stately.ai
stately.ai
stately.ai
useState()import React, { useState } from 'react';
function EspressoCounter() {
// Initialize the state variable `espressoCount` with an initial value of 0
const [espressoCount, setEspressoCount] = useState(0);
// Define a function to increment the espresso count
const drinkEspresso = () => {
setEspressoCount(prevCount => prevCount + 1);
};
return (
<div>
<h1>Espresso Counter</h1>
<p>You have drunk {espressoCount} {espressoCount === 1 ? 'espresso' : 'espressos'}.</p>
<button onClick={drinkEspresso}>Drink Espresso</button>
</div>
);
}useReducer()useEffect()useContext()useSyncExternalStore()



LLMs are
not enough


Input
Output
Input
Output
Goal
Start


AutoGPT
What is an agent?
Perform tasks → accomplish goal
Creating intelligent agents
→ State machines
Determinism, explainability
→ Reinforcement learning
Exploration, exploitation
→ Large language models
Interpretation, creativity
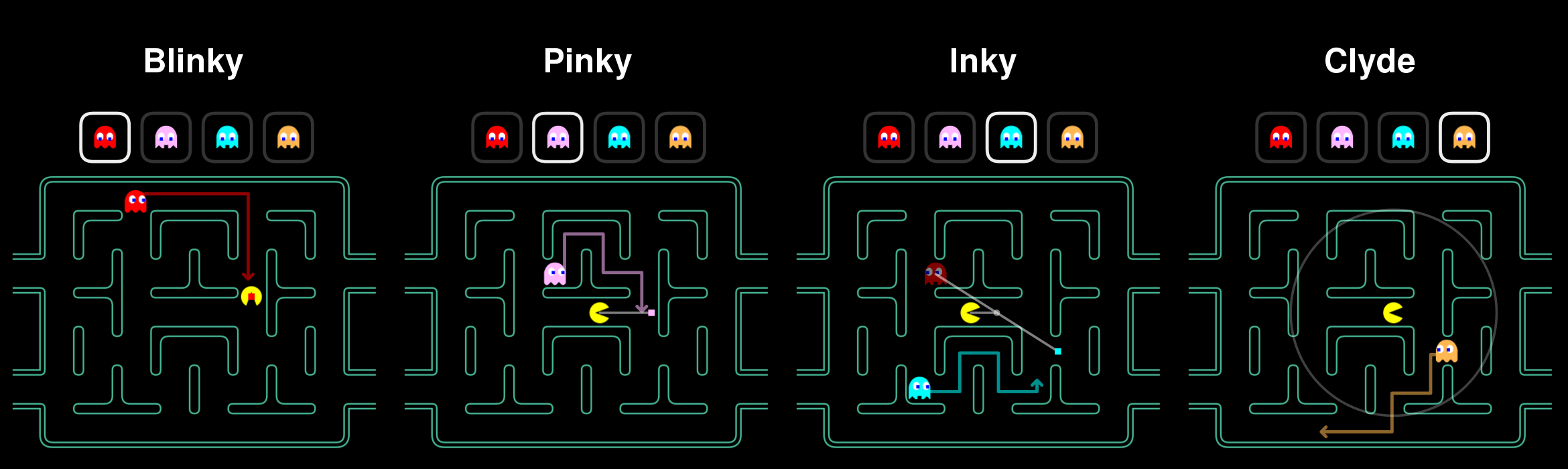
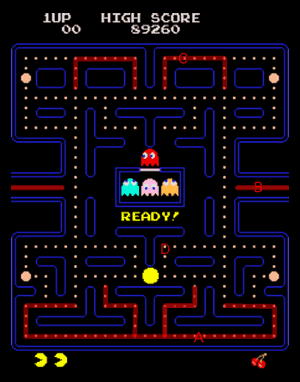
State machines
The original AI
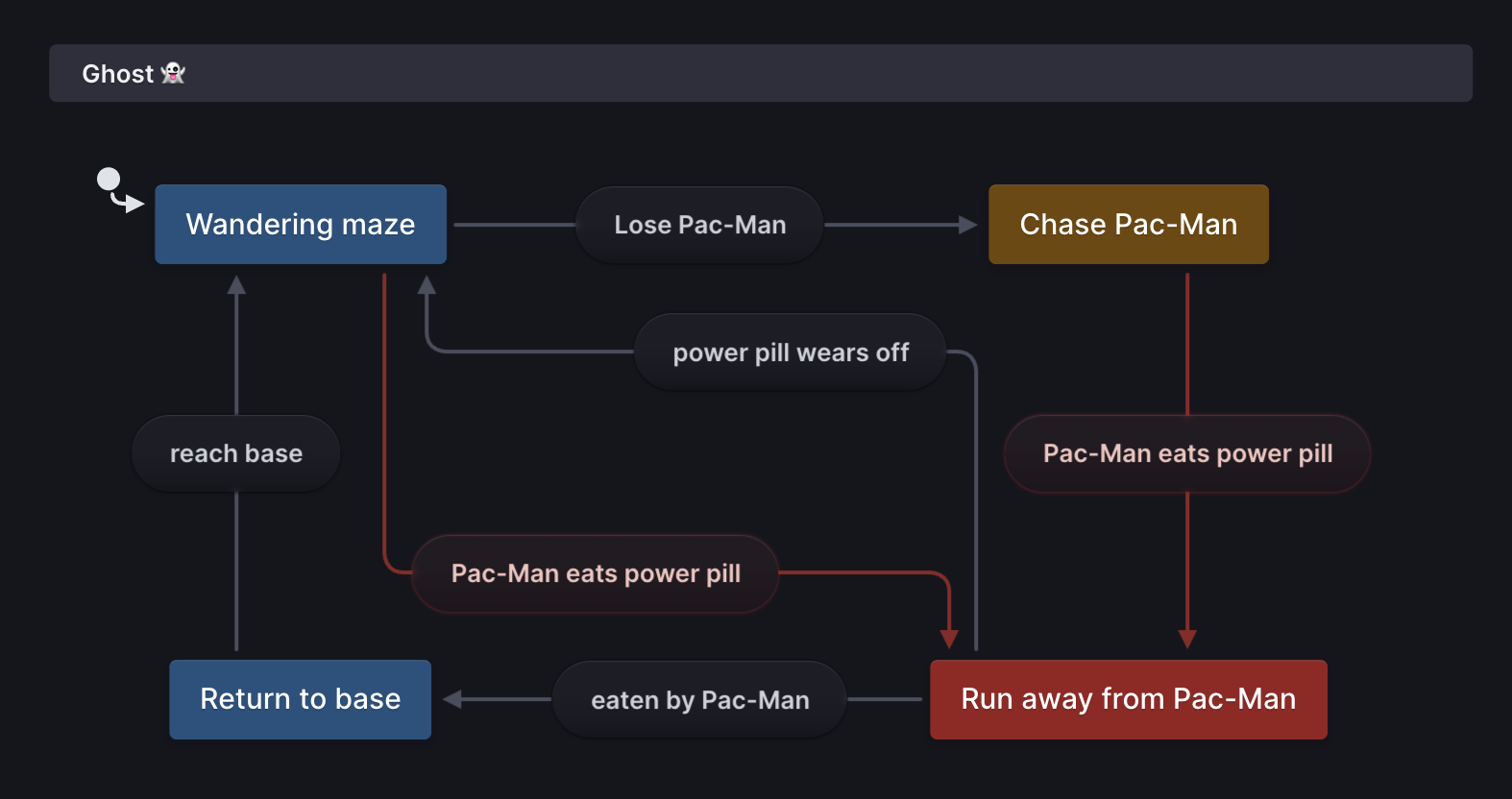
import { createMachine } from "xstate";
export const ghostMachine = createMachine(
{
id: "Ghost 👻",
initial: "Wandering maze",
states: {
"Wandering maze": {
on: {
"Lose Pac-Man": {
target: "Chase Pac-Man",
},
"Pac-Man eats power pill": {
target: "Run away from Pac-Man",
},
},
},
"Chase Pac-Man": {
on: {
"Pac-Man eats power pill": {
target: "Run away from Pac-Man",
},
