Towards Reconstructing Software Evolution Trends and Artifacts Relationships with Statistical Models
By David A. Nader
Terminology
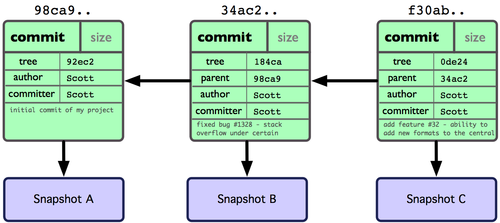
A Software Repository is a storage location where developers can publish or retrieve software artifacts (e.g., requirements, source code, or test code)




Source Files
Requirements
Test
published
retrieved
repos
artifacts
A Software Repository tracks meta-data (e.g., timestamps, ids, or descriptions) of Issues, Commits, and Stakeholders
Issues
Stakeholders
Commits


Open
Close
Assigned
Depending on the state, an issue is tagged in one of three categories: Open (by an analyst), Assigned (by a manager), or Close (by a developer)
Assigned
Open
Close
Software managers usually keep track of Management Metrics: the size of the teams (# of stakeholders), the effort spent in the project (days-person), bug appearance (# of issues), and the size of the software (# of commits)
effort
stakeholders
size
issues



Software Artifacts are continuously modified across the time, such process is known as Software Evolution
Assigned
Open
Close

State-of-the-art
(and aim)
The purpose of this project is to simulate the software evolution process from repos' meta-data
Simulation for Optimization 🡒 Software Management
