Using Statistical Inference to Enhance Link Recovery in
Software Retrieval
David N. Palacio

assigned


new Webex requirement
checks
implements
repos
Which artifacts are being affected by requirements?


architecture team
assigned
new Webex requirement
checks
implements
repos
An Impact Change Problem


affects a set of artifacts
architecture team

inspects
new Webex requirement
checks
repos
What if instead of the developer, an analyst is assessing the security impact of the requirement?

affects a set of artifacts
Stakeholders
- Managers
- Data Scientists
- Testers
Imagine other roles in the company related to the new req
Source Code
Test Cases
Bug Reports
Requirements
Software Artifacts and their nature
Software Team Assessment
How can we automatically identify if the source code is related to a specific requirement?

Software Retrieval (or Traceability) is the mechanism to uncover implicit relationships among software artifacts

Agenda
- Brief Introduction to Software Traceability
- Project Overview
- SecureReqNet & Comet
- Neural Unsupervised Software Traceability
- Information Science to Understand Trace Models
- Tools [Jenkins Integration]
Software Traceability Background
Source File
Requirement (Issue) File
Software Traceability is the mechanism to uncover implicit relationships among software artifacts
How deep are the artifacts correlated?
Source File
Requirement (Issue) File
Test File
How deep are the artifacts correlated?
Source File
Requirement (Issue) File
Test File
Is it feasible to manually recover trace links? How do you assess the quality of those manual links?
Assuming that the artifacts of a software system are text-based (e.g., requirements, source code, or test cases), what type of automation techniques can be employed to uncover hidden links?
Information Retrieval (IR) or Machine Learning (ML) techniques help to vectorize text-based artifacts and perform a distance metric
Trace Link (Similarity) Value [0,1]
Source Artifacts (i.e., requirement files)
Target Artifacts (i.e., source code files)
Project Overview
IR on Security Req
0
COMET
CI T-Miner
1
1
IR on Security Req
0
SecureReqNet
COMET
CI T-Miner
1
2
1
IR on Security Req
0
SecureReqNet
COMET
CI T-Miner
1
2
1
IR on Security Req
0
Deep Unsupervised Traceability
3
SecureReqNet
COMET
T-Miner
CI T-Miner
1
2
1
5
IR on Security Req
0
Deep Unsupervised Traceability
3
SecureReqNet
COMET
T-Miner
CI T-Miner
1
2
1
5
IR on Security Req
0
Deep Unsupervised Traceability
3
Security
Soft. Trace.
Tools
SecureReqNet
COMET
T-Miner
CI T-Miner
Why-Trace
1
2
1
5
IR on Security Req
0
Deep Unsupervised Traceability
3
4
Security
Soft. Trace.
Interpretability
Tools
Research
Dev
SecureReqNet
SecureReqNet
COMET
T-Miner
CI T-Miner
Why-Trace
1
2
1
5
IR on Security Req
0
Deep Unsupervised Traceability
3
4
Security
Soft. Trace.
Interpretability
Tools
Research
Dev

Issue Tracker
Security Related
non-Security Related
We need to design automated approaches to identify whether <issues> describe Security-Related content




SecureReqNet is an approach that identifies whether <issues>describe security-related content
Issue Tracker

