文字分類任務-111微課程之二
This is a live streamed presentation. You will automatically follow the presenter and see the slide they're currently on.
This is a live streamed presentation. You will automatically follow the presenter and see the slide they're currently on.
Deep Learning for Text Analysis
王柳鋐
Last Updated: 2022/11/25
Text Analysis
"我和順仔早上5點登上「福建號」"
我和<person>順仔</person>早上5點登上「<ship>福建號</ship>」
斷詞(tagger)
(命名)實體辨識
name-entity-recognition
原文
我 和 順仔 早上 5點 登上 福建號
r c nr t t v nr
詞性標記
part-of-speech
專業術語 + 分類
應用:索引、Hyperlink
資料來源:DocuSky 數位人文學術研究平臺:視覺化與統計分析,2020數位人文培訓營
統計單元:斷詞(實體辨識)的結果
BERT
Bidirectional Encoder Representations from Transformers
拜訪 我 普林斯 頓 神學院 的 老同 學麥克 切斯 尼 先生 和 幾位 宣教 師 。 晚上 介紹 加拿大 , 哈巴 安德 醫師 翻譯
斷詞
困難: 斷詞錯誤 雜訊
"拜訪我普林斯頓(Princeton)神學院的老同學麥克切斯尼(McChesney)先生和幾位宣教師。晚上介紹加拿大,哈巴安德醫師翻譯。"
自訂辭典
停用字列表
普林斯頓
老同學
麥克切斯尼先生
哈巴安德醫師
宣教師
我
的
和
晚上
幾位
拜訪 普林斯頓 神學院 老同學 麥克切斯尼先生 宣教師 。 介紹 加拿大 , 哈巴安德醫師 翻譯
困難: 錯別字、同義詞(不同稱呼/不同翻譯)
拜訪南勢番(南方的原住民),在包干、李流(Li-lau),薄薄、斗蘭(Tau-lan)和七腳川拍了一些照片。
台灣堡圖
1904
我們拜訪流流、薄薄、里腦,又回到大社
問題:究竟是里腦,李流還是流流?
不同翻譯
回到五股坑,蔥仔在前往領事館費里德(A.Frater)先生那裡後和我們一起。
和偕師母及閏虔益一起到五股坑,然後去洲裡,在晚上回來。
同義詞
專家
修正與建議
里漏社
自訂辭典
停用字列表
by Deep Learning
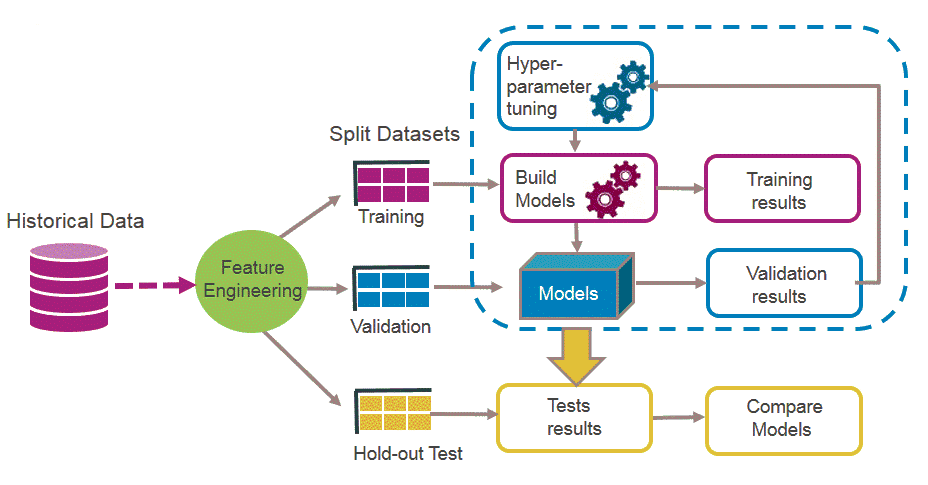
訓練資料
❶¹ 前處理
🅐 訓練集
🅑 驗證集
🅒 測試集
❷ 訓練參數
➎ 決定最終預測模型
❸ 產生預測用模型
➍ 測試模型
特徵萃取
❶² 資料集分割
情感分析(Sentiment Analysis)
負面評價Negative
這家店的售後服務完全不行
餐點還不錯啦,但是還有改進空間
中性評價neutral
中性評價neutral
正面評價positive
很讚喔,超喜歡你們家的產品
分類問題
情感分析
編碼
輸入層
隱藏層
輸出層
輸出結果分類
真實
政治宣傳
惡搞
反諷
假新聞
帶風向
片面資訊
新聞分類
分類問題
機器翻譯
迴歸問題
Transformer
輸入英文: milk drink I
輸出法文: Je bois du lait <eos>
編碼器
解碼器
編碼器輸出
解碼器輸入
<sos>: 開始符號
<eos>: 結束符號
文本生成
輸入: 一句話
輸出: 一篇短文!