},
},
"Run away from Pac-Man": {
on: {
"power pill wears off": {
target: "Wandering maze",
},
"eaten by Pac-Man": {
target: "Return to base",
},
},
},
"Return to base": {
on: {
"reach base": {
target: "Wandering maze",
},
},
},
},
}
);
import { useMachine } from '@xstate/react';
// ...
function Ghost() {
const [state, send] = useMachine(ghostMachine);
const chasing = state.matches('Chase Pac-Man');
const onEaten = () => {
send({ type: 'eaten by Pac-Man' });
}
// ...
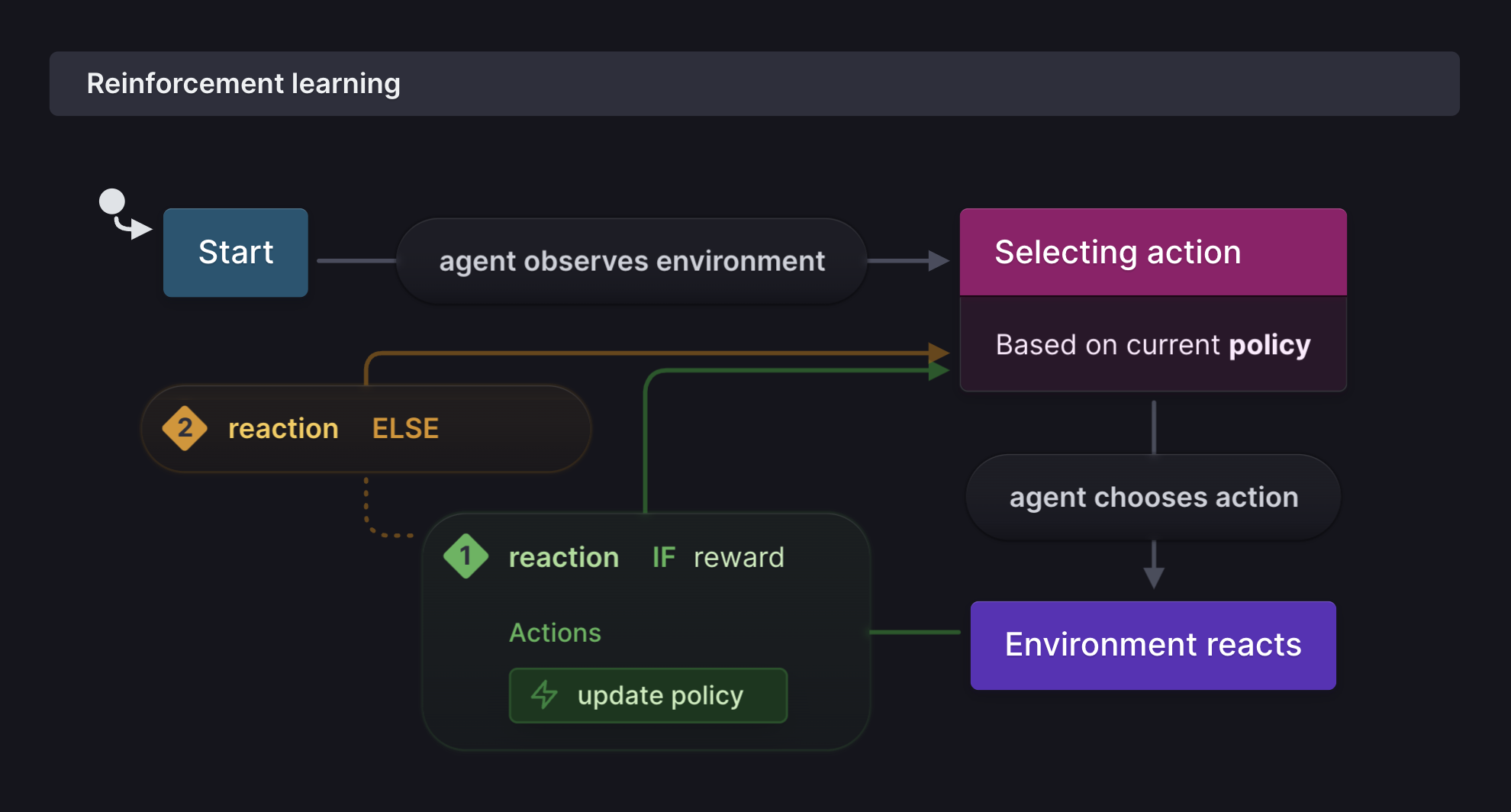
}Reinforcement learning (RL)
🤖 An intelligent agent learns
🔮 ... through trial and error
💥 ... how to take actions inside an environment
🌟 ... to maximize a future reward
State machines that can learn
Environment