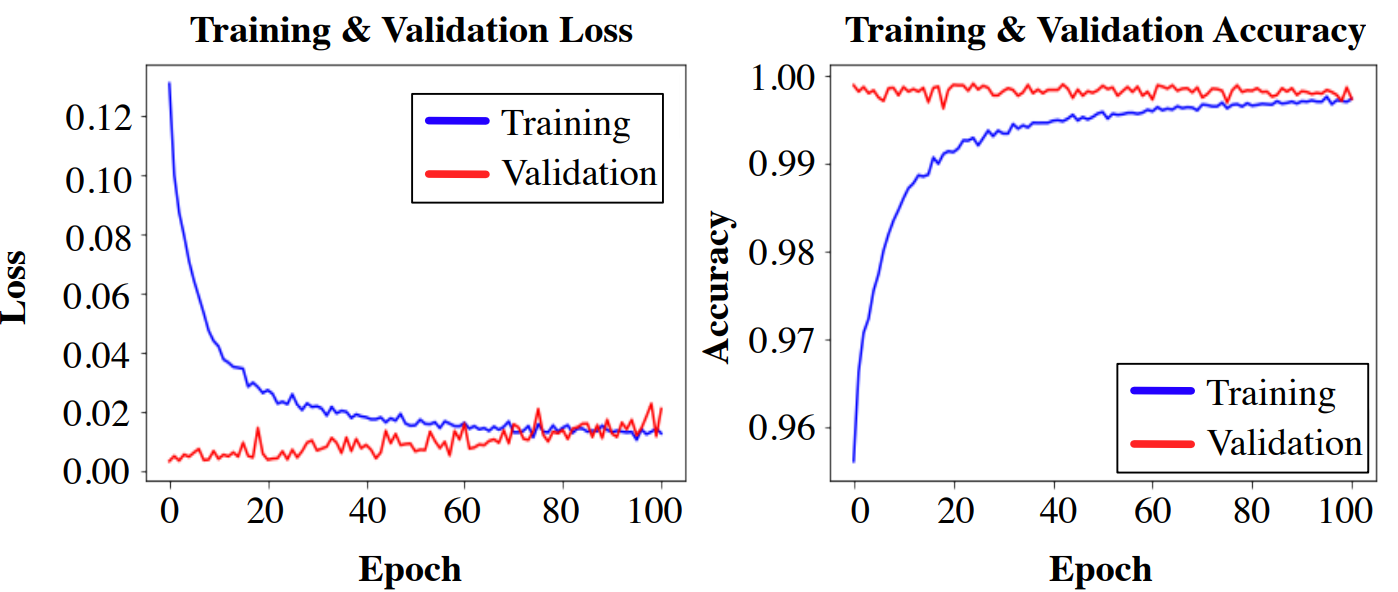
(Shallow) SecureReqNet
α-SecureReqNet

ICSME-2019 Cleveland, OH - SecureReqNet Paper
The Link Recovery Problem and Its Probabilistic Nature
SecureReqNet
COMET
T-Miner
CI T-Miner
Why-Trace
1
2
1
5
IR on Security Req
0
Deep Unsupervised Traceability
3
4
Security
Soft. Trace.
Interpretability
Tools
Research
Dev
The link recovery problem is the fundamental problem in Software Traceability; it consists of automatically establishing the relationships of artifacts allowing for the evolution of the system (maintainability)
Source File
Requirement File
The link recovery problem: How would you compute θ ?
Source File
Requirement File
Test File
How do we enhance link recovery with recent IR/ML approaches?
Source File
Requirement File
Test File
What if we compute a second θ for Req→Tc? Is the initial θ affected?
Source File
Requirement File
Test File
Test File
And what if we add more information?
Prediction
Inference
Use the model to predict the outcomes for new data points
Use the model to learn about the data generation process
Prediction
Statistical Inference Methods:
- Probabilistic Inference or Bayesian Inference
- Causal Inference
Inference
Learning Process:
- Machine Learning
- Deep Learning
Source File
Requirement File
Test File
Test File
Do we use Inference or Prediction to compute θ?
The link recovery problem is a Bayesian Inference Problem since we want to uncover a probabilistic distribution throughout a reasoning process
The General Model
Bayesian Inference Traceability
The likelihood is a fitted distribution for the IR outcomes or observations O, given the probability of H. H is the hypothesis that the link exists.
Traceability as a Bayesian Inference Problem