經過多個語言模型...
迴歸問題
96個Transformer解碼器
句子 ➠ 預測下一個字
Deep Learning 訓練參數量不斷增加
GPT-3: 175,000(175B)
MT-NLG: 530,000M(530B)
GLaM: 1,200,000M(1.2T)
17B
1. 訓練資料很難取得
遷移學習(transfer learning): 研究者可以專注於目標領域資料集
機器學習傳統做法
資料集1
資料集2
資料集3
任務1
任務2
任務3
Transfer Learning
來源領域任務
資料集S
來源領域知識
目標領域任務
大量
資料集T
小量
預訓練
兩階段
2. 需進行編碼:
訓練模型擅長直接處理數值資料
[編碼方法1] One-hot encoding: 一字一編號
<SOS> I played the piano
1
2
3
4
5
6
7
8
編碼
輸入層
隱藏層
輸出層
以向量表示
編號
詞彙
<SOS>
編號
0 0 0 0 0 0 0 0
One-hot encoding問題: 詞彙很多(資料稀疏)、編碼與語意無關...
dog
文本分析的詞彙很多
字詞編碼:向量很長、資料稀疏
向量長度 =詞彙數量(10000)
one-hot encoding
One-hot encoding問題: 詞彙很多(資料稀疏)、編碼與語意無關...
one-hot encoding
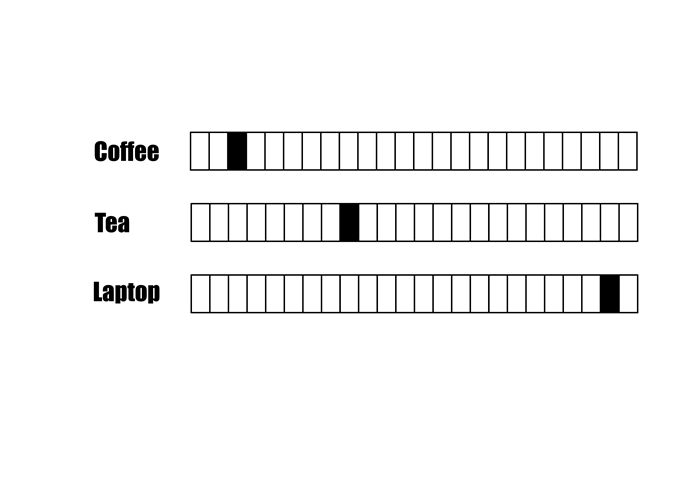
字彙語意相近,不一定有比較近的「距離」
近?
遠?
Coffee跟Laptop的距離比Tea近?
[編碼方法2]: Word Embedding(詞嵌入)
字彙語意相近,編碼必須給予比較近的「距離」
[編碼方法2]: 常見的Word Embedding方法—Word2Vec
Word2Vec學習大量詞彙,將字詞對應到100-300維度的空間
100-300
Word Embedding
Word Embedding
詞彙
7D to 2D
7D to 2D
維度
Word2Vec
Word Embedding就是編碼問題的解答嗎?
千金散盡還復來
令千金最近好嗎?
他向來一諾千金,說到做到
同樣的詞 會有相同的 詞嵌入
But...
同樣的詞,不同前後文,經常有不同意涵
脈絡(Context)的影響
輸入:Anthony Hopkins admired Michaeal Bay as a great director.