Normal mode

Scatter mode
Agent

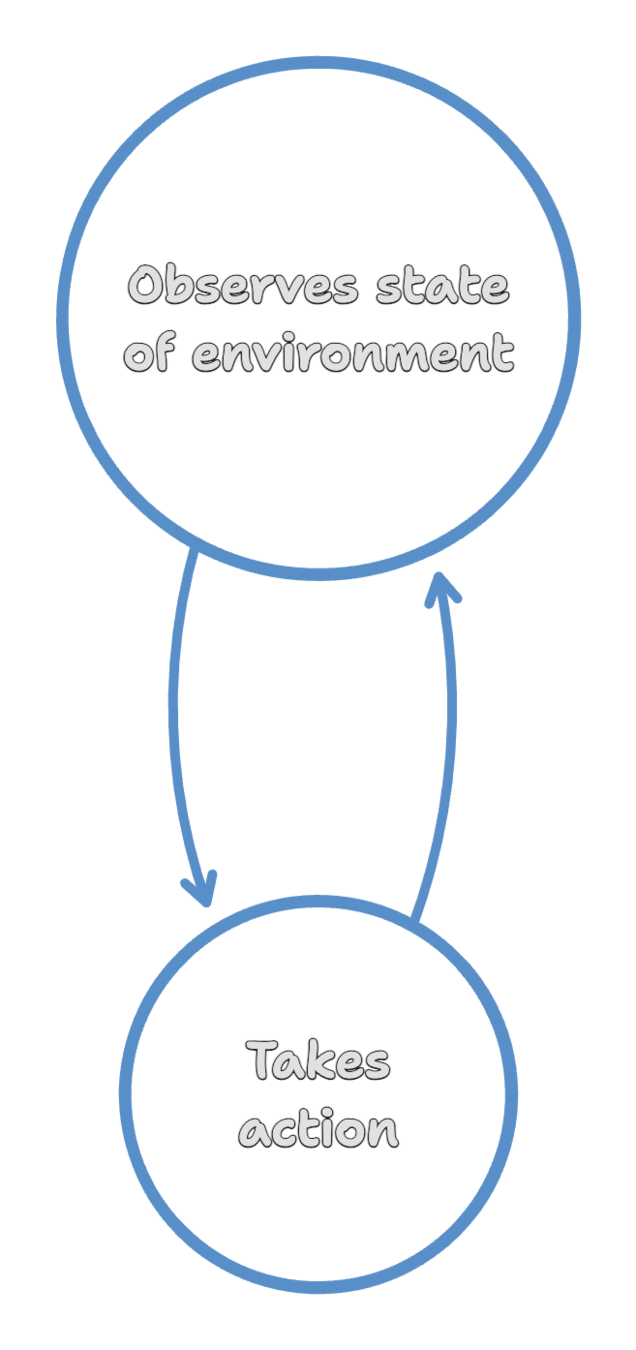


Agent
Policy
Reward
+10
-3
🟡 + 🍒 = 👍
🟡 + 👻 = 👎
Credit assignment

no reward
Do nothing
Owner has treat
Tells dog "down"
ENVIRONMENT
Nothing changes
ENVIRONMENT
Exploration


reward++
Go down
Get treat
Owner has treat
Tells dog "down"
ENVIRONMENT
Owner praises dog
ENVIRONMENT
Exploration
Go down
Owner has treat
Tells dog "down"
ENVIRONMENT
Owner praises dog
ENVIRONMENT
Exploitation
💭
Treat?
Run away
Owner has treat
Tells dog "down"
ENVIRONMENT
Undesired outcome
ENVIRONMENT