The prior probability of H. It can be drawn from the factors that influence the traceability: transitive links, other observations of IR values, or developers' feedback.
Traceability as a Bayesian Inference Problem
The marginal likelihood or "model evidence". This factor does not affect the hypothesis H.
Traceability as a Bayesian Inference Problem
The posterior probability that a trace link exits; it can be interpreted as the impact of an observation O on the probability of H
Traceability as a Bayesian Inference Problem

ICSE-2020 Seoul, Korea - COMET Paper
A HierarchiCal PrObabilistic Model for SoftwarE Traceability
[COMET]
SecureReqNet
COMET
T-Miner
CI T-Miner
Why-Trace
1
2
1
5
IR on Security Req
0
Deep Unsupervised Traceability
3
4
Security
Soft. Trace.
Interpretability
Tools
Research
Dev
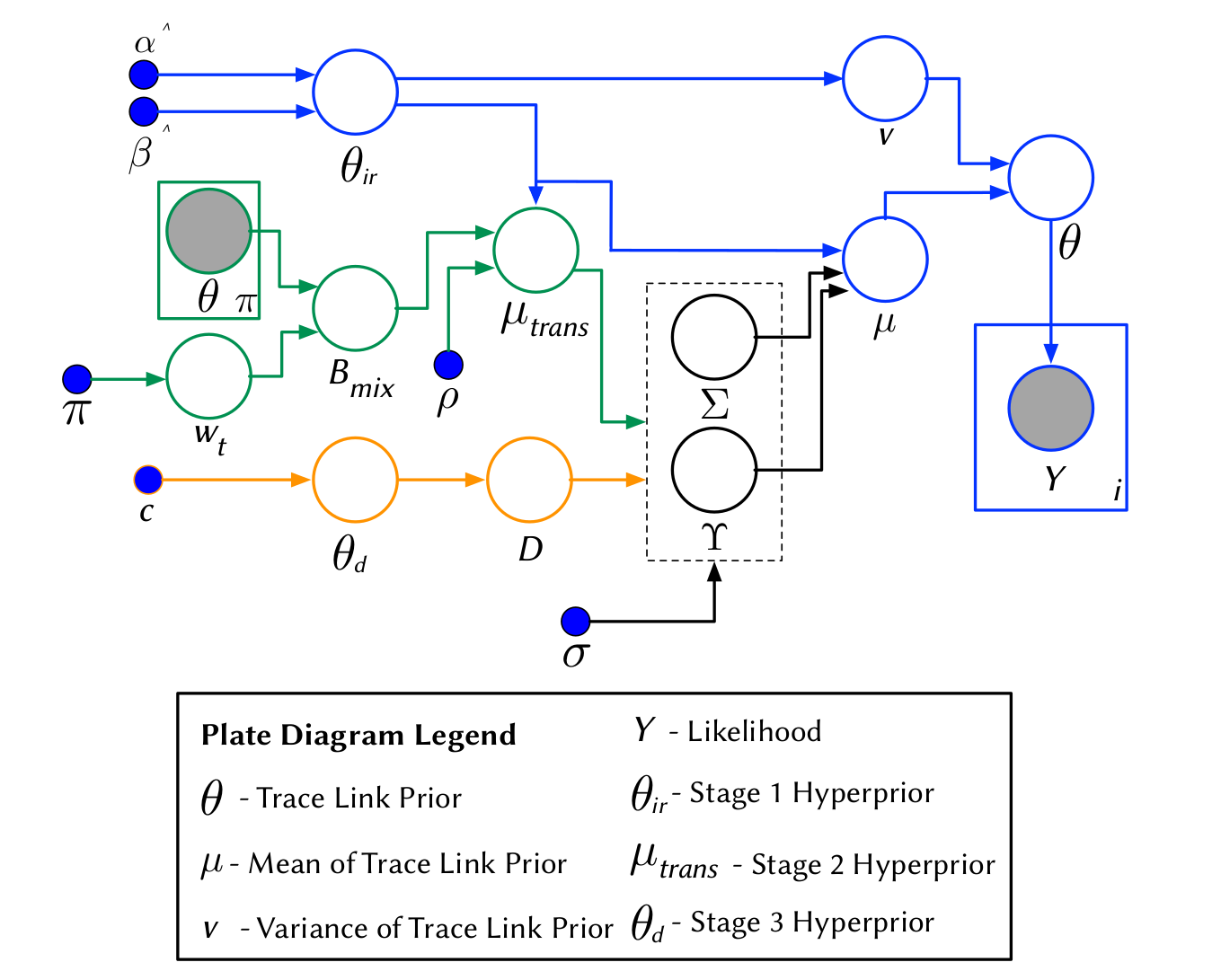
Traceability as a Bayesian Inference Problem
Estimating the Likelihood
| Model | Observation | Linked? |
|---|---|---|
| VSM | 0.085 | 0 |
| JS | 0.446 | 1 |
| LDA | 0.01 | 0 |
A Hierarchical Bayesian Network to model priors
Textual Similarities
Developers' Feedback
Transtive Links
Textual Similarities
Stage 1
The BETA distribution is fitted from distinct observations of IR techniques
Developers' Feedback
Stage 2
A different BETA distribution is fitted from distinct observations of Developers' feedback from the link under study
Transitive Links
Stage 3
Source File
Test File
Test File
A BETA mixture model is employed to model all transitive (probabilistic) links
The Holistic Model
Stage 4
Inferring the Traceability Posterior
How do we compute a posterior probability given the traceability hyperpriors?
Good luck!
well actually, we performed...
- Maximum a Posteriori estimation (MAP)
- Markov Chain Monte Carlo (MCMC) via the No-U-Turn Sampling (NUTs)
- Variational Inference (VI)
vs.