RNN循環神經網路
詞嵌入
詞嵌入
詞嵌入
詞嵌入
詞嵌入
詞嵌入
依序
↓
Transformer
平行
↑
平行
↑
平行
↑
詞嵌入
詞嵌入
詞嵌入
詞嵌入
詞嵌入
詞嵌入
詞嵌入
詞嵌入
詞嵌入
特點1. Transformers架構可採用平行計算
Vaswani et al., Attention is All You Need https://arxiv.org/abs/1706.03762
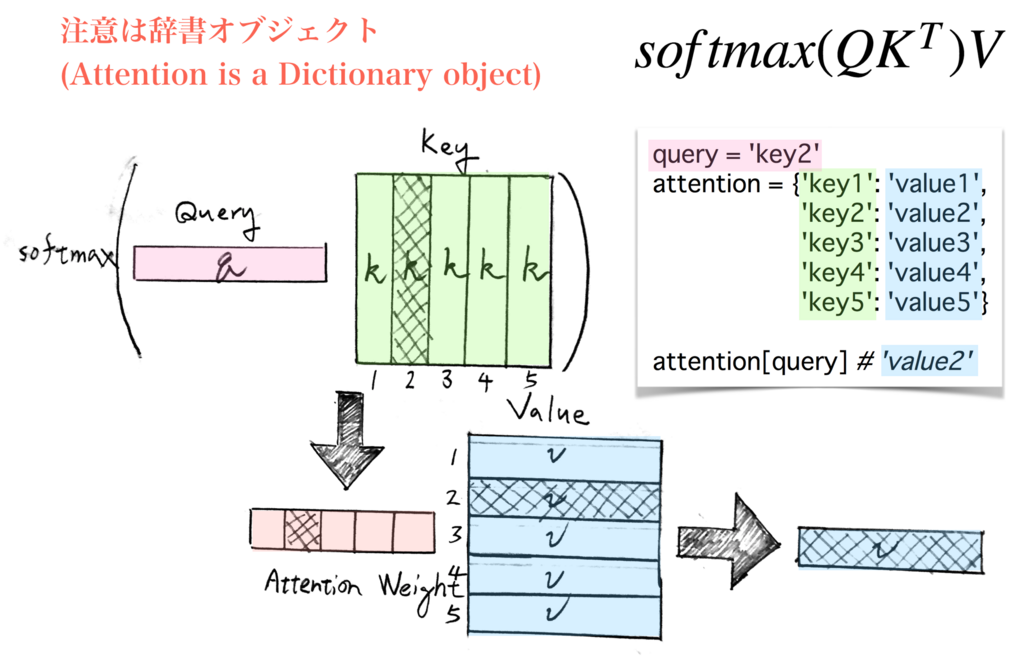
自注意(self-attention)機制
Encoder
Decoder
Attention Layer
Attention Layer
Attention Layer
Key
Query
Value
Key
Query
Value
輸入
答案
Key
Query
Value
Bidirectional Encoder Representations from Transformers
使用方法ㄧ: 透過HuggingFace Transformers
圖片來源:Transformers, PyTorch, TensorFlow
pip install -U transformers❶ 安裝transformers套件
❷ 安裝深度學習套件(擇一)
pip install -U torchpip install -U tensorflow* 後續以PyTorch為例
from ckip_transformers.nlp import CkipWordSegmenter, CkipPosTagger, CkipNerChunker
## 將斷詞結果words與 part-of-speech結果pos打包在一起
def pack_ws_pos_sentece(words, pos):
assert len(words) == len(pos), f'words{len(words)}和pos{len(pos)}長度必須一樣'
result = [] # 最終結果串列
for word, p in zip(words, pos): # zip將words,pos對應位置鏈在一起
result.append(f"{word}({p})")
return "\u3000".join(result) #\u3000是全形空白字元
# Input text
text = [
"華氏80度,氣壓30-6,整天下雨。前進到奇武荖,聆聽朗誦。然後珍珠里簡和冬瓜山,晚間在珍珠里簡的禮拜有一百五十人,拔了七十六顆牙。",
"相當涼爽舒適,與阿華出去鄉間拜訪他的一位老朋友,是一位農人。我們被看見,認出來,且受排斥。遭到兩隻大黑狗攻擊,孩童吼叫,狂暴的辱罵。 我們回家,在吃過飯之後,我們比過去更勤奮的研讀各自的功課。",
"華氏84度,陰天,氣壓30-10。上午七點離開大里簡,大部分都用走的,上午時點三十分來到頭城,拔了一些牙。十一點到打馬煙,我們剛到雨就來了。禮德醫師在路上幫一個傢伙縫手指。新漆好的禮拜堂到處都是用藍色和紅色漆,全部由他們自費花了十二元。禮德醫師拍團體照。我們照顧了十四名病人,還拔了一些牙。主持聖餐禮,聆聽十七個人背誦。大家都做得很好,我們發禮物給他們。"
]
ws_driver = CkipWordSegmenter(model="bert-base") # 載入 斷詞模型
pos_driver = CkipPosTagger(model="bert-base") # 載入 POS模型
ner_driver = CkipNerChunker(model="bert-base") # 載入 實體辨識模型
print('all loaded...')