Data analysis and Simulation have contributed to study the behavior of Time and Software Management Metrics
Simulation for Automation 🡒 Software Maintenance

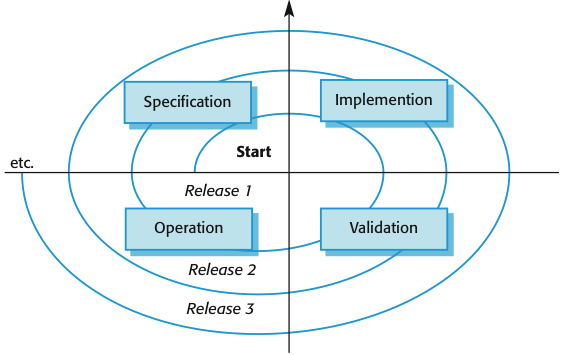
In the context of Simulation for Optimization, Honsel, et al. (ICSE'14) introduce three software engineering factors
Project Growth Treds
Bug Appearance
Development Strategies
Number of Commits
Number of Issues
Effort
The Problem
tracked in
software evolution
time-dependent metrics
tracked in
retrieved from
software evolution
time-dependent metrics
tracked in
retrieved from
software evolution
generalized
distributions
to what extend can we generalize time-depend metrics by using statistical models?
Hypothesis
Statistical Software Evolution Models are probability distributions over dynamic data stored in repositories to understand and estimate trends in software
trace-driven dynamic data
These trends are behavioral aspects like project growth (number of commits), bug appearance (number of issues), and the developer activity (effort)
Project Growth Treds
Bug Appearance
Development Strategies
Number of Commits
Number of Issues
Effort
We hypothesized that software evolution trends are described by statistical models from data repositories and the software evolution process can be simulated by trace-driven modeling