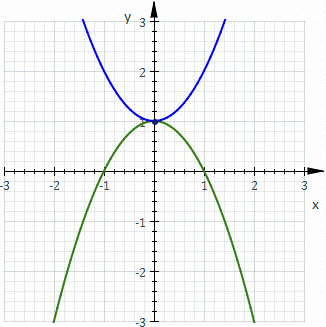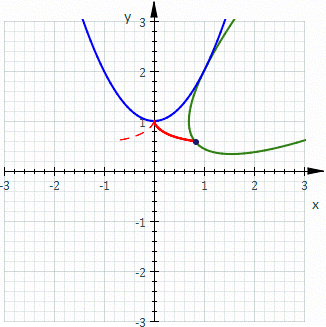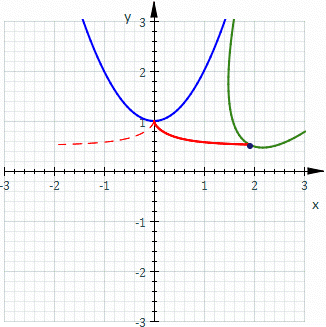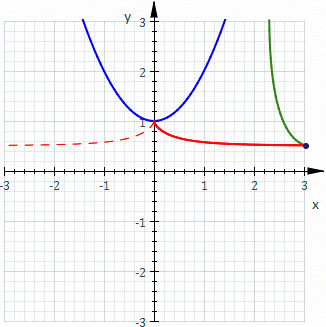
The Probabilistic Approach
The Deterministic Approach
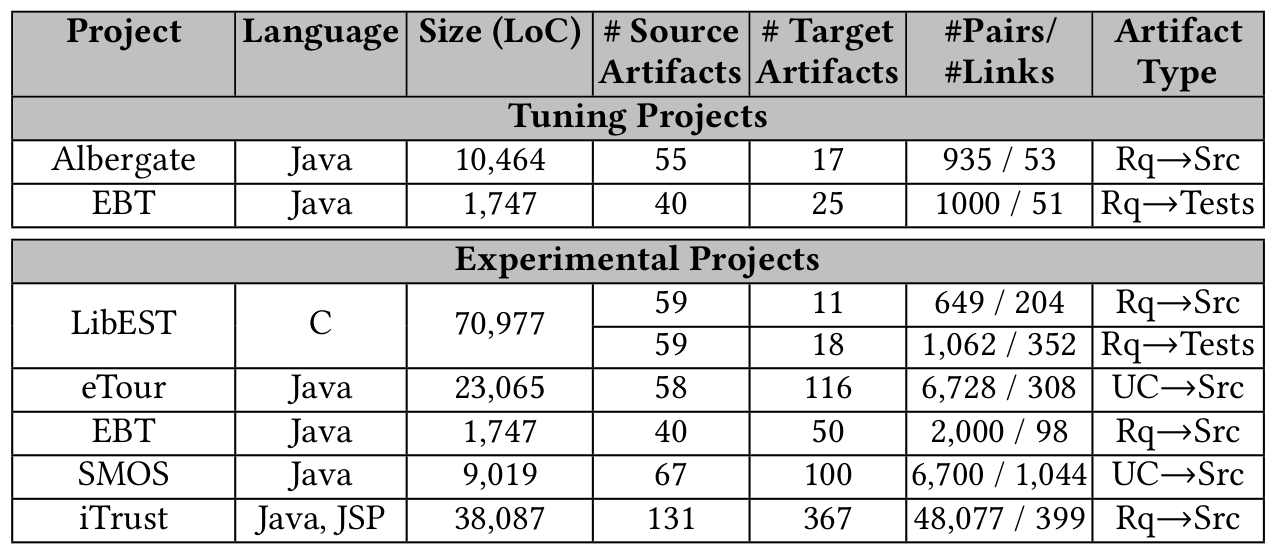
COMET's Empirical Evaluation
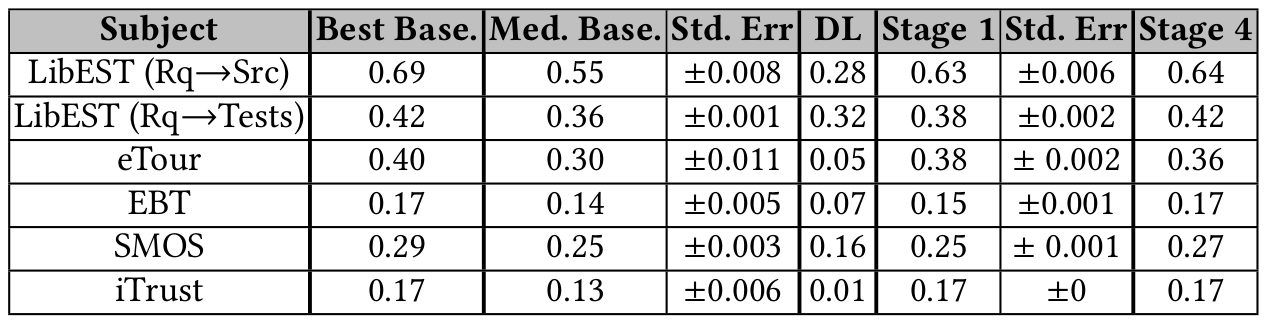
LSTM-based
IRs
COMET
COMET performance vs Information Retrieval
From previous results and after running some initial test with unsupervised neural learners, we hypothesized that the information of the artifacts bounds the link recovery
Therefore, we proposed:
Bounding the effectiveness of Unsupervised Software Traceability with Information Decomposition
Therefore, we proposed:
Bounding the effectiveness of Unsupervised Software Traceability with Information Decomposition
But,
We need more datasets to perform an empirical evaluation that supports our claims
Next Steps..
- To assess Neural Unsupervised Models for on a new dataset [semantic]
- To use Information Theory to Understand Traceability Models [interpretability]
Using Neural Unsupervised Learners for Traceability
Paragragh Vector and Embeddings
SecureReqNet
COMET
T-Miner
CI T-Miner
Why-Trace
1
2
1
5
IR on Security Req
0
Deep Unsupervised Traceability
3
4
Security
Soft. Trace.
Interpretability
Tools
Research
Dev
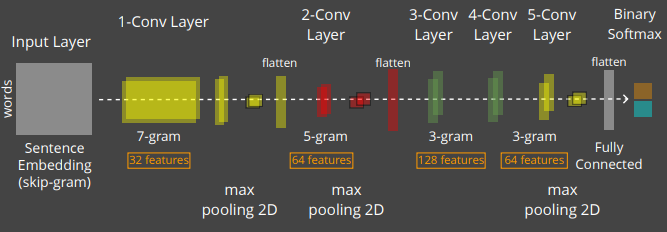
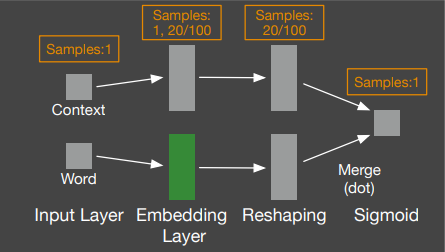
Word Neural Models (skip-gram)
Paragraph Neural Models (doc2vec)
Input Layer
word
samples:
1, 20/100
Merge (dot)
Embedding Layer
context
samples: 1
Reshaping
samples:
20/100
samples: 1
Sigmoid
Unsupervised Embedding