🤬
Exploration
"Down"
Reward 🦴

Reinforcement learning
with human feedback (RLHF)
Large language models
LLMs with
1. Get an OpenAI API key
2.
npm i openaiLLMs with
3. Create completions with SDK


tl;dr: RTFM to learn faster
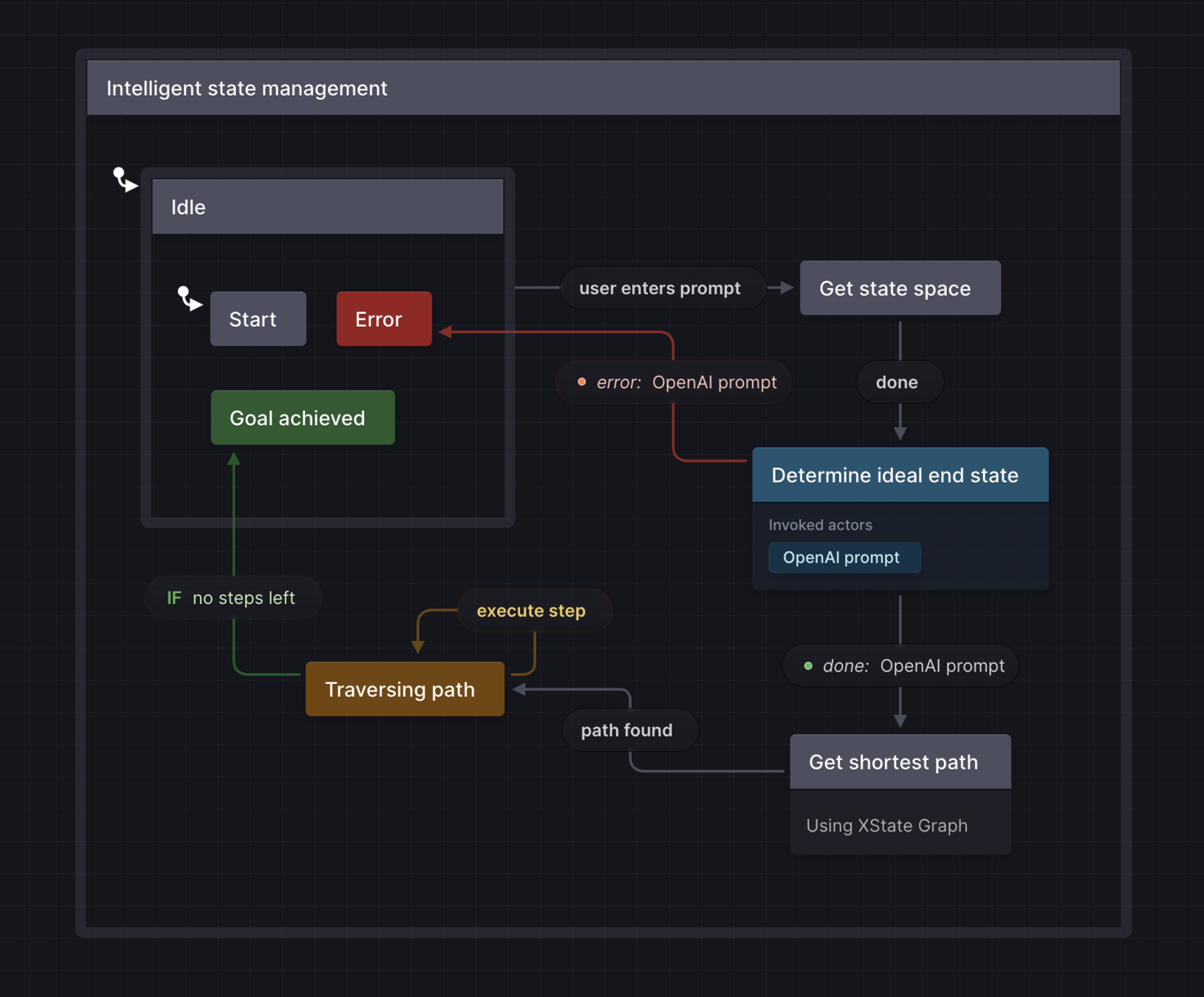
State machines for
intelligent logic