The Approach
(discrete-event simulation)
[ssq] A single-server node consists of a server and a queue
arrivals
queue
departures
server
service node
- job: issue
- server: teams or software groups
[msq] A multi-server service node consists of a single queue, and two or more servers operating in parallel
arrivals
queue
departures
servers
- job: issue
- server: teams or software groups
issue-open
issue-close
issue-wait
issue-delay
issue-service
Assigned
Open
Close
We can derive five distinct Time Metrics (Discrete-event simulation metrics) based on the repository timestamps of the issues
Datasets & Experiments

We used the MSR’14 dataset that include 90 different projects with their derivations (forks)
The dataset were pre-processed and transformed into time-traces
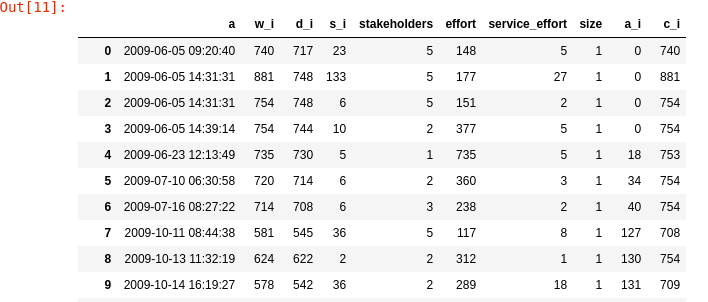
Experiments
- [Exploratory Analysis] Some probability distributions were fitted into the time-traces
- [Empirical Analysis & Simulation] It was modeled both a single-server (ssq) and a multi-server queue system (msq) to infer values for time and software metrics
Exploratory Analysis
(results)
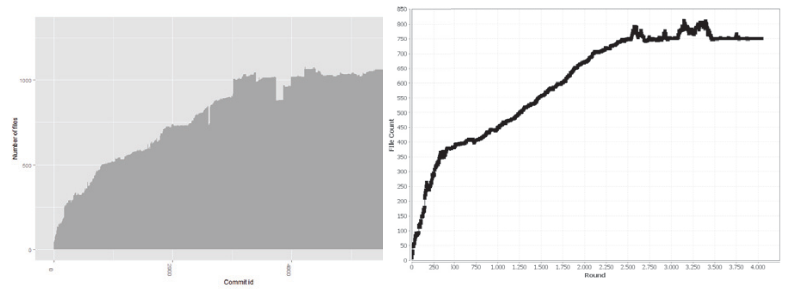
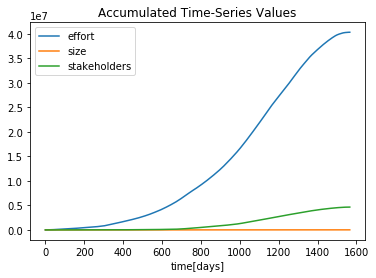
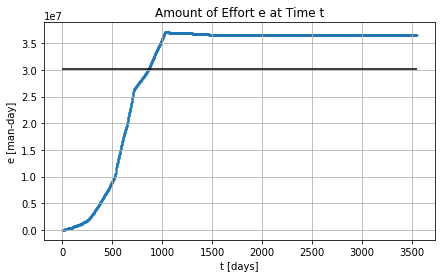