{'attack': ['network', 'exploit', 'unauthor'],
'code': ['execut', 'inform', 'special'],
'exploit': ['success', 'network', 'attack']}
Unsupervised Training or Skip-Gram Model
Word2Vec or wv
- Similarity Metrics:
- Word Movers Distance (WMD)
- Soft Cosine Similarity (SCM)
- Preprocessing Strategies:
- Conventional Pipeline (e.g., camel case splitting, stop words removal, stemming)
- Byte Pair Encodings or Subwordings:
- BPE-8k, 32k, and 128k
Doc2Vec or pv
- Similarity Metrics:
- Euclidean and Manhattan
- Cosine Similarity (COS)
- Preprocessing Strategies:
- Conventional Pipeline (e.g., camel case splitting, stop words removal, stemming)
- Byte Pair Encodings or Subwordings:
- BPE-8k, 32k, and 128k
Datasets
- Traceability Benchmarks
- cisco/repo:
- cisco/LibEst
- cisco/SACP
- Semantic Vectors were trained on:
- ~1M Java Files
- ~1M Python Files
- ~6M English Files (all Wikipedia)
cisco/LibEst
- Type of links Requirements (req) to Test Cases (tc)
- Approx 200 potential links
- Natural Language/C++
cisco/SACP
- Type of links Pull Requests (pr) to Python Files (py)
- Approx 20143 potential links
- Natural Language/Python
Some Results for cisco/SACP
Word Vectors (or skip-gram)
AUC = 0.66
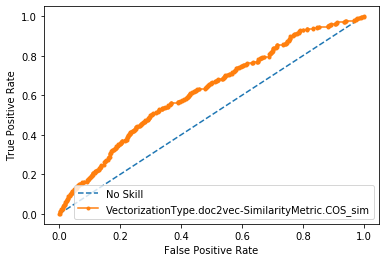
Paragraph Vectors
AUC = 0.62
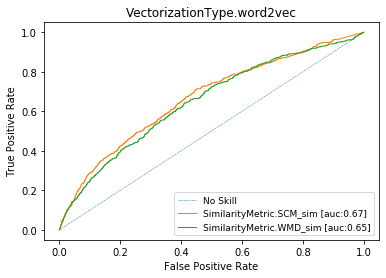
ROC CURVES with conventional prep. for cisco/SACP
Word Vectors (or skip-gram)
auprg= 0.38
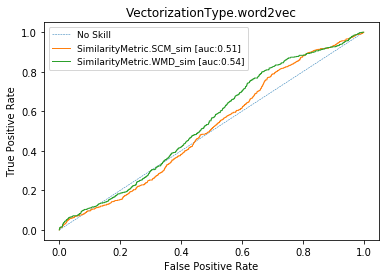
ROC CURVES with BPE-8k prep. (WMD) for cisco/SACP
A General Data Science Assessment with Ground Truth
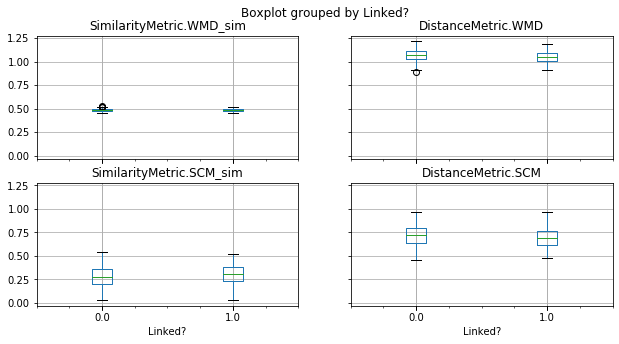
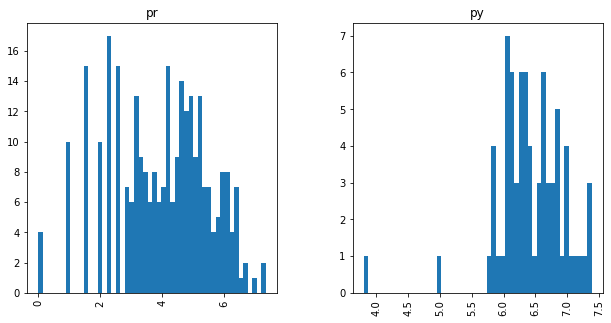
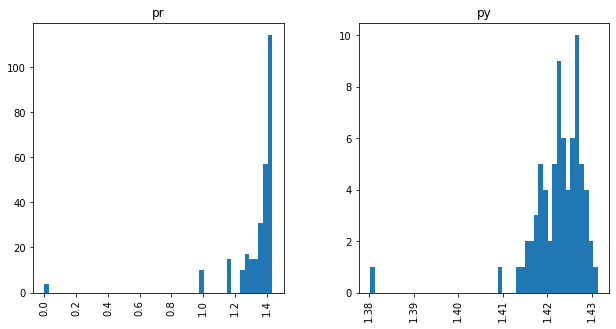
Traceability techniques are recovering links but not learning [cisco/LibEst]
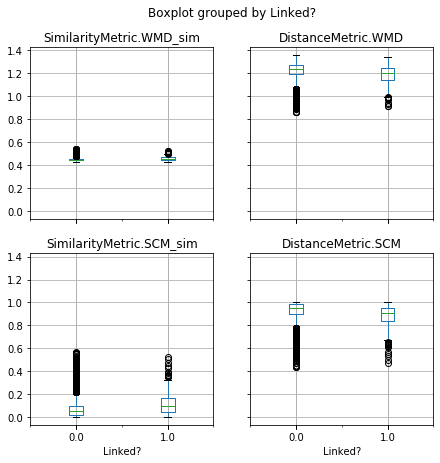
Traceability techniques are recovering links but not learning for cisco/SACP
