train_acc = measure_performance(net, ctx, train_data)
print("Epoch {}. Train_acc {}, Test_acc {}" \
.format(e, train_acc, validation_acc))def measure_performance(model, ctx, data_iter):
acc = mx.metric.Accuracy()
for _, (data, labels) in enumerate(data_iter):
data = data.as_in_context(ctx)
labels = labels.as_in_context(ctx)
output = model(data)
predictions = nd.argmax(output, axis=1)
acc.update(preds=predictions, labels=labels)
return acc.get()[1]Epoch 0. Loss: 1.19020674213, Train_acc 0.927615951994, Test_acc 0.924924924925
Epoch 1. Loss: 0.0955917794597, Train_acc 0.910488811101, Test_acc 0.904904904905
Epoch 2. Loss: 0.0780380586131, Train_acc 0.982872859107, Test_acc 0.967967967968
Epoch 3. Loss: 0.0515212092374, Train_acc 0.987123390424, Test_acc 0.95995995996
Epoch 4. Loss: 0.0513322874282, Train_acc 0.995874484311, Test_acc 0.978978978979
===== Job Complete =====
Billable seconds: 337