Cumulative Software Metrics: the effort grows faster than the source code
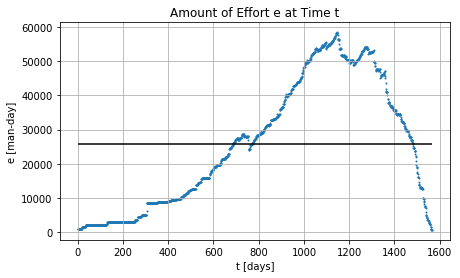
Effort across the time with and without completion times
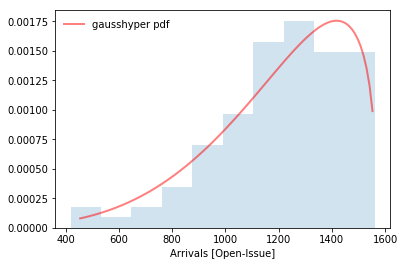
PDFs vs. Fitted Arrivals and Services [of issues]
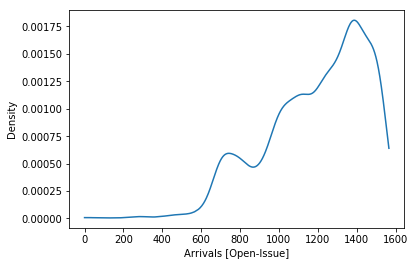
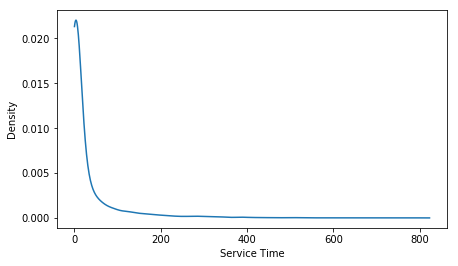
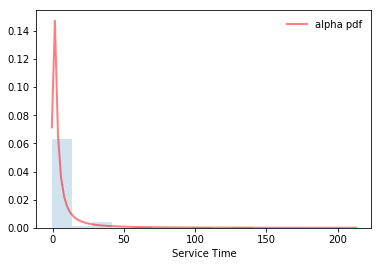
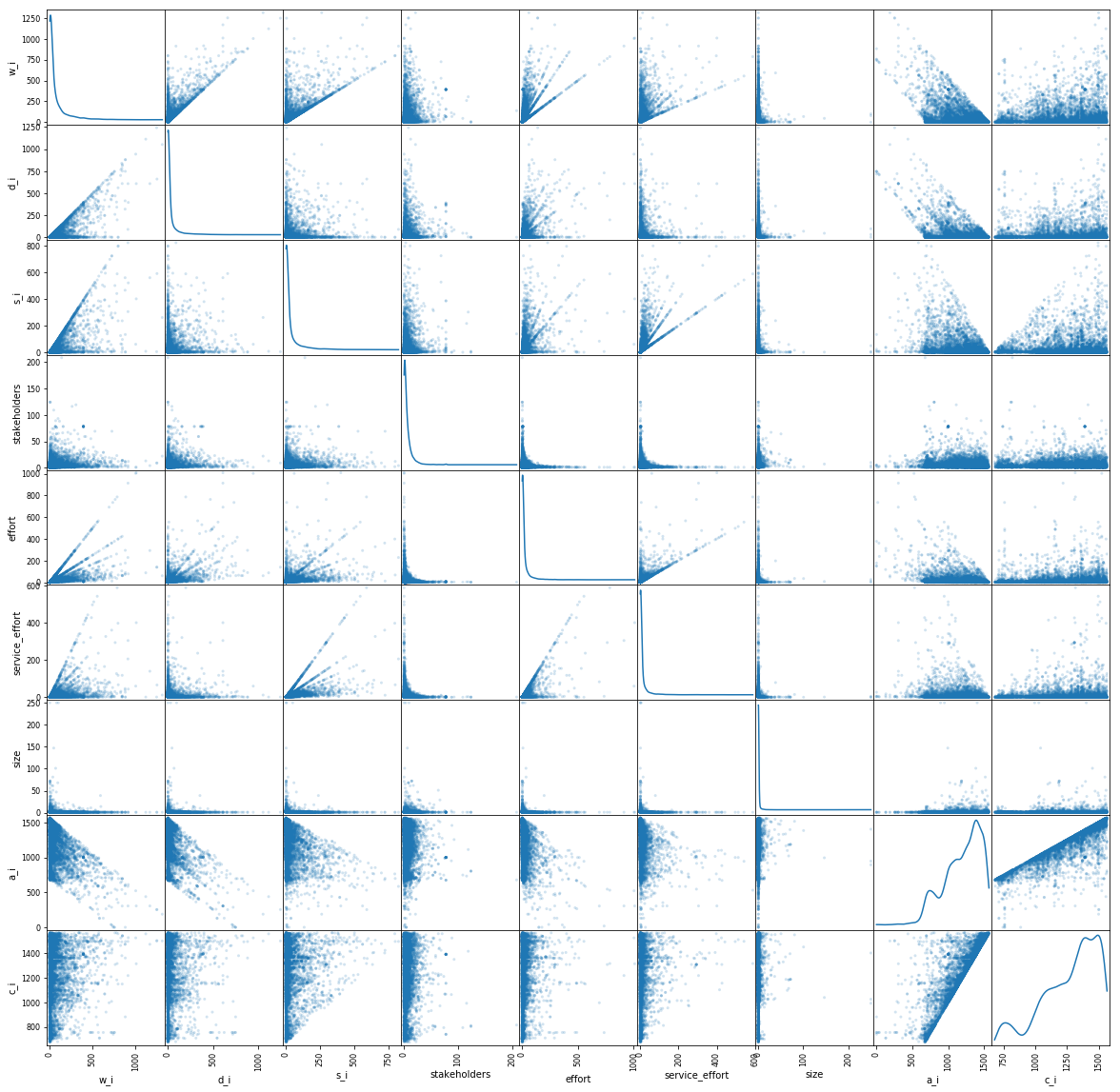
Our study demonstrates that the software effort is correlated with the wait (r=.64) and delay (r=0.51) times
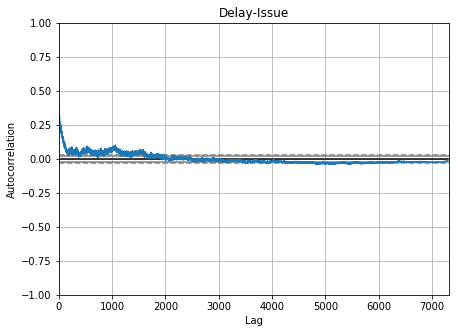
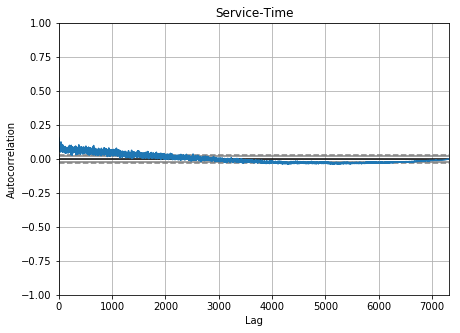
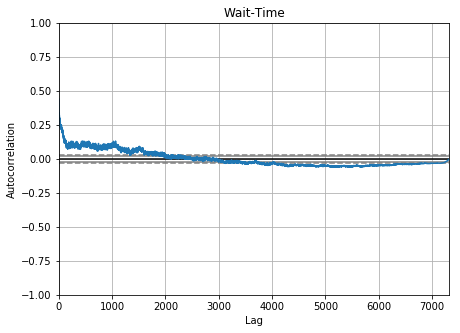
Auto-correlation in Time Metrics of Issues

Empirical Analysis & Simulation
(results)
First Order Statistics
from Datasets
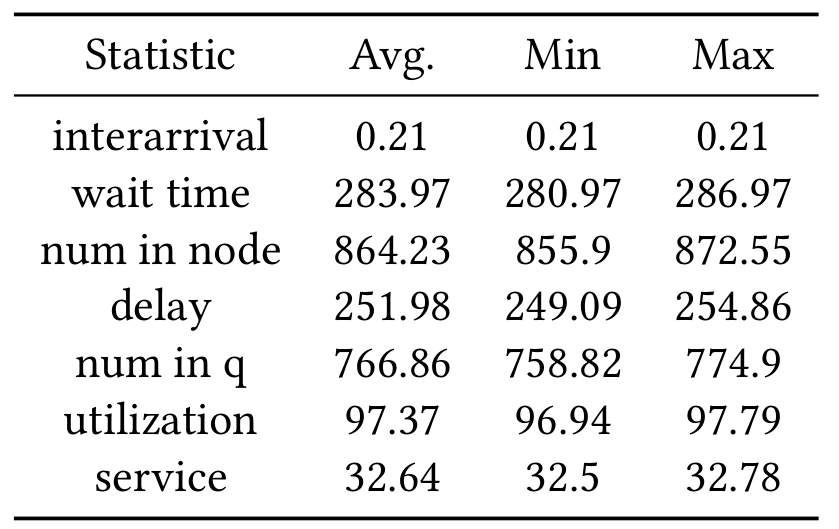
[Empirical] The average service, delay, and interarrival times are 31.9, 32.3, and 0.2 days respectively
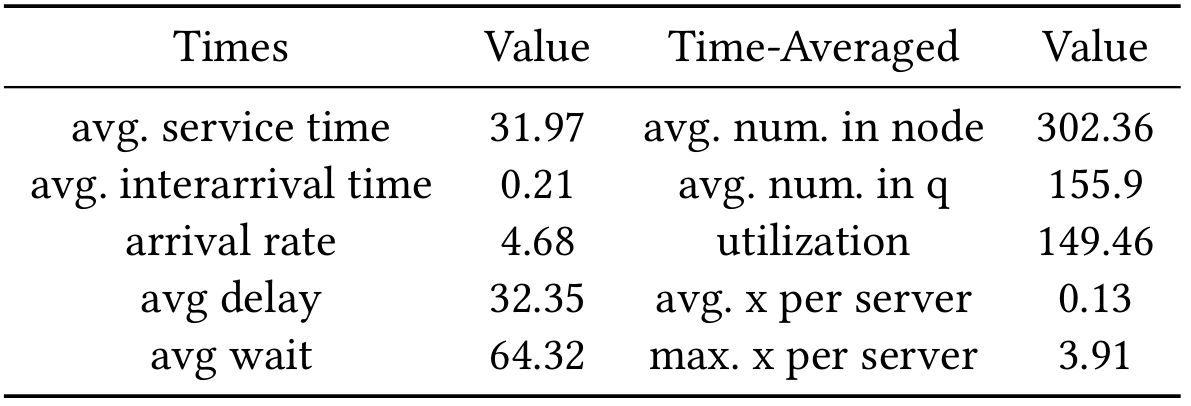
[Empirical] Time-Averaged Statistics
[Empirical] Approx Utilization per server
[Empirical] The approximate number of servers is 1177 with an average utilization of 0.13
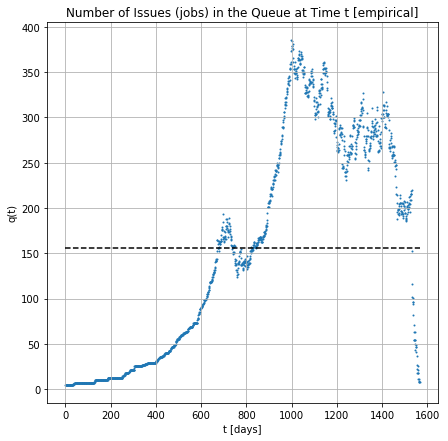
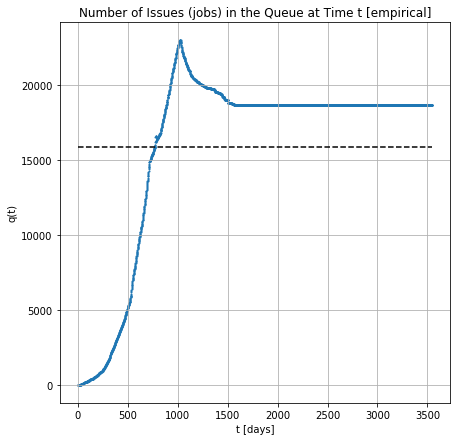
[Empirical] Number of jobs in the Q across the time
ssq