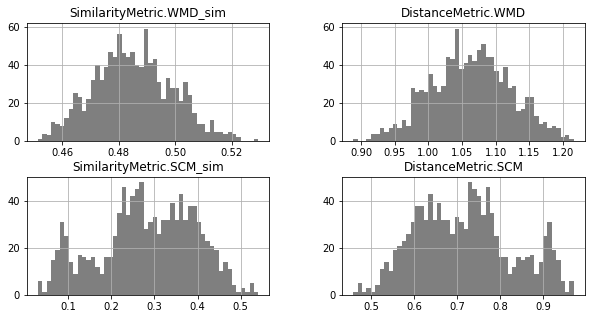
Unimodal Distributions for cisco/LibEst :(
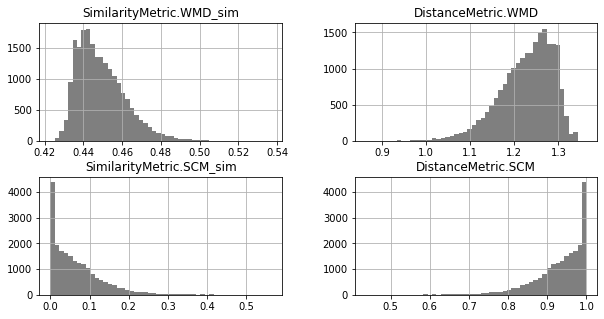
Unimodal Distributions for cisco/SACP :(
On the Use of Information Theory to Interpret Software Traceability
Information Analysis, Transmitted Information, and Clustering
SecureReqNet
COMET
T-Miner
CI T-Miner
Why-Trace
1
2
1
5
IR on Security Req
0
Deep Unsupervised Traceability
3
4
Security
Soft. Trace.
Interpretability
Tools
Research
Dev
By measuring Shannon Entropy, Extropy, and (Minimum) Shared Information, we are able to understand the limits of traceability techniques
Shannon Entropy or Self-Information
Shannon Extropy or External-Information
Entropy and Extropy for cisco/SACP
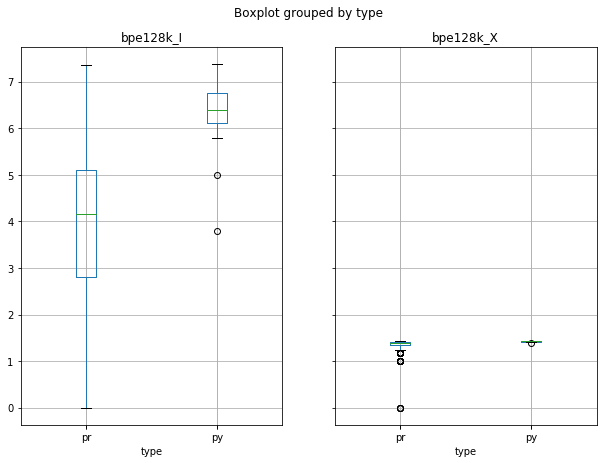
Minimum Shared Information (Entropy/Extropy)
Minimum Shared Information vs WMD for cisco/SACP
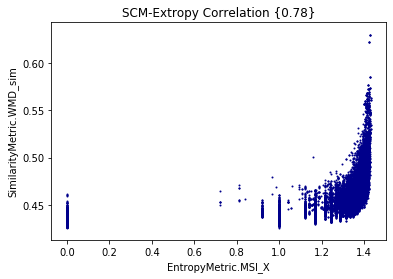
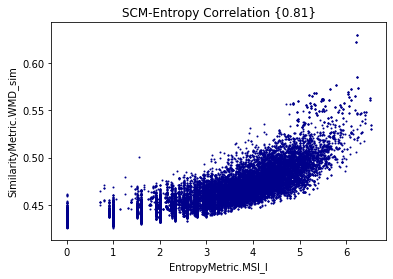
Entropy
Extropy
Semantic-Information Analysis (SCM) for cisco/SACP
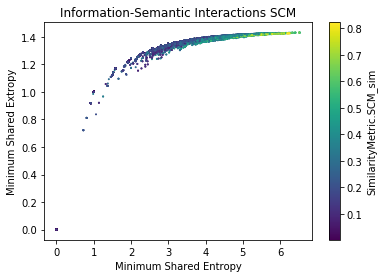
Semantic-Information Analysis by Ground Truth (SCM) for cisco/SACP
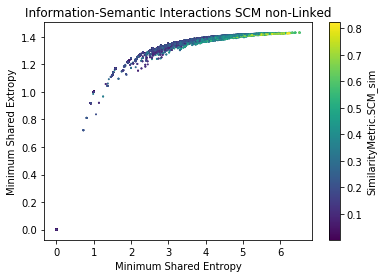
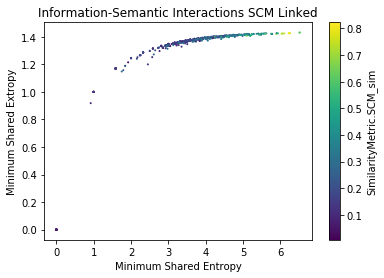
Findings
- SACP Pull Requests are more informative than SACP Python Files
- However, PR Entropy has a big variability (bigger than py)
- The larger the shared information value, the more similar the potential links are (?)
A Traceability Analysis Tool
COMET + SecureReqNet + Interpretability
SecureReqNet
COMET
T-Miner
CI T-Miner
Why-Trace
1
2
1
5
IR on Security Req
0
Deep Unsupervised Traceability
3
4
Security
Soft. Trace.
Interpretability
Tools
Research
Dev
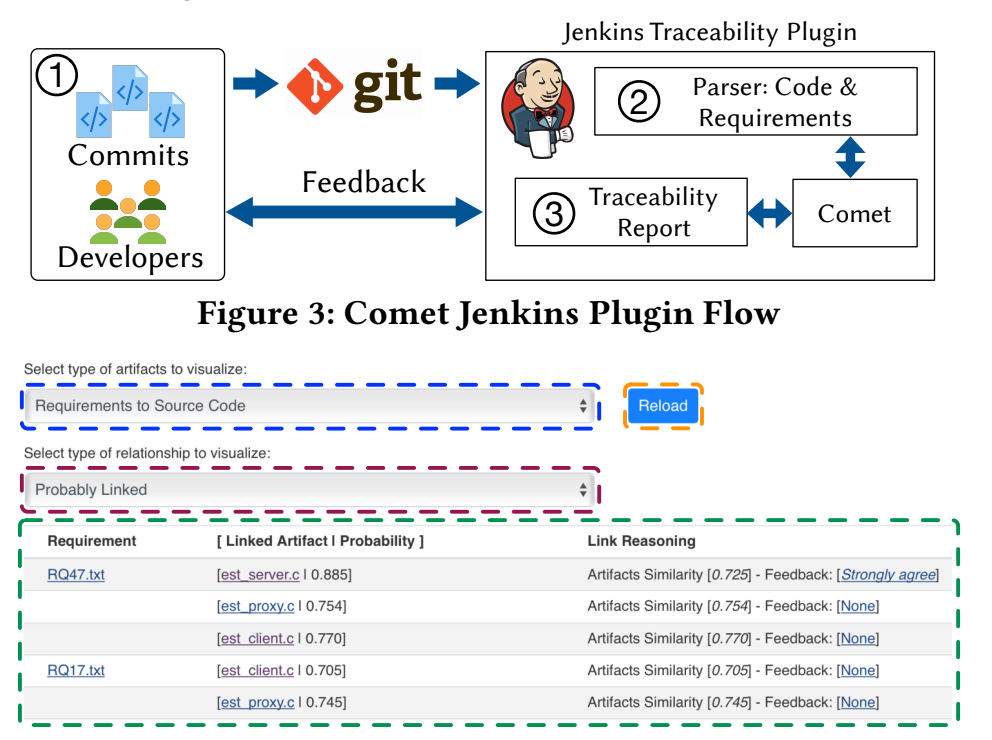
Current Deployment of [CI]T-Miner Tool
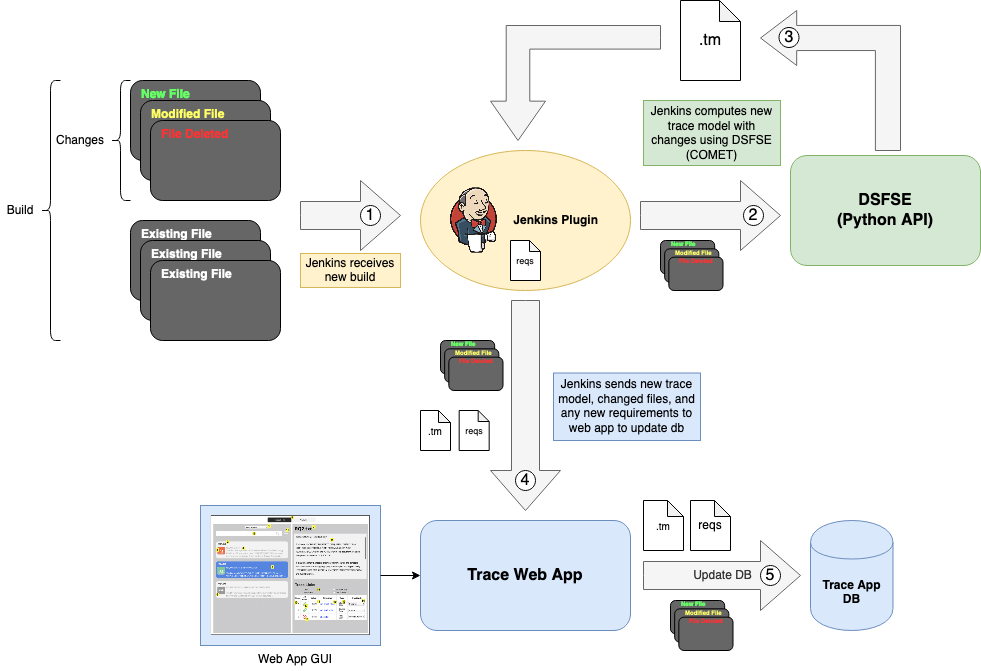
T-Miner Tool with the Information-Semantic Module included
Summary