Show this slide if the WIFI died
or you messed up the demo
Learnings
LLMs are unpredictable
Event-based logic makes our apps
more declarative
State machines & reinforcement learning
make LLM agents more intelligent
Future plans
🔭 State machine synthesis
🤖 Adaptive UIs with RL
📐 Predictable LLM output
🌌 Deep learning for state space reduction
@statelyai/agentComing soon
@xstate/graph@betaDocumentation coming soon 😅
intelligent
Make your state management
Declarative UIs
Declarative state management
Separate app logic from view logic.
LLMs (GPT-4 and similar)
Reinforcement learning
Use as minimally as possible.

¡Gracias React Alicante!

React Alicante 2023
David Khourshid · @davidkpiano
stately.ai
Agent
Environment
Reward
State
Action
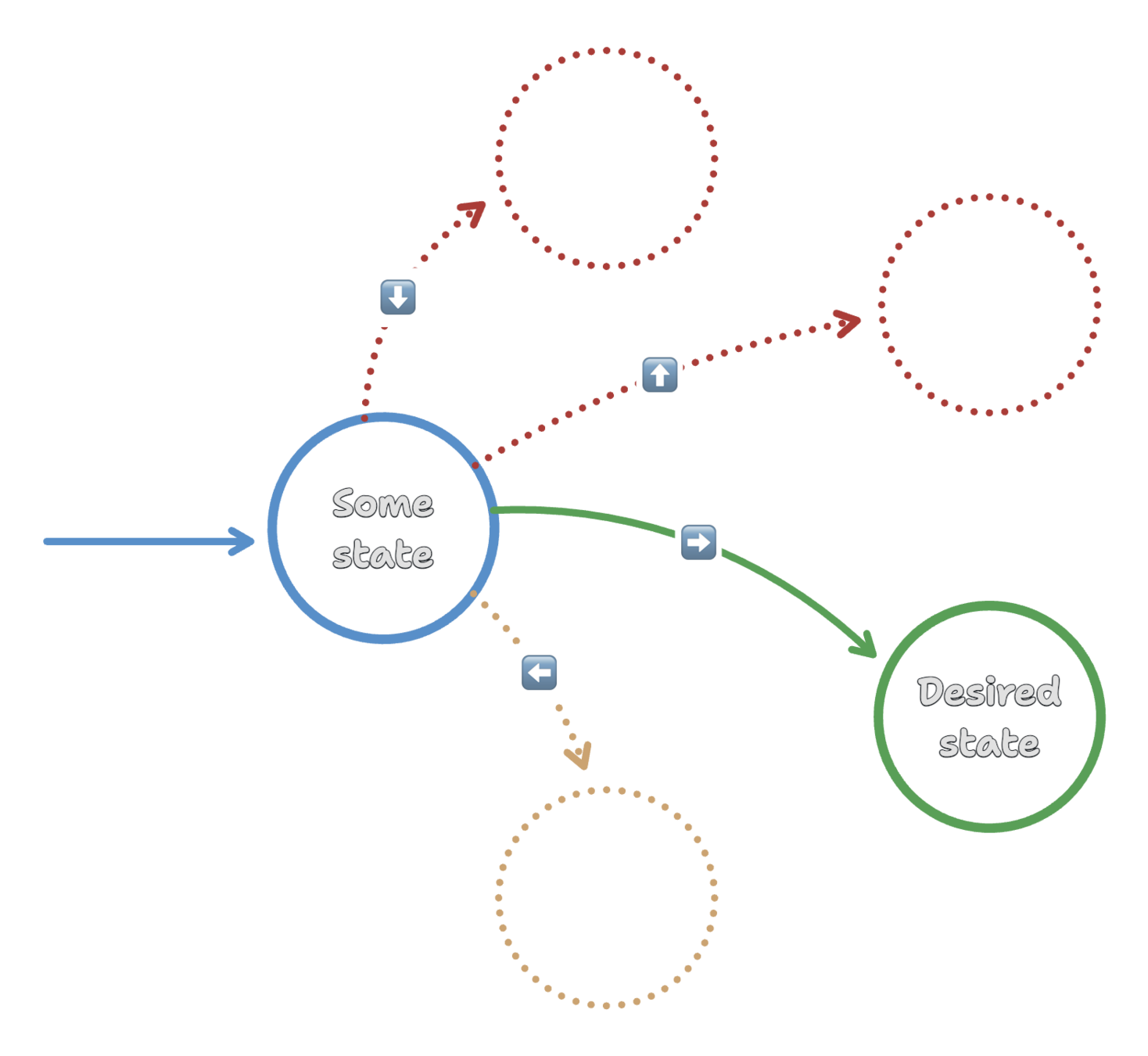
Environment = modeled as
a state machine
State = finite states
(grouped by common attributes)
Reward = how well does expected state (from state machine model) reflect actual state?
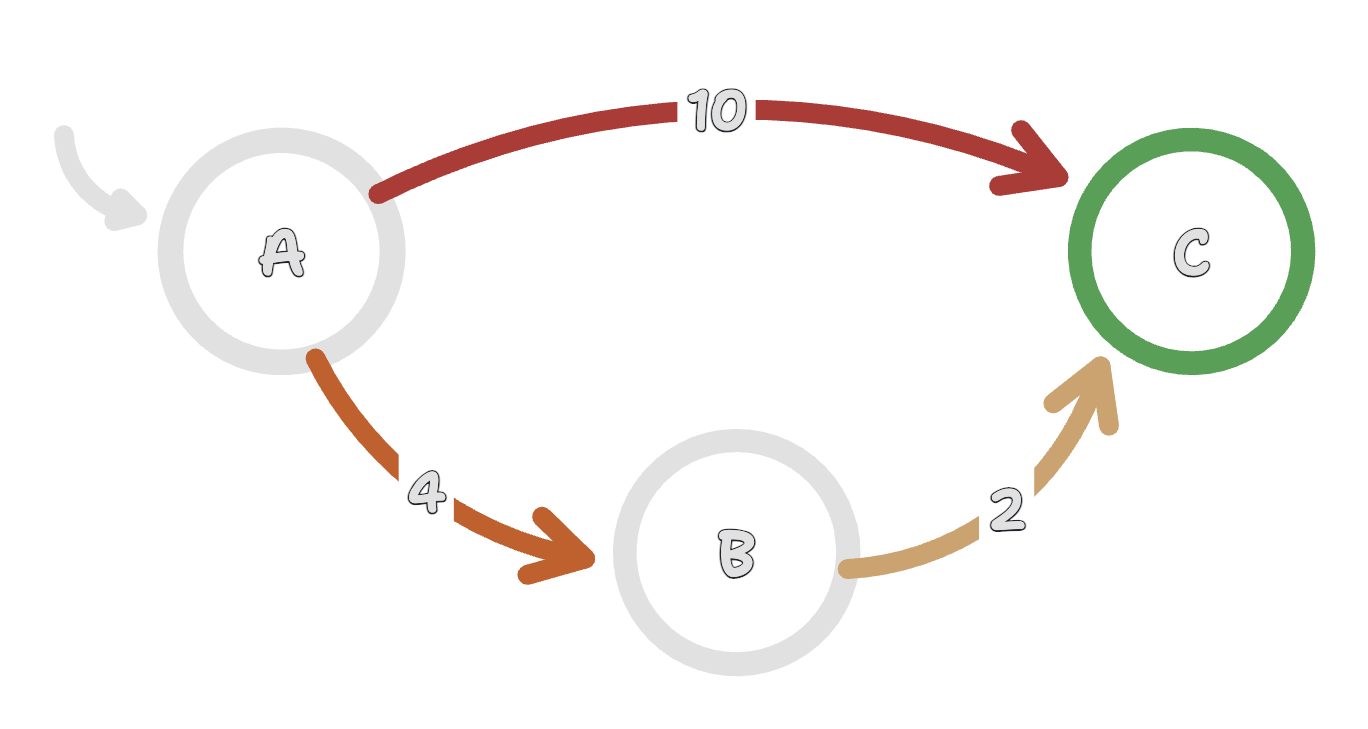
Action = shortest path
to goal state