[Simulated-ssq] providing arrivals and services for 7326 jobs:
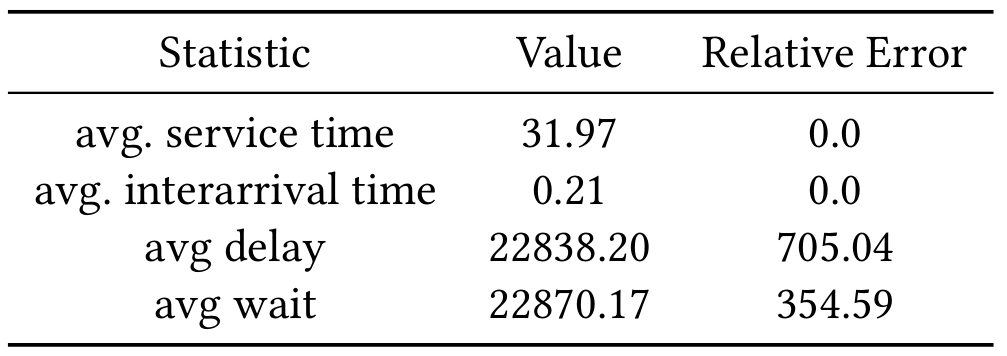
[Simulated-ssq] The average approximation error after 31 runs:
multi-server
[Simulated-msq] Avg. Approximation Error for msq providing non-stationary arrivals and exponential services
| metric | with exponential services | with fitted services | with fitted services and non stationary arrivals (λ_max) | with exponential services and non stationary arrivals (λ_max) | with approx servers |
|---|---|---|---|---|---|
| avg wait | 3.42 | 0.87 | 0.87 | 0.50 | 0.50 |
| avg delay | 6.79 | 1.00 | 1.00 | 1.00 | 1.00 |
| avg interarrival | 0.00 | 0.00 | 3.70 | 3.70 | 3.69 |
| avg service | 0.02 | 0.73 | 0.74 | 0.02 | 0.01 |
| utilization | 0.35 | 0.77 | 0.95 | 0.80 | 0.80 |
| avg # in node | 1.87 | 0.89 | 0.97 | 0.90 | 0.90 |
| avg # in q | 4.07 | 1.00 | 1.00 | 1.00 | 1.00 |
Summary
Simulation for Optimization 🡒 Software Management
Further work is needed to formulate a Dynamic Bayesian model to map the software evolution
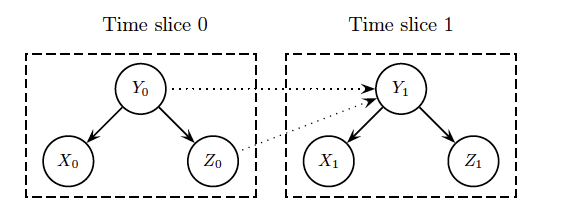
Simulation for Automation 🡒 Software Maintenance
A map is able to point out software artifacts correlations across the time
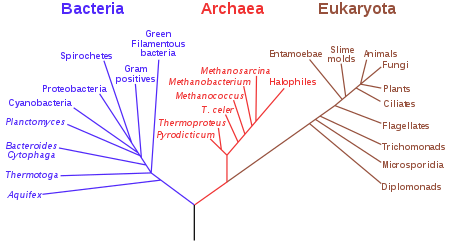
Software Traceability by means of Phylogenetic maps (?)