Adapting IR/ML Approaches
Introducing the Probabilistic Nature of the Traceability Problem
Using Information Science Theory to Understand Traceability Models
Mining Software Artifacts for Continious Integration
thank you!
Appendix →
Estimating the Likelihood
How do we enhance link recovery with recent IR/ML approaches?


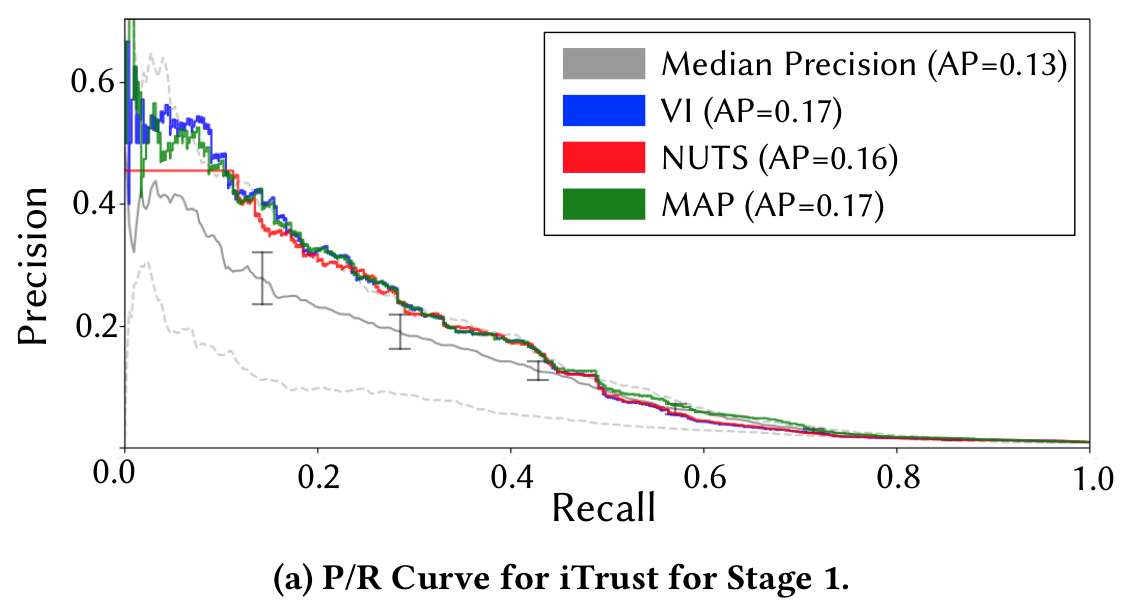
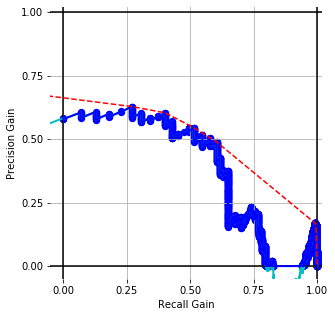
Precision-Recall Semantic Analysis
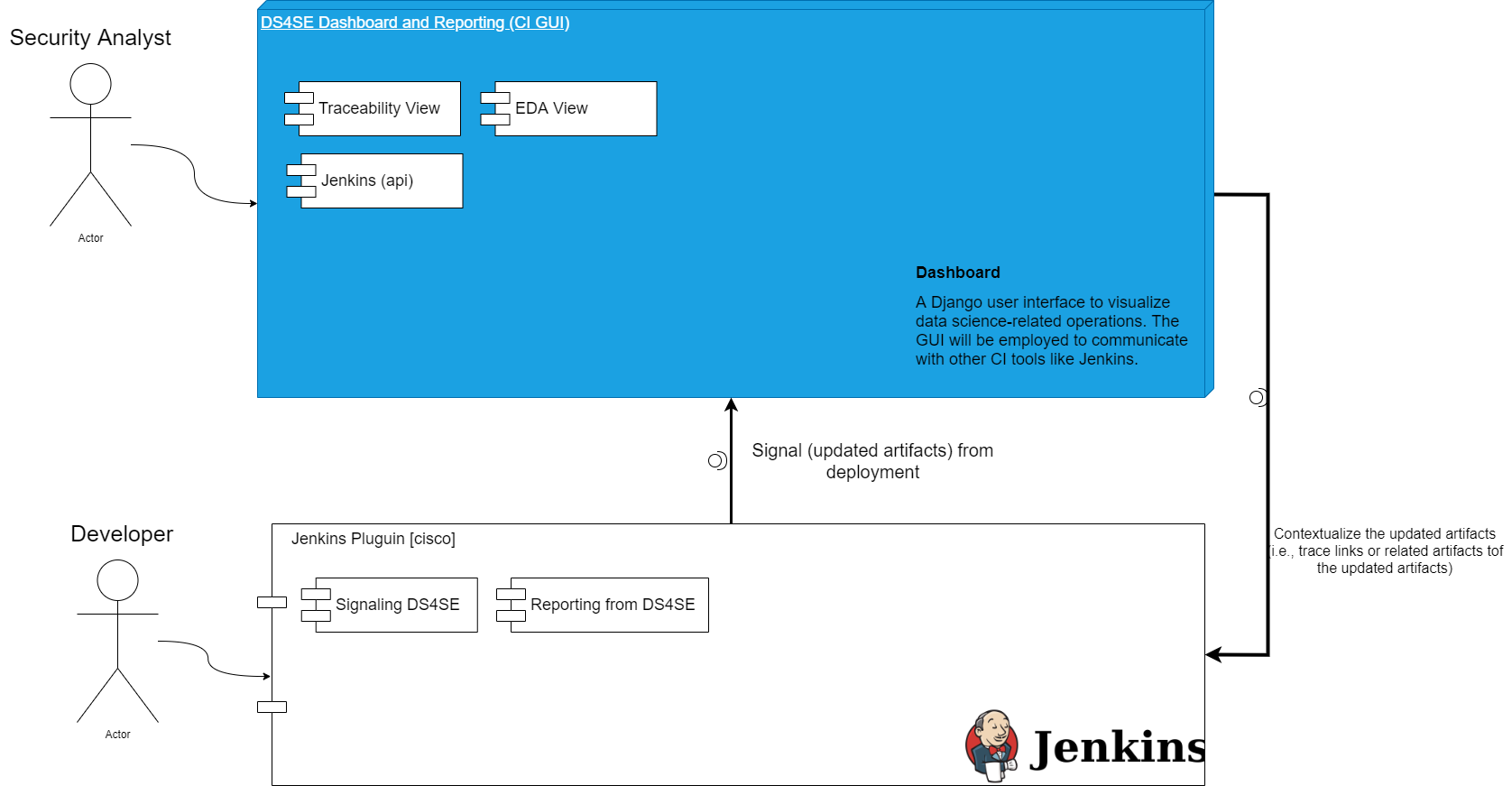
Solution Architecture
Shannon Entropy or Self-Information for cisco/SACP
Relative Frequencies
Shannon Extropy for cisco/SACP
Relative Frequencies
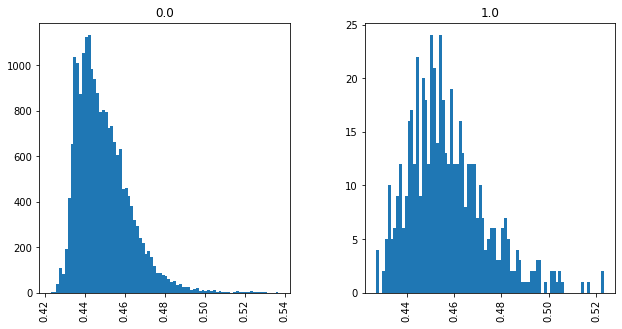
Unimodal Distributions by Ground-Truth (WMD) for cisco/SACP
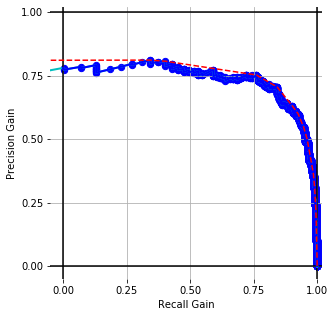
Word Vectors (or skip-gram) [WMD]
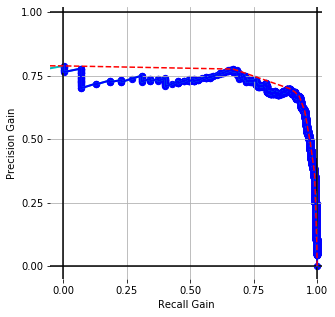
Paragraph Vectors [COS]
Embedding Performance [precision-recall gain] with conventional prep. for cisco/SACP
REQUIREMENT 4: OBTAINING CA CERTIFICATES:
| The EST client can request a copy of the current EST CA certificate(s) from the EST server. The EST client is assumed to perform this operation before performing other operations. |
Source Artifacts S are based on RFC 7030 “Enrollment over secure transport”
Source Target Artifacts are both source code <T> and test cases <TC> of LibEST
Trace Links that exits between all possible pairs of artifacts from S → T
David A. Nader
I am 3th year PhD Student at William and Mary in Computer Science.
I was born in Bogota, Colombia. I did my undergrad in Computer Engineer at The National University of Colombia (UNAL). My master was in CS between The Technical University of Munich (TUM) and UNAL.
Research interest: Deep Learning for SE, Natural Computation, Causal Inference for SE, Code Generation and Representation
Hobbies: Kayaking, Hiking, Movies,
Mentor: Chris Shenefiel
Manager: Jim Warren