# 執行pipeline 產生結果
ws = ws_driver(text) # 斷詞
pos = pos_driver(ws) # 詞性: 注意斷詞-詞性是依序完成
ner = ner_driver(text) # 實體辨識
##列印結果
for sentence, word, p, n in zip(text, ws, pos, ner):
print(sentence)
print(pack_ws_pos_sentece(word, p))
for token in n:
print(f"({token.idx[0]}, {token.idx[1]}, '{token.ner}', '{token.word}')")
print()華氏80度,氣壓30-6,整天下雨。前進到奇武荖,聆聽朗誦。然後珍珠里簡和冬瓜山,晚間在珍珠里簡的禮拜有一百五十人,拔了七十六顆牙。
華氏(Na) 80(Neu) 度(Nf) ,(COMMACATEGORY) 氣壓(Na) 30-6(Neu) ,(COMMACATEGORY) 整(Neqa) 天(Nf) 下雨(VA) 。(PERIODCATEGORY) 前進(VA) 到(P) 奇武荖(Nc) ,(COMMACATEGORY) 聆聽(VC) 朗誦(VC) 。(PERIODCATEGORY) 然後(D) 珍珠里簡(Na) 和(Caa) 冬瓜山(Nc) ,(COMMACATEGORY) 晚間(Nd) 在(P) 珍珠里簡(Nc) 的(DE) 禮拜(Na) 有(V_2) 一百五十(Neu) 人(Na) ,(COMMACATEGORY) 拔(VC) 了(Di) 七十六(Neu) 顆(Nf) 牙(Na) 。(PERIODCATEGORY)
(0, 5, 'QUANTITY', '華氏80度')
(8, 12, 'QUANTITY', '30-6')
(37, 40, 'LOC', '冬瓜山')
(41, 43, 'TIME', '晚間')
(52, 56, 'CARDINAL', '一百五十')
(60, 63, 'CARDINAL', '七十六')
實體辨識
11類專有名詞
7類數量詞
Part-of-Speech(POS)
61種詞性
華氏80度,氣壓30-6,整天下雨。前進到奇武荖,聆聽朗誦。然後珍珠里簡和冬瓜山,晚間在珍珠里簡的禮拜有一百五十人,拔了七十六顆牙。
華氏(Na) 80(Neu) 度(Nf) ,(COMMACATEGORY) 氣壓(Na) 30-6(Neu) ,(COMMACATEGORY) 整(Neqa) 天(Nf) 下雨(VA) 。(PERIODCATEGORY) 前進(VA) 到(P) 奇武荖(Nc) ,(COMMACATEGORY) 聆聽(VC) 朗誦(VC) 。(PERIODCATEGORY) 然後(D) 珍珠里簡(Na) 和(Caa) 冬瓜山(Nc) ,(COMMACATEGORY) 晚間(Nd) 在(P) 珍珠里簡(Nc) 的(DE) 禮拜(Na) 有(V_2) 一百五十(Neu) 人(Na) ,(COMMACATEGORY) 拔(VC) 了(Di) 七十六(Neu) 顆(Nf) 牙(Na) 。(PERIODCATEGORY)
(0, 5, 'QUANTITY', '華氏80度')
(8, 12, 'QUANTITY', '30-6')
(37, 40, 'LOC', '冬瓜山')
(41, 43, 'TIME', '晚間')
(52, 56, 'CARDINAL', '一百五十')
(60, 63, 'CARDINAL', '七十六')
只辨識出1個實體
且分類錯誤
應為GPE
3個地名,共出現四次
珍珠里簡: 不同詞性?
Na:普通名詞,Nc: 地方詞
新增classifier layer
fine-tuned(微調)
訓練下游任務資料集
下游任務: 每個字賦予一個類別
從頭訓練
1. 準備文本資料(下游任務資料集)
InputEample 轉換成 Bert 相容的格式
定義Bert 的訓練和預測 function
實際 fine-tune Bert 來執行分類任務