Simulation for Automation 🡒 Software Maintenance
Simulation for Optimization 🡒 Software Management
Time-dependent Metrics Analysis
Simulation for Optimization 🡒 Software Management
Correlations & Autocorrelations
Effort vs {w_i, d_i}
effort & wait time: [r = 0.64]
effort & delay time: [r = 0.51]
Time-dependent Metrics Analysis
Simulation for Optimization 🡒 Software Management
| metric | with exponential services | with fitted services | with fitted services and non stationary arrivals (λ_max) | with exponential services and non stationary arrivals (λ_max) | with approx servers |
|---|---|---|---|---|---|
| avg wait | 3.42 | 0.87 | 0.87 | 0.50 | 0.50 |
| avg delay | 6.79 | 1.00 | 1.00 | 1.00 | 1.00 |
| avg interarrival | 0.00 | 0.00 | 3.70 | 3.70 | 3.69 |
| avg service | 0.02 | 0.73 | 0.74 | 0.02 | 0.01 |
| utilization | 0.35 | 0.77 | 0.95 | 0.80 | 0.80 |
| avg # in node | 1.87 | 0.89 | 0.97 | 0.90 | 0.90 |
| avg # in q | 4.07 | 1.00 | 1.00 | 1.00 | 1.00 |
Empirical & Simulated Values
Avg. Approx. Error (msq better than ssq)
Time-dependent Metrics Analysis
Correlations & Autocorrelations
Effort vs {w_i, d_i}
effort & wait time: [r = 0.64]