UNAL'17
W&M'17
A Hierarchical Bayesian Network to model priors
Random factors that influence the probability that a trace link exists in LibEST
- Textual Similarities among artifacts
- CISCO Developers feedback
- Transitive Relationships
Textual Similarities
Developers' Feedback
Transtive Links
Textual Similarities
Stage 1
The BETA distribution is fitted from distinct observations of IR techniques
Developers' Feedback
Stage 2
A different BETA distribution is fitted from distinct observations of Developers' feedback from the link under study
Transitive Links
Stage 3
Source File
Test File
Test File
A BETA mixture model is employed to model all transitive (probabilistic) links
The Holistic Model
Stage 4
The Probabilistic Nature of The Link Recovery Problem
The link recovery problem is the fundamental problem in Software Traceability; it consists in automatically establishing the relationships of artifacts allowing for the evolution of the system and the nature of the data
The link recovery problem: How would you compute theta?
Source File
Requirement File
How do we enhance link recovery with recent IR/ML approaches?
Trace Link (Similarity) Value [0,1]
Trace Link from Requirement to Test Case
Execution Trace from Source Code to Test Case
Source Artifacts (i.e., requirement files)
Target Artifacts (i.e., source code files)
How do we enhance link recovery with recent IR/ML approaches?
Source File
Requirement File
Test File
What if we compute a second theta for Req to Tc? Is the initial theta affected?
Source File
Requirement File
Test File
And what if we add more information?
Source File
Requirement File
Test File
Test File