effort & delay time: [r = 0.51]
Thank you
Appendix
create or replace view v_processed_issues as select FirstSet.PR, FirstSet.ID,
FirstSet.open_issue,
FirstSet.wait_issue,
SecondSet.delay_issue,
(FirstSet.wait_issue-SecondSet.delay_issue) as service_issue,
ThirdSet.stakeholders,
ceil(FirstSet.wait_issue/ThirdSet.stakeholders) as effort,
ceil((FirstSet.wait_issue-SecondSet.delay_issue)
/ThirdSet.stakeholders) as service_effort
from
(select distinct ISU.id as ID, ISU.repo_id as PR,
ISU.created_at as open_issue, ISUE.action as AC,
TIMESTAMPDIFF(DAY, ISU.created_at, ISUE.created_at) as wait_issue
from msr14.issues as ISU join msr14.issue_events as ISUE on ISU.id = ISUE.issue_id
where ISUE.action='closed') as FirstSet
inner join
(select distinct ISU.id as ID, ISU.repo_id as PR,
ISU.created_at as open_issue, ISUE.action as AC,
TIMESTAMPDIFF(DAY, ISU.created_at, ISUE.created_at) as delay_issue
from msr14.issues as ISU join msr14.issue_events as ISUE on ISU.id = ISUE.issue_id
where ISUE.action='assigned') as SecondSet
on FirstSet.PR = SecondSet.PR and FirstSet.ID = SecondSet.ID
inner join v_issues as ThirdSet
on FirstSet.ID = ThirdSet.IS_ID
having service_issue >= 0
and FirstSet.wait_issue >= 0
and SecondSet.delay_issue >= 0
order by FirstSet.open_issue; An sql view to create the "Software Evolution Traces"

There are 90 different SW projects
One project has multiple issues

A pull-request has multiple issues
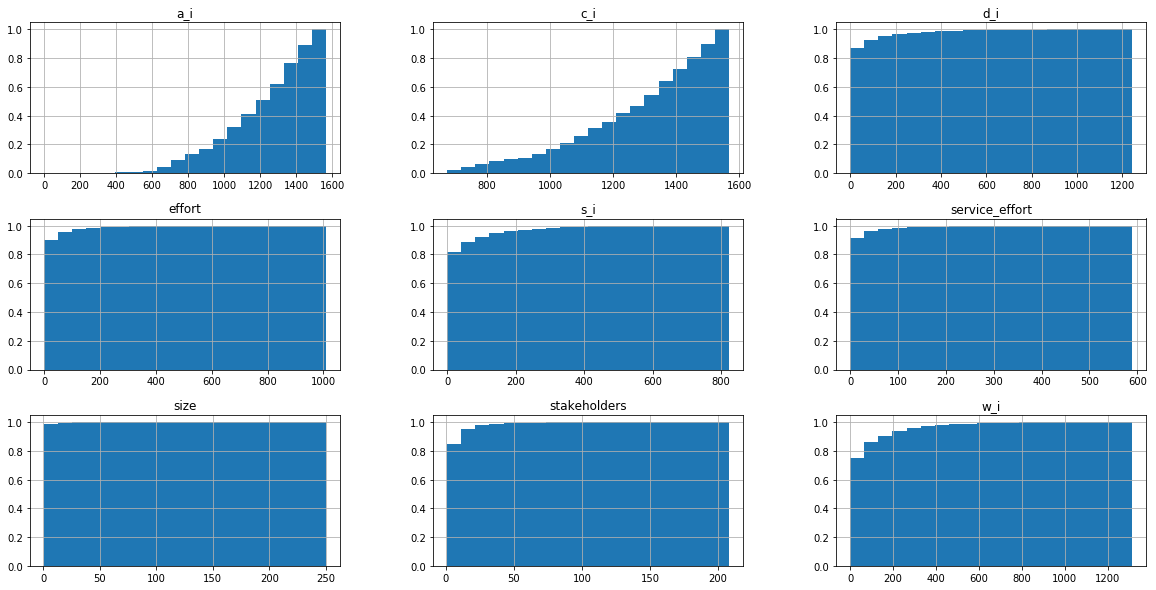
histograms main metrics

CDFs main metrics
Second study: Simulation of Software Engineering Metrics (Honsel, 2015)

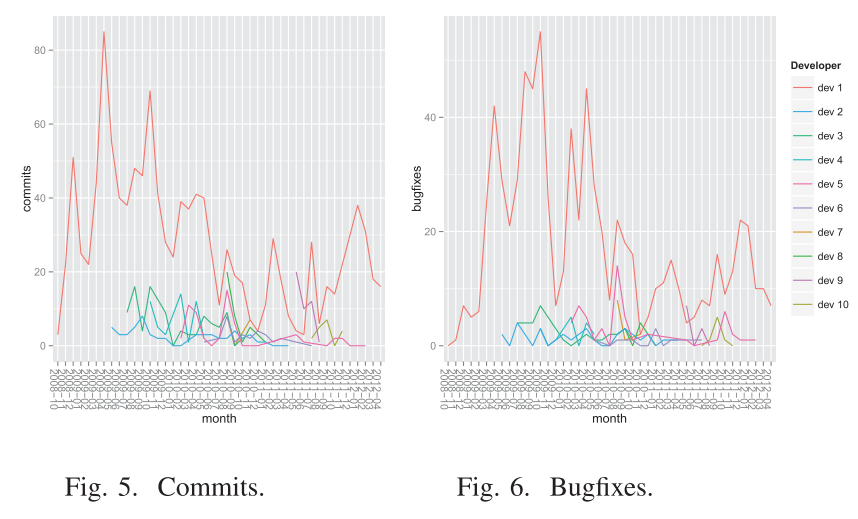
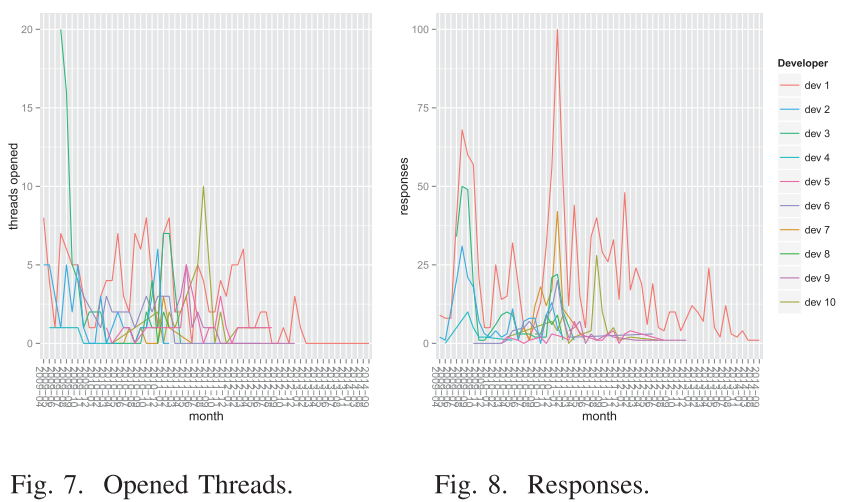

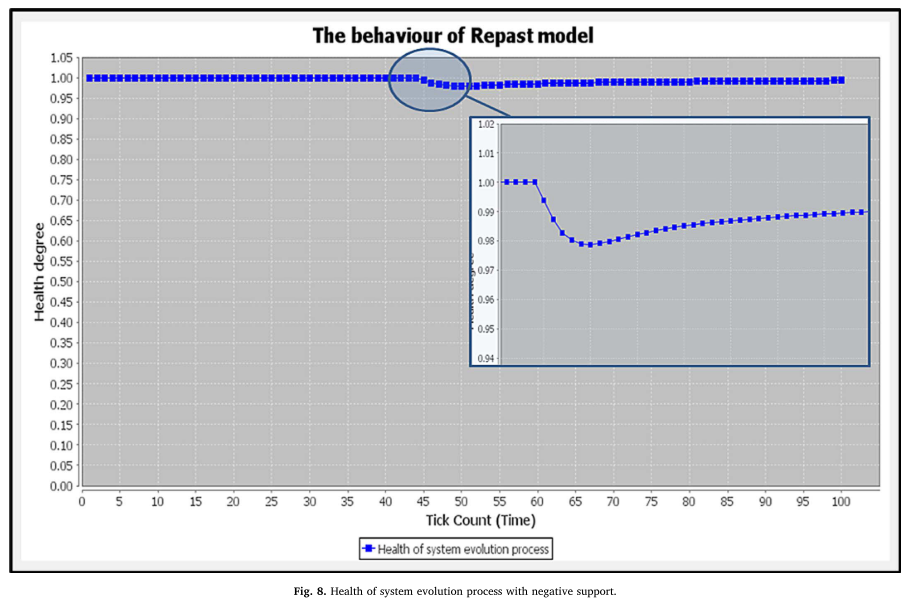
Third study: Simulation of Software Engineering Metrics (Mohammed-Ali, 2018)
Software Evolution Trends is the study of time-dependent metrics from software maintenance tasks
time-dependent metrics
maintenance tasks
[Empirical] Number of jobs in the node across the time
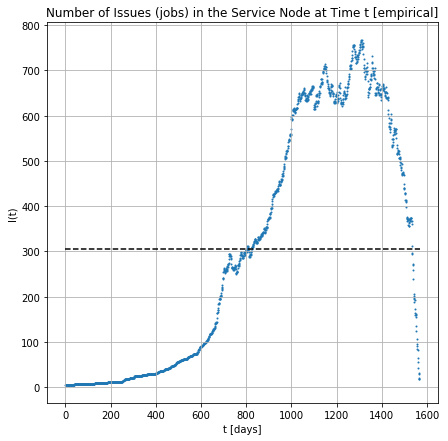
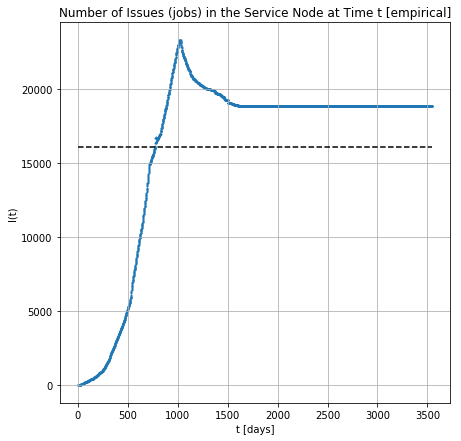
[Simulated-msq] providing arrivals and exponential service times for 7325 jobs , 150 servers, 34 runs:
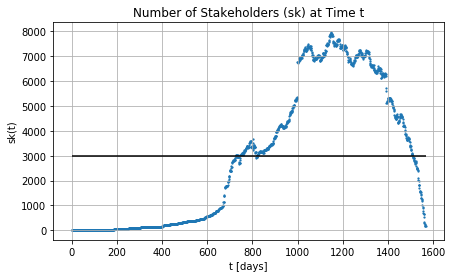
Stakeholders across the time with and without completion times
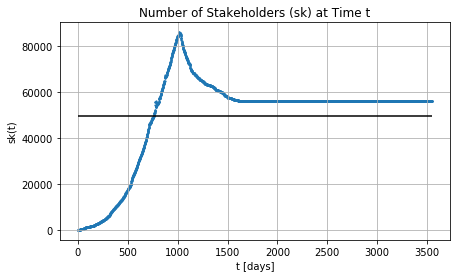

(Honsel, et al., 2014)